







1.8版本特性
Java 1.8(也称为Java 8)引入了许多新特性和改进,其中最引人注目的特性之一是函数式编程支持。以下是Java 1.8的一些主要特性:
-
Lambda 表达式:Lambda 表达式是一个匿名函数,它可以作为参数传递给方法或存储在变量中。它提供了一种更简洁、更清晰的语法来表示函数式接口(只包含一个抽象方法的接口)的实现。
-
Stream API:Stream API 提供了一种新的抽象序列的方式,使得开发者能够以声明性的方式对数据集合进行操作,例如过滤、映射、排序、聚合等操作。Stream API 的引入使得代码更加简洁和可读,并且可以更容易地进行并行处理。
-
默认方法(Default Methods):接口可以包含默认方法,这些方法在接口中有默认的实现。这样一来,接口的实现类就不需要实现默认方法,但如果需要,也可以覆盖它们。
-
方法引用:方法引用提供了一种更简洁的语法来调用已存在的方法,例如类的静态方法、对象的实例方法或者构造函数。
-
Optional 类:Optional 类是一个容器类,它可以包含或者不包含一个非空值。它可以解决空指针异常问题,并鼓励更好的代码编写实践。
-
新的日期和时间 API:Java 1.8引入了全新的日期和时间 API,以替代旧的
java.util.Date和java.util.Calendar类。新的 API 提供了更多的功能,更容易使用和理解。 -
并行数组操作:Java 1.8引入了并行数组操作,可以在数组上以并行的方式进行排序、过滤、映射等操作,从而提高了处理大型数据集合的效率。
-
重复注解(Repeated Annotations):允许在同一个元素上多次使用相同的注解,这样可以减少代码的冗余性。
这些特性使得Java 1.8成为了一个功能更加强大、更易于使用的版本,为Java编程带来了许多便利和优势。
函数式接口
函数式接口是Java中的一个重要概念,它是指只包含一个抽象方法的接口。Java 8 引入了函数式接口以支持 Lambda 表达式,这是函数式编程的一个关键概念。
函数式接口有以下特点:
-
只有一个抽象方法:函数式接口只能包含一个抽象方法,这样可以确保它可以用作函数式编程中的目标类型。
-
可以有默认方法和静态方法:函数式接口可以包含默认方法和静态方法,但只能有一个抽象方法。
-
用于 Lambda 表达式和方法引用:函数式接口可以用于 Lambda 表达式和方法引用,使得代码更加简洁和易读。
-
注解标记:Java 8 引入了
@FunctionalInterface注解,用于明确标记一个接口是函数式接口。编译器会检查带有该注解的接口是否符合函数式接口的定义,如果不符合则会报错。
函数式接口在 Java 中的使用场景包括但不限于:
- 作为方法的参数或返回值类型。
- 用于 Lambda 表达式的目标类型。
- 用于方法引用的目标类型。
例如,Java标准库中的 java.lang.Runnable 和 java.util.Comparator 都是函数式接口的典型示例。以下是一个简单的函数式接口的示例:

在这个例子中,MyFunction 是一个函数式接口,因为它只有一个抽象方法 doSomething()。在实际应用中,可以将这个接口作为 Lambda 表达式的类型或者方法参数的类型。
Java面向对象的特性
封装、继承、多态
封装指的是什么?
封装(Encapsulation)是面向对象编程(OOP)的三大特征之一,其核心思想是将数据(属性)和操作数据的方法(方法)捆绑在一起,形成一个单独的单元。这个单元被称为类,它对外部隐藏了其内部的实现细节,只暴露必要的接口供外部访问。
封装的主要目的是实现信息隐藏和安全性,通过将数据隐藏在类的内部,可以防止外部直接访问和修改对象的内部状态。只有通过类提供的公共方法(也称为接口)才能访问和操作对象的状态,从而确保了对象的数据完整性和一致性。
封装提供了以下几个好处:
-
信息隐藏:封装可以隐藏对象的内部实现细节,使得对象的使用者无需关心对象的具体实现,只需要通过公共接口与对象交互即可。
-
安全性:封装可以防止外部直接访问和修改对象的内部状态,通过限制对对象的访问,可以确保对象数据的安全性和一致性。
-
简化编程:封装可以将对象的复杂实现细节隐藏起来,简化了代码的使用和维护,提高了代码的可读性和可维护性。
-
提高灵活性:封装可以通过公共接口来访问对象,这样可以方便地修改和扩展对象的实现细节,而不会影响到对象的使用者。
在Java中,封装通常通过访问控制修饰符(如private、protected、public)来实现。通过将数据成员声明为private,然后提供公共的getter和setter方法来访问和修改数据,从而实现了封装。
三个安全修饰
在 Java 中,有三个关键字用于安全修饰:public、protected 和 private。这些修饰符用于控制类、方法和变量的访问权限。下面是它们的含义和用法:
-
public: 使用
public修饰的类、方法或变量可以被任何其他类访问。换句话说,它们是公开的,可以在任何地方被访问。public class MyClass { public int myPublicVar; public void myPublicMethod() { // 该方法可以被任何其他类调用 } } -
protected: 使用
protected修饰的成员只能在同一包中的其他类或者该类的子类中访问。它们对于同一包中的其他类来说是可见的,但对于不在同一包中的类来说是不可见的。class MyClass { protected int myProtectedVar; protected void myProtectedMethod() { // 该方法可以在同一包中的其他类或者该类的子类中访问 } } -
private: 使用
private修饰的成员只能在同一个类中访问,对于同一个包中的其他类或者该类的子类来说是不可见的。class MyClass { private int myPrivateVar; private void myPrivateMethod() { // 该方法只能在同一个类中访问 } }
这些安全修饰符允许你控制代码的访问级别,从而增强代码的安全性和封装性。
继承
继承是面向对象编程中的一个重要概念,它允许一个类(称为子类或派生类)继承另一个类(称为父类或基类)的属性和方法。在 Java 中,继承使用 extends 关键字来实现。
下面是一个简单的示例,演示了如何在 Java 中使用继承:
// 定义一个父类
class Animal { public void eat() { System.out.println("动物正在吃食物"); } }
// 定义一个子类,继承自 Animal 类
class Dog extends Animal { public void bark() { System.out.println("狗在汪汪叫"); } }
public class Main { public static void main(String[] args) {
// 创建 Dog 对象
Dog myDog = new Dog();
// 子类对象可以调用继承自父类的方法
myDog.eat();
// 子类对象也可以调用自身新增的方法
myDog.bark(); } }
在这个示例中,Dog 类继承自 Animal 类。因此,Dog 类可以使用 Animal 类中定义的 eat() 方法,同时也可以定义自己的 bark() 方法。通过继承,子类可以复用父类的方法和属性,并且可以添加新的方法和属性。
Java 中的继承还涉及一些其他概念,如方法重写(Override)和方法重载(Overload),以及访问修饰符的继承规则。但基本原理就是子类可以继承父类的属性和方法。
继承在面向对象编程中具有多种作用,其中一些主要作用包括:
-
代码复用: 继承允许子类继承父类的属性和方法,从而实现代码的复用。子类可以直接使用父类中已经定义好的属性和方法,而无需重新实现。
-
统一接口: 通过继承,可以创建具有相似接口的对象,使得一组对象可以被视为同一类型。这样就可以统一对这些对象进行操作,而不需要考虑它们的具体类型。
-
多态性: 继承和方法重写(Override)的结合可以实现多态性。即使是不同的子类对象,如果它们继承自同一个父类并且重写了相同的方法,那么可以根据实际对象的类型来调用相应的方法,从而实现不同行为的表现。
-
拓展功能: 子类可以在继承父类的基础上添加新的方法和属性,从而拓展父类的功能。这样可以保持原有代码的稳定性,并且可以根据需要灵活地拓展功能。
-
软件设计的层次化: 通过合理地设计类之间的继承关系,可以将系统分解为多个层次,从而提高代码的组织结构和可维护性。通过继承,可以将通用的功能放在父类中,而将特定的功能放在子类中,使得整个系统更易于理解和扩展。
总的来说,继承是面向对象编程中一种重要的机制,它可以提高代码的复用性、灵活性和可扩展性,是实现面向对象设计原则之一的关键手段。
父类有string name;子类可以重新定义一个一模一样的string name吗?
在子类中重新定义与父类相同的属性是允许的,但这并不是一种好的做法,因为这可能导致混淆和代码不易理解。在 Java 中,如果子类重新定义了与父类相同的属性,这将会隐藏父类的同名属性,而不是继承它。
当子类重新定义一个与父类相同名称的属性时,我们称之为"属性隐藏"。这意味着在子类对象中,访问该属性时将会访问到子类中定义的属性,而不是父类中的属性。这可能会导致意外的行为,特别是在代码中存在继承关系时。
通常情况下,更好的做法是通过父类的构造方法或者提供 getter 和 setter 方法来访问父类的属性,而不是在子类中重新定义相同的属性。
以下是一个示例说明属性隐藏的情况:

