









欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
空气质量优劣程度与一个城市的综合竞争力密切相关,它直接影响到投资环境和居民健康,因此越来越受到政府和公众的关注。本项目利用网络爬虫从某空气质量监测网站抓取全国各大城市的历年空气污染数据(PM2.5,PM10,SO2,NO2,CO,O3),对全国各城市(空间维度)不同年度(时间维度)等维度进行空气污染物的统计分析,并利用 Echarts 进行可视化展示。
二、功能
功能主要包括:
三、基于 Python 的全国空气质量监测与可视化分析平台
3.1 登录注册
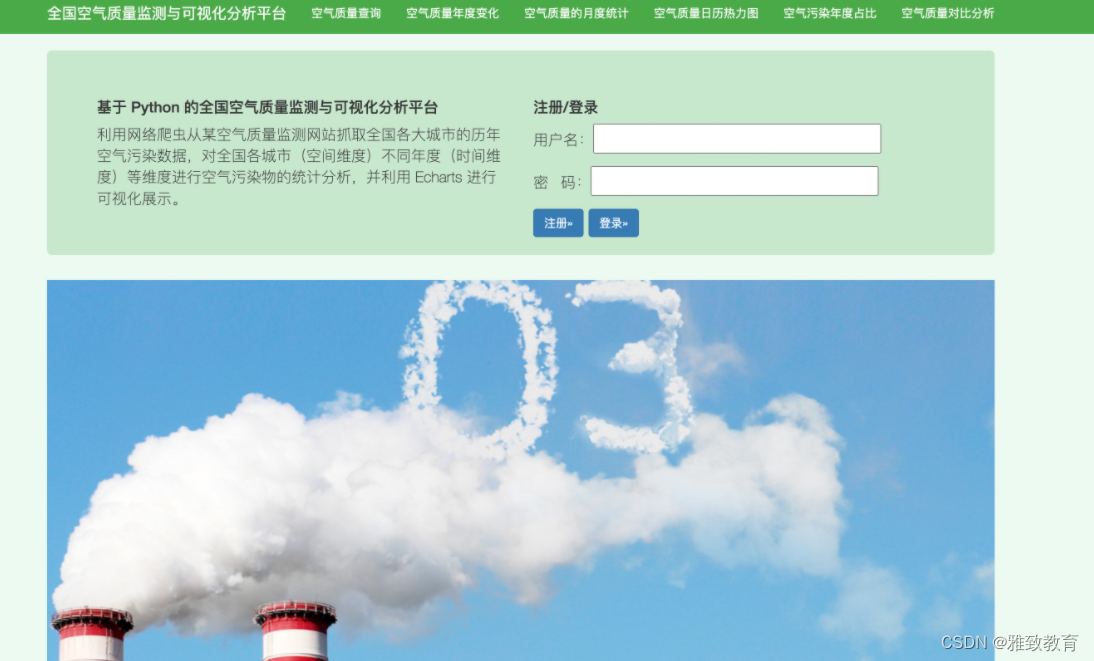
3.2 城市历史空气质量数据查询
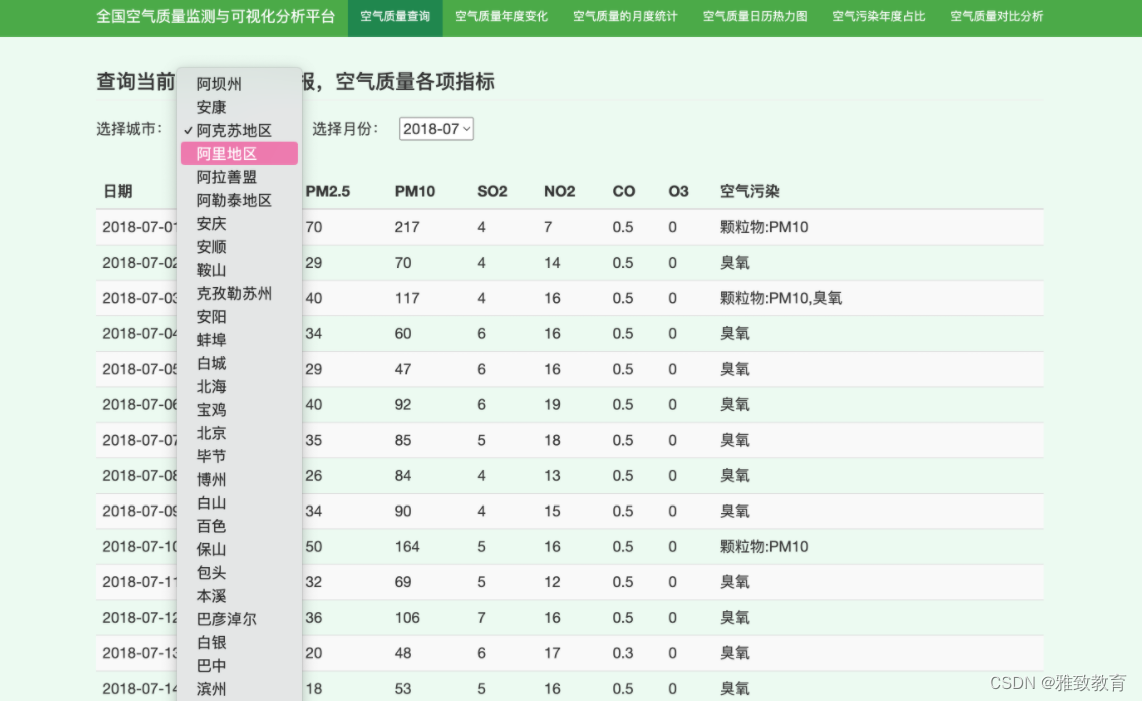
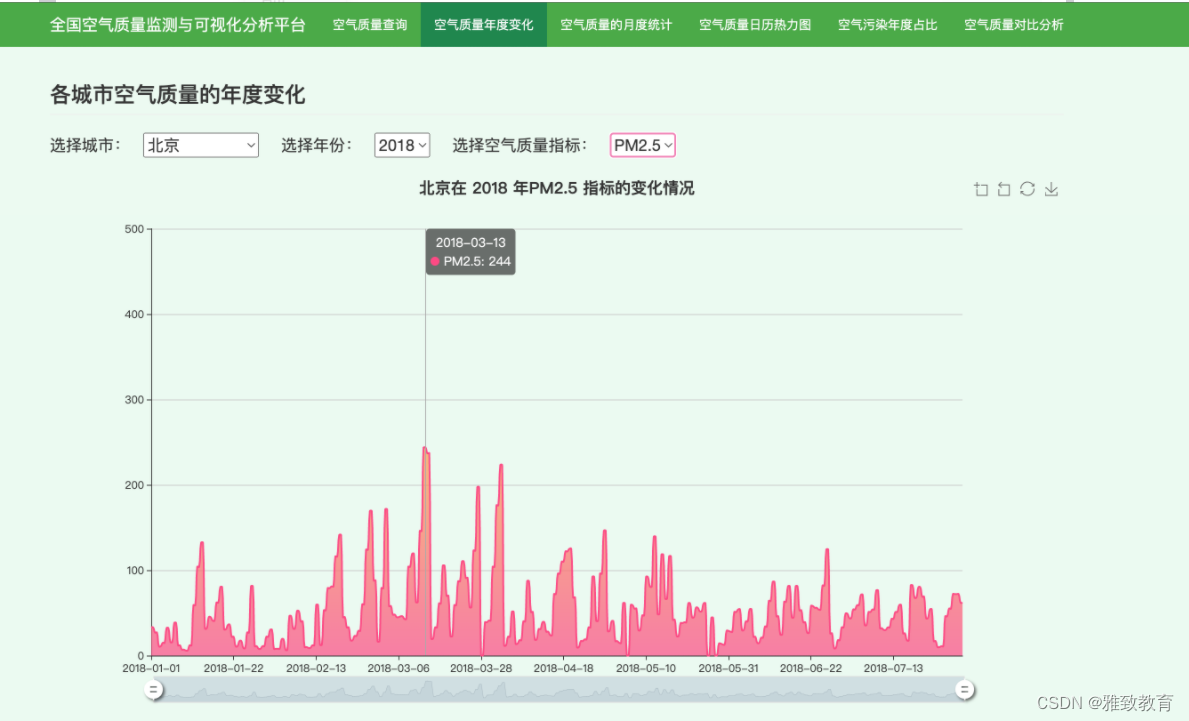
3.3各城市空气质量年度变化分析
通过对某城市某一年份的各类污染物(PM2.5,PM10,SO2,NO2,CO,O3)进行变化分析,分析出一年当中某类污染物的指标走势情况:
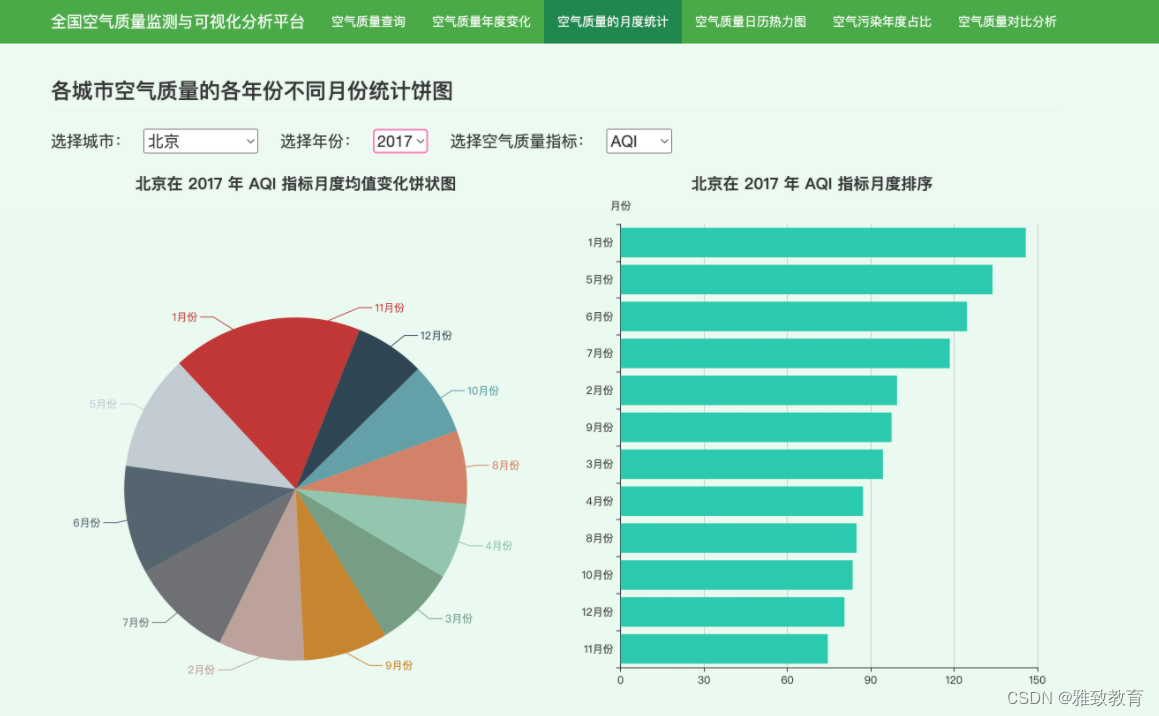
3.4 各城市空气质量年度月份统计
对各城市某一年的各类空气污染指标,按照月份进行分组计算平均污染指数,并绘制柱状图和饼状图,可以直观的发现这些污染物最严重的月份等信息:
def get_city_month_air_quality(city, year, zhibiao):
