






擦除是复位操作:擦除将存储单元从“0”状态恢复为“1”状态(即擦除后的单元默认值为全1),而非主动写入1。写入1是通过擦除实现的,而写入0需要电子注入
覆写不可行:Flash不支持“直接覆写”(Overwrite)。若需修改已写入的数据,必须先擦除整个块,再写入新数据。这一限制导致擦除成为性能瓶颈
无法感知文件的语义指文件系统或存储设备仅以原始字节流形式处理文件,缺乏对文件内容逻辑结构(如数据格式、业务含义、上下文关联)的理解能力。具体表现为:
- 无内容结构识别
- 文件系统仅将文件视为二进制序列,无法识别内部结构(如JSON键值对、数据库记录、图像元数据),导致无法针对特定格式优化存储或检索
文件系统语义是文件系统在管理和操作文件时遵循的规则与逻辑保证,定义了文件操作(如读写、修改、共享)的行为规范和一致性要求。其核心作用在于确保多进程、多用户或分布式环境中对文件的访问符合预期,避免数据冲突或逻辑混乱。以下是文件系统语义的主要分类及特点:
- UNIX语义
- 要求所有读写操作基于最近一次对该文件的写操作结果,操作顺序由时间轴严格确定,需借助同步机制(如互斥锁)保证一致性。
- 适用于本地文件系统及低延迟分布式环境,但对网络延迟敏感
就地更新的复杂性:若直接在原物理位置更新数据,需先擦除整个Block,再写入新数据。这一过程包含多个步骤:读取Block内所有有效数据到缓冲区 → 更新目标Page → 擦除原Block → 将缓冲区数据写回新Block。这种操作不仅耗时,还会显著增加写放大(Write Amplification),即实际写入的数据量远大于用户请求的数据量
擦除单位大:NAND Flash的擦除操作以**Block(块)**为基本单位,而一个Block通常包含多个Page(页)。例如,一个Block可能由128个4KB的Page组成,总大小可达512KB至数MB。相较于以Page为单位的读写操作,擦除整个Block需要更长时间。
操作速度慢:擦除操作需要将Block内所有存储单元从“0”状态恢复为“1”状态(即物理擦除)。这一过程的耗时远高于读写操作,典型速度关系为:擦除时间 > 写时间 > 读时间
磨损均衡压力:NAND Flash的每个Block有有限的擦写次数(P/E Cycle),例如SLC约10万次,TLC可能仅数千次。频繁擦除会加速特定Block的损耗,导致寿命缩短。FTL需要通过磨损均衡(Wear Leveling)将擦除操作均匀分布到所有Block,而频繁擦除会增加均衡算法复杂度
坏块风险:擦除操作可能因电压波动或物理损耗导致Block损坏,形成坏块。频繁擦除会提高坏块出现的概率,进一步影响存储容量和可靠性
。传统存储器的数据布局与处理通常 由主机完全负责,存储器本身仅通过块接口与主机进行通信。然而,可计算存储器 引入了一种新的数据处理范式,传统的基于主机的文件系统并不能有效支持可计 算存储进行近数据处理。可计算存储器需要直接读写存储器中的数据,因此理解数 据格式变得尤为重要。为应对这一挑战,现有的可计算存储器数据管理方法大致可 分为四类:应用数据的直接管理[21,43]、基于传统文件系统的管理[8,44–46]、近数据文 件系统[47,48]以及协同文件系统[24,49]。

数据管理机制的挑战:许多可计算存储器[42]为了与现有软件栈兼容,选择使用 文件系统语义进行管理。然而,传统的文件系统以主机为中心,并未考虑如何在可 计算存储器内直接访问文件,这导致在任务卸载时产生冗余开销,并引发一致性问 题

在可计 算存储器读取文件数据时,无法感知主机对文件的修改,可能导致获取到正在写入 的文件,从而引发严重的一致性问题
,研究如何实现存储器内文件的直接访 问和高效的一致性机制成为关键。这不仅能提升数据处理速度,还能确保在并发操 作下的数据一致性和可靠性,从而支持高效、可靠的存储器内文件访问和处理


