







目录
4.1从某些镜像网站上下载jdk1.8与hadoop的压缩包(这里我用的是hadoop3.2.4版本的、可以从清华大学镜像网站上下载这些资源)
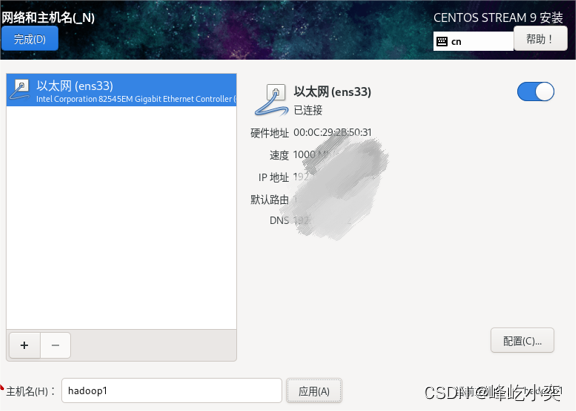
一、创建虚拟机
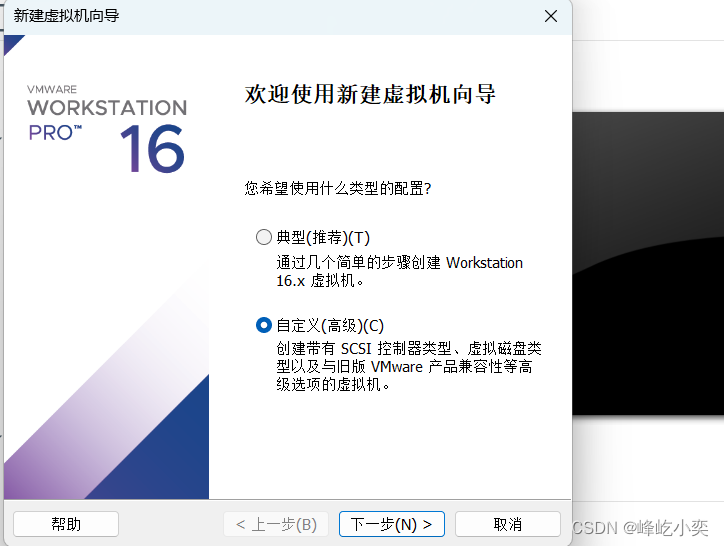
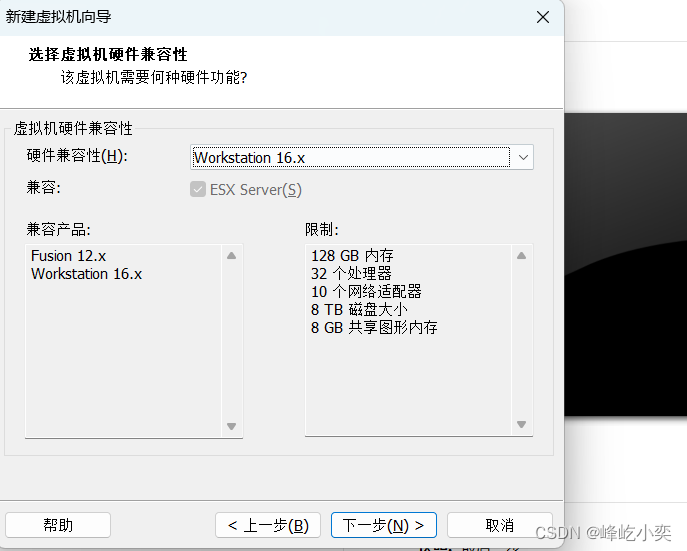
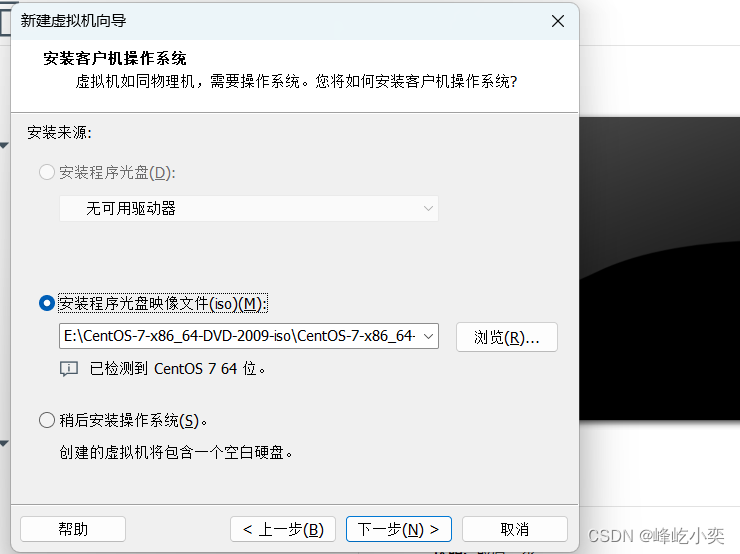
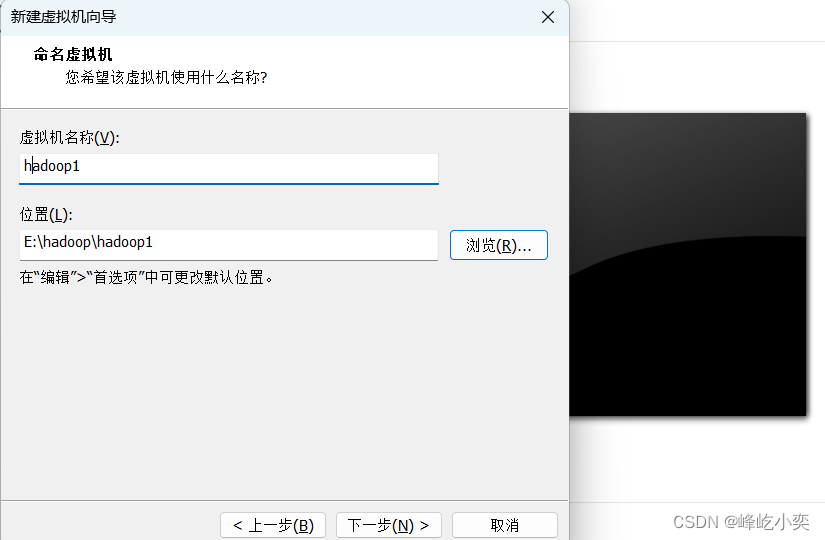
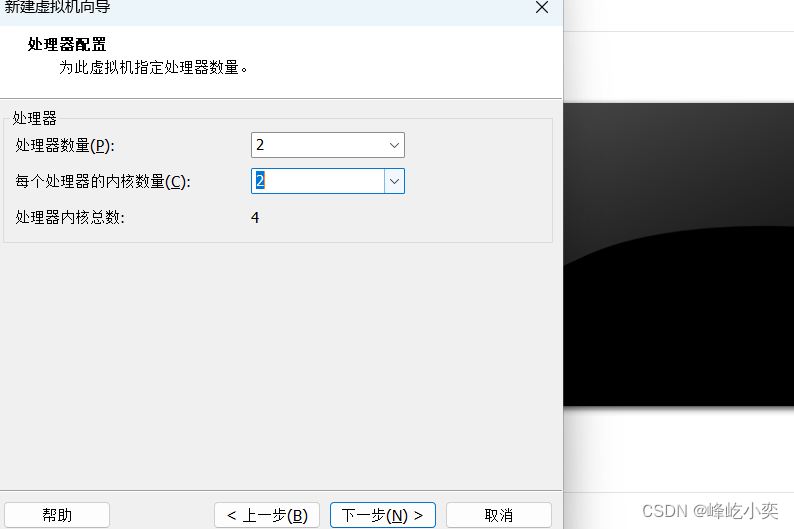
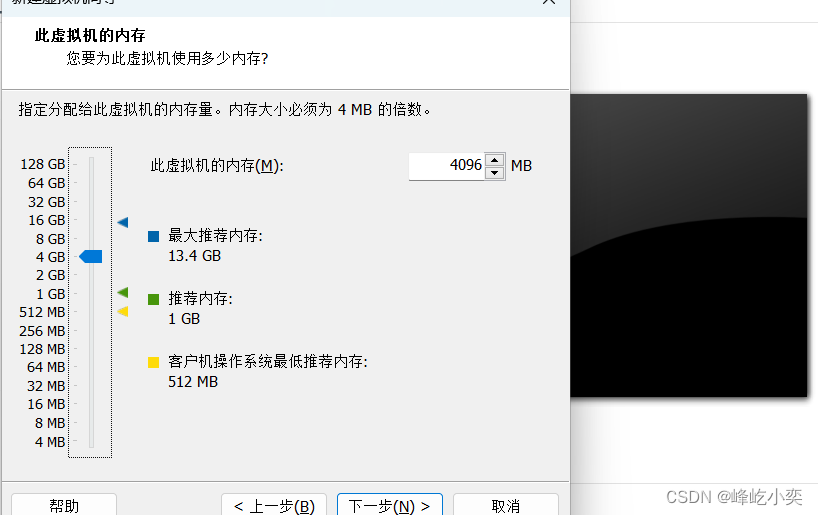
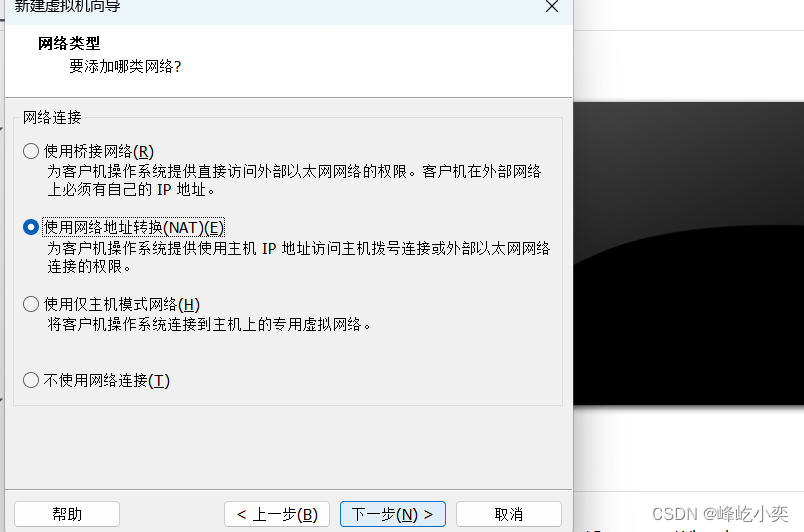
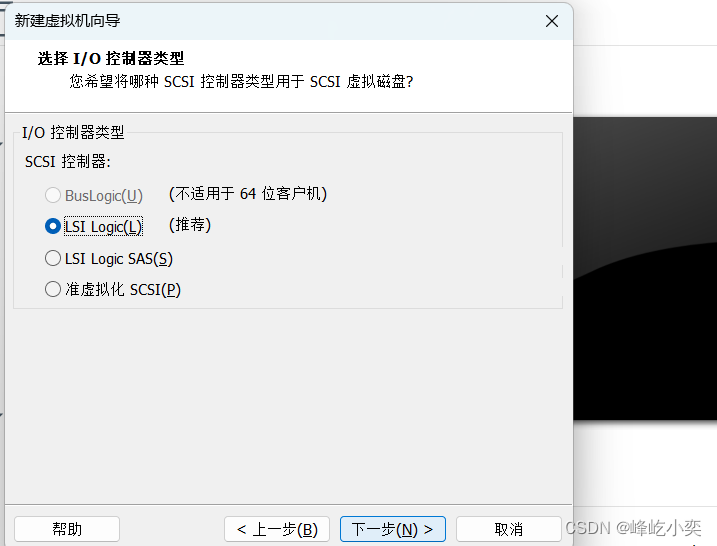

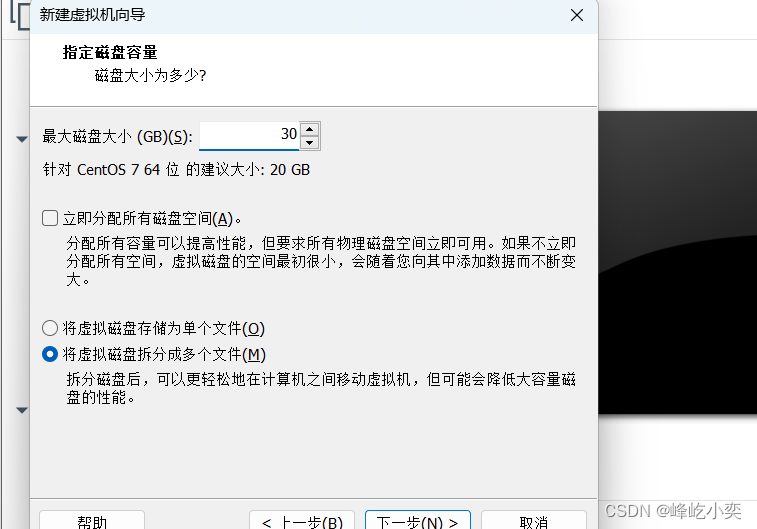
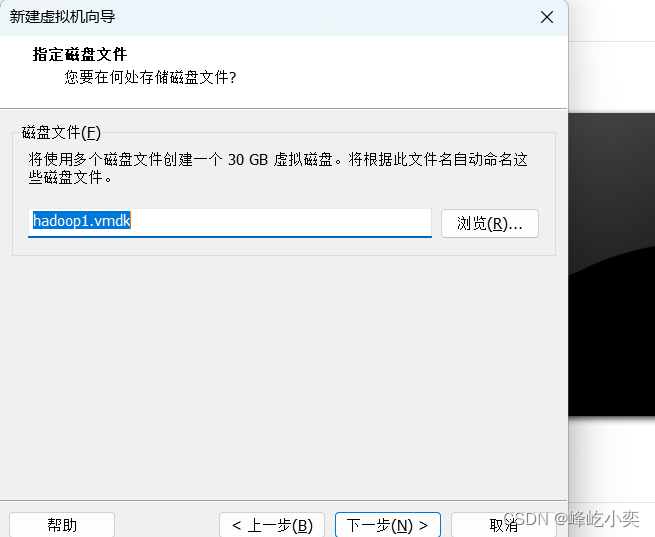
根据自己的需求设置磁盘大小

二、克隆虚拟机
以下是我克隆好的图片及克隆步骤

结果:
