






1 简介
自然场景下的文本检测可以看作一种特殊的目标检测,在模型的第一步,往往需要生成能够足够覆盖单词或者句子的bounding box。但是不同于真实世界的实体,自然场景的文本角度多变、长短不一、间隔不同,普通的目标检测算法不能很好胜任。所以在目标检测的模型基础上,作者提出了将自然场景文本分解为两个元素:分割 (segment)和连接 (link),二者联立将重复的多尺度字符框连接成单词或者句子。(论文地址:https://arxiv.org/abs/1703.06520)

其工作难点是怎样把分割和连接的思想有效转化为模型结构,并且能在代码层面进行实现。本模型具备以下特点:①分割和连接同时进行,不需要分开训练;②以SSD为基础模型;③多尺度融合;④两种连接类型:层内连接、跨层连接。
2 探究方法
2.1 SegLink模型框架
该网络由卷积特征层(显示为灰色块)和卷积预测器(细灰色箭头)组成。分割和连接只运用在某些层的特征图上,文中共选用了6层。
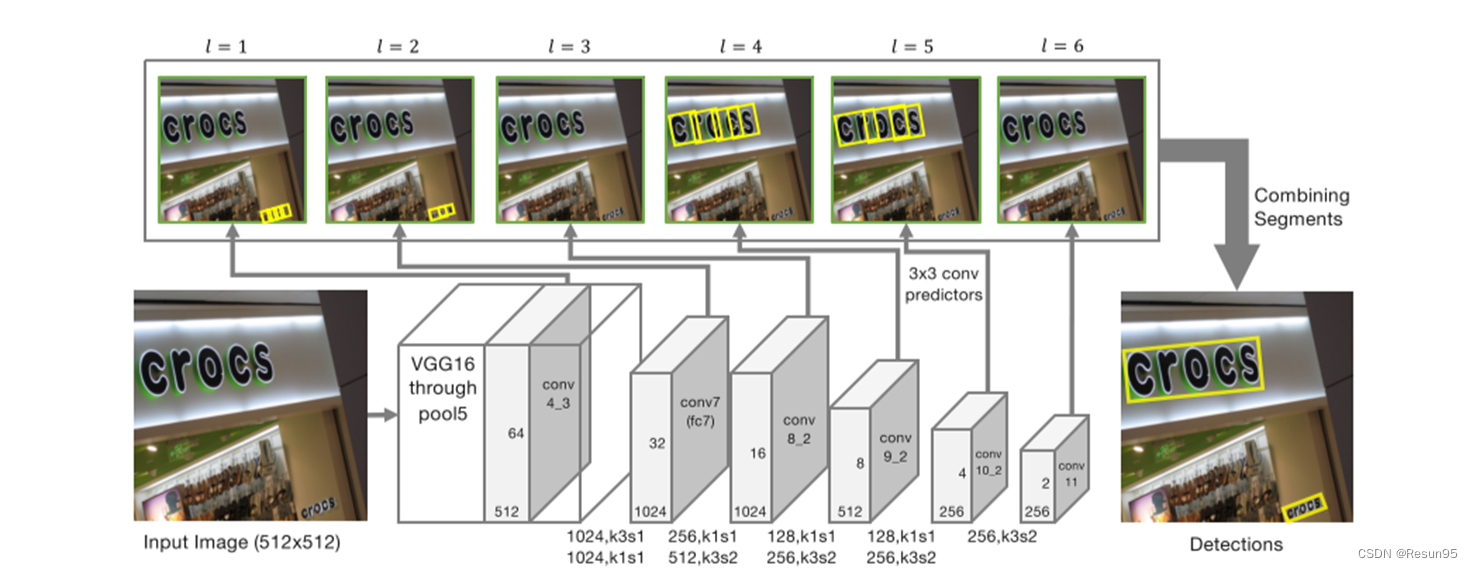
2.2 分段检测
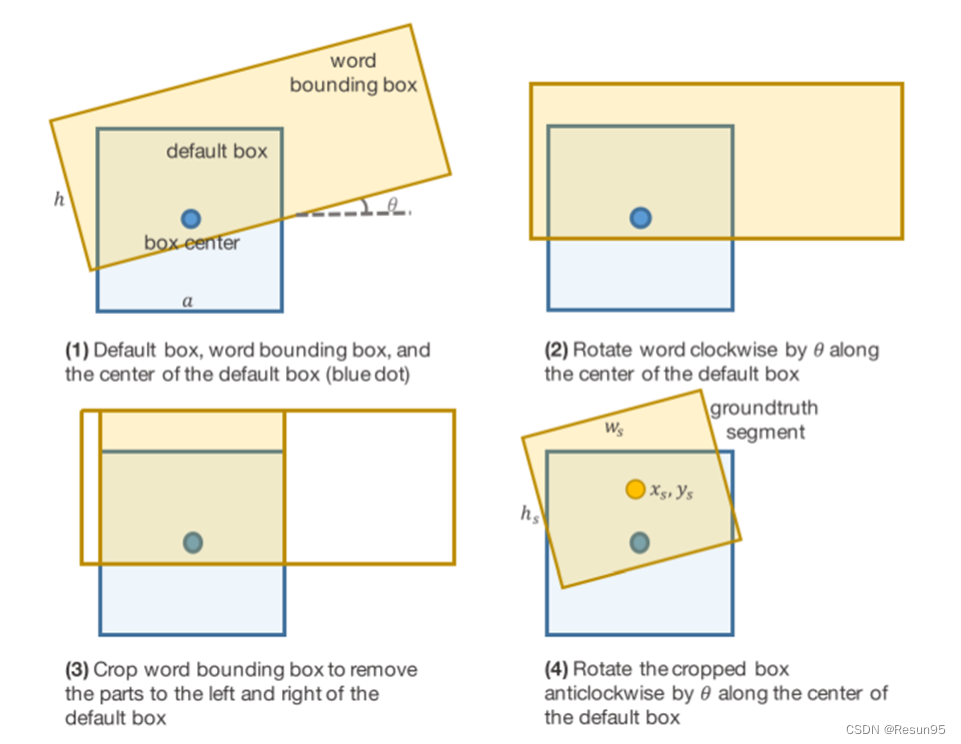
文中的分割并非是指单一的像素级的分割,而是等同回归框检测+特征层像素分割的的分割。采用了SSD框架中的的default boxes,但是特征图的每个位置上只用一个框作为简化。考虑第𝑙个特征层的尺寸为𝑤𝑙×h𝑙,坐标(𝑥,𝑦)对应的default box中心为(𝑥𝑏,𝑦𝑏)。default box的宽度和高度都设置为常量𝑎𝑙 。
