






今日复习计划:做复习题
例题1:分糖果
题目描述:
最近暑期特训算法班的同学们表现出色,他们的老师肖恩决定给他们分发糖果。肖恩买了n个不同种类的糖果。用小写的阿拉伯字母表示。每个糖果必须分发给一个同学,并且每个同学至少要分到一个糖果。同学们的开心程度定义为他们所分到的糖果组成的字符串S[i]的字典序。肖恩希望同学们的开心程度相差尽可能小,因此他要找到一种方案,使得所有糖果组成的字符串的字典序中的最大的字符串尽可能小。请输出能使字典序最小可能的max(S[1],S[2],...,S[x])。
输入描述:
第一行输入一个整数n和x,表示有n个糖果和x个同学;
第二行输入一个长度为n的字符串S,S[i]表示第i个糖果的种类。
数据保证:1 <= n <= 10^6, 1<= x <= n, S[i]属于['a','z']。
输出描述:
输出一个字符串,为所有糖果组成的字符串中字典序最大的字符串最小的可能值。
参考答案:
import math
n,x = map(int,input().split())
S = list(input())
S.sort()
S = [''] + S
if S[1] == S[x]:
if S[x + 1] == S[-1]:
print(S[x],end = '')
for i in range(x + 1,math.ceil((n - x) / x) + 1):
print(S[i],end = '')
else:
print(''.join(S[x:]))
else:
print(S[x])运行结果:
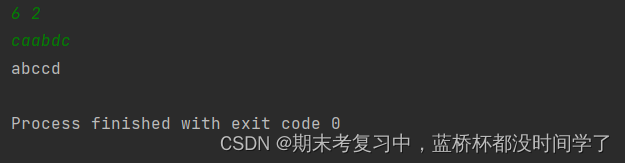
以下是我对代码的理解:
整体来说,首先,代码导入了math模块,并从输入中获取了两个整数n和x,分别表示糖果的数量和同学的数量。接着,从输入中获取了一个长度为n的字符串S,表示每个糖果的种类。然后对字符串S进行排序。
接下来根据逻辑判断进行条件分支:
如果第一个糖果和第x个糖果的种类相同(即S[1] == S[x],那么会进一步判断第x + 1个糖果和最后一个糖果的种类是否相同,即S[x + 1] == S[-1])。如果相同,说明在这个方案下,同学们的开心程度可以达到最小,因此会按一定规律输出糖果的种类。
如果第1个糖果和第x个糖果的种类不相同,则直接输出第x个糖果的种类。
import math:导入了python的math模块
n,x = map(int,input().split()):这行代码从标准输入获取一行包含两个整数的输入,并使用split()方法将其分隔成单独的字符串,然后通过map函数将这些字符串转换为整数类型。最后将两个整数分别赋值给变量n和x。
S = list(input()):这行代码从标准输入获取了一行字符串输入,并使用list函数将其转换为一个字符串列表。这个列表中的每个字符代表了一个糖果的种类。
S.sort():对糖果种类的列表进行排序,以便后续的操作。排序后,糖果种类会按照字母顺序排列。
S = [''] + S:这行代码在排序后的糖果种类列表的开头插入了一个空字符串,这样做的目的是后续方便处理第一个糖果,让它的下标为1。
然后就是判断了,检查第1个糖果和第x个糖果的种类是否相同,如果相同,则进一步判断第x + 1个糖果和最后一个糖果的种类是否相同。如果相同,则按照一定的规律输出糖果的种类,具体地,从第x + 1个糖果开始,依次输出一定数量的糖果种类。
如果不相同,则直接输出从第x个糖果到最后一个糖果的种类组成的字符串。
如果第1个糖果的种类与第x个不相同,则直接输出第x个糖果的种类。
for i in range(x + 1,math.ceil((n - x) / x + 1):使用了math.ceil()函数来进行向上取整操作。这是因为在计算糖果的分配数量时,可能存在除不尽的情况,而向上取值可以确保分配的数量足够覆盖所有糖果,同时尽量保证同学们的开心程度相差尽可能小。因此,为了确保分配的数量够,避免出现不足的情况,选择向上取整是一个合理的选择。
例题2:最小化战斗力差距
题目描述:
小蓝是机甲战队的队长,他手下共有n名队员,每名队员都有一个战斗力值wi。现在他需要将这n名队员分成两组a和b,分组必须满足以下条件:
每个队员都属于a组或b组;
a组和b组都不为空;
战斗力差距最小。
战斗力差距的计算公式为|max(a) - min(b)|,其中max(a)表示a组中战斗力最大的,min(b)表示b组中战斗力最小的。
请你计算可以得到的最小战斗力差距。
输入格式:
第一行一个整数n,表示队员个数;
第二行n个整数w1,w2,...,wn,表示每个队员的战斗力值。
数据范围保证:2 <= n <= 10^5,1 <= wi <= 10^9
输出格式:
输出一个整数,表示可以得到的最小战斗力差距。
