






一、特征工程概念入门
利用专业背景知识和技巧处理数据,让机器学习算法效果最好。这个过程就是特征工程
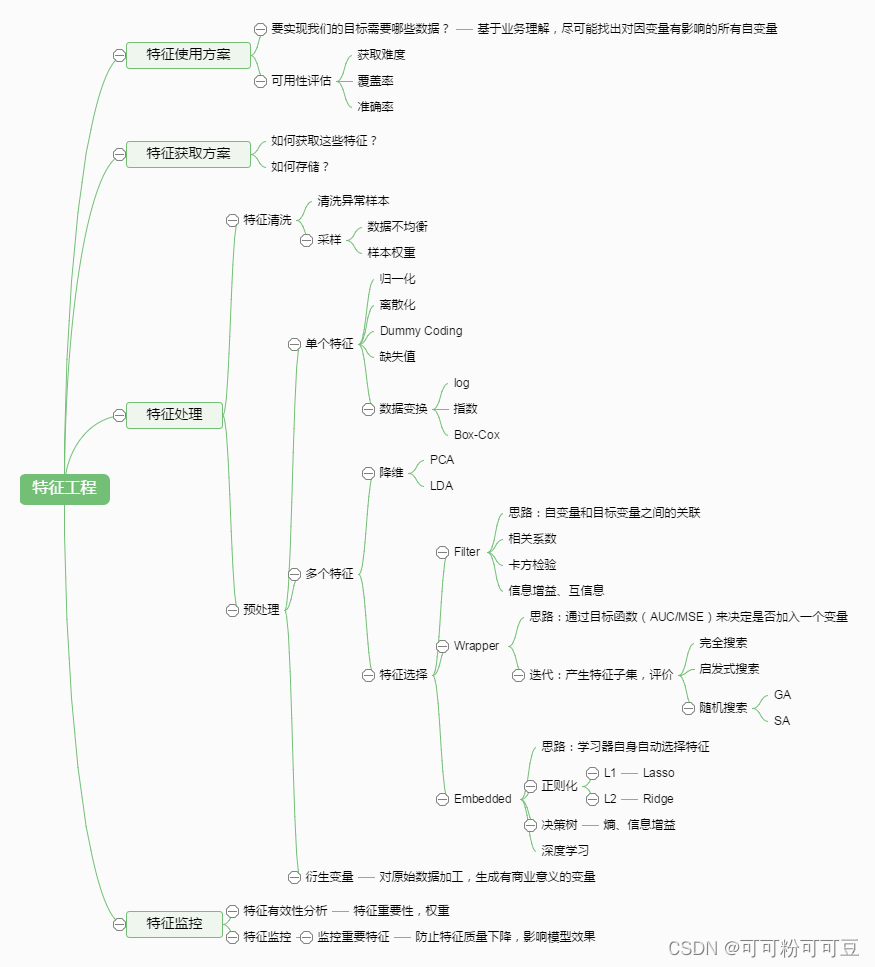
1、特征提取( feature extraction)
寻找出任务的一部分相关特征,把这些特征构成特征向量
例如鸢尾花的花萼的长度于宽度,花瓣的长度与宽度等
2、特征预处理
特征对模型产生影响;因量纲问题,有些特征对模型影响大、有些影响小
有些数据看着并不直观,或者说会影响判断可以用“归一法”对数据进行一个简单的处理,当然常见的还有标准化、特征选择、特征转换和特征编码等。这些方法各有特点,可以根据具体的数据和任务需求选择适合的预处理方法。不过,需要注意的是,预处理后的特征应该能够保持原始数据的有用信息,并尽可能减少噪声和冗余,以提高模型的性能。
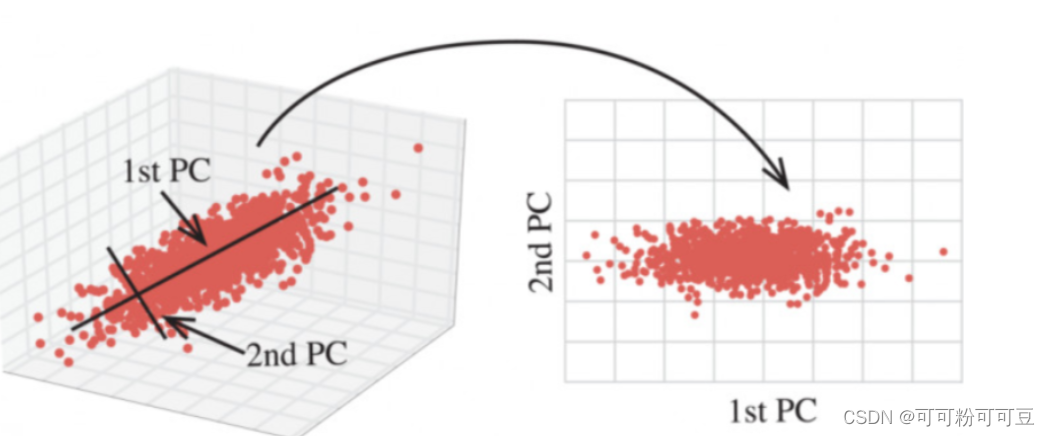
3、特征降维
降低数据的维度,会对原数据产生影响
4、特征选择
同样可以降低数据的维度,提高学习算法的性能,但是不会对原数据产生影响
5、特征组合
把多个特征合并成一个特征,用乘法或者加法来计算
6、总结
特征降维会影响原数据,特征选择不会影响原数据(二者都是降维数据)
二、KNN算法
1、近邻算法
KNN算法思想:如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类。
样本相似性:样本都是属于一个任务数据集的。样本距离越近则越相似。
 (k一般取5)!
(k一般取5)!
