






创新实训项目博客:基于LoRA的医疗大模型高效微调实战
创新实训项目博客:基于LoRA的医疗大模型高效微调实战
在上一篇[《医疗大模型的数据收集与预处理》中,我们详细介绍了“智能医疗助手”项目中医疗数据集(如 Medical-O1 Reasoning SFT)的选择、清洗与格式化过程,并最终得到了适合模型微调的结构化数据。
本篇博客将聚焦于项目的核心阶段——利用LoRA(Low-Rank Adaptation)技术对 unsloth/DeepSeek-R1-Distill-Llama-8B 大语言模型进行高效微调,旨在使其更适应我们特定的中文医疗问答与复杂推理任务。我们将详细阐述LoRA的原理、我们的实验环境配置、数据准备、模型微调的具体步骤、关键代码实现、训练过程以及微调前后的效果对比。
第一部分:背景与原理介绍
1.1 为什么需要模型微调?
预训练大语言模型(LLMs)虽然具备了广泛的知识和一定的通用能力,但在特定领域(如医疗)或特定任务(如遵循特定指令格式进行思考链推理)上,其表现往往不尽如人意。微调(Fine-tuning)能够使模型学习到特定领域的数据分布和任务模式,从而在目标任务上获得更好的性能,使其更贴合实际应用需求。
1.2 LoRA (Low-Rank Adaptation) 技术详解
全参数微调(Full Fine-tuning)虽然效果好,但对计算资源(尤其是显存)要求极高,对于参数量动辄数十亿的大模型而言,往往难以承受。参数高效微调(Parameter-Efficient Fine-tuning, PEFT)技术应运而生,LoRA是其中的佼佼者。
LoRA的核心思想是: 在冻结预训练模型原始权重(我们表示为 W 0 W_0 W0)的同时,向模型中的特定层(通常是Transformer的Attention层中的查询Q、键K、值V、输出O投影矩阵以及MLP层)注入可训练的“旁路”低秩矩阵。
具体来说,对于原始权重矩阵
W
0
∈
R
d
×
k
W_0 \in \mathbb{R}^{d \times k}
W0∈Rd×k,LoRA引入两个低秩矩阵
A
∈
R
r
×
k
A \in \mathbb{R}^{r \times k}
A∈Rr×k 和
B
∈
R
d
×
r
B \in \mathbb{R}^{d \times r}
B∈Rd×r,其中秩
r
r
r 是一个远小于原始维度
d
d
d 和
k
k
k 的值 (即
r
≪
min
(
d
,
k
)
r \ll \min(d, k)
r≪min(d,k))。在训练过程中,
W
0
W_0
W0 保持不变,我们只训练
A
A
A 和
B
B
B 的参数。模型前向传播时,对权重的更新
Δ
W
\Delta W
ΔW 通过矩阵乘积
B
A
BA
BA 计算得到。因此,微调后的新权重
W
W
W 可以表示为:
W
=
W
0
+
Δ
W
=
W
0
+
B
A
W = W_0 + \Delta W = W_0 + BA
W=W0+ΔW=W0+BA
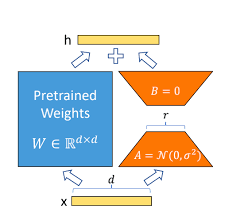
- 图示说明:一个大方块代表原始预训练权重 W 0 W_0 W0,旁边有两个较小的、细长的矩阵分别代表 B B B (维度 d × r d \times r d×r) 和 A A A (维度 r × k r \times k r×k)。箭头指示 B B B 和 A A A 相乘得到增量权重 Δ W \Delta W ΔW,然后 Δ W \Delta W ΔW 与 W 0 W_0 W0 相加(或并行作用于输入)得到最终的有效权重。
LoRA的优势:
- 大幅减少可训练参数:仅训练矩阵 A A A 和 B B B,参数量从原始的 d × k d \times k d×k 个减少到 r ( d + k ) r(d+k) r(d+k) 个。
- 显著降低显存占用:使得在消费级GPU上微调大模型成为可能。
- 训练速度更快:由于可训练参数少,梯度计算和更新更快。
- 推理无额外延迟:训练完成后,可以将学习到的增量权重 B A BA BA 与原始权重 W 0 W_0 W0 合并(即 W ′ = W 0 + B A W' = W_0 + BA W′=W0+BA),推理时与原模型结构一致,不引入额外计算。
- 轻松切换任务:可以为不同任务训练不同的LoRA权重,加载不同任务时只需替换较小的LoRA权重文件。
1.3 选择unsloth/DeepSeek-R1-Distill-Llama-8B作为基础模型
我们选择unsloth/DeepSeek-R1-Distill-Llama-8B作为基础模型,主要基于以下考虑:
- 强大的基础能力:DeepSeek-R1-Distill-Llama-8B 是由 DeepSeek AI 团队基于 Llama-3.1-8B 通过知识蒸馏得到的模型,继承了 Llama 架构的优秀特性,并在数学和推理能力上有所增强。
- 中文支持良好:该模型对中文有较好的原生支持。
- 参数规模适中:8B 参数量在 4-bit 量化后,能够在如 Google Colab 提供的免费 T4 GPU (16GB VRAM) 或消费级显卡(如 RTX 3060 12GB)上进行高效微调。
- Unsloth 优化支持:Unsloth 社区对该模型提供了优化支持,可以进一步提升训练速度和降低显存占用。
