






DFS
在蓝桥杯备赛的过程中遇到不少的搜索类题目,其中近两年尤其都有考到DFS,看来是时候把欠下的坑补上了(指第二次模拟赛时说要做个整理来着)
1.核心思想
dfs(或者深度优先搜索)听起来就很抽象,实际上总结下来只有三个字 ---- “搜到底”,一个递归的dfs程序的结束一定是以搜到最深处结束的(无论是绝对最深还是剪枝后的“相对最深”),这就是dfs 的核心思想
所以我们就很轻松能想到这样一种(伪)代码模版 (或者称为基本模型)
void dfs(int step){
if(终止条件) return;
for(int i = 0;i<n;i++){
if(下一步条件) //提前判断完成剪枝
dfs(step + 1);
//此处可选回溯
}
return;
}
int main()
{
dfs(初始状态);
}基于这个模板,我们看几个题来对dfs做一个入门了解
2.排列组合问题
排列组合问题是很经典的入坑题,大致有以下几种
2.1 全排列
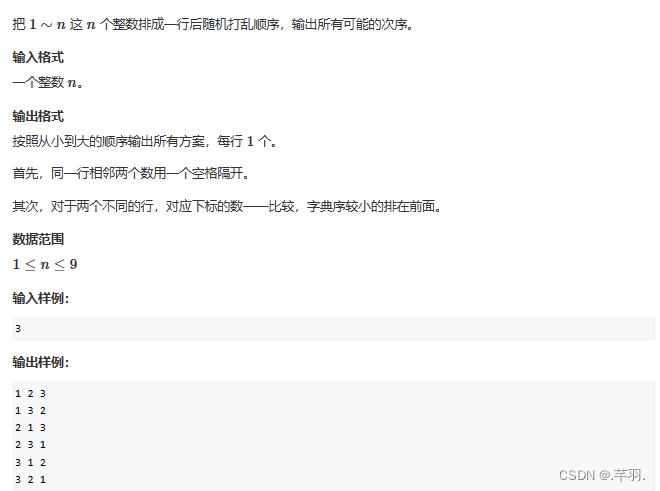
借用我们的基本模型来看,step可以对应为已选数字的数量,那么终止条件即是step == n,下一步条件是该数未被选择,初始状态则是没有数字被选择,由于需要寻找其他排列方法,所以需要回溯,捋清楚各个位置在本题中对应的实际意义,那么题目逻辑就很清晰了
废话不多说,上代码
#include<iostream>
using namespace std;
const int N = 10;
int n,length;
int visited[N];
int ans[N];
void dfs(int step){
if(step == n){
for(int i = 0;i < n;i++){
cout << ans[i] << " ";
}
cout << endl;
}
for(int i = 1;i <= n;i++){
if(!visited[i]){
ans[step] = i;
visited[i] = 1;
dfs(step+1);
visited[i] = 0;
}
}
return;
}
int main(){
cin >> n;
dfs(0);
return 0;
}2.2 指数型枚举
与全排列的区别在于不需要用上每一个数,也就是说,对于任意一个数,其具有被选择与未被选择两种状态
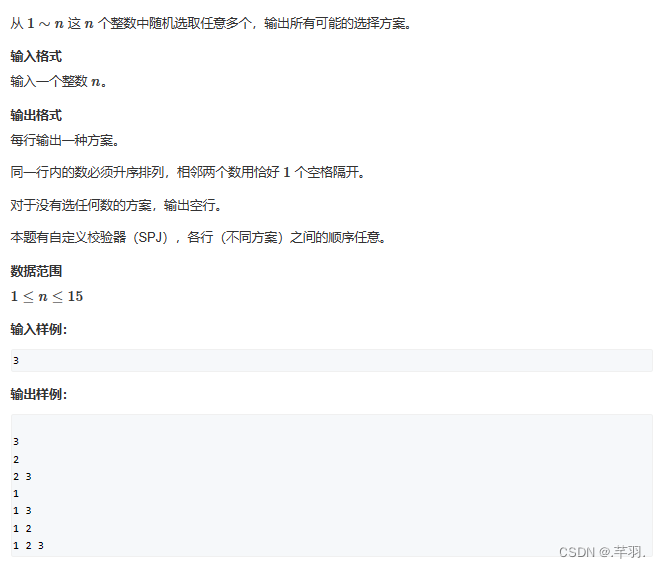
对应我们的基本模型来看,step对应的条件不能再是已选择数的数量了,因为一个数可能具有未被选择状态导致一直dfs(step)原地死递归,那么step应该对应的是已经开始对第step个数做选择了,终止条件则为对最后一个数进行选择,下一步条件应该为无条件进行下一步(前面的选择与后面无关),初始状态仍然为未开始选择。
代码表示如下
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int ans[N];
bool b[N];
int n;
void show(int i){
for(int j = 0;j<i;j++){
if(b[j]){
cout << ans[j] << " ";
}
}
cout << endl;
}
void dfs(int i){
if(i == n){
show(i);
return;
}
dfs(i+1);
b[i] = 1;
dfs(i+1);
b[i] = 0;
return;
}
int main()
{
cin >> n;
for(int i = 0;i<n;i++){
ans[i] = i+1;
}
dfs(0);
return 0;
}2.3 组合型枚举
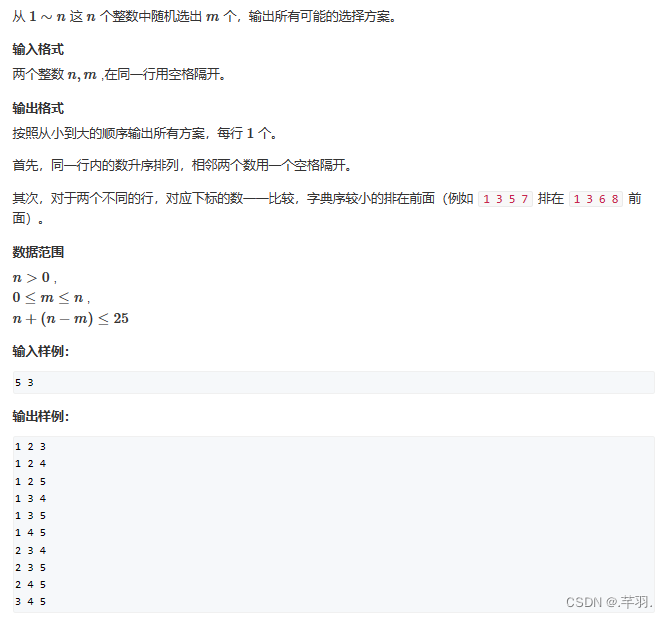
仍然以基本模型分析该题,发现和全排列的区别,在于结束的条件,以及由于m<n可得一个数可以具有被选择和未被选择两种状态。
代码实现如下
#include<iostream>
#include<vector>
using namespace std;