分类问题:1.计算未知样本到每一个训练样本的距离
2.将训练样本根据距离大小升序排列
3.取出距离最近的 K 个训练样本
4.进行多数表决,统计 K 个样本中哪个类别 的样本个数最多
5.将未知的样本归属到出现次数最多的类别
回归流程:1.计算未知样本到每一个训练样本的距离
2.将训练样本根据距离大小升序排列
3.取出距离最近的 K 个训练样本
4.把这个 K 个样本的目标值计算其平均值
5.作为将未知的样本预测的值
2、k值选择
k值过小,会受到异常点的影响,发生过拟合
k值过大,受到样本均衡的问题 且K值的增大就意味着整体的模型变得简单,发生欠拟合
3、总结
1、有关KNN的K值选择,以下说法中正确的是?(多选)
A)若k值过小,意味着模型更易受到异常点影响,更易学习到嘈杂数据,模型有过拟合的风险。 B)若k值过大,模型会变的相对简单,结果更容易受到异常值的影响。(受到样本均衡的问题 且K值的增大就意味着整体的模型变得简单,发生欠拟合)
C)若k值与训练集样本数相同,会导致最终模型的结果都是指向训练集中类别数 最多的那一类,忽略了数据当中其它的重要信息,模型会过于简单。
D)实际工作中经常使用交叉验证的方式去选取最优的k值,而且一般情况下, k值都是比较小的数值。
答案 ACD
三、算法运行
1、分类
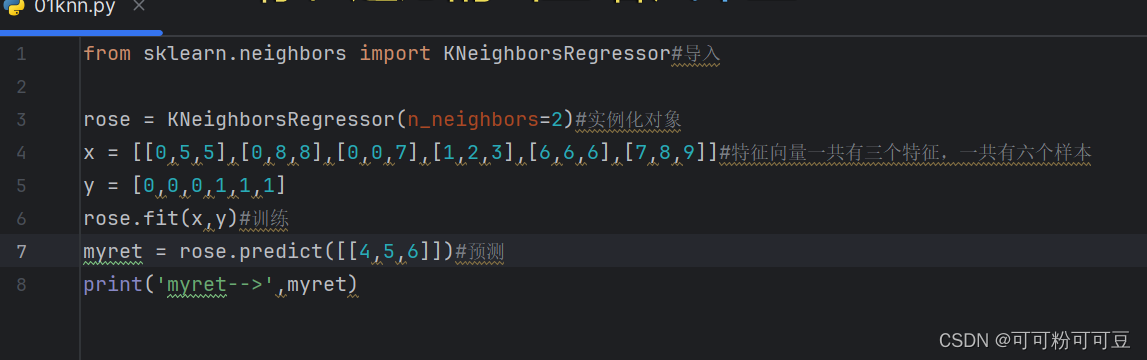
2、回归实现


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









