






目录
HTTP协议的请求/响应格式
HTTP是典型的“一问一答”模式的协议。即一次客户端请求对应一次服务器响应。
HTTP是一个“文本”格式的协议。本质上,一个HTTP数据包,就是按照HTTP协议的报文格式,构造出一串文本,写入到 tcp socket中。
一个HTTP请求报文如下,分成4个部分:

1)首行
首行又包含3个部分,请求的方法(GET),请求的url(请求的对方的网址),版本号。使用空格来区分这三个部分。
![]()
2)请求头(header)
header中可以包含若干行数据。此处本质上是一个“键值对”结构,每一行是一个键值对,键和值之间使用:分割。
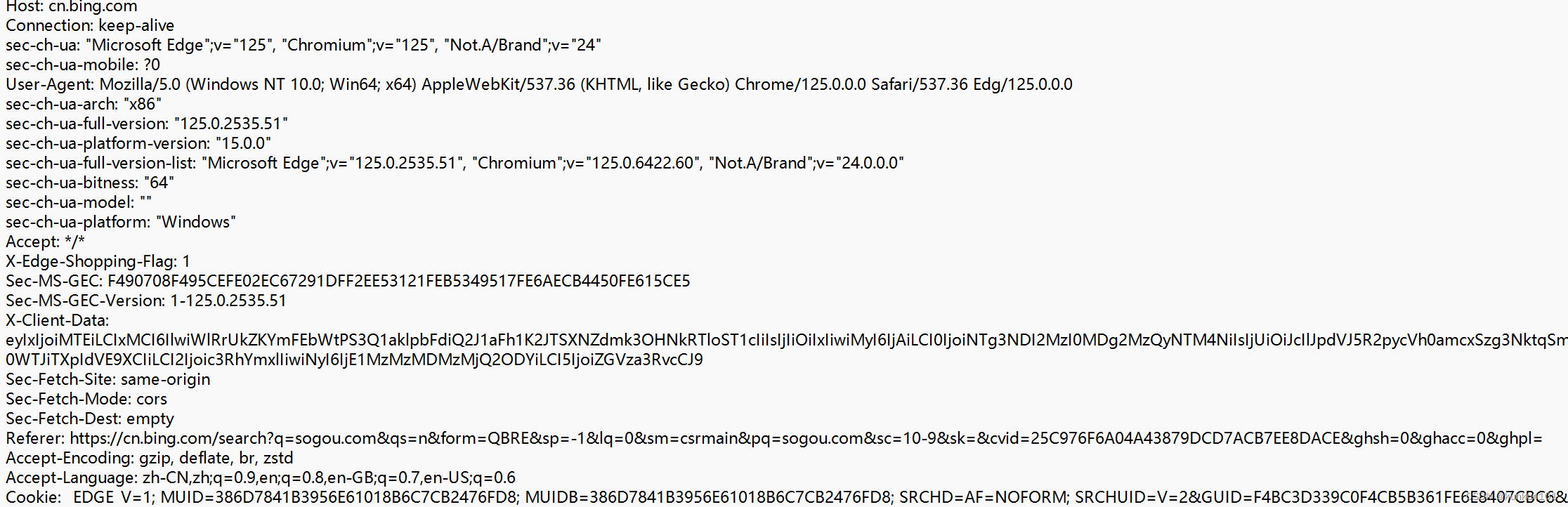
3)空行
最后一个header后面,存在一个空行。作为结尾。
4)正文(body)
相当于tcp/ip协议的载荷数据一样,是要真正要传输的业务数据。
是可选的,请求报文中有些情况下显示正文。有的情况下没有。
HTTP响应也是有四个部分的。与请求格式非常相似。
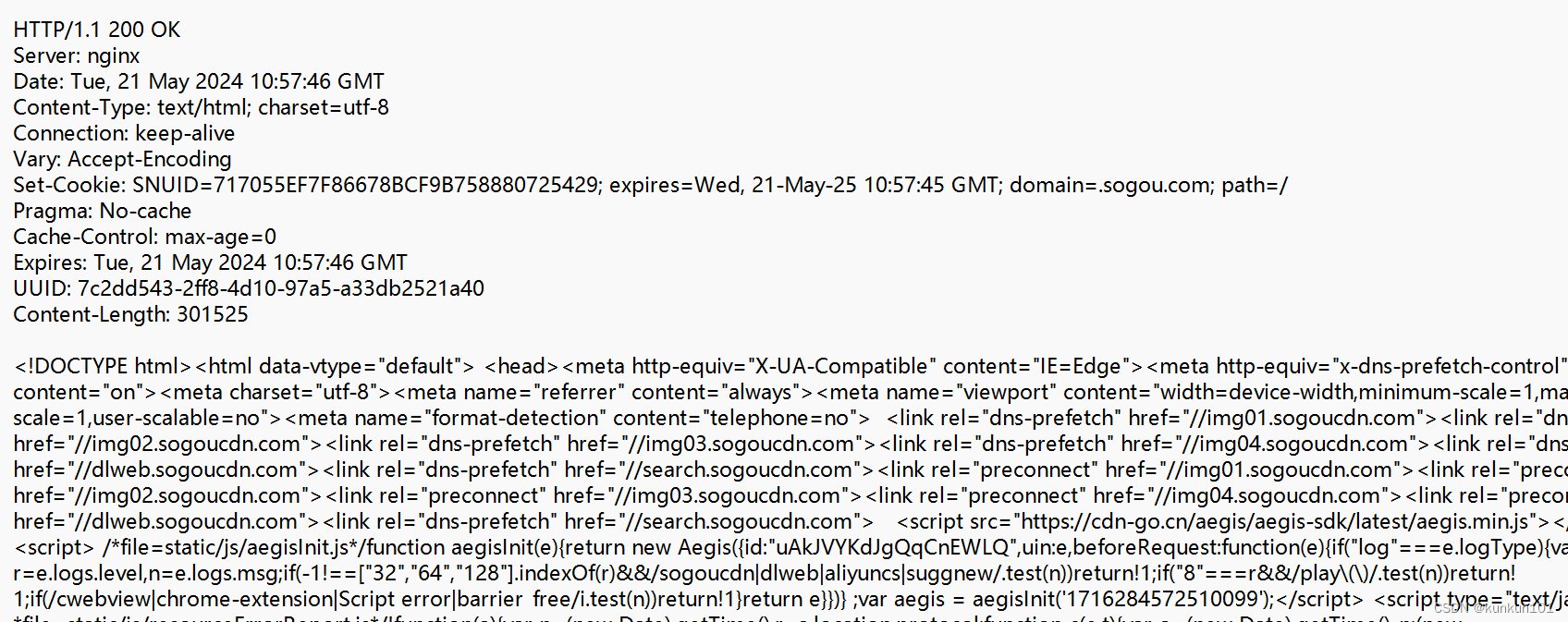
1)响应的首行
首行分为三部分:版本号,状态码,状态码描述
状态码表示这是一个成功的响应,还是一个失败的响应。如果失败了,具体是啥原因。
200 OK 就是成功了。
![]()
2)响应的报头 header
3)空行
4)正文
注:正文中的空行没有特定含义,表示正文内容。只有HTTP数据包中的第一个空行,才是header的结束标记。
URL
我们平时说的“网址”其实就是说的URL(统一资源定位符)。互联网上每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。

协议方案名:标识不同的协议名,描述url接下来要干啥。
登录信息认证:上古时期登录认证的方式,现在已经没人这样进行登录了。
服务器地址:描述要访问的服务器是哪个。一般是ip地址/域名
服务器端口号:访问服务器的哪个端口。url中的端口号可以省略不写。不写的时候,浏览器会设置一个默认的端口。这个端口是固定的“服务器”的端口,是目的端口,是服务器自己决定的。而客户端的源端口号是系统自动分配的空闲端口。
如果是http协议,端口号会使用80.
如果是https协议,端口使用443.
带层次的文件路径:描述了要访问服务器的哪个资源。一个服务器,可以提供很多资源供外界访问。比如,web服务器(网站),就可能会包含很多不同的网页,就可以通过这里的路径区分不同的网页了。