在上面的示例中,Child 类重新定义了一个与父类 Parent 相同名称的属性 name。在 printNames() 方法中,使用 super.name 可以访问父类的属性,而使用 this.name 则访问子类的属性。
抽象类可以被new出来的吗?
不可以。
抽象类是不能直接实例化的,也就是说你不能使用 new 关键字来创建抽象类的对象。抽象类是用来被继承的,它通常包含了一些抽象方法,这些方法需要在子类中被具体实现。
抽象类的存在主要是为了定义一个通用的模板或者接口,子类通过继承抽象类,并实现其中的抽象方法,来提供具体的功能实现。因此,抽象类的主要作用是为子类提供一个统一的规范,而不是被直接实例化的。
在 Java 中,如果一个类包含抽象方法,那么该类必须声明为抽象类。而抽象类本身不能被实例化,只有具体的子类可以被实例化。

在上面的示例中,Animal 类是抽象类,其中包含了一个抽象方法 makeSound()。由于抽象类不能被直接实例化,因此尝试实例化 Animal 类对象会导致编译错误。但是可以实例化它的子类 Dog,并调用其中实现的方法。
接口的特点
接口是Java编程中的一种重要机制,它具有以下特点:
-
抽象性: 接口中的方法都是抽象的,即只有方法的声明,没有方法的实现。接口中定义的方法都是公共的抽象方法,默认情况下使用
public abstract修饰。 -
多继承: 类可以实现多个接口,这种多继承的特性使得Java中的类具有更大的灵活性。一个类可以同时实现多个接口,从而获得接口中定义的所有方法。
-
无法实例化: 接口本身不能被实例化,因为它只包含抽象方法的声明,没有方法的实现。因此,不能使用
new关键字来创建接口的对象。 -
通过类实现: 类通过关键字
implements来实现接口,并提供接口中所有抽象方法的具体实现。
至于接口是否可以不定义抽象方法,是不可以的。因为接口的存在就是为了定义一组抽象方法,以定义一种行为规范或契约。如果接口中不定义任何抽象方法,那它就失去了存在的意义。
如果在接口中定义了非抽象方法,则必须使用 default 关键字来修饰该方法。这样的方法就是接口的默认方法,它们可以提供一个默认的实现,而不需要实现类强制去重写它们。这样做的好处是可以在不破坏现有实现的情况下向接口添加新的方法。

在上面的示例中,MyInterface 接口定义了一个抽象方法 abstractMethod() 和一个默认方法 defaultMethod()。接口的实现类 MyClass 实现了接口,并提供了抽象方法的具体实现。调用实现类对象的方法可以看到抽象方法和默认方法的执行结果。
接口里面所有的抽象方法必须都要被实现吗?
在 Java 中,当一个类实现了一个接口时,它必须实现接口中的所有抽象方法,除非这个类自己也是抽象类。
如果一个类实现了一个接口但没有实现接口中的所有抽象方法,那么这个类必须被声明为抽象类。否则,在编译时会报错。

