






目录
第一次作业
基于度量分析程序结构
类复杂度:
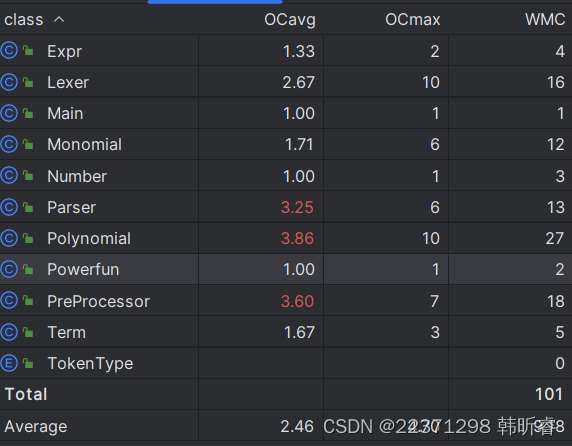
可以看到,预处理类、解析类和多项式类爆红,这主要是因为它们中含有较多的面向过程性的方法所致。(字符串操作、逐个解析、多项式转化为字符串)
方法复杂度:
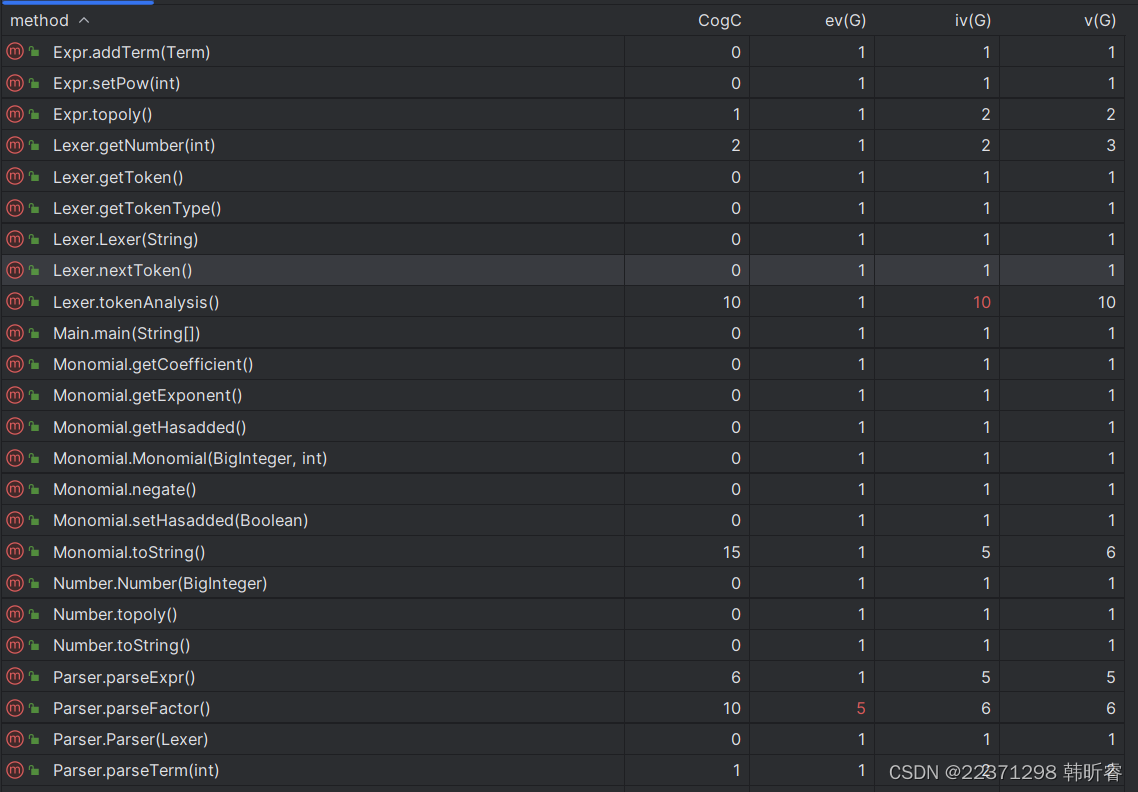
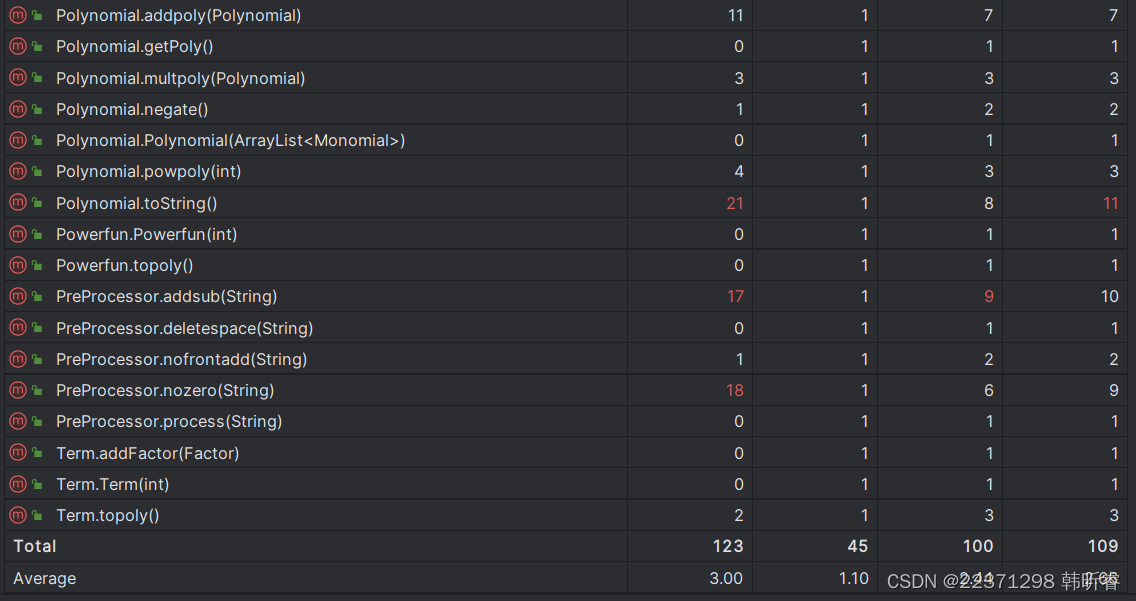
爆红的方法,主要是预处理类中的去除连续+-号,去除前导0的方法,Parser类中的解析不同因子的方法,Poly类中的将多项式最终转化为字符串的方法,这与之前的分析相符。
UML类图

架构设计体验
在第一次作业之初,由于对面向过程编程中利用栈分析并计算表达式的方法太根深蒂固,导致我经历了一段较为痛苦的设计历程。我完全不理解如何层次化解析表达式,建立表达式树模型,使得表达式可计算,尤其是面对着后续将要多层括号嵌套的情形时。在仔细阅读了实验、训练用的代码和课程组提供的递归下降法技术文档后,我终于明白了递归下降法的原理和效果,理解了其实现流程。首先,我用PreProcessor类实现了对字符串的预处理。
1.PreProcessor类:根据题目要求,封装了对字符串的预处理,包括去除空白符、去除前导零、合并连续加减号和去除多余正号。
2.因子建模:根据表达式的定义,因子是表达式的底层单元,因此需要先对因子进行建模。这包括常数因子、幂函数因子和可递归的表达式因子。又因为它们都是“因子”,在行为上有许多相似的地方,因此可以利用“因子”接口来统一管理这些类,使得各种行为的实现更加方便。
