






在学习爬虫前请务必学会Python基础
一、爬虫爬取数据的四个步骤
一般来说,爬虫爬取数据的基本流程总共需要四个步骤,分别是确定目标、发送请求、解析HTML、数据处理。
确定目标:即确定你要爬取的网站的URL,明确包含所需数据的目标网址或页面,这是整个流程的第一步,决定了你要获取什么数据和你要怎样设计爬虫程序。
发送请求:使用编程语言(一般爬虫程序用的都是Python)中一些发送请求的库发送请求到目标网址,并获取HTML响应。如我们可以使用Python中的requests库对目标网址发起请求,一般发送请求的方法为GET和POST,这个视具体情况而定。
解析HTML:在获得响应数据之后使用HTML解析库(如BeautifulSoup、lxml等)对获取到的HTML内容进行解析,提取所需数据。这一步主要是将HTML文件转化为结构化的数据以便后续的使用和处理。
数据处理:在获取到所需数据后需要将获取的数据进行数据清洗、格式化和筛选,然后进行持久化存储,这一步主要目的是为了取出不需要或无意义的数据并保存到本地,以便后续的使用。
以上为数据爬虫的四个步骤,每个步骤都具有相应的作用和技术细节需要掌握,爬取不同页面时需要制定不同的可以绕过网页反爬机制的爬虫策略,如数据加密,验证码等,具体情况需具体分析。
二、爬虫入门基础案例之requests库
1、requests库的使用
安装requests库:在PyCharm终端中输入如下命令安装requests库
pip install requests如果下载速度过慢可考虑更换镜像源:
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
#更换镜像源语句为 pip install xxx -i 镜像源网址
#https://pypi.tuna.tsinghua.edu.cn/simple为清华镜像源,仅作参考使用安装好requests库后通过import导入requests库
import requests导入所需要的库以后就可以按照上述四个步骤来爬取网页数据了,举个简单的例子,爬取百度首页数据。

Step 1:指定url
url = 'https://www.baidu.com/'通过url = 'https://www.xxx.com/'将所需要爬取的url封装到参数url中,后续直接调用即可。注意:https为超文本传输安全协议,在指定目标网址时务必加上此协议。
Step 2:发起请求
response = requests.get(url=url)
#通过requests库的get方法发送请求,get方法会获得一个返回对象,我们用response来接收Step 3:解析HTML,获取响应数据
page_text = response.text
#text返回的是字符串形式的相应数据
print(page_text)
#打印数据查看是否有问题Step 4:持久化存储
with open('./baidu.html','w',encoding = 'utf-8') as fp:
fp.write(page_text)
print("爬取数据结束")
#with open('filename.xxx','w','编码规则')语句用于Python文件读写完整代码如下:
import requests
url = 'https://www.baidu.com/'
response = requests.get(url=url)
page_text = response.text
print(page_text)
with open('./baidu.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
print('爬取数据结束')是不是很简单,新手小白快去试一试吧!
2、requests库实战之简易网页采集
本次实战旨在爬取简易的页面数据,在这个实战里我们将接触到很常见也是很基础的一个反爬策略:UA伪装。
UA伪装:门户网站的服务器会检测对应请求的载体身份标识。
将对应的user-agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}导入requests库:
import requests分析url,当我们在百度的搜索框中输入猫去搜索我们会发现新跳出的页面的url非常长,那我们适当的去掉一些会不会影响最终的搜索页面呢?

我们发现,当我们将猫字后面的内容都去掉也不会影响最终的搜索结果,那如果我们把猫换成狗又会出现什么效果呢?

当换成狗时页面发生了变化,搜索内容成了狗。通过尝试实验可知,搜索内容是通过数据传参获取的,我们可由此指定url,然后将参数封装到一个字典中,通过传参将数据传输给搜索框中进行搜索。

指定url:
url = 'www.baidu.com'处理url携带的参数并将其封装到字典中:
kw = input('enter a word:')
param = {
'querry':kw
}
#通过input函数可在键盘上打出想要搜索的内容并将其作为参数封装到param字典中由于对于指定的url是带参数的,所以我们在对目标url发起请求的时候需要携带参数。
response = requests.get(url=url,params=param,headers=headers)
page_text = response.text
#对文件命名
filename = kw+'.html'
#持久化存储
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(page_text)
print(filename,'保存成功')完整代码如下:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.1311 SLBChan/30'
}
import requests
url = 'https://baidu.com/'
kw = input('enter a word:')
param = {
'querry':kw
}
response = requests.get(url=url, params=param,headers=headers)
page_text = response.text
filename = kw+'.html'
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(page_text)
print(filename,'保存成功')3.requests实战之破解百度翻译
在本个实战中,我们主要任务是获取百度翻译中的翻译结果页面数据,话不多说,开始实践吧!
导包
import requests
import json第一步还是指定URL:百度翻译-200种语言互译、沟通全世界!
post_url = 'https://fanyi.baidu.com/'接下来我们打开网址在输入框随便输入一个单词来查看url的规律

