







 本文讨论了SQL数据库优化的关键点,包括表设计中的类型选择、索引优化策略、避免索引失效的SQL编写技巧、主从复制与读写分离的应用,以及在面试中提及的分库分表和SQL查询效率提升方法。
本文讨论了SQL数据库优化的关键点,包括表设计中的类型选择、索引优化策略、避免索引失效的SQL编写技巧、主从复制与读写分离的应用,以及在面试中提及的分库分表和SQL查询效率提升方法。
主要通过以下几个方面
表的设计优化
索引优化 参考优化创建原则和索引失效
SQL语句优化
主从复制、读写分离
分库分表(由于内容比较多,我写到另一篇文章里面)
表的设计优化(参考阿里开发手册《嵩山版》)。
① 比如设置合适的数值(tinyint int bigint),要根据实际情况选择
②比如设置合适的字符串类型(char和varchar)char定长效率高,varchar可变长度,效率稍低
SQL语句优化
SELECT语句务必指明字段名称(避免直接使用select*)①
② SQL语句要避免造成索引失效的写法
③ 尽量用union all代替union union会多一次过滤,效率低
④避免在where子句中对字段进行表达式操作
⑤ Join优化 能用innerjoin 就不用left join rightjoin,如必须使用 一定要以小表为驱动内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。left ioin 或 riaht join,不会重新调整顺序

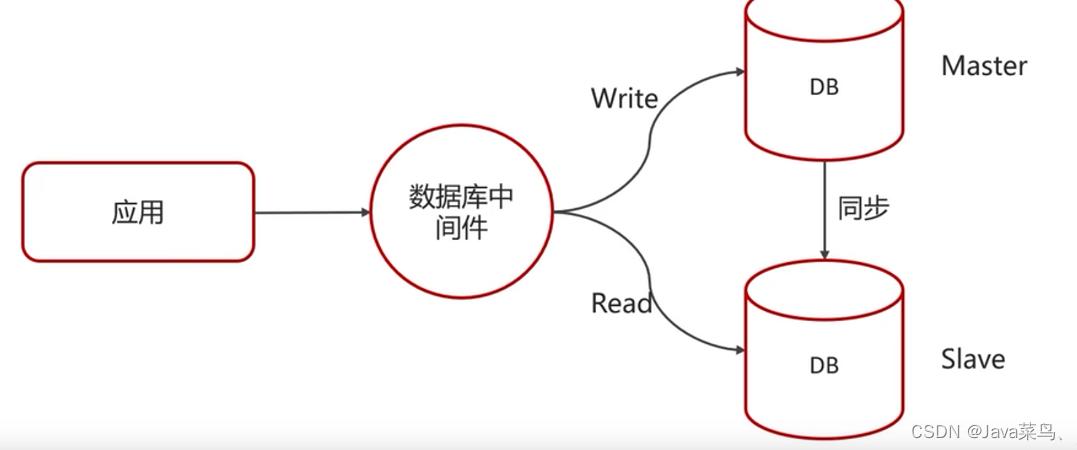
主从复制、读写分离
如果数据库的使用场景读的操作比较多的时候,为了避免写的操作所造成的性能影响 可以采用读写分离的架构。
读写分离解决的是,数据库的写入,影响了查询的效率。
面试参考回答:
面试官:sq!的优化的经验
候选人:嗯,这个在项目还是挺常见的,当然如果直说sq!优化的话,我们会从这几方面考虑,比如建表的时候、使用索引、sq!语句的编写、主从复制,读写分离,还有一个是如果量比较大的话,可以考虑分库分表
面试官:创建表的时候,你们是如何优化的呢?
候选人:这个我们主要参考的阿里出的那个开发手册《嵩山版》,就比如,在定义字段的时候需要结合字段的内容来选择合适的类型,如果是数值的话,像tinyint、int、bigint这些类型,要根据实际情况选择。如果是字符串类型,也是结合存储的内容来选择char和varchar或者text类型
面试官:那在使用索引的时候,是如何优化呢?
候选人:【参考索引创建原则 进行描述】
面试官:你平时对sql语句做了哪些优化呢?
候选人:嗯,这个也有很多,比如SELECT语句务必指明字段名称,不要直接使用select*,还有就是要注意SOL语句避免造成索引失效的写法;如果是聚合查询,尽量用unionall代替union,union会多一次过滤,效率比较低;如果是表关联的话,尽量使用imnerioin,不要使用用leftjoin rightjoin,如必须使用 一定要以小表为驱动
















 42万+
42万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