在这个示例中,MyClass 类实现了 MyInterface 接口,但是没有实现接口中的所有抽象方法,因此会导致编译错误。要么实现所有的抽象方法,要么将 MyClass 声明为抽象类。
常用的集合
在 Java 中,集合(Collection)是一种用于存储和操作对象的容器。Java 提供了丰富的集合框架,其中最常用的集合包括以下几种:
-
ArrayList: 基于动态数组实现的列表,允许快速随机访问元素。ArrayList 的特点是可以动态增长,但在删除元素时可能需要移动其他元素。
-
LinkedList: 基于双向链表实现的列表,适合插入和删除操作,但访问元素的效率较低。LinkedList 提供了在任何位置进行元素插入和删除的灵活性。
-
HashSet: 基于哈希表实现的集合,不保证元素的顺序,且不允许重复元素。HashSet 提供了常数时间的插入、删除和查找操作,适合用于需要快速查找元素的场景。
-
TreeSet: 基于红黑树实现的有序集合,元素按照自然顺序或者指定的比较器进行排序。TreeSet 提供了快速的有序遍历功能,但插入、删除和查找操作的时间复杂度略高于 HashSet。
-
HashMap: 基于哈希表实现的键值对映射,可以通过键快速查找对应的值。HashMap 允许空键和空值,但不保证元素的顺序。
-
TreeMap: 基于红黑树实现的有序键值对映射,元素按照键的自然顺序或者指定的比较器进行排序。TreeMap 提供了按照键排序的遍历功能,但插入、删除和查找操作的时间复杂度略高于 HashMap。
-
LinkedHashMap: 基于哈希表和双向链表实现的有序键值对映射,保持元素的插入顺序或者访问顺序。
-
HashSet 和 TreeSet 是实现了 Set 接口的类,它们不允许重复元素。而 HashMap、TreeMap 和 LinkedHashMap 则实现了 Map 接口,允许键和值都可以为空,且键不能重复。
这些是 Java 中最常用的集合类,根据具体的需求和场景选择合适的集合类可以提高程序的效率和性能。
Stream流Java8操作集合的方法
Java 8 引入了 Stream API,它提供了一种更为函数式和声明式的方式来操作集合数据。使用 Stream,可以轻松进行过滤、映射、排序、聚合等操作,使代码更加简洁和易于理解。下面是一些常见的 Stream 操作方法:
-
创建 Stream:
- 通过集合调用
stream()方法创建流:List.stream()、Set.stream()、Map.entrySet().stream()等。 - 通过数组调用
Arrays.stream(T[] array)创建流。
- 通过集合调用
-
中间操作:
filter(Predicate<T> predicate): 过滤符合条件的元素。map(Function<T, R> mapper): 将流中的每个元素映射为另一个元素。sorted(): 对流中的元素进行排序。distinct(): 去除流中重复的元素。
-
终端操作:
forEach(Consumer<T> action): 对流中的每个元素执行指定操作。collect(Collector<T, A, R> collector): 将流中的元素收集到一个集合或其他数据结构中。reduce(BinaryOperator<T> accumulator): 将流中的元素进行归约操作,返回一个值。count(): 返回流中元素的数量。anyMatch(Predicate<T> predicate): 判断流中是否存在符合条件的元素。allMatch(Predicate<T> predicate): 判断流中是否所有元素都符合条件。noneMatch(Predicate<T> predicate): 判断流中是否所有元素都不符合条件。findFirst(): 返回流中的第一个元素(如果存在)。findAny(): 返回流中的任意一个元素(如果存在)。min(Comparator<T> comparator)和max(Comparator<T> comparator): 返回流中的最小值和最大值。
-
其他操作:
skip(long n): 跳过流中的前 n 个元素。limit(long maxSize): 限制流中元素的数量不超过 maxSize。
这些方法可以根据具体的需求进行组合使用,以完成各种对集合数据的处理和转换操作。 Stream API 提供了一种更加简洁、高效和易于理解的方式来处理集合数据。
Springboot 的核心注解
Spring Boot 是一个基于 Spring 框架的快速开发框架,它通过一系列的核心注解来简化应用程序的配置和开发。下面是 Spring Boot 中一些常用的核心注解:
-
@SpringBootApplication: 这是一个组合注解,用于标注主应用程序类,它包含了以下三个注解的功能:
@SpringBootConfiguration: 标识该类是 Spring Boot 的配置类,通常用于替代传统的 XML 配置文件。@EnableAutoConfiguration: 开启自动配置功能,Spring Boot 根据项目的依赖和环境自动配置应用程序的各种功能。@ComponentScan: 开启组件扫描,自动扫描并注册 Spring 组件(如 @Component、@Service、@Controller 等)。
-
@RestController: 用于标注 RESTful 风格的控制器类,相当于
@Controller和@ResponseBody的组合。 -
@RequestMapping: 用于映射 HTTP 请求路径到控制器方法,可以用在类级别和方法级别。
-
@Autowired: 用于自动装配 Spring Bean,通过类型或者名称来自动注入 Bean 的实例。
-
@Value: 用于注入配置属性值到 Bean 的字段或者方法参数中。
-
@Component: 通用的组件标识注解,用于将一个类标记为 Spring 的组件,通常与
@Autowired搭配使用。 -
@Service: 用于标注服务层(Service)组件。
-
@Repository: 用于标注数据访问层(Repository)组件,通常与持久化相关的操作。
-
@Configuration: 标识配置类,通常与
@Bean搭配使用,用于定义 Spring Bean。 -
@EnableConfigurationProperties: 开启配置属性绑定功能,将配置文件中的属性值绑定到指定的 JavaBean。
-
@Bean: 用于在配置类中定义 Bean,Spring 容器会根据该注解的方法返回值来注册 Bean。
-
@Profile: 用于标识不同环境下的配置类或者 Bean,可以根据不同的环境选择加载不同的配置。
这些注解是 Spring Boot 中常用的核心注解,它们使得开发者能够更加方便地搭建和管理 Spring Boot 应用程序。
包扫描的是什么东西?
在 Spring 框架中,包扫描(Package Scanning)是一种自动化配置机制,用于扫描应用程序中指定的包及其子包,以发现和注册标有特定注解的组件(如 @Component、@Service、@Repository 等)到 Spring 容器中。这种机制允许开发者通过注解的方式来声明 Spring Bean,而无需手动在配置文件中指定每个 Bean 的定义。
包扫描通常由 @ComponentScan 注解来启用,在 Spring Boot 应用中,通常会在主应用程序类上使用 @SpringBootApplication 注解,而这个注解中已经包含了 @ComponentScan 的功能。@ComponentScan 注解会指定需要扫描的包路径,Spring 容器会递归地扫描该路径下的所有类文件,并将标记了特定注解的类实例化为 Spring Bean。
例如,如果有一个包结构如下:

如果在主应用程序类上标注了 @SpringBootApplication 注解,并且没有额外配置 @ComponentScan,Spring Boot 将会默认扫描 com.example 包及其子包中的所有类,并根据类上的注解自动注册为 Spring Bean。因此,UserController、UserService 和 UserRepository 可能会被自动扫描并注册到 Spring 容器中,以供其他组件使用。
通过包扫描机制,Spring 框架可以更加灵活地管理和装配 Bean,减少了配置的繁琐性,提高了开发效率。
@Bean
在 Spring 框架中,@Bean 注解用于在配置类(通常使用 @Configuration 注解标注的类)中声明一个 Bean,Spring 容器会根据该注解标注的方法返回值来注册一个 Bean 实例。
具体来说,使用 @Bean 注解标注的方法会被 Spring 容器调用,并将方法的返回值作为一个 Bean 注册到容器中。方法名默认就是 Bean 的名称,也可以通过 name 属性指定 Bean 的名称。
下面是一个简单的示例:

在上面的例子中,AppConfig 类被标注为一个配置类(@Configuration),并且声明了一个名为 myBean 的 Bean。myBean 方法使用 @Bean 注解标注,它返回一个 MyBean 类的实例。当 Spring 容器启动时,会自动调用 myBean 方法,并将其返回的 MyBean 实例注册为一个 Bean。
可以通过 @Bean 注解的属性来指定 Bean 的作用域、依赖关系等配置。例如,可以使用 @Scope 注解来指定 Bean 的作用域(如 Singleton、Prototype 等),也可以使用 @DependsOn 注解来指定 Bean 依赖的其他 Bean。
总之,@Bean 注解为开发者提供了一种便捷的方式来手动注册 Bean 到 Spring 容器中,通常用于那些无法通过组件扫描自动发现的 Bean 的注册。
有一个类不属于三个注解但也要Springboot管理用什么注解?
如果一个类不属于 Spring Framework 中的常见注解(如 @Component、@Service、@Repository 等),但你仍然希望 Spring Boot 来管理它,你可以使用 @Bean 注解将其声明为一个 Bean。通过在配置类中使用 @Bean 注解,你可以手动将该类实例化并注册到 Spring 容器中。
假设你有一个名为 MyCustomClass 的类,你可以在配置类中像这样声明它:

在上面的例子中,AppConfig 类被标注为一个配置类(@Configuration),并且声明了一个名为 myCustomClass 的 Bean。myCustomClass 方法使用 @Bean 注解标注,它返回一个 MyCustomClass 类的实例。当 Spring 容器启动时,会自动调用 myCustomClass 方法,并将其返回的 MyCustomClass 实例注册为一个 Bean。
通过这种方式,你可以将任何自定义类纳入 Spring Boot 的管理范围,让 Spring Boot 来管理它的生命周期和依赖关系。
在 Spring Boot 中,依赖注入可以通过多种方式来实现,其中包括构造器注入、Setter 方法注入和字段注入。同时,使用 @Bean 注解也是一种常见的注入方式。
构造器注入:通过在类的构造函数上添加 @Autowired 注解,Spring Boot 可以自动将依赖注入到构造函数中。

Setter 方法注入:通过在类的 Setter 方法上添加 @Autowired 注解,Spring Boot 可以自动将依赖注入到 Setter 方法中。
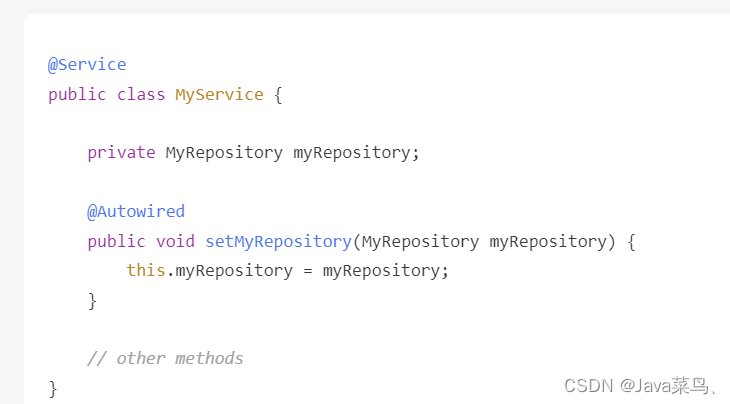
字段注入:直接在字段上使用 @Autowired 注解,Spring Boot 可以自动将依赖注入到字段中。

@Bean 注入:通过在配置类中使用 @Bean 注解声明 Bean,并通过方法返回值提供实例,然后在其他组件中通过 @Autowired 或者直接引用该 Bean 名称来注入。

以上是常见的 Spring Boot 中依赖注入的方式,你可以根据项目需求和个人偏好选择适合的方式。
除了@Antowired还有什么?不规范
@Resource:@Resource 注解是 Java EE 提供的一种依赖注入的方式,在 Spring 中也被支持。它可以通过名称或类型来自动装配 Bean。当未指定名称时,默认按照字段名或方法名进行匹配。

@Qualifier:@Qualifier 注解用于与 @Autowired 或 @Resource 注解一起使用,指定具体要注入的 Bean 的名称。当存在多个实现类时,可以通过 @Qualifier 来明确指定要注入的 Bean。

@Inject:@Inject 注解与 @Autowired 类似,也是用于依赖注入的。它可以在 JSR-330(依赖注入 for Java)中使用,与 Spring 的 @Autowired 注解具有类似的功能。

这些注解提供了不同的方式来实现依赖注入,可以根据具体情况选择合适的注解使用。
Mybatis-plus条件构造器有哪些?
MyBatis-Plus(简称 MP)是 MyBatis 的增强工具,在进行条件构造时提供了一系列方便的 API。其中,条件构造器是用于构建 SQL 查询条件的重要组件。以下是 MyBatis-Plus 中常用的条件构造器:
QueryWrapper:用于构建查询条件的条件构造器。可以通过 eq、ne、gt、ge、lt、le、in、notIn、like、notLike、isNull、isNotNull 等方法构建查询条件。