第二部分:实验环境与依赖
我们在Google Colab平台上使用免费的T4 GPU(约15GB显存)完成了本次微调实验。
安装与配置:
首先,安装必要的Python库:
# %%capture # 在Colab中用于隐藏单元格输出
# 安装Unsloth最新版,它会自动处理bitsandbytes等依赖
# 针对Colab环境优化,确保使用最新的kernels以获得最佳兼容性
!pip install "unsloth[colab-newest-kernels] @git+https://github.com/unslothai/unsloth.git"
# 虽然Unsloth会尝试安装依赖,但有时显式安装特定版本有助排错
# bitsandbytes 是进行4-bit量化的核心库
# transformers 和 trl (Transformer Reinforcement Learning) 用于训练
!pip install "transformers>=4.38.0" "datasets>=2.16.0" "accelerate>=0.27.0" "trl>=0.8.0" "peft>=0.10.0" "bitsandbytes>=0.41.3"
## 第三部分:模型加载与数据准备
### 3.1 加载基础模型和Tokenizer
我们使用Unsloth提供的`FastLanguageModel`来加载模型,并启用4-bit量化以大幅降低显存占用。
```python
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # 根据任务和显存调整,我们这里选择2048
dtype = None # None会自动检测,BF16 (Ampere+) 或 F16 (T4, V100)
load_in_4bit = True # 启用4-bit量化
# 从Hugging Face Hub加载Unsloth优化过的模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "YOUR_HF_TOKEN", # 如果是私有模型或需要授权的模型,请填入token
)
[模型加载后显存占用]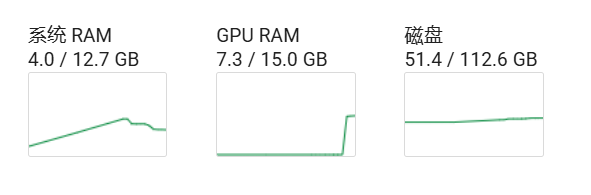
3.2 微调前推理测试(可选但推荐)
在微调之前,我们先用一个医疗问题测试一下原始模型的表现,以便后续对比。
# 定义推理时的Prompt模板,包含思考链的引导
# 注意,<think>标签后的内容留空,由模型生成
prompt_style_inference = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
question = "我今天有点头疼,而且肚子不舒服,没胃口,怎么办"
# Unsloth支持快速推理模式
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style_inference.format(question, "")], return_tensors = "pt").to("cuda")
outputs_before = model.generate(
input_ids = inputs.input_ids,
attention_mask = inputs.attention_mask,
max_new_tokens = 1200, # 限制生成长度
use_cache = True,
pad_token_id = tokenizer.eos_token_id, # 对于开放式生成,设置pad_token_id很重要
)
response_text_before = tokenizer.batch_decode(outputs_before)
print("="*20 + " 微调前模型的回答 " + "="*20)
# 通常模型输出会包含输入的prompt,所以我们取 ### Response: 之后的部分
# 并且去除可能存在的 <|end_of_sentence|> 或 eos_token
response_content_before = response_text_before[0].split("### Response:")[1].replace(tokenizer.eos_token, "").strip()
print(response_content_before)
print("="*60)
[微调前模型回答示例]

3.3 准备训练数据集
我们使用上一篇博客中处理好的FreedomIntelligence/medical-o1-reasoning-SFT数据集(中文部分)。关键是将其格式化为包含明确指令、问题、思考链(CoT)和答案的文本。
# 定义训练时的Prompt模板,需要包含完整的Question, Complex_CoT, 和 Response
# 注意,这里我们将CoT放在<think>标签内,引导模型学习这种思考模式
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. Please answer the following medical question.