地址映射、垃圾回收、请求解 析与调度以及计算
地址映射:也称为闪存转换层(Flash Translation Layer, 简称FTL)。由于 闪存固态盘由多个独立的闪存芯片构成,形成多个物理地址空间,FTL负责将这些 地址整合为统一的逻辑地址空间。
为避免高昂的擦除开销,FTL 采用异地更新策 略,即将更新数据写入新的物理位置,并更新地址映射表,使逻辑地址指向新的物 理地址;
垃圾回收:异地更新会导致闪存块中无效页逐渐累积,需要擦除以释放存 储空间。在此之前,有效数据会被转移到其他块,更新映射表后再进行擦除操作;
请求解析与调度:用户的I/O请求被解析为一系列近数据任务,如对多个 闪存芯片的读任务和DMA传输任务。由于缺乏操作系统支持,主控通常采用简单 的调度算法(如先来先服务策略),而在可计算存储器中,NDP 请求的复杂度更 高,包含具有更加复杂依赖关系的更多子任务,简单的调度算法将会导致性能下降; ④ 计算:虽然主控芯片计算能力较弱,但在某些计算需求较低的应用中,主 控芯片也可承担数据处理任务[15,33,34]。然而,由于主控芯片无法进行进程切换,若 计算时间过长,可能导致任务阻塞,影响其他操作的处理。
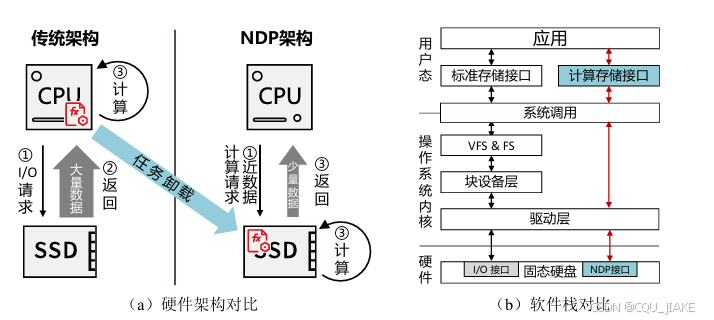
软件栈冗长:以Linux系统为例,应用发出的I/O请求需要依次经过标准 系统接口(Portable Operating System Interface,简称 POSIX)、系统调用、虚拟 文件系统(Virtual File System,简称 VFS)、文件系统(File System,简称FS)、块设备层和驱动层等,才能最终访问存储器,如图1.2(b)所示。冗长的 存储栈降低了访存效率,增加了软件开销
存储性能利用率低:闪存固态盘内部往往拥有多个闪存芯片和读写通 道,在并发读写时可提供极高的带宽。然而,由于接口限制,内部带宽难以充分 发挥
通过添加额外的计算单元和请求控制逻辑构建而成
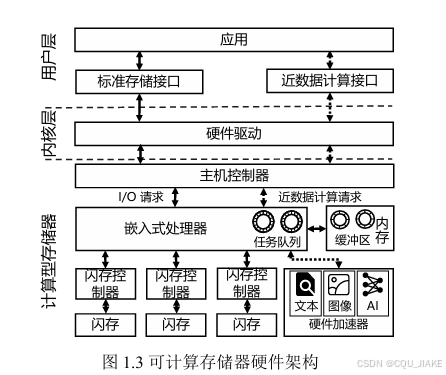
主机控制器用于与主机进行通信,包括接收 NVMe(Non-Volatile Memory Express)请求、使用DMA(Direct Memory Access,直接内存访问)传输数据、管 理主机请求队列和返回请求结果等
闪存芯片(通常为NAND Flash)是闪存固态盘中用于持久化存储数据的核心 单元。闪存芯片逻辑上划分为多个层级,最小的读写单元为页(Page),大小通常 为4KB至32KB[30]。闪存具有"先擦后写"的特性,即在写入一个Page之前,必须 先对包含该Page的块(Block)进行擦除。一个Block通常由数十个Page组成。 成千上万的闪存单元根据特定排布规则构成了闪存芯片。闪存芯片通常并不直接 连接到嵌入式处理器,而是通过闪存控制器(NAND Flash Controller,简称NFC) 与其通信。
闪存控制器接收包含读写和擦除的操作指令,并将其转化为底层的控制 操作,免去了嵌入式处理器处理复杂的闪存时序控制。一个闪存固态盘通常包含2 至8个闪存控制器(也称为闪存通道),通过这些通道与多个闪存芯片并发读写操 作,闪存固态盘可提供相比机械硬盘更高的性能且易于扩展
即仅保存非零元素的值(在数组V中)以 及这些元素的位置(在数组C中)

构造临时数组tmp(标记非零元素)
- 规则:若原数组A[i] ≠ 0,则tmp[i] = 1;否则tmp[i] = 0。
并行前缀求和(确定非零元素的位置)
- 目的:通过前缀求和,将tmp转换为每个非零元素在V中的目标位置。
- 操作:对tmp数组执行并行前缀求和(类似累加,但并行完成)。