3.语法分析:语法分析即解析表达式,对表达式建树。根据递归下降法,首先实现了一个Lexer类用于解析表达式中的“单词”,即可解析的最小单元;然后实现了一个Parser类,实现对表达式(逐个读取项和+-号)、项(逐个读取因子和*号)、因子的读取,自顶向下建立了表达式树。
建立好表达式树后,下一步要解决的就是计算问题。经过观察,可以发现第一次作业最终的结果都可以化为的多项式的形式,并且计算过程中产生的每一步中间结果也都可以化为这样的形式。因此,我们采用这种形式对各种结果进行建模,并统一计算:
4.形式标准化:建立了一个单项式Mono类和多项式Poly类,多项式由单项式构成的ArrayList构成,单项式由系数coe、指数pow两个属性构成。对于底层因子常数、幂函数,建模为只有一个Mono的Poly;而项的Poly由各因子Poly相乘而成,表达式的Poly由各项Poly相加而成,Poly类中实现多项式相加、相乘和求幂的方法。这样,我们就在各个类中实现了toPoly标准化方法,递归地将整个表达式转化为了Poly的标准形式。
5.计算和输出:由上述形式标准化过程,在对整个表达式进行toPoly的过程中,实际上已经递归地进行了计算,最终在单项式和多项式类中分别实现toString方法,以完成对表达式Poly的输出即可。
Bug分析
分析自己的Bug:
在提交前,我进行了一定数量的本地测试,发现了两个Bug:
1.读入指数为1的表达式时会崩溃退出,这是在Parse表达式时忘了有些表达式的指数1可以忽略,对每个表达式读取完后,都强制进行了一次^和数字的读取所致。