### Question:
{}
### Response:
<think> {} </think> {}"""
EOS_TOKEN = tokenizer.eos_token # 必须在每个训练样本末尾添加结束符,否则可能导致无限生成
# 数据格式化函数
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input_text, cot_text, output_text in zip(inputs, cots, outputs):
# 构建符合训练模板的文本
# 确保所有部分都是字符串
text = train_prompt_style.format(str(input_text), str(cot_text), str(output_text)) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
# 加载数据集 (以中文部分为例,并取少量样本进行演示)
from datasets import load_dataset
# dataset_full = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", 'zh', split = "train", trust_remote_code=True) # 加载完整数据集
dataset_sample = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", 'zh', split = "train[0:500]", trust_remote_code=True) # 演示用,取前500条
dataset_formatted = dataset_sample.map(formatting_prompts_func, batched = True,)
print("="*20 + " 处理后的第一条训练数据示例 " + "="*20)
print(dataset_formatted["text"][0])
print("="*70)
第四部分:LoRA模型配置与训练
4.1 配置LoRA参数并应用到模型
使用Unsloth,可以方便地将LoRA配置应用到FastLanguageModel。
model = FastLanguageModel.get_peft_model(
model,
r = 16, # LoRA的秩(rank),推荐8, 16, 32, 64。越大参数越多,效果可能更好但更耗资源。
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",], # 目标Transformer模块
lora_alpha = 16, # LoRA的alpha缩放因子,通常设为r或2*r
lora_dropout = 0, # LoRA层的dropout,Unsloth推荐为0以获得优化
bias = "none", # 是否训练bias,"none"为不训练,Unsloth推荐
use_gradient_checkpointing = "unsloth", # 节省显存的关键技术,"unsloth"为优化版
random_state = 3407, # 保证可复现性
use_rslora = False, # 是否使用Rank Stabilized LoRA,可选
loftq_config = None, # LoftQ量化配置,可选
)
# 打印可训练参数信息
print("="*20 + " LoRA模型可训练参数 " + "="*20)
model.print_trainable_parameters()
print("="*60)
[截图位置F:可训练参数信息]

4.2 设置训练参数并启动训练
我们使用Hugging Face trl库中的SFTTrainer进行监督微调。
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported # 检查硬件是否支持bfloat16
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset_formatted, # 使用格式化后的数据集
dataset_text_field = "text", # 指定包含完整文本的列名
max_seq_length = max_seq_length, # 与模型加载时一致
dataset_num_proc = 2, # 数据预处理的进程数
packing = False, # 是否将短序列打包以提高效率,对于长序列通常设为False
args = TrainingArguments(
per_device_train_batch_size = 2, # 根据显存调整
gradient_accumulation_steps = 4, # 实际batch_size = 2 * 4 = 8
warmup_steps = 5, # 学习率预热步数
max_steps = 60, # 总训练步数 (演示用,实际应更多,如1-3个epoch)
# num_train_epochs = 1, # 或者使用epoch数控制训练时长
learning_rate = 2e-4, # 学习率
fp16 = not is_bfloat16_supported(), # T4不支持bf16,用fp16
bf16 = is_bfloat16_supported(), # Ampere+ 使用bf16
logging_steps = 1, # 每隔多少步打印一次日志
optim = "adamw_8bit", # 使用8-bit AdamW优化器节省显存
weight_decay = 0.01,
lr_scheduler_type = "linear", # 学习率衰减策略
seed = 3407,
output_dir = "outputs", # 模型检查点和日志输出目录
report_to = "none", # 如需WandB等,可配置 "wandb"
),
)
# 开始训练
print("="*20 + " 开始LoRA微调 " + "="*20)
trainer_stats = trainer.train()
print("="*20 + " 微调完成 " + "="*20)
[截图位置G:训练过程日志]
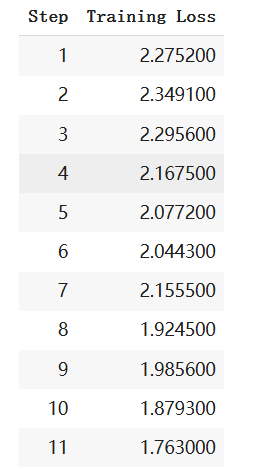
第五部分:模型保存
5.1 保存模型
可以将微调后的LoRA权重保存下来,或者将LoRA权重与基础模型合并后保存。Unsloth也支持直接保存为GGUF格式,方便在llama.cpp等框架中本地运行。