三、配置虚拟机
3.1配置ip映射
分别在虚拟机Hadoop1、Hadoop2和Hadoop3执行“vi /etc/hosts”命令编辑映射文件hosts,在配置文件中添加如下内容:(注意:ip地址是 自己电脑上的)
192.16.13.12 Hadoop1 Hadoop1.hadoop.com
192.16.13.13 Hadoop2 Hadoop2.hadoop.com
192.16.13.14 Hadoop3 Hadoop3.hadoop.com

3.2配置虚拟机ssh远程登陆及免密登陆
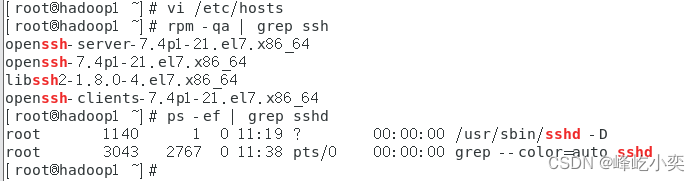
在虚拟机中,分别执行“rpm -qa | grep ssh”和“ps -ef | grep sshd”命令,查看当前虚拟机是否安装了SSH服务,以及SSH服务是否启动。
如果虚拟机中没有安装ssh服务则:
输入命令安装:sudo apt-get install openssh-server(虚拟机版本不一样命令也不一样)
启动ssh服务:sudo service ssh start
3.2.1修改ssh配置文件
非必须要修改:
分别在hadoop1与hadoop2、hadoop3 在虚拟机Hadoop2中执行“vi /etc/ssh/sshd_config”命令编辑配置文件sshd_config。