2.输入为0时直接没有输出,在多项式的toString方法中先特判一下,若整个表达式值为0,则返回0,即可解决问题。
由于本地测试较为充分,且第一次要求的功能尚为简单,因此在公测和互测中没有发现Bug。
分析别人的Bug:
在互测中,我选取了几个较为常见的Bug进行测试,但并没有发现别人的Bug,只有一人在运行较大规模的数据(如表达式指数达到6)时结果正确但TLE,可能是由于其乘法的实现方式过于低效所致。
优化分析
第一次作业中,优化的空间还较少,主要为以下几个方面:
1.系数优化:系数为0时,整个单项式不显示;系数为1或-1时,省略系数。
2.指数优化:指数为0时,视为常数;指数为1时,省略指数。
3.正项提前:要输出的第一个单项式为负时,先向后遍历一遍整个多项式,如果有正的,则将这一正项提前至最前输出。
只要做了以上三点优化,就可以保证自己的输出一定是最短的可能输出。
第二次作业
基于度量分析程序结构
类复杂度:
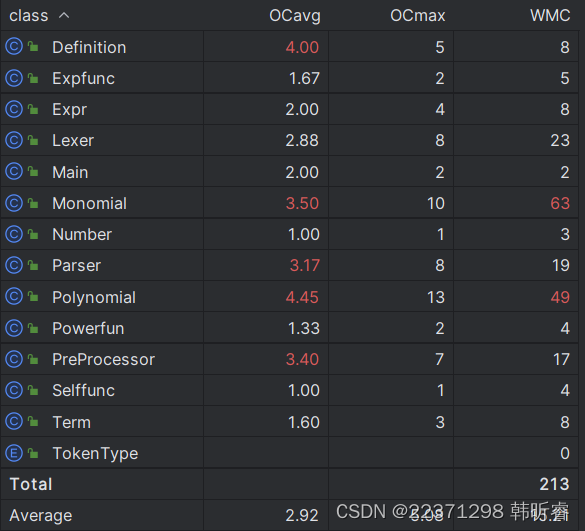
与上一次相比,这次单项式类的复杂度也大幅增加,原因是这次单项式类转化为字符串的方法更加复杂了;新增的Definition(自定义函数替换)类也复杂度较高,原因是实参替换时做了较多的字符串操作。
方法复杂度:
复杂度较高的方法主要如下
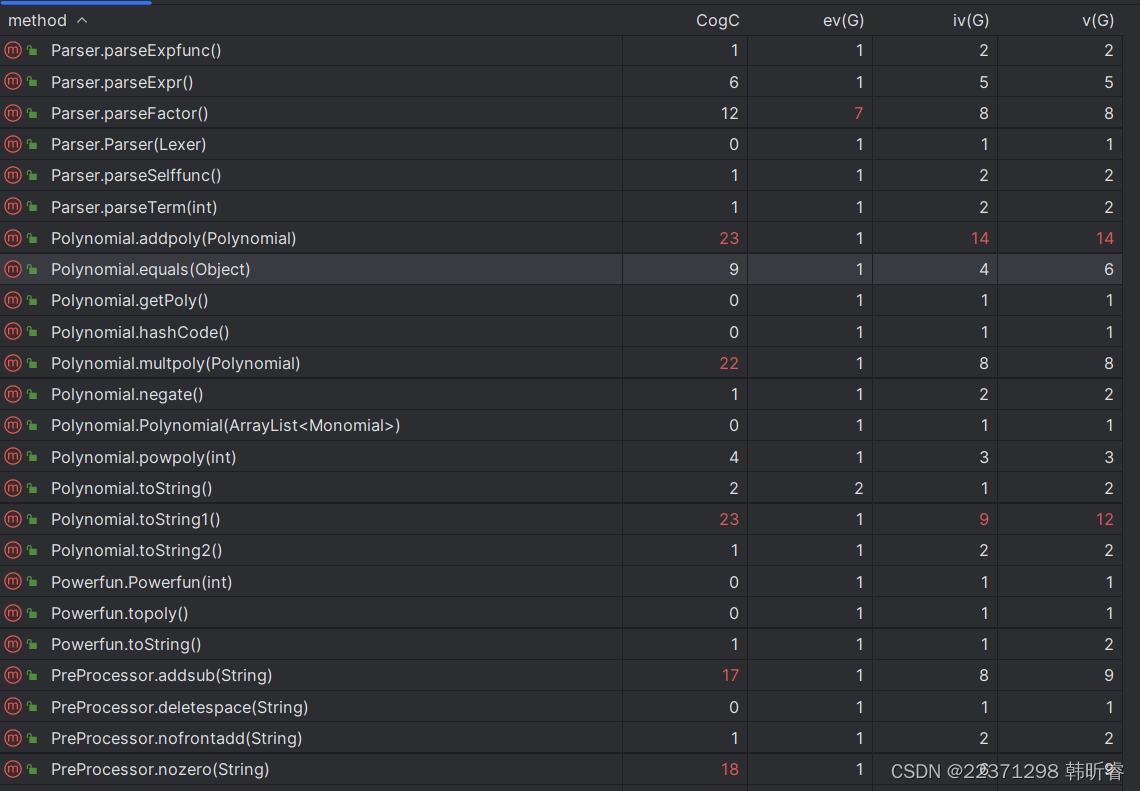
此外,单项式toString时判断是否可以去除不必要的括号的方法,复杂度也较高。