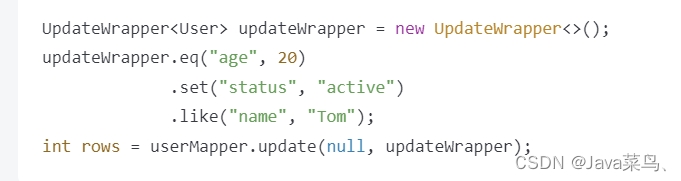
UpdateWrapper:用于构建更新条件的条件构造器。可以通过 eq、ne、gt、ge、lt、le、in、notIn、like、notLike、isNull、isNotNull 等方法构建更新条件。
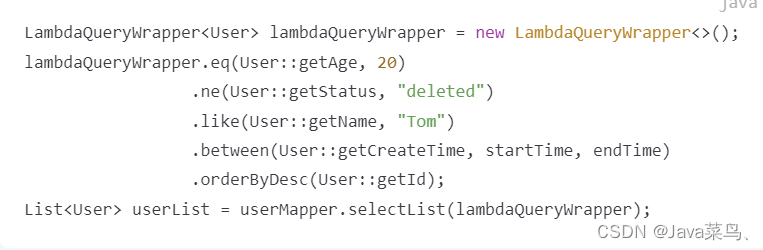
LambdaQueryWrapper:基于 Lambda 表达式的查询条件构造器。使用 Lambda 表达式可以避免手写字段名字符串,提高代码的可维护性和安全性。
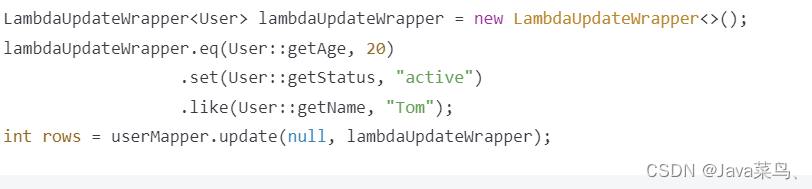
LambdaUpdateWrapper:基于 Lambda 表达式的更新条件构造器。与 LambdaQueryWrapper 类似,使用 Lambda 表达式来构建更新条件。
这些条件构造器提供了灵活且强大的条件构建功能,使得在 MyBatis-Plus 中进行复杂的 SQL 查询和更新操作变得更加简便和高效。
Mybatis-plus怎么样实现自动化构造?
在 MyBatis-Plus 中,实现自动化构造通常指的是自动生成实体类的 CRUD 操作(增删改查)以及对应的 Mapper 接口和 XML 映射文件。MyBatis-Plus 提供了一种基于代码生成器的自动化构造方式,可以根据数据库表结构自动生成实体类、Mapper 接口和 XML 映射文件,大大减少了开发人员的工作量。
以下是使用 MyBatis-Plus 代码生成器实现自动化构造的基本步骤:
-
配置代码生成器参数:在项目的配置文件(如
application.yml或application.properties)中配置代码生成器的参数,包括数据库连接信息、生成包路径、生成文件输出路径等。 -
创建代码生成器:在项目中创建一个代码生成器的启动类,用于配置和执行代码生成器。
-
配置生成策略:可以通过配置策略来控制生成的内容,如是否生成 Controller、Service、ServiceImpl、Entity、Mapper 等。
-
执行生成:运行代码生成器启动类,即可自动根据数据库表结构生成对应的实体类、Mapper 接口和 XML 映射文件。
下面是一个简单的示例,演示如何使用 MyBatis-Plus 代码生成器实现自动化构造:

在这个示例中,我们创建了一个 Spring Boot 应用,并配置了数据源、生成包路径等参数。然后,通过 GeneratorCode 类执行代码生成器。
当应用启动后,代码生成器将会根据数据库表结构自动生成相应的实体类、Mapper 接口和 XML 映射文件,并输出到指定的包路径下。
需要注意的是,自动生成的代码通常需要根据实际需求进行进一步的定制和修改,以满足项目的具体业务需求。
MyBatis-Plus怎么基于实体类自动构造条件?
基于实体类自动构造条件通常指的是根据实体类的属性动态生成查询条件。在 Java 开发中,这种需求经常出现在使用 MyBatis-Plus、Spring Data JPA 等持久层框架进行数据库操作时。
下面是一种常见的方法,可以基于实体类自动构造条件:
- 使用 QueryWrapper(MyBatis-Plus):
MyBatis-Plus 提供了 QueryWrapper 类,可以用于构建查询条件。你可以创建一个 QueryWrapper 对象,并通过其提供的方法动态添加查询条件,其中条件可以基于实体类的属性。

在这个示例中,我们通过 QueryWrapper 构造了一个查询条件,其中使用了 eq 方法添加了一个等值条件(username = "张三"),以及使用了 gt 方法添加了一个大于条件(age > 18)。
通过这种方式,可以根据实体类的属性动态构造查询条件,使代码更加灵活和可维护。 MyBatis-Plus 还提供了许多其他的查询方法和条件构造器,可以根据具体需求选择使用。
MyBatis怎么基于实体类自动构造条件?
在 MyBatis 中,基于实体类自动构造条件可以通过动态 SQL 来实现。通常情况下,可以使用 <where>、<if>、<choose> 等标签结合实体类的属性来动态构造查询条件。
以下是一种基于实体类自动构造条件的示例:
假设有一个实体类 User:

在 MyBatis 的 XML 映射文件中,可以使用 <where> 和 <if> 标签来动态构造查询条件:

在这个示例中,<select> 标签用于定义一个查询语句,其中使用了 <where> 标签来包裹动态条件。每个条件都使用了 <if> 标签,根据实体类的属性是否为空来判断是否添加该条件。如果实体类的属性值不为空,则会添加相应的条件到 SQL 语句中。
在实际使用时,可以根据需要添加更多的条件,并在 SQL 语句中灵活使用动态 SQL 标签来构造条件。这样就能够实现基于实体类自动构造条件的功能。
.Mybatis有了解吗?动态标签
当然了解,MyBatis 是一个优秀的持久层框架,它提供了一种灵活且强大的方式来管理 SQL 查询语句和结果映射。MyBatis 中的动态标签允许我们根据不同的条件来动态生成 SQL 查询语句,这使得我们可以根据实际需求构建灵活的查询。
以下是 MyBatis 中常用的一些动态标签:
<if>:条件判断标签,根据条件动态包含 SQL 片段。
<choose>、<when>、<otherwise>:类似于 Java 中的 switch-case 结构,根据条件选择不同的分支。
<trim>、<where>、<set>:用于处理 SQL 片段的前缀和后缀。
<foreach>:用于迭代集合,生成多个参数的 SQL 片段。
- 这些动态标签使得我们可以更灵活地构建 SQL 查询语句,根据不同的条件生成不同的 SQL 片段,从而满足各种复杂的查询需求。
内连接和左连接的区别
内连接(Inner Join)和左连接(Left Join)是 SQL 中常用的连接类型,它们之间有一些重要的区别:
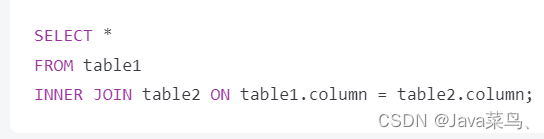
-
内连接(Inner Join):
- 内连接返回两个表中满足连接条件的行。只有当连接条件满足时,才会将来自两个表的行组合在一起返回结果集。
- 如果左表(第一个表)和右表(第二个表)中没有匹配的行,则这些表中的数据不会出现在结果集中。
-
左连接(Left Join):
左连接返回左表中的所有行,以及右表中满足连接条件的行。如果右表中没有匹配的行,则在结果集中显示为 NULL 值。即使右表中没有匹配的行,左表中的行也会被包含在结果集中。

总的来说,内连接返回两个表中交集的行,而左连接返回左表中的所有行,以及右表中满足条件的行,如果没有匹配的行,则为 NULL 值。因此,选择内连接还是左连接取决于你想要的结果集中是否包含左表中没有匹配的行。
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