先是并行地去遍历A,得到一个1,0构成的tmp数组
然后再并行地对tmp求前缀和
然后再并行遍历的是A,遍历A,如果发现A不是0,那么就在V数组的tmp[i]上写入A
以及,将i写入到C数组的tmp[i]上
度:网络的度(Degree)是指所有节点中邻居数目的最大值
对分宽度(Bisection-width):指一个边集合的最小数目,使得当这些边从网 络中移除后,网络分类为尺寸相等的两个不连通部分
直径:指任意2个节点之间全部最短路径中的最大值
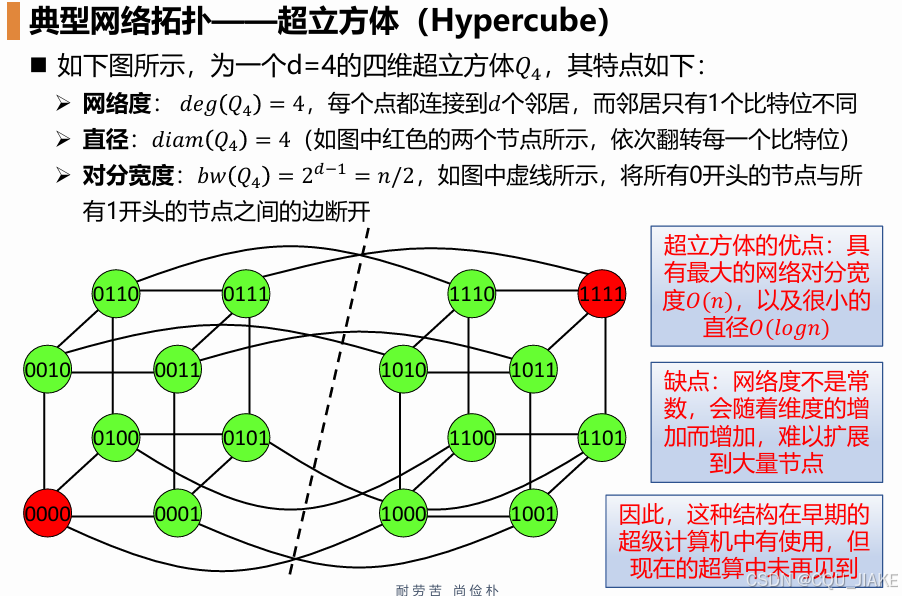
超立方体的度,就是用二进制量化其结点坐标后,每个点的每个坐标都反转一下就是,所以它的度就是logn
超立方体网络的节点扩展机制主要依赖于维度(n)的增加,但其扩展方式并非绝对局限于物理维度的直接提升。以下结合搜索结果,从节点数量与维度的关系、扩展灵活性及应用场景适配性三个方面展开分析:
1. 节点数量与维度的固定关系
-
基本规则:
根据超立方体的定义(网页1、网页3),n 维超立方体(Qn)的节点数量严格为 2n2n。例如:- 1 维(Q1):2 节点
- 2 维(Q2):4 节点
- 3 维(Q3):8 节点
这一规律源于超立方体的递推构造规则 Qn=K2×Qn−1Qn=K2×Qn−1,即每增加一维度,节点数翻倍
固定性体现:
每个维度的超立方体节点数量是严格确定且不可调整的。例如,无法在 3 维超立方体中仅增加 1 个节点而不破坏其拓扑结构,必须提升至 4 维(16 节点)才能实现扩展
(a) 测试基准(Benchmark)
Graph500排名使用的测试基准是 Graph500 Benchmark,该基准专注于评估超级计算机在数据密集型应用中的性能,尤其是针对图计算任务。核心测试包括以下步骤
5
6
10
:
- 生成大规模随机图:基于R-MAT算法生成无向图,顶点数为2SCALE2SCALE,边数为16×2SCALE16×2SCALE,确保数据分布无局部性。
- 构造图结构(Kernel1):将边列表转换为高效存储的数据结构(如邻接表或压缩稀疏矩阵)。
- 执行图算法:
- 广度优先搜索(BFS,Kernel2):随机选择64个搜索键,生成有效的搜索树。
- 单源最短路径(SSSP,Kernel3):计算每个顶点的最短路径。
- 性能指标:以 每秒遍历边数(TEPS) 作为主要指标,定义为 TEPS=MtTEPS=tM,其中MM为边数,tt为算法执行时间。
该基准旨在反映超级计算机在复杂关联数据处理(如社交网络分析、生物信息学)中的实际性能
7
10
。
(b) 顶级系统的实测性能与配置
根据2024年最新Graph500排名,中国“天河”新一代超级计算机在 Big Data Green Graph500(大数据能效)和 Small Data Green Graph500(小数据能效)两个榜单中均位列第一,具体表现如下
1
2
3
8
:
Big Data Green Graph500(大数据能效)
- 系统:“天河”新一代(国家超算天津中心)
- 性能功耗比:6320.24 MTEPS/W(每瓦特每秒百万次操作)
- 配置:
- 硬件:基于国产处理器,采用异构计算架构(CPU+加速器),支持高带宽内存和低延迟互连网络。
- 软件优化:研发了TianheGraph图计算优化系统,通过深度图压缩、拓扑感知通信等技术提升效率。
- 应用领域:无人机路径规划、药物筛选、城市风场仿真等。
Small Data Green Graph500(小数据能效)
- 系统:“天河”(国家超算长沙中心)
- 性能功耗比:22301.67 MTEPS/W
- 配置:
- 硬件:国产处理器结合高效能互联网络,支持高并行度的数据密集型任务。
- 算法创新:面向国产处理器的分布式图计算算法,减少通信开销。
