







5
假设read_document函数可以实现读取第m个文件,并返回该文本文档的每行数据
那么考虑双层并行结构,外层为文档级并行,内层为每个文档内的行级并行
动态分配文档任务,避免线程闲置
#include <omp.h>
int total_words = 0;
#pragma omp parallel reduction(+:total_words) // 开启并行区域并声明归约变量
{
#pragma omp for schedule(dynamic) // 动态分配文档任务
for (int doc_id = 0; doc_id < m; doc_id++) {
vector<string> lines = read_document(doc_id); // 线程独立读取文档
int local_count = 0;
// 行级并行
#pragma omp parallel for reduction(+:local_count) // 内层并行统计行内单词
for (auto &line : lines) {
vector<string> words = split_line(line);
local_count += words.size();
}
total_words += local_count; // 归约合并到全局计数器
}
}
4
OpenMP提供了三种主要的循环任务调度机制,分别为静态调度(static)、动态调度(dynamic)、引导式调度(guided)。这些机制通过schedule子句指定
以for (int i = 0; i < 100; i++)为例
静态调度schedule(static [, chunk_size])在编译阶段预先将循环迭代划分为大小相等的块(默认块大小为总迭代数/线程数;若指定chunk_size,则每次分配chunk_size个连续迭代),每个线程分配固定数量的迭代:为schedule(static,5)时,就是编译时循环分配,线程0处理0-4,25-29....线程1处理5-9,30-34....每个线程要处理的迭代都是固定好的;
其优点为:开销较低,分配策略预先确定,运行时无需动态调度;缓存友好,连续迭代的分配有利于数据局部性优化。缺点为若迭代执行时间差异大(如循环体内计算量不等),可能造成线程空闲或等待,造成负载不均衡。
动态调度schedule(dynamic [, chunk_size])运行时动态分配迭代块(默认块大小为1,也可指定chunk_size),线程完成当前任务后从队列中获取新块。为schedule(dynamic,5)时,与静态调度相比,当线程0完成0-4迭代后,还没分配完线程1,2,3,4时,就可能从当前正要分配的位置分配一个块给线程0,然后其它线程再从后面分配。这样每个线程要处理的迭代数量是不固定的,和迭代的计算量,时间差异有关。
其优点为:负载均衡,适应迭代执行时间差异大的场景,减少线程空闲,计算资源利用率高。缺点为:开销高,动态分配需维护任务队列,增加运行时同步成本,且缓存不友好,迭代分配不连续,可能降低数据复用率。
引导式调度schedule(guided [, chunk_size])初始分配较大的迭代块,后续块大小逐渐减小(指数级递减,默认最小块大小为1,可通过chunk_size指定下限)。为schedule(guided,2)时,初始块可能分配64,后续就逐步减少32,16这样,最小为chunk_size,即2。
其特点是静态与动态调度的一个折中,即早期大块减少调度开销,后期小块优化负载均衡;也意味着是参数敏感的方法,需通过实验调整chunk_size以平衡开销与负载
此外还有两类特殊的,分别为运行时调度schedule(runtime)以及自动调度schedule(auto);运行时调度就是类似于宏或者环境变量,不直接修改程序代码,而是通过修改环境变量OMP_SCHEDULE来确定(如export OMP_SCHEDULE="dynamic,5"),实际上用的调度策略还是其它的。而自动调度就是完全交给编译器或运行时库自动选择,通常基于硬件特性和循环结构。
3
nowait子句用于消除隐式同步屏障,允许线程在完成当前并行块后立即执行后续代码,而无需等待其他线程。以上一题的parallel for为例,指令结束时会有隐式屏障(所有线程必须同步后才能继续),而nowait就可以取消这一屏障,减少线程空闲时间。但是这需要后续代码不依赖并行块内的共享变量,否则可能导致竞态条件
