






 本文介绍了五个编程问题,涉及斜线最大最小值计算、矩阵连乘问题(包括备忘录法、动态规划求解)以及基因序列相似度计算。这些问题展示了动态规划在算法中的应用,要求找出最优解或满足特定条件的解。
本文介绍了五个编程问题,涉及斜线最大最小值计算、矩阵连乘问题(包括备忘录法、动态规划求解)以及基因序列相似度计算。这些问题展示了动态规划在算法中的应用,要求找出最优解或满足特定条件的解。
问题 A: 斜线最大最小值
[命题人 : 201501010119]
时间限制 : 1.000 sec 内存限制 : 128 MB
提交问题列表
题目描述
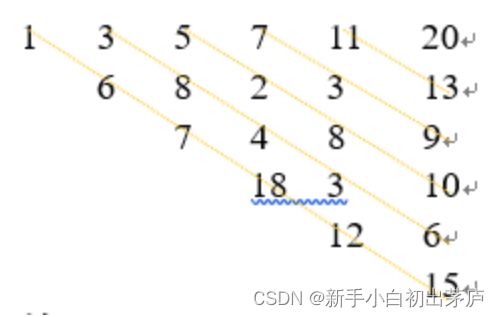
求如图所示一个上三角矩阵中每一条斜线中的最大元素(L)和最小元素(S)。
输入
每组输入包括两部分,一部分为数字n,表示三角矩阵的行数。
第二部分即为三角矩阵。
输出
每一个对角线输出一行,每行包括Lx=Max, Sx=Min,其中x为斜线序号(序号从1开始),Max为该斜线上的最大值,Min为该斜线上的最小值。
样例输入 Copy
6 1 3 5 7 11 20 0 6 8 2 3 13 0 0 7 4 8 9 0 0 0 18 3 10 0 0 0 0 12 6 0 0 0 0 0 15
样例输出 Copy
L1=18, S1=1 L2=8, S2=3 L3=10, S3=2 L4=9, S4=3 L5=13, S5=11 L6=20, S6=20
#include <stdio.h>
void solve(int a[100][100], int n) {
for (int r = 0; r < n; r++) {
int max_val = a[0][r];
int min_val = a[0][r];
for (int i = 0; i < n - r; i++) {
int j = i + r;
if (max_val < a[i][j]) {
max_val = a[i][j];
}
if (min_val > a[i][j]) {
min_val = a[i][j];
}
}
printf("L%d=%d, S%d=%d\n", r+1, max_val, r+1, min_val);
}
}
int main() {
int n;
while (scanf("%d", &n) != EOF) {
int a[100][100];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
scanf("%d", &a[i][j]);
}
}
solve(a, n);
}
return 0;
}
问题 B: 矩阵连乘问题-备忘录法求最优值
[命题人 : admin]
时间限制 : 1.000 sec 内存限制 : 128 MB
提交问题列表
题目描述
使用备忘录法求解矩阵连乘问题,输出最少乘法次数。
输入
每组数据包括两行,第一行为数组长度n,第二行为存储矩阵维数的一维数组。
输出
矩阵连乘最优计算次数。
样例输入 Copy
7 30 35 15 5 10 20 25
样例输出 Copy
15125
def slove(x, y):
for r in range(2, y):
for i in range(1, y-r+1):
j = i+r-1
dp[i][j] = dp[i+1][j]+p[i-1]*p[i]*p[j]
for k in range(i+1, j):
dp[i][j] = min(dp[i][j], dp[i][k]+dp[k+1][j]+p[i-1]*p[k]*p[j])
return dp[x][y-1]
while True:
n = int(input())
p = [int(i) for i in input().split()]
dp = [[0] * n for _ in range(n)]
print(slove(1, n))问题 C: 矩阵连乘问题-动态规划求最优值
[命题人 : 201501010119]
时间限制 : 1.000 sec 内存限制 : 128 MB
提交问题列表
题目描述
使用动态规划算法求解矩阵连乘问题,输出最少乘法次数。
输入
每组数据包括两行,第一行为数组长度n,第二行为存储矩阵维数的一维数组。
输出
矩阵连乘最优计算次数。
样例输入 Copy
7 30 35 15 5 10 20 25
样例输出 Copy
15125
#include <stdio.h>
#include <stdlib.h>
int min(int a, int b) {
return (a < b) ? a : b;
}
int main() {
while (1) {
int n;
if (scanf("%d", &n) != 1) {
return 1;
}
int *arr = (int *)malloc(n * sizeof(int));
if (arr == NULL) {
return 1;
}
for (int i = 0; i < n; i++) {
if (scanf("%d", &arr[i]) != 1) {
free(arr);
return 1;
}
}
int **dp = (int **)malloc((n + 1) * sizeof(int *));