- 应用领域:金融风险分析、社交网络挖掘、实时推荐系统。
(c) Graph500与TOP500的优缺点对比
优点
-
更贴合实际应用场景:
- Graph500针对数据密集型应用(如AI、大数据分析)设计,反映超算在复杂关联数据处理中的性能,而TOP500仅关注浮点运算能力(HPL测试),适用于传统科学计算(如气候模拟、核物理)
6
10
。 - 测试指标(如TEPS)直接衡量内存访问效率和通信性能,更符合现代应用需求(如社交网络、生物信息学)
5
7
。
- Graph500针对数据密集型应用(如AI、大数据分析)设计,反映超算在复杂关联数据处理中的性能,而TOP500仅关注浮点运算能力(HPL测试),适用于传统科学计算(如气候模拟、核物理)
-
强调能效与实用性:
- Green Graph500榜单引入 性能功耗比(MTEPS/W),推动超算向节能方向发展,弥补了TOP500仅强调峰值算力的不足
2
3
8
。 - 支持异构计算架构(如GPU加速),更贴近实际系统设计趋势
5
10
。
- Green Graph500榜单引入 性能功耗比(MTEPS/W),推动超算向节能方向发展,弥补了TOP500仅强调峰值算力的不足
-
多样性评估:
- Graph500包含多个子榜单(如大数据、小数据、能效),提供多维性能视角,而TOP500仅基于单一HPL测试排名
1
8
。
- Graph500包含多个子榜单(如大数据、小数据、能效),提供多维性能视角,而TOP500仅基于单一HPL测试排名
缺点
-
测试范围较窄:
- Graph500仅聚焦图计算任务,无法全面反映超算在传统科学计算(如流体力学、量子化学)中的性能
6
10
。 - 对硬件架构的普适性要求较低,可能忽略某些优化方向(如浮点运算专用加速器)。
- Graph500仅聚焦图计算任务,无法全面反映超算在传统科学计算(如流体力学、量子化学)中的性能
-
数据生成与算法局限性:
- 基于R-MAT生成的随机图与实际应用中的真实图结构(如社交网络幂律分布)存在差异,可能影响测试结果的代表性
5
10
。 - BFS和SSSP算法仅为图计算的子集,无法覆盖所有图算法(如社区发现、图神经网络)的复杂性
5
。
- 基于R-MAT生成的随机图与实际应用中的真实图结构(如社交网络幂律分布)存在差异,可能影响测试结果的代表性
-
国际影响力待提升:
- Graph500排名历史较短(始于2010年),厂商和用户对其关注度低于TOP500
6
10
。 - 部分国家(如中国)因未提交数据导致榜单覆盖不全,削弱了全球代表性
1
3
。
- Graph500排名历史较短(始于2010年),厂商和用户对其关注度低于TOP500
总结
Graph500通过聚焦数据密集型应用和能效指标,成为TOP500的重要补充,但其测试场景的局限性及国际参与度仍需改进
5
6
10
。中国“天河”超算在Graph500中的持续领先,体现了其在软硬协同优化和图计算领域的突破
2
3
8
。
question
final
依据网站,截至2024年11月,Graph500四大榜单(Green Small Data、Green Big Data、BFS、SSSP)如下所示:
1. GreenGraph500 Small Data(小数据能效榜单)
- 排名第一:Tianhe-HNU(国家超级计算长沙中心/湖南大学联合研发)
- 能效比:22,301.67 MTEPS/W(每瓦特百万遍历边数)
- 硬件配置:
- 节点数:1节点(单节点优化)
- 核心数:64核(推测基于国产飞腾或ARM架构低功耗处理器)
- 功耗:82.73瓦(极低功耗,面向轻量级图计算)
- 性能指标:
- Scale 26(图规模,约6.7亿顶点)
- GTEPS:1845.02(每秒十亿遍历边数)