int n,m;
vector<int> num;
void dfs(int k)
{
if(num.size() > m || num.size() + (n - k + 1) < m)
return;
if(k == n + 1){
for(int i = 0;i < num.size();++i)
cout << num[i] << " ";
cout << endl;
return;
}
num.push_back(k);
dfs(k+1);
num.pop_back();
dfs(k+1);
}
int main()
{
cin >> n >> m;
dfs(1);
return 0;
}3.路径搜索问题
一般指在给定的图或树中搜索路径的问题,例如二叉树的前中后序遍历,或在一个图(或矩阵中)找到限定条件下的路径。
3.1 二叉树的遍历
二叉树常用的四种遍历中,除了层序遍历使用的是bfs,其他都是dfs的搜索方法,区别在于将根节点数据加入遍历序列的时间点不同,先序正如其名,自然是最先加入根节点,中序则是在继续搜索左结点和右结点之间,将根节点加入,后序则是最后加入根节点
代码表示如下
vector<int> res;
void preorder(TreeNode *root){
if(root == nullptr){
return;
}
res.push_back(root->val);
preorder(root->left);
preorder(root->right);
}
void inorder(TreeNode *root){
if(root == nullptr){
return;
}
inorder(root->left);
res.push_back(root->val);
inorder(root->right);
}
void postorder(TreeNode *root){
if(root == nullptr){
return;
}
postorder(root->left);
postorder(root->right);
res.push_back(root->val);
}3.2 路径搜索
dfs不一定能解决所有的路径搜索问题(比如最短路问题时就不太好用),算法竞赛中一般用于求解一些迷宫问题

例如该题,题意分析下来,可以总结为:求解在一个迷宫中的活动范围,由基本模型来分析,step应该是所处位置的横纵坐标,终止条件为遇到不可再走的红瓷砖或触碰边界,前进条件应为无条件向四个方向都前进,初始状态则为'@'位置的横纵坐标。 那么代码表示如下:
#include<iostream>
#include<cstring>
using namespace std;
char a[25][25];
int n,m,cnt;
int startx,starty;
void dfs(int x,int y){
if(a[x][y] == '#'){
return;
}
else{
cnt++;
a[x][y] = '#';
dfs(x-1,y);
dfs(x+1,y);
dfs(x,y-1);
dfs(x,y+1);
}
}
int main(){
while(cin >> m >> n){
if(n == 0 && m == 0){
break;
}
cnt = 0;
memset(a,'#',sizeof(a));
for(int i = 1;i <= n;i++){
for(int j = 1;j <= m;j++){
cin >> a[i][j];
if(a[i][j] == '@'){
startx = i;
starty = j;
}
}
}
dfs(startx,starty);
cout << cnt << endl;
}
return 0;
}4.题目练习
这些只是基础的入门题,想要对dfs有更深层次的了解,刷题可能会是不错的选择
















 5002
5002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