UML类图
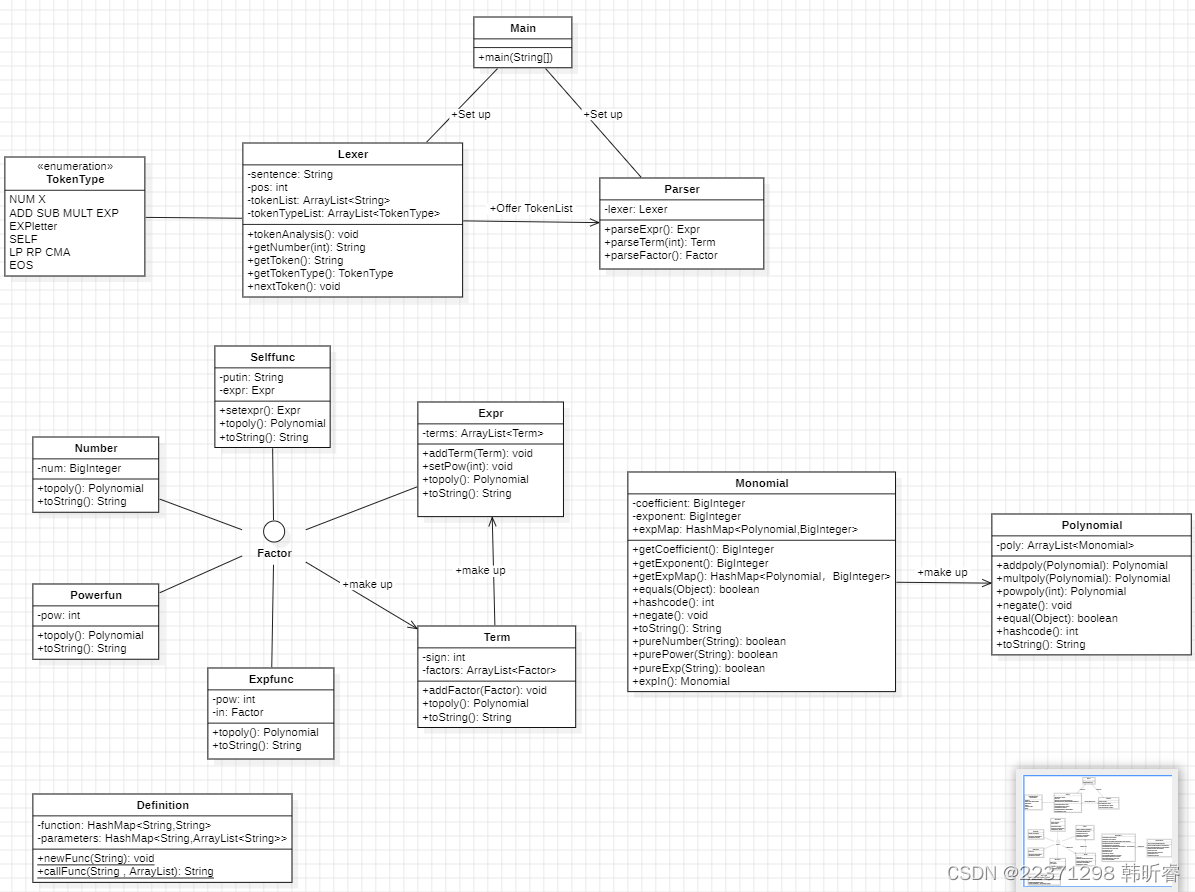
架构设计体验
第二次作业中,提出了更加复杂的要求:允许有自定义函数、允许有指数函数、自定义函数和表达式中均允许括号嵌套。因此,我进行了如下新的架构设计:
1.自定义函数。自定义函数作为一种新的因子类型,必然要新开一个类,并继承Factor接口。那么,这个类该如何设计呢?首先,自定义函数有一个十分明显的属性:实参因子,因此类内应当有一个属性ArrayList<Factor>,在遇到自定义函数时作为构造方法的参数传入。其次,自定义函数还要传入函数名,以区分f,g,h函数。因此,这个类应当有这些属性:函数名、因子列表,具有方法:将该自定义函数转化为标准型的方法toPoly(事关核心功能,也是继承Factor接口所必须的,类似第一次作业)。
方法的实现,就是将实参因子的字符串形式替换进函数定义式,并用parseExpr方法将替换后的字符串转为易于操作和可计算的表达式,再调用第一次作业中已实现的标准化方法(toPoly)即可。由此我们又注意到,每种因子都有可能作为函数的实参,需要被代入,因此需要一个共同的toString方法,因此声明在Factor接口中,并为每种因子实现。
2.指数函数。类似地,指数函数应当具有的属性是:内部的因子,外部的指数。方法是:转化为标准型的toPoly方法,转化为字符串形式的toString方法(代入用)。
3.允许括号嵌套:上述自定义函数的解析方法支持括号和自定义函数的嵌套,递归下降法天然地支持表达式的括号嵌套,因此无需专门改动。