if (dp == NULL) {
free(arr);
return 1;
}
for (int i = 0; i <= n; i++) {
dp[i] = (int *)calloc(n, sizeof(int));
if (dp[i] == NULL) {
for (int j = 0; j < i; j++) {
free(dp[j]);
}
free(dp);
free(arr);
return 1;
}
}
for (int r = 2; r <= n; r++) {
for (int i = 1; i <= n - r; i++) {
int j = i + r - 1;
dp[i][j] = dp[i + 1][j] + arr[i - 1] * arr[i] * arr[j];
for (int k = i + 1; k < j; k++) {
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k + 1][j] + arr[i - 1] * arr[k] * arr[j]);
}
}
}
printf("%d\n", dp[1][n - 1]);
for (int i = 0; i <= n; i++) {
free(dp[i]);
}
free(dp);
free(arr);
}
return 0;
}问题 D: 矩阵连乘问题-构造最优解
[命题人 : 201501010119]
时间限制 : 1.000 sec 内存限制 : 128 MB
提交问题列表
题目描述
使用动态规划算法求解矩阵连乘问题。
输入
每组数据包括两行,第一行为数组长度n,第二行为存储矩阵维数的一维数组。
输出
矩阵连乘最优计算次序。
样例输入 Copy
7 30 35 15 5 10 20 25
样例输出 Copy
A[2:2] * A[3:3] A[1:1] * A[2:3] A[4:4] * A[5:5] A[4:5] * A[6:6] A[1:3] * A[4:6]
#include <stdio.h>
#include <stdlib.h>
void traceback(int **ind, int i, int j, char **res, int *res_size) {
if (i == j) {
return;
}
traceback(ind, i, ind[i][j], res, res_size);
traceback(ind, ind[i][j] + 1, j, res, res_size);
sprintf(res[*res_size], "A[%d:%d] * A[%d:%d]", i, ind[i][j], ind[i][j] + 1, j);
(*res_size)++;
}
int main() {
int n;
while (scanf("%d", &n) != EOF) {
if (n == 0) {
break;
}
int *arr = (int *)malloc(n * sizeof(int));
for (int i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
int **dp = (int **)malloc((n + 1) * sizeof(int *));
int **ind = (int **)malloc((n + 1) * sizeof(int *));
for (int i = 0; i < n + 1; i++) {
dp[i] = (int *)malloc(n * sizeof(int));
ind[i] = (int *)malloc(n * sizeof(int));
}
char **res = (char **)malloc(100 * sizeof(char *));
for (int i = 0; i < 100; i++) {
res[i] = (char *)malloc(20 * sizeof(char));
}
int res_size = 0;
for (int i = 0; i < n + 1; i++) {
for (int j = 0; j < n; j++) {
dp[i][j] = 0;
ind[i][j] = 0;
}
}
for (int r = 2; r <= n; r++) {
for (int i = 1; i <= n - r; i++) {
int j = i + r - 1;
dp[i][j] = dp[i + 1][j] + arr[i - 1] * arr[i] * arr[j];
ind[i][j] = i;
for (int k = i + 1; k < j; k++) {
int t = dp[i][k] + dp[k + 1][j] + arr[i - 1] * arr[k] * arr[j];
if (t < dp[i][j]) {
dp[i][j] = t;
ind[i][j] = k;
}
}
}
}
traceback(ind, 1, n - 1, res, &res_size);
for (int i = 0; i < res_size; i++) {
printf("%s\n", res[i]);