collapse子句可以合并嵌套循环为单层循环,collapse(n)指定合并的嵌套层数,即将多层循环的迭代空间扁平化,形成更大的迭代集合。这个制导语句通常用于矩阵的遍历中,当处理器数量小于任务多余任务数量时,就可以使用这个子句,扁平化迭代空间后可以充分利用所有的计算资源,避免负载不均衡。
firstprivate子句为每个线程创建私有变量副本,并继承主线程中同名变量的初始值。即private变量无法在#pragma外部赋值初始化,只能在内部,而firstprivate标定的变量就可以在#pragma外部初始化
lastprivate子句与firstprivate类似,也是和主线程的变量交互,不过和firstprivate方向不同;lastprivate在线程退出并行区域时,将最后一次迭代(for)或最后一个section中的私有变量值赋给主线程同名变量,即firstprivate是在初始时由主线程拷贝数据进子线程,而lastprivate是在结束时,将数据传回给主线程。
2
对于代码一的#pragma omp parallel,会创建2个线程,每个线程独立执行完整的循环体,即每个线程都会完整执行for(int i=0; i<10; i++),导致每个i被打印两次(总计20次输出),但线程间执行顺序不确定,可能出现交错
对于代码二的#pragma omp parallel for,会将循环的10次迭代自动分配给2个线程(默认按块划分,例如线程0处理i=0~4,线程1处理i=5~9),即每个i仅被处理一次,总计10次输出。
实践结果如下:
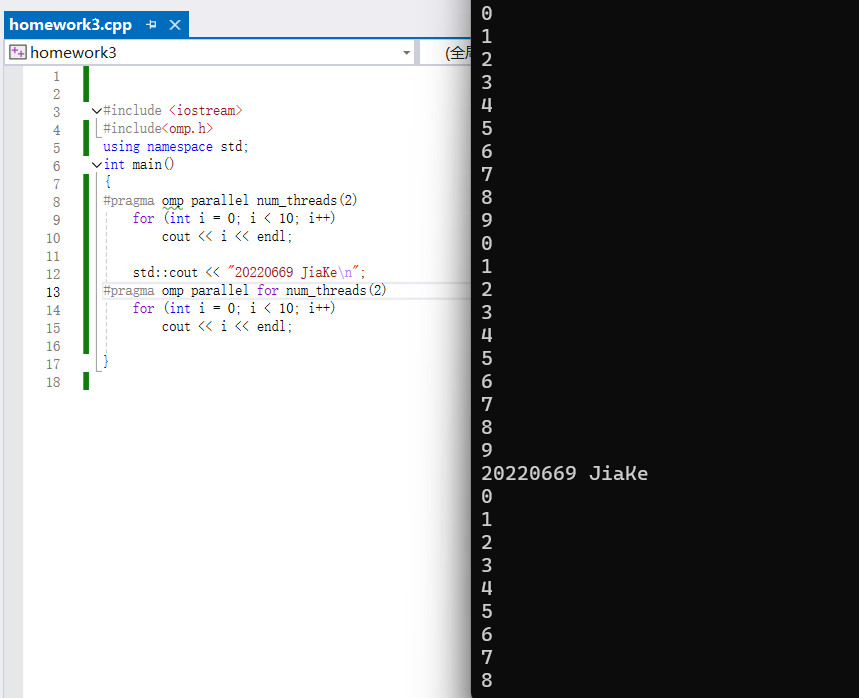
从工作机制上说,#pragma omp parallel是生成2个线程,每个线程执行并行区域内的所有代码,所有线程同时访问共享变量i和cout,可能导致竞态条件(Race Condition);#pragma omp parallel for是将循环拆分为独立的任务块,每个线程处理不同的迭代区间,循环变量i默认被设为私有(Private),每个线程有自己的副本,避免了竞态条件,循环结束后自动同步线程,保证后续代码的正确性
1
参照
What's new in OpenMP 5.0 | Red Hat Developer
任务归约(Task Reductions):OpenMP 5.0 首次允许在 taskloop 构造中使用 reduction 子句,并引入了 task_reduction(用于 taskgroup 构造)和 in_reduction(用于 task 和 taskloop 构造)子句。早期版本仅支持线程级(parallel)或 SIMD 级归约,而 5.0 允许在任务粒度下对变量进行归约操作,即使全局变量被多个任务共享,5.0 的归约机制也能通过私有化副本避免竞态条件。
任务组(Taskgroup)与任务循环(Taskloop)的增强:若 taskloop 未指定 nogroup,则隐含一个 taskgroup 作用域,此时 reduction 子句同时作用于隐式任务组和显式任务,简化了任务间的依赖管理;在 parallel 或 workshare 构造中使用 reduction(task:) 修饰符后,子任务可通过 in_reduction 参与归约,实现嵌套任务的协同计算
内存管理与数据环境优化:5.0 引入了 allocate 指令,允许在并行区域内动态分配内存并绑定到特定数据环境,这一特性优化了内存局部性,减少了跨线程的数据竞争。
设备卸载(Device Offloading)改进:新增 ompx_bare 子句,允许在 GPU 等设备上执行更底层的任务调度,减少主机与设备间的通信开销。支持通过 map 子句显式管理设备内存与主机内存的映射关系,提升了异构计算的效率。
此外,还在循环构造中支持更灵活的 SIMD 指令,例如 declare simd 允许为函数生成向量化版本;引入了 hint 子句,允许开发者指定锁的类型(如自旋锁或适应性锁),提升高竞争场景的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