4.计算:考虑到新增了指数函数 exp(因子)^指数,本次作业修改单项式为如下形式:
其中最后的各
和
分别作为键和值用Hashmap存储。多项式Poly仍由单项式相加构成。值得注意的是,单项式中虽又包含了多项式作为组成成分,但由于表达式长度是有限的,最终总会递归到常数、幂函数这些基本单元,因此不会无限递归。
Bug分析
分析自己的Bug:
本次作业在互测中被发现了Bug,是在多个exp嵌套时会超时。在调试的过程中,我发现运行卡在了输出阶段,解析和计算阶段并不花费时间。这说明问题出在了toString上。进一步调试后,观察toString的调用栈,我发现每调用一层exp因子的toString方法,内部因子(转化为多项式后)的toString方法都被调用了4遍,而不是预想的一次逐层递归到最内层就结束了。结合代码,我终于找到了原因:我单项式的toString方法写的过于粗糙,对于单项式中,某个下层多项式的字符串形式,我每次用到这个字符串就调一次toString,而不是一开始就把它用一个字符串s存起来,以后每次访问时访问s即可。修改后,递归开销从4*4*4*4......变成了预期的1*1*1*1......,便直接通过了测试。
分析别人的Bug:
在互测中,我通过阅读别人的代码,发现了一个功能性问题:开始处理表达式时默认表达式的长度至少为2,于是我通过使输入表达式仅含一位数或者x,发现了这个Bug。
优化分析
第二次作业中,优化的方向就较多了:
1.系数优化、指数优化、正项提前同第一次作业。
