







一.表达式求值
1.1 表达式求值
求值的顺序一般根据操作符的优先级和结合性来决定。但是有些表达式的操作符在求值的过程中可能需要转换为其他类型
1.2 隐式类型转换
c的整型算术运算总是以缺省(默认)整型的精度来进行的
为了获得这个精度,表达式中的字符型和短整型操作数在使用之前需要转换为普通整型(int),这种转换称为整型提升
1.3 整型提升的意义
表达式的整型运算要在CUP的相应运算器件内执行,CPU内整型运算器(ALU)的字节长度一般就是int的字节长度,同时也是CPU的通用寄存器的长度
因此两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度
(虽然计算机中可能有这种字节相加的指令(Adc指令))。表达式中各种长度可能小于int长度的整型值,都必须先中转换为一个int或unsigned int,然后送入CPU中区执行运行
1.4 如何整型提升
如何整型提升?
正数的整型提升
char a = 1;1的补码存在char所开辟的空间中,即 : 00000001(因为char是一个字节只能存8个bit,即将5的补码后8位截取(从低位开始截取))
整型提升后:00000000000000000000000000000001(有符号类型高位补原符号)
负数的整型提升
char a = -1;同上
-1的补码:10000001
整型提升后:11111111111111111111111110000001
无符号整型,整型提升高位补0
例1:
char a = 5;
char b = 126;
char c = a + b;
printf("%d", c);
因为a,b在进行整形运算,又因为a,b是两个字符,一个字符在内存中开辟的空间是容纳不下一个整型的,所以这时候就需要系统将a,b整型提升之后在运算
没整型提升之前a,b,c在内存中存储的内容为(以补码的形式):
5的补码存在char所开辟的空间中,即 : 00000101
同理,126的补码: 01111110
当a和b开始整型计算的时候,他们需要先整型提升后在进行运算
即:
5整型提升之后:00000000000000000000000000000101
126整型提升之后:00000000000000000000000001111110
在将他们相加得到:00000000000000000000000010000011
因为我们的操作完之后放在char c中所以这时又需要截断
c得:10000011(-3)
又因为题目让我们以%d得形式打印,所以先将a整型提升得:11111111111111111111111110000011(signed char 补原符号)
因为负数得原码得算所以(1.对补码取反加1得到原码 2.对补码减1取反也可以 )
原码得:10000000000000000000000001111101(-125)
例2:
#include <stdio.h>
int main()
{
char c = 1;
printf("%zu\n", sizeof(c));
printf("%zu\n", sizeof(+c));
printf("%zu\n", sizeof(-c));
return 0;
}1. sizeof(c)
因为c就是char类型的数据所以得到的结果为:1
2. sizeof(+c)/sizeof(-c)
因为c参与了表达式运算,即c进行了整型提升,所以sizeof(+c)/(-c)得:4
1.5 寻常算术转换加操作符优先级表格
(signed) long double
(signed) double
(signed) float
unsigned long int
(signed) long int
unsigned int
(signed) int //从下往上向大类型转换,表达式求值同一个类型时 signed ——> unsigned操作符优先级表格
| 优先级 | 运算符 | 名称/含义 | 使用形式和用法示例 | 结合性 | 说明 | 是否控制求值顺序 |
| 1 | () | 圆括号 (聚组) | (表达式) | (x + y) | 左 --> 右 | -- | 否 |
| () | 函数调用 | 函数名(形参表) | add(x, y) | -- | |||
| [ ] | 下标引用 | 数组名[常量表达式] | array[5] | -- | |||
| . | 成员选择(对象) | 对象.成员名 | stu.a | -- | |||
| -> | 用指针访问结构体 | 对象指针.成员名 | stu->a | -- | |||
| 2 | ++ | 后置++ | 变量名++ | num++ | 左 --> 右 | 单目运算符 | 否 |
| -- | 后置-- | 变量名-- | num-- | ||||
| ! | 逻辑非 | !表达式 | !a | 右 --> 左 | |||
| ~ | 按位取反(二进制位) | ~表达式 | ~a | ||||
| + | 正号运算符 | +表达式 | +1 | ||||
| - | 负号运算符 | -表达式 | -1 | ||||
| ++ | 前置++ | 表达式++ | num++ | ||||
| -- | 前置-- | 表达式-- | num-- | ||||
| * | 间接访问(解引用) | *指针变量 | *p | ||||
| & | 取地址运算符 | &变量名 | &a | ||||
| sizeof | 求变量的长度,单位字节 以数据类型为准,不计算内部表达式 | sizeof(表达式) | sizeof(int) | ||||
| (类型) | 强制类型转换 | (数据类型)表达式 | (char)a | ||||
| 3 | / | 除 | 表达式/表达式 | a / b | 左 --> 右 | 双目运算符 | 否 |
| * | 乘 | 表达式*表达式 | a * b | ||||