参考答案:
import math
n = int(input())
li = list(map(int,input().split()))
li.sort()
res = 1e9
for i in range(0,n - 1):
res = min(res,li[i + 1] - li[i])
print(res)运行结果:
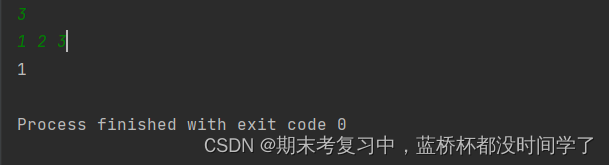
以下是我对代码的理解:
import math:导入了python的math模块
n = int(input()):从标准输入获取一个整数n,表示队员的个数
li = list(map(int,input().split())):从标准输入获取一行整数,使split()方法将其分割成单独的字符串,然后通过map()函数将这些字符串转换为整数类型,并利用list()函数将其转换为一个列表。这个列表li包含了每个队员的战斗力值。
li.sort():对战斗力值列表进行排序,以便后续的操作。排序后,战斗力值会按照从小到大的顺序排列。
res = 1e9:初始化变量res为一个较大的数,这里设置为1e9,目的是为了后续的比较操作中最小的战斗力差距
for i in range(0,n - 1):迭代范围是0到n - 2,即遍历战斗力值列表的前n - 1 个元素
接下来的我都会了,就不写了。
例题3:小蓝的零花钱
题目描述:
小蓝和小桥正在玩一个游戏,他们有一个长度为n的序列,其中既有奇数又有偶数,且奇数和偶数的数量相等。
小蓝有一些零花钱,他可以用这些群来做一个特殊的操作:他们在序列中选取一个位置,然后在这个位置上将序列分成两段,要求每一段中偶数和奇数的数量相等。小蓝想用他的零花钱尽可能地做这个操作,但每次操作都有花费代价。具体而言,每次选取的位置可以看成是对序列的切割,切割需要的代价为切割元素的两端的元素的差的绝对值。小蓝想知道,在他的预算范围内,最多能进行多少次操作。
请你帮助小蓝计算最多能够进行的操作的次数。
输入格式:
第一行包含两个整数n和B(2 <= n <= 100,1 <= B <= 100),表示序列的长度和小蓝拥有的零花钱数;
第二行包含n个整数a1,a2,...,an(1 <= ai <= 100),表示给定的序列(保证在这n个元素中奇数的个数等于偶数的个数)。
输出格式:
输出一个整数,表示在小蓝的预算范围内,能够进行的最多操作次数。
参考答案:
n,B = map(int,input().split())
li = list(map(int,input().split()))
cnt = 0
res = []
for i in range(0,n - 1):
if li[i] % 2 == 0:
cnt += 1
else:
cnt -= 1
if cnt == 0:
res.append(abs(li[i] - li[i + 1]))
res.sort()
tot = 0
for i in res:
if B >= i:
tot += 1
B -= i
else:
break
print(tot)
运行结果:

以下是我对代码的理解:
n,B = map(int,input().split()):从标准输入获取两个整数,分别表示序列的长度和小蓝拥有的零花钱数
li = list(map(int,input().split())):从标准输入中获取一行整数,使用split()方法将其分割成单独的字符串,然后通过map()函数将其转化为整数类型,并使用list()函数将其转换为列表。这个列表li包含了序列中每个位置的元素。
cnt = 0:初始化遍历cnt为0,用于记录当前序列中奇数和偶数的数量差
res = []:初始化一个空列表res,用于存储每次操作的花费代价
for i in range(0,n - 1):这是一个for循环,这里的迭代范围是0到n - 2,也就是前n - 1个元素,因为在判断每个位置的时候,我们需要考虑该位置与下一个位置的情况,而最后一个位置的元素没有与之后的元素形成对比,所以不需要额外考虑。
如果当前位置的元素为偶数,则cnt + 1,否则cnt - 1。这样做是为了统计当前位置之前的奇数和偶数的数量差。
当cnt变为0时,说明当前位置可以将序列分成两段,使得每一段中奇数和偶数的数量相等。此时将当前位置的切割代价(即相邻两元素的差的绝对值)加入到res列表中。
res.sort():对切割代价列表res进行排序,以便后续的操作
tot = 0:初始化变量tot为0,用于记录小蓝在预算范围内能够进行的最多操作次数。
for i in res:迭代切割代价列表res中的每个元素。
如果小蓝的零花钱数B大于等于当前切割代价i,则说明小蓝可以进行这次切割操作,将tot + 1,并从零花钱中扣除代价i。