2.合并同类项。合并同类项是第二次作业的一个难点,主要是要对exp()中的多项式判等。多项式的判等需要两者中的单项式能一一对应相等,而单项式的相等需要中的pow相等,并且存储后面exp因子的哈希表相等。后者的判定,可以使用Java自带的Objects.equal方法实现。
3.去除指数函数因子中不必要的括号,我采用对括号内字符串进行形式化判定的方法实现,即若括号内的字符串满足纯数字,或纯幂函数,或纯指数函数因子的特有形式,就不多加一层括号。
4.指数相乘合并。多个指数函数相乘时,可以利用相乘后“底数不变,指数相加”而进行优化。可以证明,这样做后字符数一定是减少了。这一优化也很简单,只需对各exp()中的多项式调用addPoly方法即可。
5.提取公因式。将各系数的公因数提出,放到exp()的外面。这一优化出于正确性和大多数实际应用场景中效果的考虑,我并未实现。
第三次作业
基于度量分析程序结构
类复杂度:
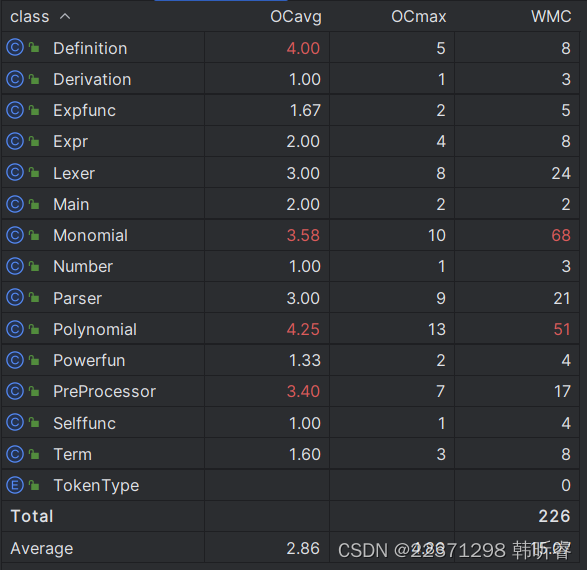
类复杂度仍与上一次作业类似。
方法复杂度:
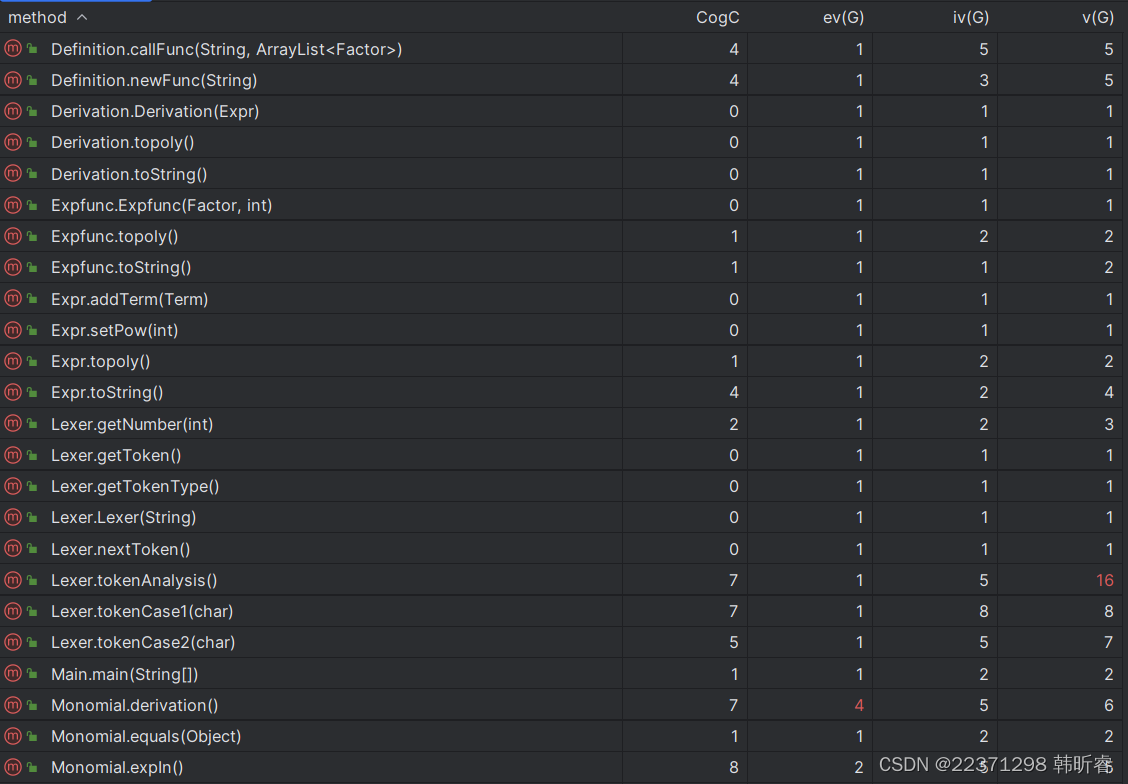
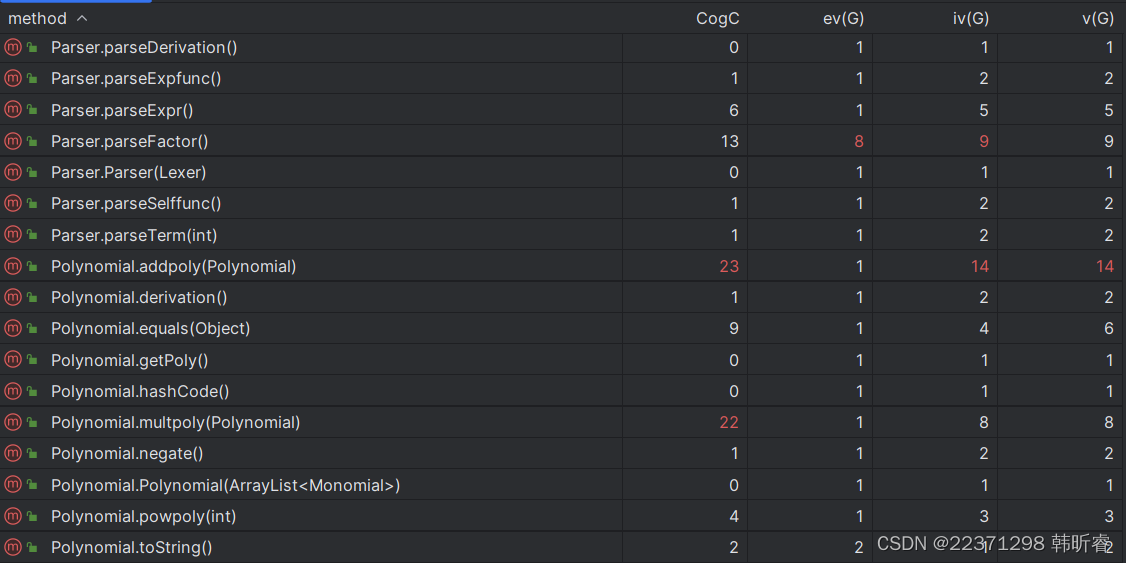
复杂度高的方法仍为面向过程性比较强的方法,如分析不同种类的因子,多项式和单项式的计算(加、乘、求导)方法等。
UML类图
主要变化就是在Factor中,加入了Derivation求导类因子。
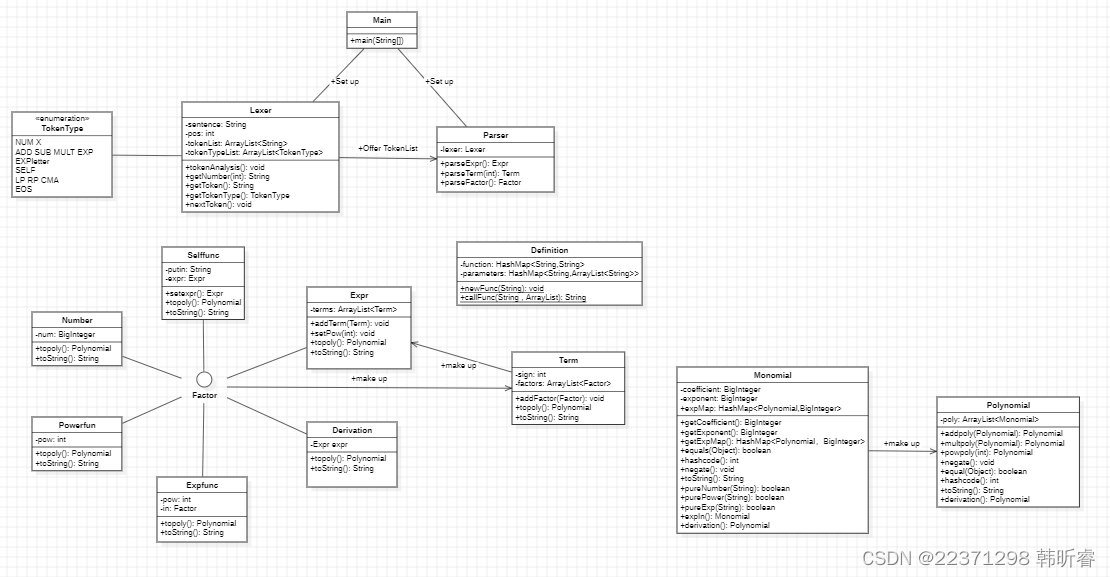
架构设计体验
第三次作业的架构设计可以说是这几次当中最轻松的一次~