改为PermitRootLogin yes
重启SSH服务 systemctl restart sshd
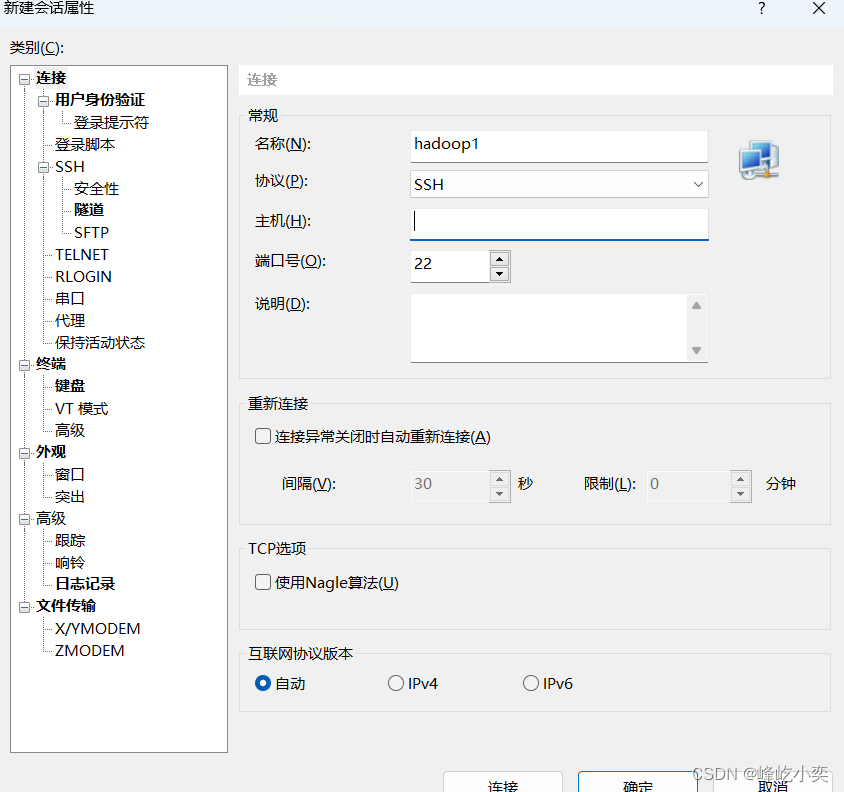
3.2.2在xshell中进行连接
输入主机ip:
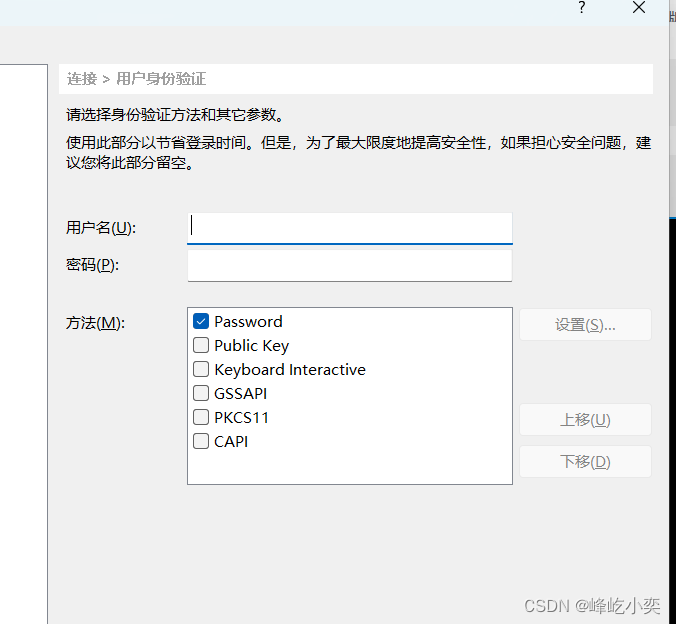
输入用户名密码:
连接成功:

3.2.3配置虚拟机ssh免密登陆功能
在虚拟机Hadoop1中执行“ssh-keygen -t rsa”命令,生成密钥
复制公钥文件
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
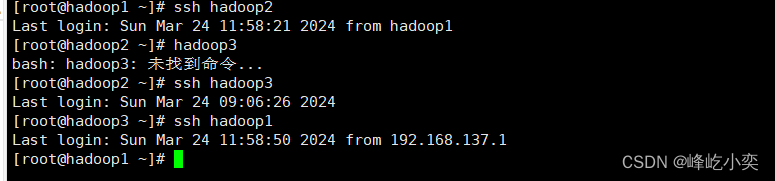
之后再测试免密登陆 第一次输入命令可能需要密码
确保他们直接跳转的时候不需要密码
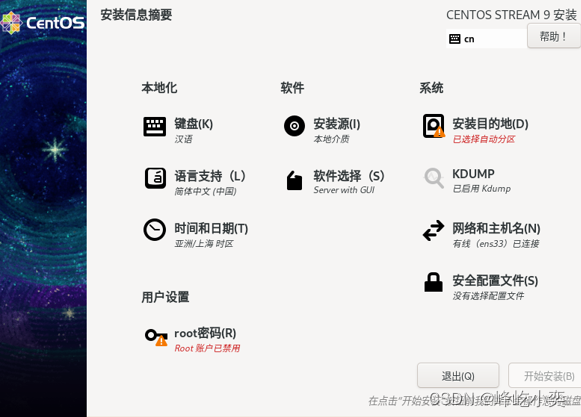
四、安装jdk与hadoop
4.1从某些镜像网站上下载jdk1.8与hadoop的压缩包(这里我用的是hadoop3.2.4版本的、可以从清华大学镜像网站上下载这些资源)
下载完成都上传到linux虚拟机上(注:要使用专门的软件上传例如Xftp 7,不能直接复制到虚拟机中,否则会后续可能会报错。)
结果:

4.2解压hadoop与jdk