如果小蓝的零花钱数不足以支付当前的切割代价,则结束循环。
最后输出tot,即小蓝在预算范围内能够进行的最多操作次数。
例题4:第k个数
题目描述:
给定一个整数n,请你在1到n中找出字典序排序后第k个数字。例如:当n为11,k为3时,字典序如下:1,10,11,2,3,4,5,6,7,8,9。因此,第3个数是11。
输入格式:
输入两个整数n和k(1 <= n,k <= 10^9)。
输出格式:
输出一个整数,表示字典序排列后第k个数字。
参考答案:
def findKthNumber(n,k):
cur = 1
k -= 1
while k:
steps = calSteps(cur,n)
if steps <= k:
cur += 1
k -= steps
else:
cur *= 10
k -= 1
return cur
def calSteps(cur,n):
step = 0
cur1 = cur + 1
while cur <= n:
step += min(n + 1,cur1) - cur
cur1 *= 10
cur *= 10
return step
n,k = map(int,input().split())
print(findKthNumber(n,k))运行结果:
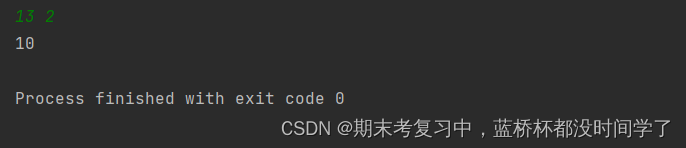
以下是我对此题的理解:
findKthNumber(n,k):这是一个函数,接受两个参数n和k,用于找到字典序排序后的第k个数字。该函数的实现过程如下:
cur = 1:初始化当前数字为1
k -= 1:将k减去1,因为我们将当前数字设置为1,相当于找到了第一个数字
while k:进入一个循环,当k不为0时继续执行
steps = calSteps(cur,n):调用calSteps函数计算当前数字cur到n之间的步数
if steps <= k:如果步数小于等于k,说明第k个数字在当前数字cur的子树中,即当前数字的后继数字中
cur += 1:将当前数字加一
k -= steps:将k减去步数,表示跳过当前数字的子树中的所有数字
else:如果步数大于k,说明第k个数字在与当前数字cur相同的同级数字中(即与当前数字同级的其他数字中)
cur *= 10:将当前数字乘以10,表示向下移动到下一个级别的数字
k -= 1:表示跳过当前数字
return cur:返回找到的第k个数字
calsteps(cur,n):这是一个辅助函数,用于计算当前数字cur到n之间的步数,该函数的实现如下:
step = 0:初始化步数为0
cur1 = cur + 1:将当前数字加一,作为下一个数字
while cur <= n:进入一个循环,当当前数字小于等于n时继续执行
step += min(n + 1,cur1) - cur:将当前数字cur与cur1之间的数字数量加到步数中。这里使用min(n + 1,cur1)时因为如果cur1大于n,即取n + 1,否则取cur1。这样可以确保计算的是当前数字及其后继数字中的有效数字数量。
cur1 *= 10:将cur1向下移动一位,即乘以10
cur *= 10:将当前数字向下移动一位,即乘以10
n,k = map(int,input().split()):从标准输入获取两个整数n和k,分别表示数字序列的最大值和要找的第k个数字
print(findKthNumber(n,k)):调用函数,输出结果。
解决这个题时,首先要理解题目要求,找到给定范围内的数字序列按字典序排序后的第k个数字。
我们可以通过从最小的数字1开始,逐步增加到下一个数字,然后考虑移动到当前数字的下一级(乘以10)或者向右移动到同级的下一个数字(加一),以找到下一个按字典序排序的数字。
具体来说,我们可以通过模拟一个十叉树的遍历来解决这个问题。以n为根节点,1到n为其子节点,通过深度优先搜索的方式进行遍历。在这个遍历过程中,我们会统计当前节点和及其子节点的数量(包括当前节点本身),并不断更新k的值,知道k等于0或者遍历完整个十叉树。
在代码实现中,fineKthNumber()函数实现了这一过程,它使用了一个循环来不断的寻找第k个数字,每次迭代中,通过调用calSteps函数来计算当前节点及其当前子节点的数量。然后根据这个数量和k的关系,决定是移动到下一级的数字还是移动到同级的下一个数字。
而calSteps函数则是用来计算当前节点及其当前子节点的数量。它通过迭代,不断的将当前节点乘以10,统计在不超过n的情况下,当前节点及其后继节点的总数量。
OK,这篇就先写到这里,因为我要做的题还很多,而我的速度有点慢,所以我打算重新写一篇。
下一篇继续!















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