本次作业新增要求:自定义函数定义式中允许出现已定义过的自定义函数,新增求导因子。
1. 求导因子:显然,作为一种新的数据类型,且仍然具有之前已有的因子的行为模式,应当新建求导Derivation类并实现Factor接口,类中的属性就是解析求导因子dx()时解析到的括号内的表达式,类中的方法就是Factor接口中要求的各种方法。重点在于toPoly方法,即怎样把求导因子转化为之前所通用的标准型,这是求导方法的具体实现处。
我的做法是,先将括号内的表达式用toPoly转化为标准型,再对标准型调用Poly类中的求导方法,返回一个Poly类对象即可。这样做,既可以极大减少“重复造轮子”,很多地方调用之前已写过的方法即可,又可支持嵌套求导。这样,我们只需具体实现单项式Monomial的求导方法(返回一个Poly对象),Poly的求导对各单项式求导的返回值调用addPoly即可。
2. 函数定义式中允许出现已定义过的自定义函数,这个用之前的架构中所采用的方法,是天然支持的,无需做任何改动。
Bug分析
分析自己的Bug:
本次作业中,在互测中又出现了Bug,而类型竟然和上次遇到的一样。分析之后我发现,我上次是将单项式的toString中,下层toString方法的多次调用优化掉,通过了上次互测中六七个exp嵌套的测试点。而我在多项式的toString中,仍有对下层单项式的toString方法调用了3次的情况,并没有被优化。经测试,这样大概能承受十三个左右括号的嵌套(在1秒左右),而本次作业由于允许函数定义中使用定义过的函数,可能的exp嵌套达可达近三十次之多,于是从十三个嵌套起,我的程序运行时长再次出现了类似上次的指数爆炸,大概每多一层,时间开销正好*3左右。修改后,我的程序即通过了互测数据。
