






所用stata的版本是2017版
stata严格区分大小写字母,建议变量名使用小写字母,以便阅读。
本文以数据集grilic.dta为例。
1、审视数据
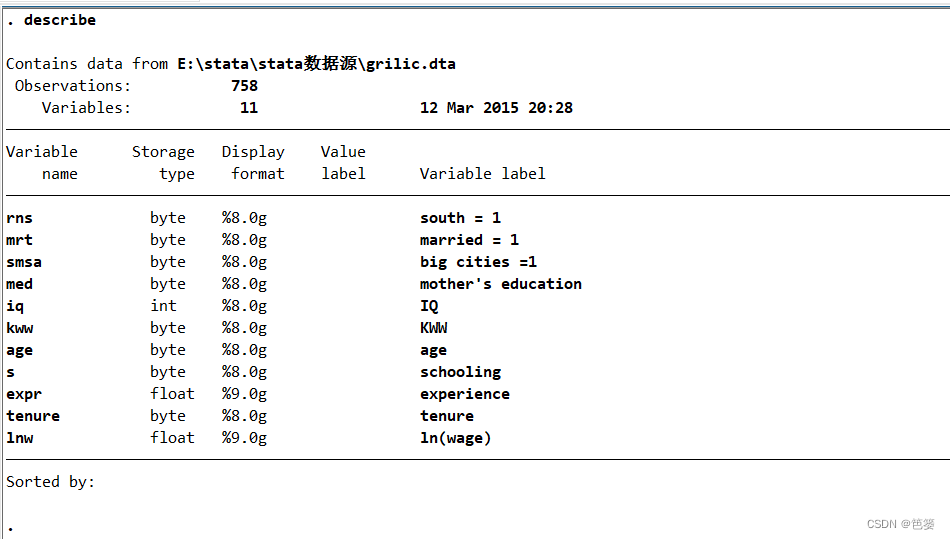
如果想看数据集中的变量名称、标签等,可以输入命令
describe
其中,“describe”的下划线表示,可将该命令简写为“d”
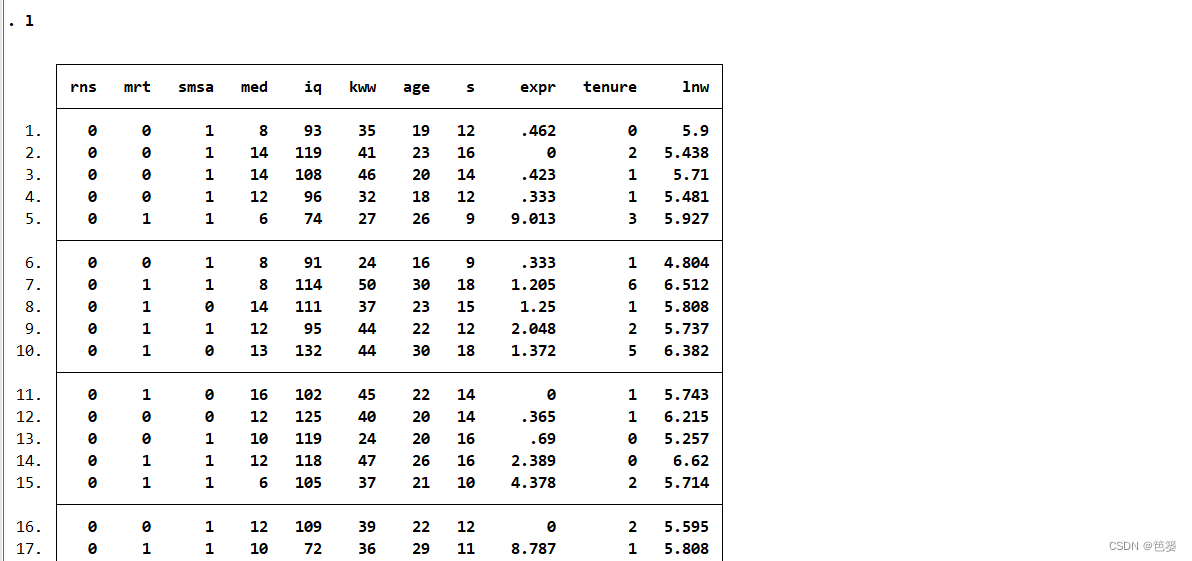
list s lnw
显示变量s与lnw的具体数据