}
// Free allocated memory
for (int i = 0; i < n + 1; i++) {
free(dp[i]);
free(ind[i]);
}
free(arr);
free(dp);
free(ind);
for (int i = 0; i < 100; i++) {
free(res[i]);
}
free(res);
}
return 0;
}问题 E: 石子合并问题
[命题人 : 201501010119]
时间限制 : 1.000 sec 内存限制 : 128 MB
提交问题列表
题目描述
在一条直线上有n堆石子,每堆有一定的数量,每次可以将两堆相邻的石子合并,合并后放在两堆的中间位置,合并的费用为两堆石子的总数。求把所有石子合并成一堆的最小花费。例如:输入{1,2,3,4,5},输出33。【3+6+9+15=33】
输入
本题应该处理到文件尾,每组输入包括两行,第一行为石子堆的个数n,第二行则为每堆石子的个数。
输出
输出最小花费。
样例输入 Copy
5 1 2 3 4 5
样例输出 Copy
33
def merge_stones(stones):
n = len(stones)
# 创建一个二维数组dp,dp[i][j]表示合并第i堆到第j堆石子所需的最小花费
dp = [[0] * n for _ in range(n)]
# 创建一个前缀和数组prefix,用于快速计算区间石子数的总和
prefix = [0] * (n + 1)
# 计算前缀和数组
for i in range(1, n + 1):
prefix[i] = prefix[i - 1] + stones[i - 1]
# 动态规划过程
for length in range(2, n + 1): # 枚举子区间的长度
for i in range(n - length + 1): # 枚举区间起点
j = i + length - 1 # 区间终点
dp[i][j] = float('inf') # 初始化为无穷大
# 枚举区间内的分割点
for k in range(i, j):
# 更新dp[i][j]为最小值
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k + 1][j] + prefix[j + 1] - prefix[i])
return dp[0][n - 1]
# 读取输入
while True:
try:
n = int(input())
stones = list(map(int, input().split()))
# 调用函数输出结果
print(merge_stones(stones))
except EOFError:
break问题 F: X星人的基因
[命题人 : admin]
时间限制 : 1.000 sec 内存限制 : 128 MB
提交问题列表
题目描述
X星人的基因由A、B、C、D、E五种不同的结构组合而成。
如果两个性别不同的X星人的基因序列相似度大于50%,按照X星的法律他们是禁止结婚的,等于50%据说还是可以的。
那么基因的相似度怎么计算呢?分别从两个人身上取长度均为N的基因片段,如果它们的最长公共子序列为M,则相似度=M/N。是不是很简单呢?
现在给你两段X星人的基因序列片段,请你判断他们是不是可以结婚?
输入
每一组测试数据包含3行,
第1行数字N表示待比较基因序列片段的长度,N<=10^3。
第2行和第3行为两个长度为N的基因序列片段。
输入0表示结束。
输出
两个X星人是否可以结婚,如果可以输出”Yes“,如果不可以输出”No“。
样例输入 Copy
8 A B C D E A B C A C C D C B A E 6 A B C D E E A E D C B B 0
样例输出 Copy
Yes Yes
def longest_common_subsequence(seq1, seq2):
m, n = len(seq1), len(seq2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
if seq1[i - 1] == seq2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i][j - 1], dp[i - 1][j])
return dp[m][n]
def can_marry(N, seq1, seq2):
similarity = longest_common_subsequence(seq1, seq2) / N
if similarity > 0.5:
return "No"
else:
return "Yes"
# 读取输入并进行处理
while True:
N = int(input())
if N == 0:
break
seq1 = input().split()
seq2 = input().split()
result = can_marry(N, seq1, seq2)
print(result)














 918
918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