| % | 余数(取模,两边只能是整数) | 表达式%表达式 | a % b | ||||
| 4 | + | 加 | 表达式+表达式 | a + b | |||
| - | 减 | 表达式-表达式 | a - b | ||||
| 5 | << | 左移 | 变量<<表达式 | a << 1 | |||
| >> | 右移 | 变量>>表达式 | a >> 1 | ||||
| 6 | > | 大于 | 表达式>表达式 | a > b | 左-->右 | 双目运算符 | 否 |
| >= | 大于等于 | 表达式>=表达式 | a >= b | ||||
| < | 小于 | 表达式<表达式 | a < b | ||||
| <= | 小于等于 | 表达式<表达式 | a <= b | ||||
| 7 | == | 等于 | 表达式==表达式 | a == b | |||
| != | 不等于 | 表达式!=表达式 | a != b | ||||
| 8 | & | 按位与(二进制位)(有0为0,不同为1) | 表达式&表达式 | a & b | 左-->右 | 双目运算符 | 否 |
| 9 | ^ | 按位异或(二进制位)(相同为0,不同为1) | 表达式^表达式 | a ^ b | |||
| 10 | | | 按位或(二进制位)(有1为1,没1为0) | 表达式|表达式 | a | b | |||
| 11 | && | 逻辑与(左边为0,右边断路) | 表达式&&表达式 | a && b | 是 | ||
| 12 | || | 逻辑或(左边为真,右边断路) | 表达式||表达式 | a || b | |||
| 13 | ?: | 条件运算符 | 表达式1?表达式2: 表达式3 | 无 | 三目运算符 | 是 |
| 14 | = | 赋值 | 变量=表达式 | a = 2 | 右 --> 左 | 双目运算符 | 否 |
| /= | 除等于 | 变量/=表达式 | a /= 2 | ||||
| *= | 乘等于 | 变量*=表达式 | a *= 2 | ||||
| %= | 取余等于 | 变量%=表达式 | a %= 2 | ||||
| += | 加等于 | 变量+=表达式 | a += 2 | ||||
| -= | 减等于 | 变量-=表达式 | a -= 2 | ||||
| <<= | 左移后赋值 | 变量<<=表达式 | a <<= 2 | ||||
| >>= | 右移后赋值 | 变量>>=表达式 | a >>= 2 | ||||
| &= | 按位与后赋值 | 变量&=表达式 | a &= 2 | ||||
| ^= | 异或后赋值 | 变量^=表达式 | a ^= 2 | ||||
| |= | 按位或后赋值 | 变量|=表达式 | a |= 2 | ||||
| 15 | , | 逗号运算符(表达式都执行,结果为最后一个表达式的值) | 表达式,表达式,....... | 左 --> 右 | -- | 是 |
如果我们写出得表达式不能跟据操作符(运算符)的优先级确定唯一路径,那我们写出的表达式就是有错的
二. 深度刨析数据在内存中的存储
1.1 数据类型介绍
c语言提供的一些基本的内置类型
类型 开辟内存空间的大小(字节)
char (字符型) 1
short(短整型) 2
int (整型) 4
long (长整型) 32位/64位 4/8
long long (更长的整型) 8
float (单精度浮点型) 4
double (双精度浮点型 8
1.2 整型的基本归类
整型家族(int类型在limits.h的头文件中定义):
char(字符型,因为本质是ASCII码值,所以划分到整型家族)
unsigned char signed char
int
unsigned int
signed int
short
unsigned short [int]
signed short [int]
long
unsigned long [int]
signed long [int]
long long
unsigned long long [int]
signed long long [int]int a; ---> signed int a; 是一样的
1.3 unsigned 和 signed 的区别以及用法
例:生活中有些数据是没有负数的如:身高,体重,长度... 像这些数据就可以用unsigned加以修饰
signed int a = 0;//有符号 00000000000000000000000000000000 最左边的0就是符号位(1表示负,0表示正)
unsigned int high = 0;//无符号 00000000000000000000000000000000 此时这个值就没有符号位了最左边的数为有效数加入计算
总结:如果创建的数据没有负数就用unsigned,有负数就用signed
1.4 浮点型的介绍和基本归类
浮点型家族:只要表示小数就可以用浮点型
float的精度低,储存的数值范围小(精确到后六位)
double的精度高,储存数值范围大 (精确到后十五位)
1.5 构造类型:自定义类型 - 用户创建新类型
数组类型 int a[5] //根据需求可以创建不同的数组
结构体类型 struct
枚举类型 enum
联合类型 union1.6 指针类型
int* pi;
char* pa;
float* pc;
void* pd;
1.7 空类型
void 表示空类型(无类型)
通常用于函数的放回类型,函数参数,指针参数
void test (void)函数无返回值,函数无参数,参数表中有void,传参会报警告。无void传参就不会报警告
作为指针类型
void* pa;
2.0 整型在内存中的储存
整数是以补码的二进制序列存于内存中的
正负整数均有原码,反码,补码
正:三码和一(三码一致) 负:三码都不同,所以需要算
算法:原码取反加1就得到补码
为什么整数以补码得形式存在内存中了?