只有“l”则会显示所有变量的数据
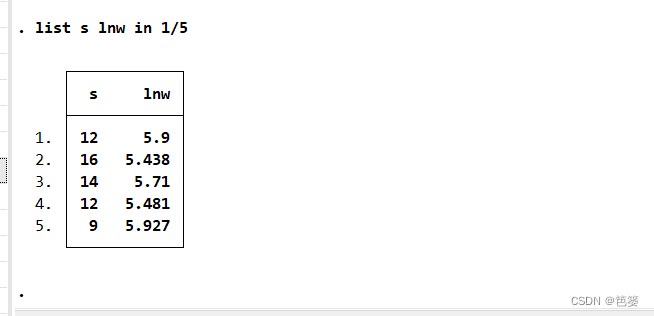
list s lnw in 1/5
如果只想对数据集的一部分子集执行命令,比如只看s与lnw的前5个数据(从1到5),可使用命令。
如果要看从第20到第30个的数据,则用list s lnw in 20/30

如果要看完整的数据,点击Data Editor图标,或者点击Browse图标,二者的区别在于,Data Editor可以看也可以该,而Browse只能看不能改。

如果要删除满足“s>=16" 条件的观测值,可输入命令
drop if s>=16

反之,如果只想保留满足”s>=19"条件的观测值,可使用命令
keep if s>=19
删除观测值之后,Stata不提供撤销,建议慎重删除数据,最好先将原始数据备份。
如果想将变量s的升序排列,可输入命令
sort s
list

在最下面我们发现有一个“more”这是为什么呢?原来是因为数据列表太长了,这一页放不下,那么怎么样才能看到完整的数据呢?接下来我们就要使用一个新的命令
set more off
连续滚屏显示运行结果
set more on
恢复分页显示运行结果
但是我实际操作的时候,惊讶的发现,输入任意都会导致滚屏显示一部分的结果,于是我猜测可能是因为版本不一样导致的。大家可以尝试下自己的会使什么效果。
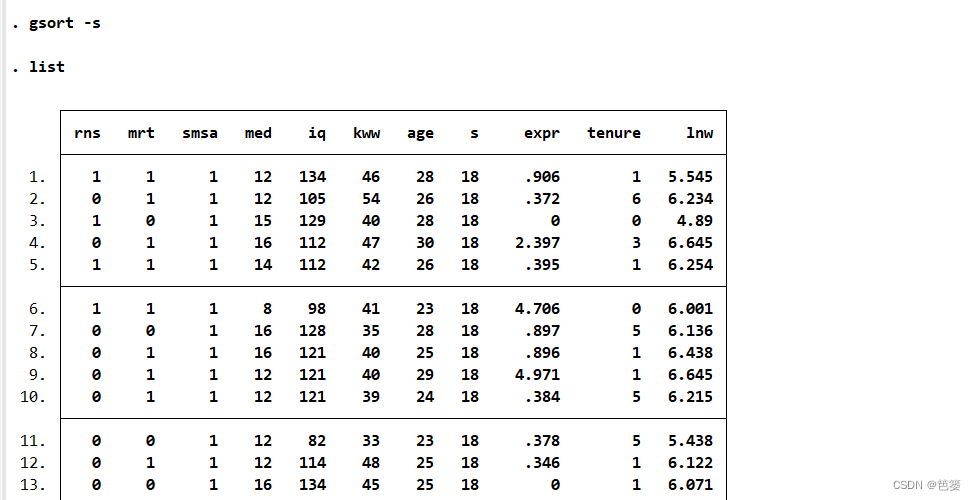
命令sort无法按照变量的降序排列,如果想降序排列可以使用命令
gsort -s
list
2、画图
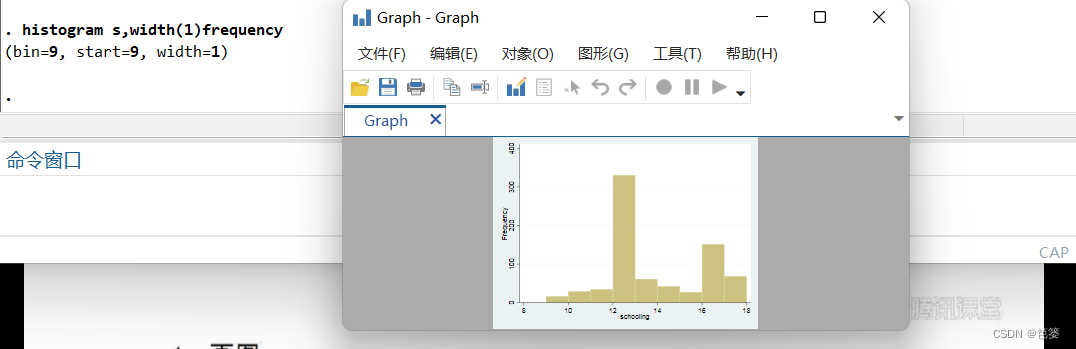
看数据的最直观的方法是画图,想看变量s的分布情况,可输入以下命令画直方图:
histogram s,width(1) frequency
histogram表示直方图
选择项“width(1)”表示将组宽设为1(否则将使用Stata根据样本容量计算的默认分组数),
选择项“frequency”表示将纵坐标定为频数(默认使用密度)。

















 1935
1935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