将jdk解压到了 /hmzfy/servers/文件夹中
tar -zxvf jdk-8u241-linux-x64.tar.gz -C /hmzfy/servers/
在虚拟机Hadoop1执行“vi /etc/profile”命令编辑环境变量文件profile,在该文件的底部添加配置JDK系统环境变量
export JAVA_HOME=/hmzfy/servers/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
初始化系统环境变量source /etc/profile
将hadoop解压到文件 /hmzfy/servers/hadoop 注意压缩包的位置
tar -zxvf /software/hadoop-3.2.4.tar.gz -C \ /hmzfy/servers/hadoop
配置环境变量同上 打开vi /etc/profile
export JAVA_HOME=/hmzfy/servers/jdk1.8.0_241
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
查看jdk与hadoop时候 下载成功

4.3分别在hadoop1、2、3上关闭防火墙
暂时关闭:systemctl stop firewalld
永久关闭:systemctl disable firewalld
五、修改hadoop配置文件实现基于完全分布式模式
5.1配置hadoop运行时环境
在虚拟机Hadoop1的/hmzfy/servers/hadoop/etc/hadoop/目录,执行“vi hadoop-env.sh”命令,在hadoop-env.sh文件的底部添加如下内容
注意 如果没能成功打开目录那你是以上的目录名写错了可以直接点开目录查看,如果觉得jdk1.8.0_241名字太长可以修改一下文件夹的名字
export JAVA_HOME=/hmzfy/servers/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
在虚拟机Hadoop1的/hmzfy/servers/hadoop/etc/hadoop/目录,执行“vi core-site.xml”命令添加如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hmzfy/data/hadoop-3.3.0</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
配置HDFS
在虚拟机Hadoop1的/hmzfy/servers/hadoop/etc/hadoop/目录,执行“vi hdfs-site.xml”命令添加如下内容。