结合ip确定主机,结合端口号确定主机上的程序,结合路径确定程序里的哪个资源。综合上述三个部分,就可以确定互联网上唯一的一个资源了。
查询字符串(query string):往往确定了资源之后,还需要给出一些补充信息。查询字符串就是一些参数,通过参数,把客户端想传给服务器的数据告知过去。
片段标识符:区分页面中的不同部分。目录/导航的效果,在文档类的网站中比较常见。
urlencode
url中,存在很多特殊的符号,像/?:等这样的字符,已经被url当做特殊意义理解了.因此这些字符不能随意出现.⽐如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进⾏转义。
汉字经常是utf8/gbk编码方式,如果汉字的utf编码中,恰好某个字节和某个特殊符号(/?:&)ascii值重复了,此时就可能导致解析的时候出问题。为了避免这样的情况,就引入了urlencode这样的机制。
转码规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不⾜4位直接处理),每2位做 ⼀位,前⾯加上%,编码成%XY格式
![]()
HTTP方法
HTTP请求首行里,包含了方法,方法描述了“语义”,就是这次请求要干啥。
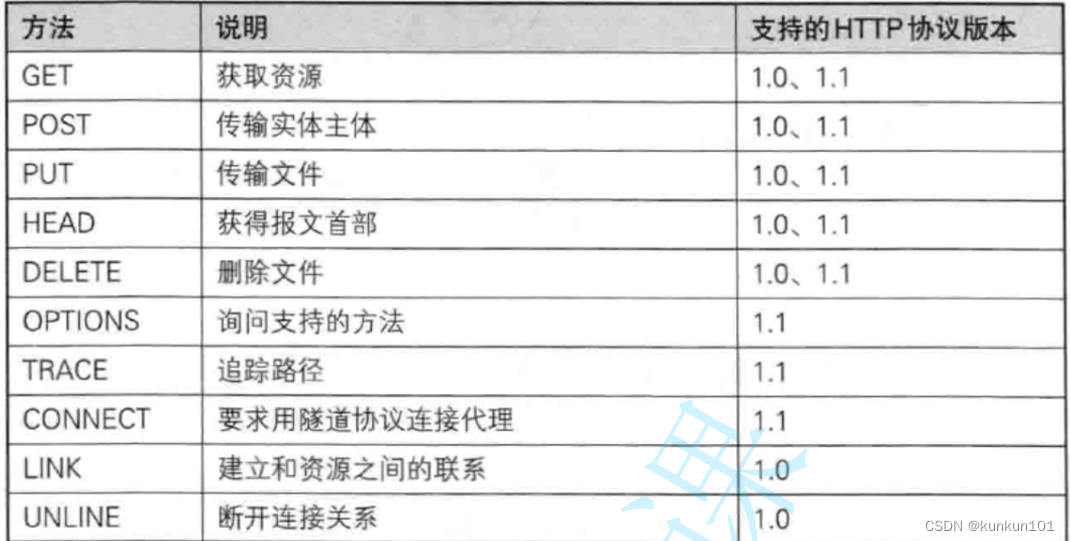
HTTP中的方法,有很多种,常用的有两种:GET和POST。
GET语义从服务器获取某个数据。
POST语义往服务器发送/提交数据。
实际编程中使用这俩方法的时候,对应的语义已经存在一些更模糊的东西了。实际开发中,GET也可以用来提交某个数据,使用POST也能获取某个数据。
使用习惯上,GET通常不会搭配body,有需要传输的数据,通过query string。
POST则通常不搭配 query string,通过body传输数据。
上述HTTP请求,都是如何构造的呢?
GET
1)在浏览器地址栏,直接输入url,此时就是GET请求。点击收藏夹,同理的效果。
2)网页html中可能有一些特殊的标签。img/a/link 这些标签,会带有一个url作为属性。页面被浏览器加载之后,解析到这些标签,就会根据url构造出新的http请求。
3)表单 html中的特殊标签form
4)通过js构造,比如使用原生的ajax api/jquery的ajax api /一些第三方库axios, fetch等。