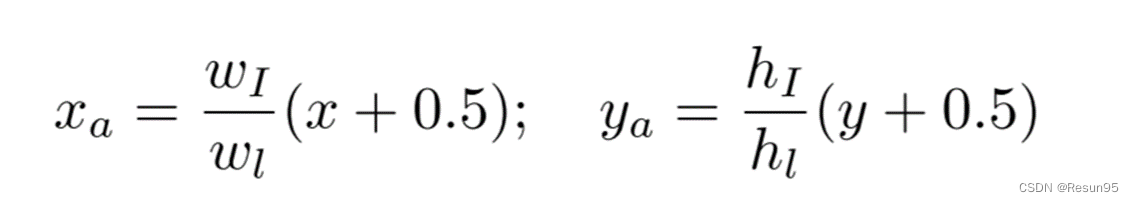
对于特征层上的某个像素点(𝑥,𝑦),检测器得到2个分割的正样本值和负样本值(代表二分类的是否属于文本区域),和5个几何偏移( ∆𝑥𝑠 ,∆𝑦𝑠, ∆𝑤𝑠 , ∆h𝑠, ∆𝜃𝑠 )。根据偏移和默认框计算得到的预测值如下。(𝑎𝑙 =γ(𝑤i/𝑤l),γ=1.5)
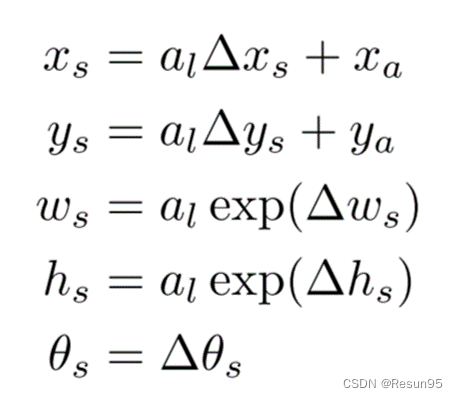
常量𝑎𝑙控制分割输出的尺度,常量𝛾控制尺度的放缩。可以看出𝑥𝑠和𝑦𝑠的表达式是线性偏移,𝑤𝑠和h𝑠的表达式是指数偏移,这是因为坐标和长宽的量级不同。
2.3 连接检测
a图中conv8_2上的一个位置(黄色块)及其8个连接的邻接块(有填充和没有填充的蓝色块)。检测到的层内链接(绿色线)连接同一层上的一个线段(黄色框)及其两个相邻线段(蓝色框)。b图中交叉层链接连接conv9_2上的一个段(黄色框)和conv8_2上的两个段(蓝色框)。
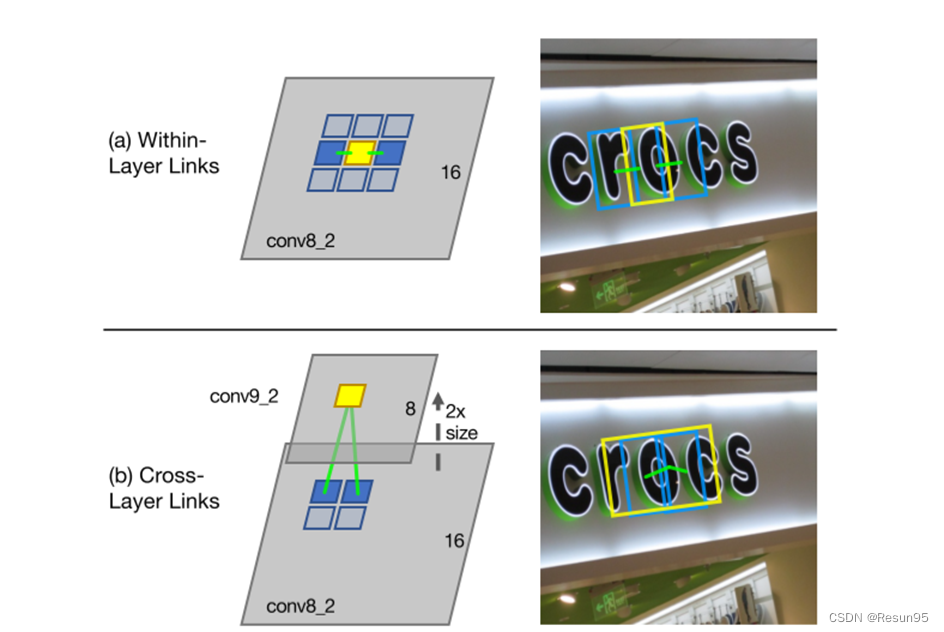
分割检测得到的是字符或字符块,层内连接将一对相邻的分割连接起来,表示二者属于同一个单词。作者认为连接不仅能帮助拼接分割块,还对分离两个相邻单词有益。层内连接的实现是对于特征图每个位置,同样通过卷积得到其与8个相邻位置连接与否的16个值来进行,公式对应图a:
![]()
为了检测不同尺度的文本,在不同层产生的分割框会存在大量冗余。而跨层连接的目的就是为了解决冗余问题,根据不同融合层特征图尺寸缩放为1/4的特性(池化把𝑤和h都减小了1倍)。𝑙层一个位置上对应𝑙−1层的四个像素(𝑙从第二层开始算),所以产生8个值表示与上一层这四个像素的连接,公式对应图b:
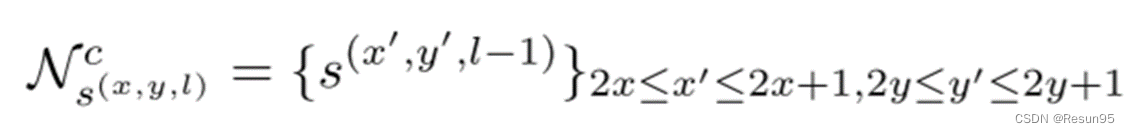
分割和连接需要分别接独立的softmax层,该区块显示了深度为31的𝑤𝑙×h𝑙地图。 𝑙=1的预测器不输出用于跨层链路的信道。卷积层输出格式如下:

2.4 分段与连接的结合
网络的前向推理完将得到分割了连接的输出,将分别过滤后的分割当作点,连接当作边,可以将输出转换为一张图。然后通过深度优先搜索(DFS)来寻找联通成分。每个联通成分包含一个分割集合ℬ,其元素被link连接。集合内的分割框按左图算法组合生成单词。算法思想就是先找到中心点所在的直线,然后通过已有数据生成word-level的中心点、首尾端点、倾斜角、宽高,然后得到一个大的包含整个单词框。

3 训练
该模型核心部分只有分割和连接两个模块,为了适应这两个部分,需要预先对GroundTruths做计算,得到训练样本的分割连接。若图中仅含1个词,默认框被标记为正需要满足:一是框中心在GT内,二是框的大小𝑎𝑙和GT高h满足𝑚𝑎𝑥(𝑎𝑙/h,h/𝑎𝑙)≤1.5,否则都作为负样本。若图中包含多个词,则默认框只要满足以上两点,就被标记为正且对应尺寸最接近的GT。当默认框分别满足以下两点,层内和跨层连接分别被标记为正:相邻俩默认框连接为正,两个默认框对应同一个单词。
该网络模型是通过同时最小化分段分类、偏移回归和链路分类的损失来训练的。分割和连接的损失是分开计算的,所以和一般loss相比重复了一个𝐿𝑐𝑜𝑛𝑓的项, 𝐿𝑐𝑜𝑛𝑓是在预测的分段和链路分数上的softmax损失。总的来说,损失函数是三种损失的加权和:
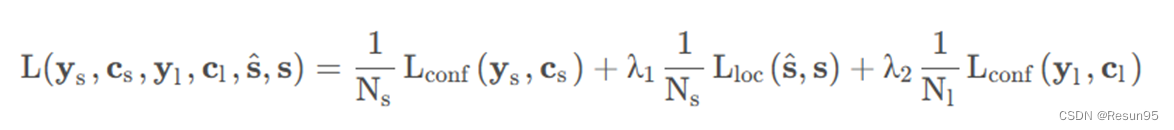
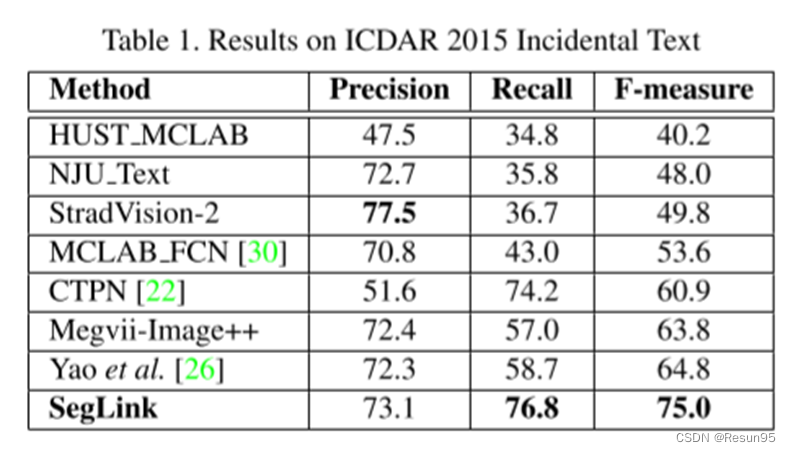
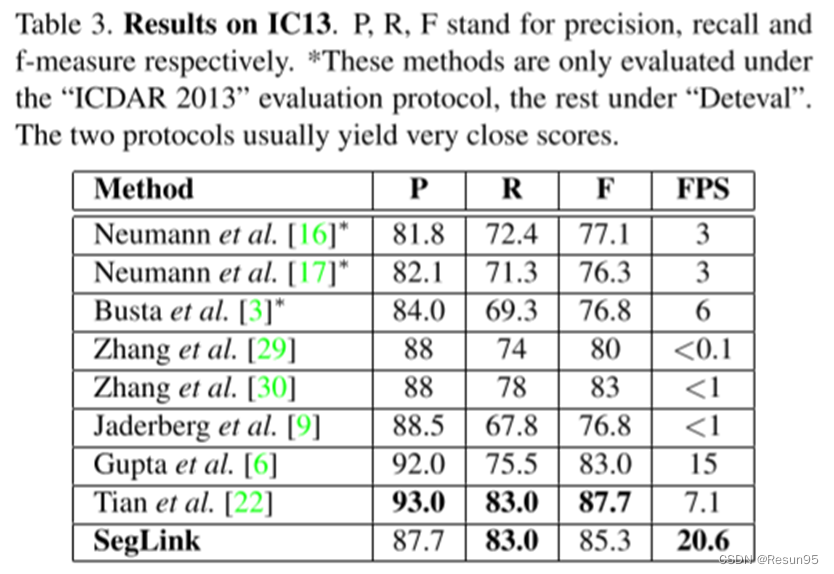
对于片段和链接,否定占据了大部分训练样本。因此,作者为了平衡正样本和负样本需要进行硬负挖掘,它是针对分段和链接单独执行的。基于之前研究提出的在线硬负挖掘策略,以保持负和正之间的比率最多为3:1。作者采用了一种类似于SSD和YOLO的在线增强管道。训练图像被随机裁剪成一个补丁,该补丁与任何GroundTruths单词的Jaccard重叠度𝑜∈(0,0.1,0.3,0.5,0.7,0.9)。该模型的准确度与之前的模型对比如下所示。

4 小结
SegLink的一个主要限制是需要手动设置阈值。在实践中,通过网格搜索来找到阈值的最佳值。简化参数将是未来工作的一部分。另一个弱点是SegLink无法检测到字符间距非常大的文本。SegLink是一种通过简单高效的CNN模型实现的新型文本检测策略。在水平、定向和多语言文本数据集上的卓越性能很好地证明了SegLink的准确性、快速性和灵活性。未来作者将进一步探索其在检测变形文本(如弯曲文本)方面的潜力,此外也可将SegLink扩展到端到端的识别系统中。















 2357
2357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