# 仅保存LoRA适配器权重 (只保存增量部分,文件小)
# model.save_pretrained("lora_medical_deepseek_adapter")
# tokenizer.save_pretrained("lora_medical_deepseek_adapter")
# print("LoRA适配器已保存到 lora_medical_deepseek_adapter 目录")
# 如果需要合并权重并保存完整模型 (需要更多磁盘空间和内存,推理时无需额外加载适配器)
# merged_model = model.merge_and_unload()
# merged_model.save_pretrained("full_medical_deepseek_finetuned")
# tokenizer.save_pretrained("full_medical_deepseek_finetuned")
# print("完整合并后的模型已保存到 full_medical_deepseek_finetuned 目录")
# 保存为GGUF格式 (例如,8-bit量化,方便本地CPU/GPU运行)
# output_gguf_path = "medical_deepseek_q8_0.gguf"
# model.save_pretrained_gguf(output_gguf_path, tokenizer, quantization_method = "q8_0")
# print(f"模型已保存为GGUF格式: {output_gguf_path}")
# (可选) 上传到Hugging Face Hub
# from google.colab import userdata # Colab环境下获取secrets
# HUGGINGFACE_TOKEN = userdata.get('HUGGINGFACE_TOKEN') # 需要先在Colab Secrets中设置HF_TOKEN
# if HUGGINGFACE_TOKEN:
# model_name_on_hub = "YourHFAccount/DeepSeek-R1-Distill-Llama-8B-Medical-LoRA" #替换为你的HF用户名和仓库名
# # 上传LoRA适配器
# # model.push_to_hub(model_name_on_hub, token=HUGGINGFACE_TOKEN)
# # tokenizer.push_to_hub(model_name_on_hub, token=HUGGINGFACE_TOKEN)
# # print(f"LoRA适配器已推送到Hugging Face Hub: {model_name_on_hub}")
# # 或者上传GGUF文件
# # model.push_to_hub_gguf(model_name_on_hub_gguf, tokenizer, token=HUGGINGFACE_TOKEN, quantization_method="q8_0")
# # print(f"GGUF模型已推送到Hugging Face Hub: {model_name_on_hub_gguf}")
# else:
# print("Hugging Face Token未设置,跳过上传。")
第六部分:总结与展望
通过本次实训,我们成功实践了:
- 使用Unsloth框架加载并以4-bit量化
unsloth/DeepSeek-R1-Distill-Llama-8B模型。 - 基于
Medical-O1 Reasoning SFT数据集,构建了包含明确思考链引导的训练Prompt。 - 配置了LoRA参数,并使用
SFTTrainer在单张T4 GPU上对模型进行了高效微调。 - 初步对比了模型微调前后的推理效果,微调后的模型在遵循指令、生成结构化思考链以及医疗问题回答的专业性上通常会有所改善。
遇到的挑战与经验:
- Prompt工程的重要性:训练和推理时的Prompt模板对模型行为有巨大影响,
<think>标签的使用是我们引导模型学习CoT的关键。 EOS_TOKEN的添加:训练数据末尾必须添加tokenizer.eos_token,否则可能导致模型生成时无法正常停止。- 超参数调优:LoRA的秩
r、lora_alpha、学习率、batch_size等都需要根据具体任务和数据集进行调整,本次仅为初步演示。 - 训练步数:演示中
max_steps = 60远不足以让模型充分学习,实际项目中需要训练更长时间(例如1-3个epoch,或根据数据集大小调整max_steps)。 - 资源限制:即使有Unsloth和4-bit量化,对于非常大的上下文或batch_size,T4的15GB显存仍可能成为瓶颈。
未来工作:
- 更充分的训练:使用完整数据集和更长的训练步数(例如,训练1-3个epoch)进行微调,以期达到更好的收敛效果。
- 系统评估:设计更全面的评估方案,例如使用保留的测试集,并引入BLEU、ROUGE等客观指标,以及更细致的人工评估来衡量模型在医疗推理、信息准确性、流畅性等方面的性能。
- RAG(Retrieval Augmented Generation)集成:探索将微调后的模型与上一篇博客中提到的其他适合构建RAG知识库的数据集(如MedDialog-CN、cMedQA等)结合,通过检索增强生成的方式,进一步提升回答的准确性和时效性。
- 迭代优化:根据评估结果,持续优化Prompt设计、LoRA超参数、数据预处理流程等。
我们相信,通过不断的迭代和优化,能够逐步打造出一个更智能、更专业的“智能医疗助手”。
第七部分:参考资料
- Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
- Unsloth AI GitHub Repository: https://github.com/unslothai/unsloth
- Hugging Face PEFT Library: https://huggingface.co/docs/peft
- Hugging Face TRL Library: https://huggingface.co/docs/trl
- DeepSeek-R1-Distill-Llama-8B (Unsloth version) Model Card: https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
- Medical-O1 Reasoning SFT Dataset: https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