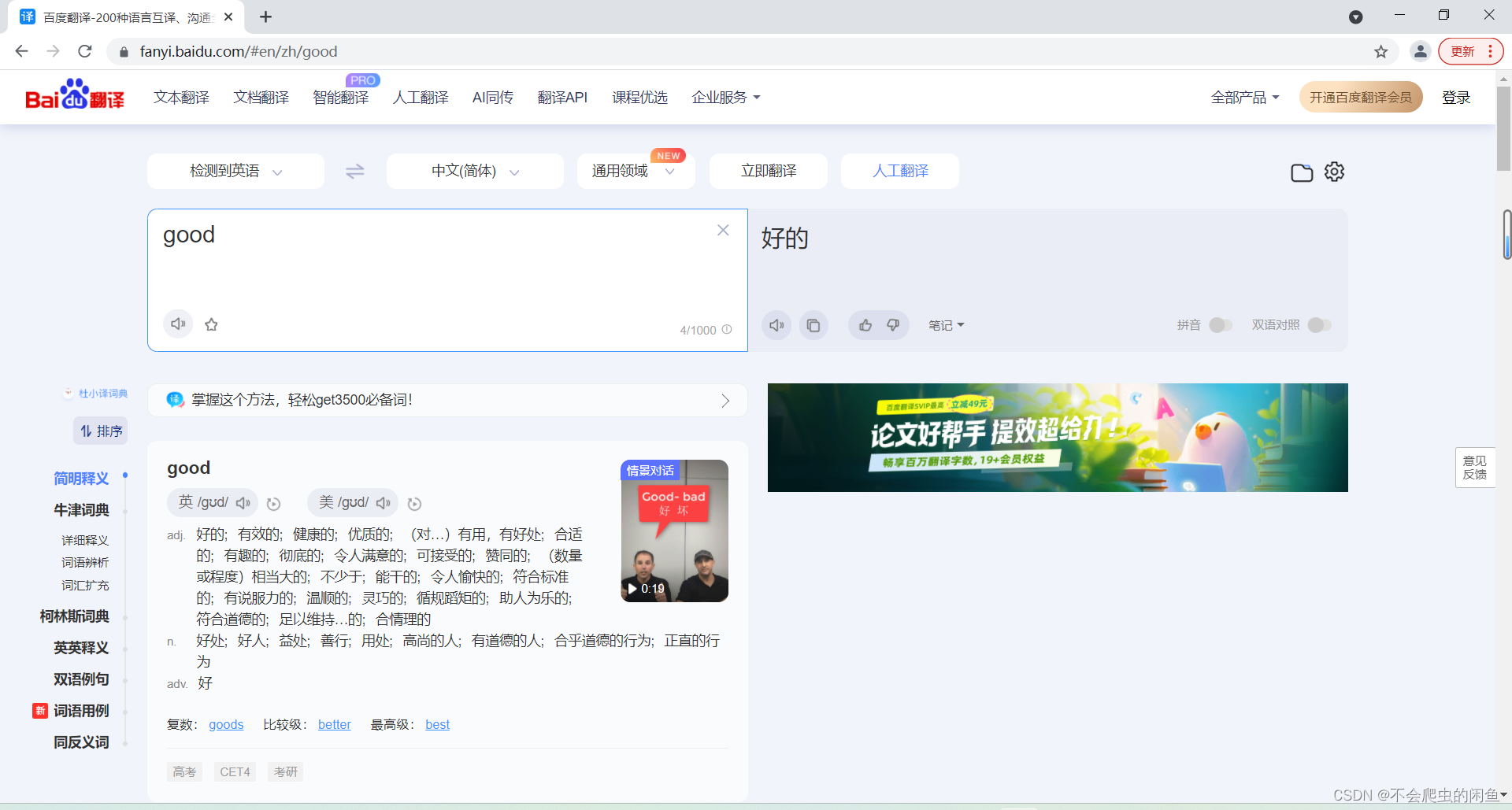
通过对比我们发现我们所需要翻译的数据同样是通过传参输入到搜索框的 ,与上个实战案例类似,所以我们同样需要封装个关键词字典,同样设置成动态的,并将参数赋值给word
word = input('enter a word:')
data = {
'kw':word
}
进行ua伪装和发送请求并获取响应数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
response = requests.post(url=post_url,data=data,headers=headers)
#获取响应数据:json()方法返回的是一个obj,(如果确认响应数据是json类型的才能用json())
dic_obj = response.json()进行持久化存储
fileName = word+'.json'
fp = open(fileName,'w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
print('爬取完毕')
三、数据解析
常用的数据解析库
常用的数据解析有三种:正则解析、xpath解析,BeautifulSoup解析,接下来我们依次了解学习。
(1) 正则解析
在学习正则解析之前我们要先了解什么事正则语句,正则语句有什么用,怎么用。
正则语句:正则表达式(RE是一种用于描述和匹配一系列符合某个语法规则的字符串的模式。它使用一系列字符来定义这个模式,这些字符可以是普通字符(例如字母、数字)或特殊字符(称为元字符)。正则表达式可以用于文本搜索、文本替换、数据验证等多种场景。
同其他解析库一样,在使用re时要先下载库并且导包
pip install re
import re具体表达式写法可在csdn或其他博客网站搜索,这里我就不一一赘述了。
(2)xpath解析
xpath解析是我们在进行元素定位时经常用到的一种解析方式,要想用xpath解析,首先需要下载相应库:lxml,并从lxml导入etree包
import requests
from lxml import etree指定url,进行ua伪装后,获取响应数据。准备工作完成后,我们开始解析HTML数据。
假设我们获取到的HTML数据名为page_text,那我们需要先实例化一个etree队形tree,具体操作如下:
tree = etree.HTML(page_text)
然后我们进入我们指定url网址,通过开发者工具定位到我们需要的数据元素的位置,,然后选中,鼠标右键点击复制->复制xpath或者完整的xpath

通过tree.xpath('复制过来的xpath路径')找到我们所需要的数据元素,紧接着就是数据爬取和数据持久化存储了,与之前的操作大同小异。
(3)BeautifulSoup解析
在使用本解析方法之前依然要下载相应的库和导包
pip install bs4
from bs4 import BeautifulSoup然后用标准爬虫的方法获取到指定URL的页面源码数据
准备工作完成之后实例化一个bs4对象需要将页面源码数据加载到对象中
soup = BeautifulSoup(page_data)
#实例化一个soup对象然后解析HTML源文件,最后找到自己需要的数据并进行持久化存储即可。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