分析别人的Bug:
本次互测中,我并没有查看他人的代码,而是“盲狙”,即预先构造了几个容易出Bug的测试点提交。遗憾的是,未能发现他人的Bug。
优化分析
沿用第二次作业中的优化即可,没有新的需要优化的地方。
心得体会
1.在面向对象设计与构造的过程当中,设计良好的架构是十分有必要的,在这一点上应仔细思考。
2.层次化设计是一种非常好用的思想,每个层次中只关心自己的问题,可以使复杂的问题逐步得到解决,如本单元作业中的表达式、项、因子......
3.合理地划分和设计类,可以使程序分工有序,思路分明;在此基础上,合理运用继承、接口等,实现数据的抽象或行为的抽象,能极大地提高编程效率,如本单元作业中根据需求,将常数、表达式、幂函数等统一用Factor接口管理,使得许多操作十分方便。
4.理解面向对象的设计思想是有一定难度的,我虽上过先导课程,但还是有了些遗忘,所幸能很快重拾起来。在这个过程中,我不止一次感慨,当初要是没有上过OO先导课程,那要在短短几周内理解面向对象的思想,并实现一个复杂的程序,将是多么恐怖的事情(据说以前并没有面向对象先导课程)。感谢课程组在先导课和正课的付出。
未来方向
可以增加一些关于如何写评测机,数据生成器等的指导,让大家都能掌握“大国重器”。















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