"""对城市的年度空气指标进行统计,计算平均指标"""
city_df = air_df[(air_df['city'] == city) & (air_df['year'] == year)]
city_df = city_df.sort_values(by='time', ascending=True)
print('数据条目数:', city_df.shape[0])
city_month_df = city_df[['month', zhibiao]].groupby(by='month').mean().reset_index()
city_month_df = city_month_df.sort_values(by=zhibiao, ascending=True)
results = {'月份': ['{}月份'.format(int(r)) for r in city_month_df['month'].values.tolist()],
'均值': city_month_df[zhibiao].values.tolist()}
print(results)
return jsonify(results)
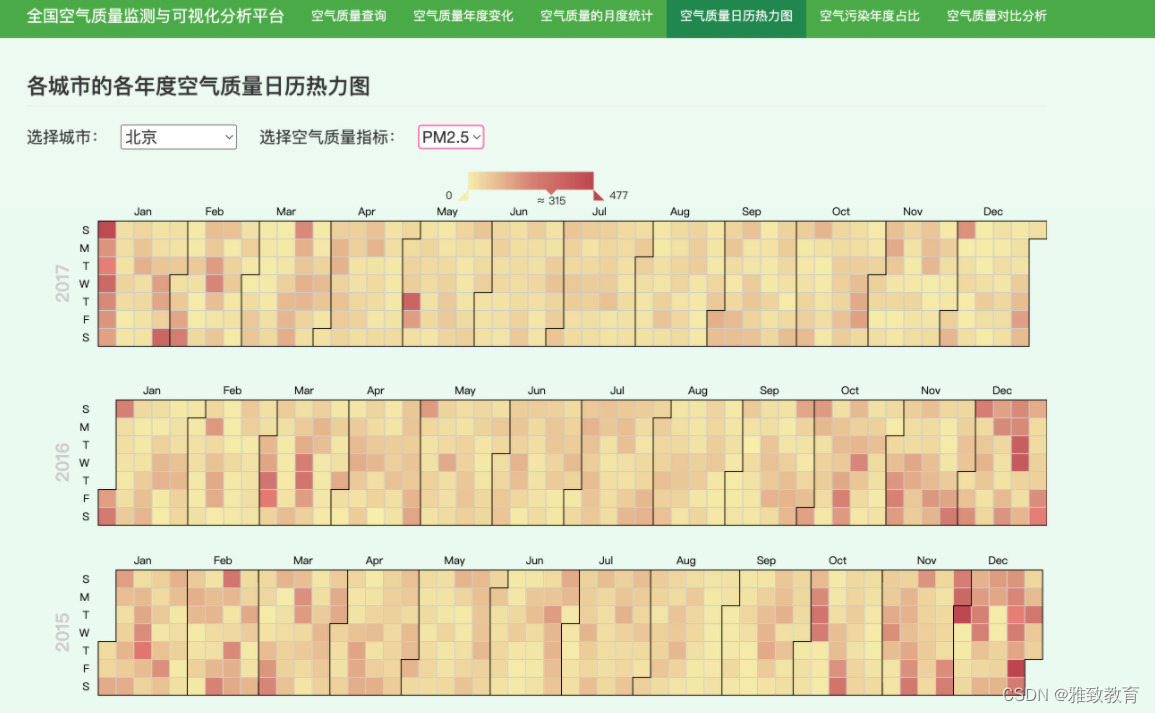
3.5 各城市年度空气质量日历热力图
对各城市每个年份某空气污染物的分布情况,通过对每年的污染情况绘制日历热力图,直观的发现该污染物随时间的变化情况:
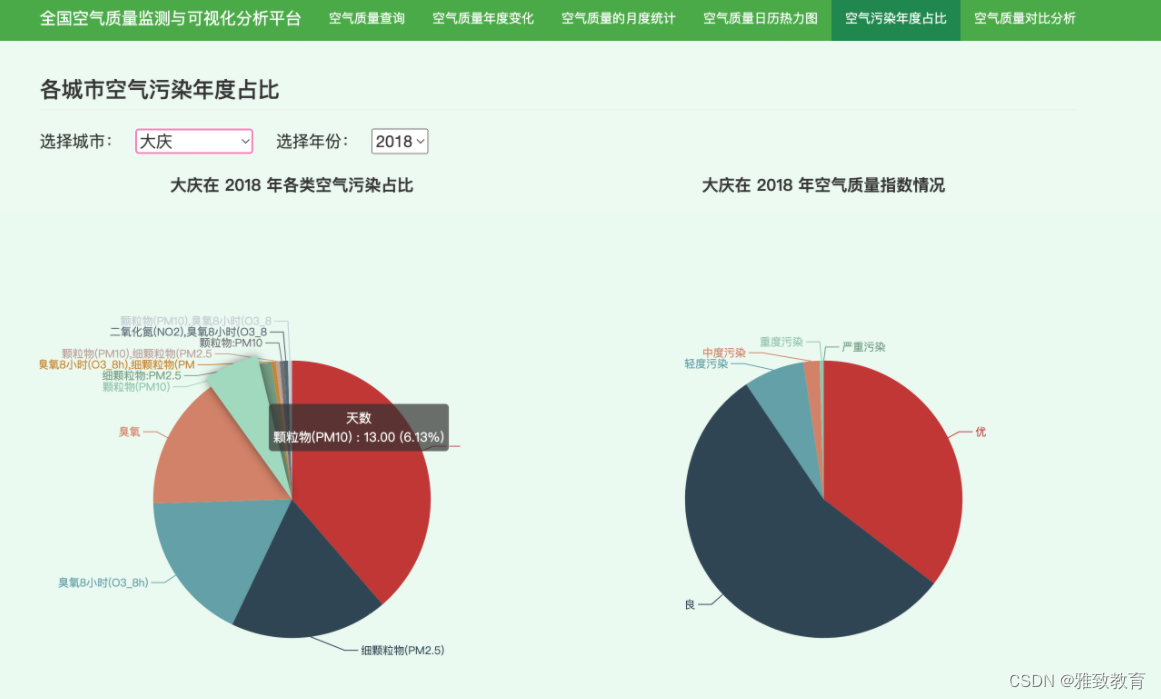
3.6 各城市空气污染物年度占比
计算各城市每年各类空气污染物指数占比情况,可得出影响该城市空气质量的主要污染源有哪些,为空气治理提供依据:
def get_city_polution_data(city, year):
city_df = air_df[(air_df['city'] == city) & (air_df['year'] == year)]
city_df['primary_pollutant'] = city_df['primary_pollutant'].map(lambda x: str(x).replace('-', '良').replace('None', '良'))
pollutants = city_df['primary_pollutant'].value_counts().reset_index()
all_aqis = city_df['AQI'].values.tolist()
air_quality = {'优': 0, '良': 0, '轻度污染': 0, '中度污染': 0, '重度污染': 0, '严重污染': 0}
for aqi in all_aqis:
if 0 <= aqi < 50:
air_quality['优'] += 1
elif 50 <= aqi < 100:
air_quality['良'] += 1
elif 100 <= aqi < 150:
air_quality['轻度污染'] += 1