在计算机系统中,数值一律用补码表示和存储,原因在于使用补码可以将符号位和数值域统一处理(CPU只有加法器)此外,补码与原码互相转换其原理是相同的,不需要额外的硬件电路
例
1+(-1)用补码计算
用8位表示
00000001 + 11111111 得:100000000 多出一位,最高位丢弃为:00000000(0)
2.1 大小端的认识
例:
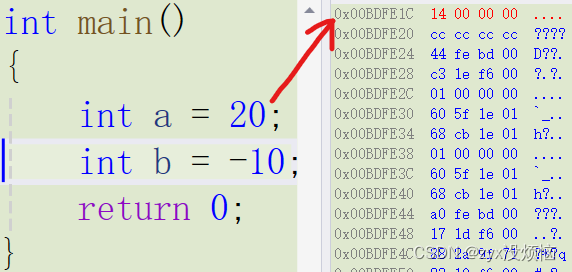
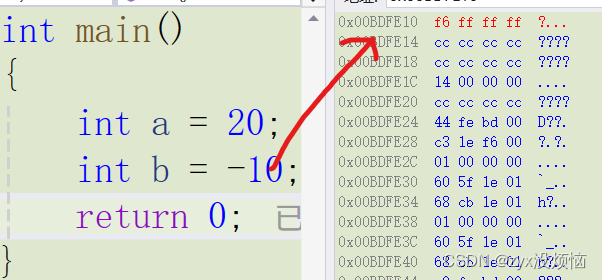
20的十六进制补码为:0x00000014
-10的十六进制补码为:0xfffffff6
以 20 和 -10 为例它们在内存中以十六进制补码形式存储在内存中,那它们为什么会以这些的顺序存储了,这里就开始进入了大小端的概念
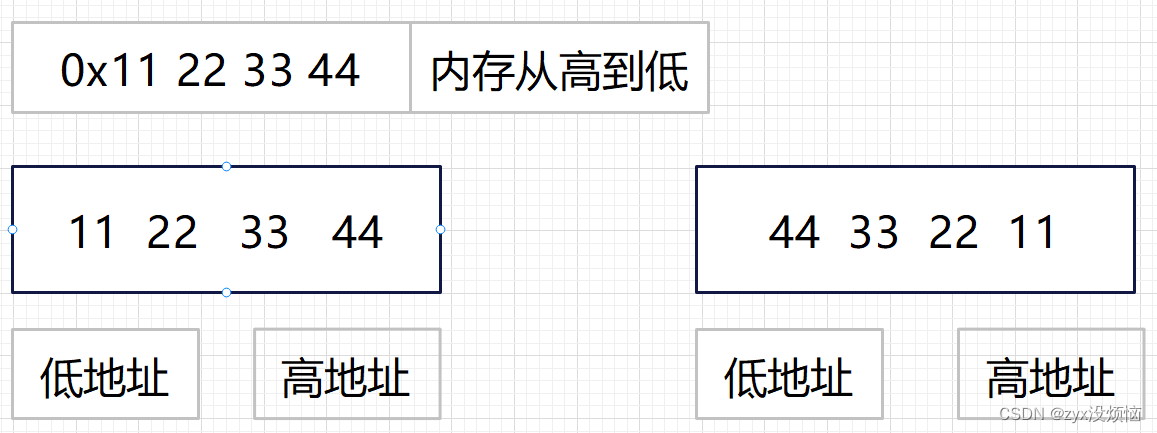
上图低高地址位置随意,不止倒叙和正序,其他存放顺序没意义,所以这里以倒叙和正序为例
十六进制一个数字代表4bit两个数字就是1byte
11 22 33 44 ——>大端字节序存储(正序)
44 33 22 11 ——>小端字节序存储(倒序)
大端字节序存储:把一个数据的高位字节序的内容存放在低地址处,低字节序的内容存放在高地址处
小端字节序存储:把一个数据的高位字节序的内容存放在高地址处,低字节序的内容存放在低地址处
例:百度2015系统工程师笔试题
判断这个机器是大端还是小端:
#include <stdio.h>
int check_sys()
{
int a = 1;
return *(char*)&a;
}
int main()
{
ret = check_sys;
if(ret)
{
printf("小端");
}
else
{
printf("大端");
}
return 0;
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