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>
配置MapReduce
在虚拟机Hadoop1的/hmzfy/servers/hadoop/etc/hadoop/目录,执行“vi mapred-site.xml”命令添加如下内容。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.Webapp.address</name> <value>hadoop1:19888</value>
</property>
在虚拟机Hadoop1的/hm/servers/hadoop/etc/hadoop/目录,执行“vi yarn-site.xml”命令添加如下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
配置Hadoop从节点服务器
在虚拟机Hadoop1的/hmzfy/servers/hadoop/etc/hadoop/目录,执行“vi workers”命令,将workers文件默认的内容修改为如下内容。
hadoop2
hadoop3
5.2分发hadoop安装目录及环境变量
使用scp命令
scp -r /hmzfy/servers/hadoop root@hadoop2:/hmzfy/servers/
scp -r /hmzfy/servers/hadoop root@hadoop3:/hmzfy/servers/
scp /etc/profile root@hadoop2:/etc
scp /etc/profile root@hadoop3:/etc
5.3格式化
在虚拟机Hadoop1执行“hdfs namenode -format”命令,对基于完全分布式模式部署的Hadoop进行格式化HDFS文件系统的操作
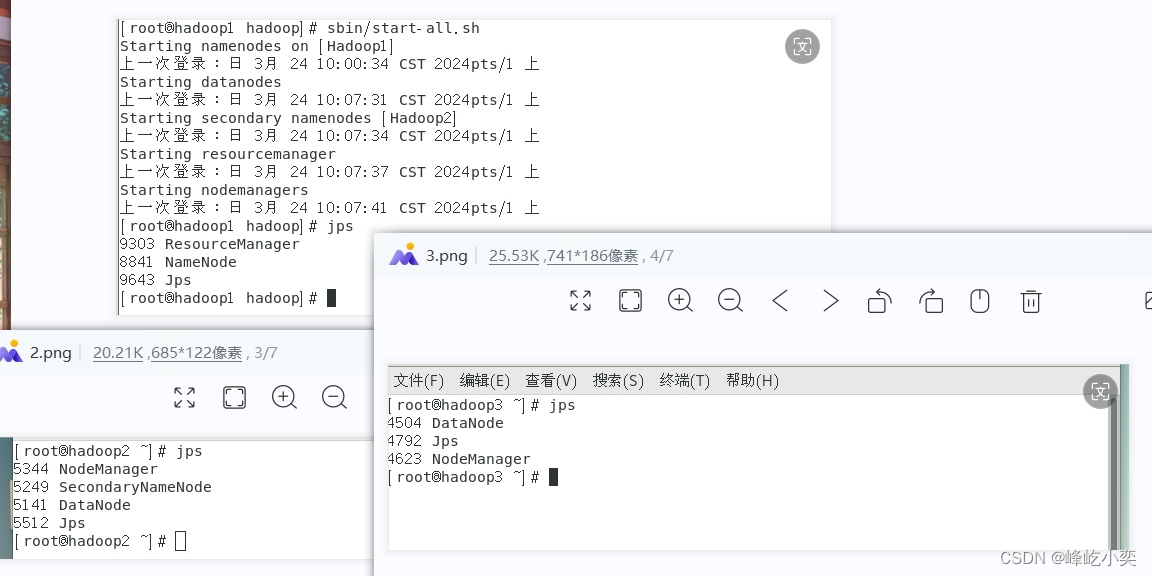
5.4、启动
在hadoop安装目录下执行
启动:sbin/start-all.sh
关闭:sbin/stop-all.sh
博主制作文章需要付出巨大的努力和心血制作不易!!如果对你有帮助的话 不妨点个赞噢!
博主渴望读者的关注和赞赏,因为这是对他们辛勤工作的最好认可和鼓励。
博主希望读者能够欣赏他们的专业知识和独到见解,同时也希望读者能够积极参与讨论,分享自己的看法和经验
文章中也有许多不足之处但希望能帮助大家获取些经验,大家可根据自己的需求自行学习安装
















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