2. GreenGraph500 Big Data(大数据能效榜单)
- 排名第一:Tianhe Exa-node Prototype(国家超级计算天津中心)
- 能效比:6,320.24 MTEPS/W
- 硬件配置:
- 节点数:1节点(原型验证机)
- 核心数:64核(推测为混合架构,如CPU+国产加速器)
- 功耗:167瓦(较Small Data场景更高,但能效仍领先)
- 性能指标:
- Scale 30(图规模,约10.7亿顶点)
- GTEPS:1,055.48
3. BFS(广度优先搜索榜单)
- 排名第一:Supercomputer Fugaku(日本理化学研究所)
- 性能指标:
- GTEPS:204,068(每秒20.4万亿边遍历,历史性突破)
- Scale 43(图规模,约8.6万亿顶点)
- 计算时间(C_time):6,788.46秒(近2小时)
- 硬件配置:
- 处理器:Fujitsu A64FX(ARM架构,集成HBM2内存)
- 节点数:152,064节点(全球最大规模部署之一)
- 核心数:729.9万核
- 网络:Tofu Interconnect D(专为大规模并行优化)
- 性能指标:
4. SSSP(单源最短路径榜单)
- 排名第一:Wuhan Supercomputer(华中科技大学/武汉超算中心)
- 性能指标:
- GTEPS:15,335.9(每秒1.5万亿边处理)
- Scale 41(图规模,约2.2万亿顶点)
- 构造时间(construction time):16,285秒(约4.5小时)
- 硬件配置:
- 处理器:华为鲲鹏920(ARM架构)+ NVIDIA Tesla A100 GPU(混合计算)
- 节点数:252节点
- 核心数:699.9万核(含GPU流处理器)
- 内存:584,640 GB(约584 TB)
- 性能指标:
优点
-
侧重实际应用
-
测试图计算(BFS/SSSP),贴近社交网络、AI推理等数据密集型任务,弥补TOP500仅测浮点运算(Linpack)的局限。
-
-
能效导向
-
Green榜单引入能效比(MTEPS/W),推动低功耗设计;TOP500仅关注峰值性能(PFlops)。
-
-
异构计算适配性
-
鼓励CPU+加速器混合架构优化,更适合现代大数据场景;TOP500早期偏向纯CPU性能堆叠。
-
缺点
-
测试覆盖窄
-
仅两类算法(BFS/SSSP),无法全面反映传统科学计算(如流体力学、气候模拟)能力。
-
-
标准化不足
-
图算法实现差异大(如数据分区策略),可比性弱于TOP500的标准化Linpack测试。
-
-
影响力有限
-
TOP500仍是超算“黄金标准”,Graph500受众较窄,部分系统优化针对性过强(如牺牲扩展性换能效)。
-
优点
- 侧重实际应用:测试图计算(BFS/SSSP),贴近社交网络、AI推理等数据密集型任务,弥补TOP500仅测浮点运算(Linpack)的局限。
- 能效导向:Green榜单引入能效比(MTEPS/W),推动低功耗设计;TOP500仅关注峰值性能(PFlops)。
- 异构计算适配性:鼓励CPU+加速器混合架构优化,更适合现代大数据场景;TOP500早期偏向纯CPU性能堆叠。
缺点
- 测试覆盖窄:仅两类算法(BFS/SSSP),无法全面反映传统科学计算(如流体力学、气候模拟)能力。
- 标准化不足:图算法实现差异大(如数据分区策略),可比性弱于TOP500的标准化Linpack测试。
- 影响力有限:TOP500仍是超算“黄金标准”,Graph500受众较窄,部分系统优化针对性过强(如牺牲扩展性换能效)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