elif 150 <= aqi < 200:
air_quality['中度污染'] += 1
elif 200 <= aqi < 300:
air_quality['重度污染'] += 1
else:
air_quality['轻度污染'] += 1
air_quality_keys = list(air_quality.keys())
return jsonify({'污染种类': pollutants['index'].values.tolist(),
'数值': pollutants['primary_pollutant'].values.tolist(),
'空气质量': air_quality_keys,
'空气质量数值': [air_quality[k] for k in air_quality_keys]})
四. 空气质量 AQI 数据采集
从某天气监测网站采集全国各大城市的历年空气质量数据,并进行数据清洗和格式化:
......
for city in city_map:
for year_month in year_months:
year_month_line = []
try:
print('爬取{} {} 的AQI数据'.format(city, year_month))
url = 'http://www.xxxx.com/aqi/{}-{}.html'.format(city_map[city], year_month)
response = requests.get(url, timeout=1000)
response = response.text
soup = BeautifulSoup(response, 'lxml')
items = soup.table.find_all('tr')
for i, item in enumerate(items):
if i == 0:
continue
data = item.find_all('td')
# 日期
date = remove_space(data[0].text)
# 质量等级
tianqi = remove_space(data[1].text)
# AQI指数
qiwen = remove_space(data[2].text)
year_month_line.append(','.join([city, date, tianqi, qiwen]) + '\n')
fout.writelines(year_month_line)
fout.flush()
except:
continue
......
五. 总结
本项目利用网络爬虫从某空气质量监测网站抓取全国各大城市的历年空气污染数据(PM2.5, PM10, SO2, NO2, CO, O3),对全国各城市(空间维度)不同年度(时间维度)等维度进行空气污染物的统计分析,并利用 Echarts 进行可视化展示。
————————————————















 6642
6642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