POST
1)表单
2)js
剩下的请求只有通过js。
经典面试题:谈谈GET和POST有啥差别。
从本质讲,没有区别。GET的应用场景,使用POST也可以。POST的应用场景,GET也可以。
从使用习惯的角度,还是有区别的。
1)GET从语义上讲,通常用来“获取数据”。POST从语义上讲,通常用来“提交数据”。
2)GET传递数据的时候,通常使用query string。POST传递数据的时候,通常使用body。
3)服务器对于GET请求的设计,经常是设计成“幂等”的。而POST请求的设计,则不要求“幂等”。
幂等性: 在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
比如,要执行“支付10块”操作,假设账户余额是100,支付操作就期望支付之后,余额90。此时一不小心把支付操作,重复发送了。但是没关系,这两次支付操作,都能得到余额90(只有一次真正扣款了)。这样的操作就认为是稳定的,幂等的。
4)GET请求的结果可以被缓存,可以被浏览器收藏夹收藏。POST一般不行。
下列几个说法都存在问题:
1)POST比GET更安全
论据:在提交登录请求这一下,如果使用GET,GET把参数放到url中,url会显示到浏览器地址栏。
这个论据是不太成立的。POST请求也一样不安全。不是说密码显示到浏览器地址栏就不安全,也不是说放到body中就安全。安全不安全,取决于是否加密。并不能说明POST比GET更安全。
2)GET传输的数据量比较有限,比较短。POST传输的数据量比较长,没有限制。
HTTP标准中,明确说了一句话,针对GET的url的长度是不做任何限制的。实践中,是可以构造一个很长的url的。
这是因为上古时期IE浏览器对于url的长度做出了限制(url长度超过一定的数值,就会请求失败)。现在已经没有了。
3)GET只能传输文本数据,POST可以传输二进制,也能传输二进制。
url的query string中提供了 urlencode机制,二进制数据,也是可以进行encode,得到转义,并进行传输。虽然POST可以直接传二进制,很多时候,也是转义了之后通过文本的方式来传的。
以上,关于http协议,希望对你有所帮助。















 3113
3113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









