







简介
RAG技术就像给AI装上了「
实时百科大脑」💪,通过先查资料后回答的机制,让AI摆脱传统模型的”知识遗忘”困境。
核心流程
- 文档切割 → 建立智能档案库
- 向量编码 → 构建语义地图
- 相似检索 → 智能资料猎人
- 生成增强 → 专业报告撰写
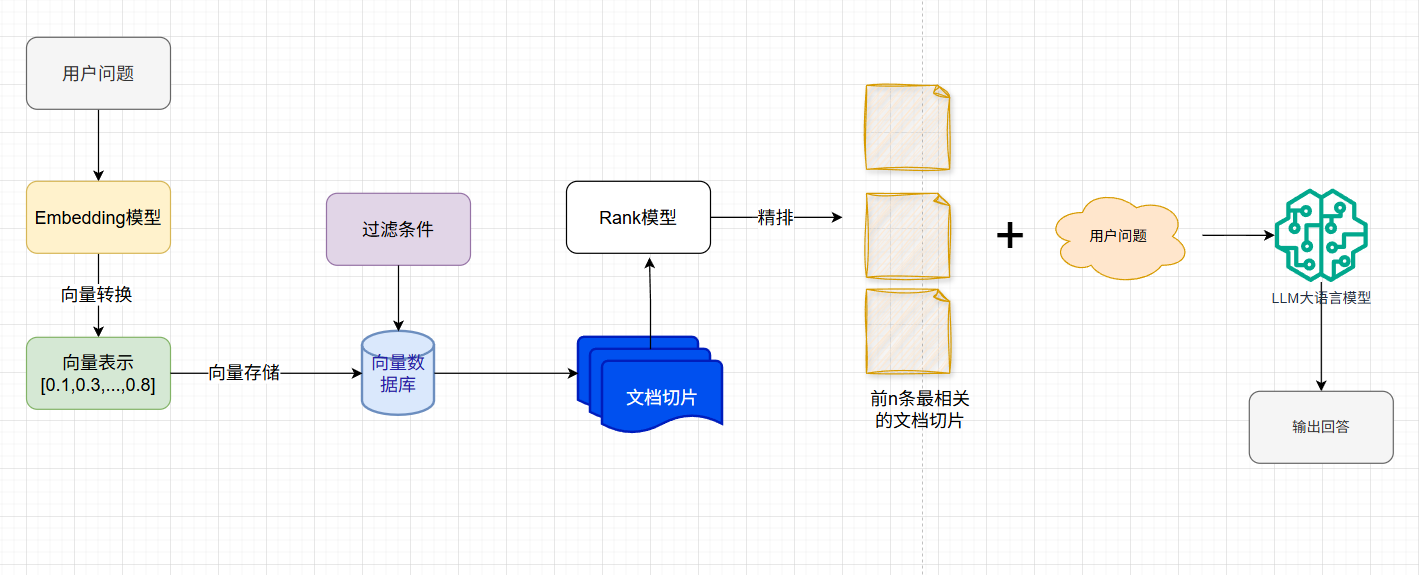
Embedding 模型
Embedding嵌入是将高维离散数据(如:文字、图片、音视频等)转换为低维向量的过程。这些向量可以在数学空间中表示原始数据的语义特征,使计算机能够理解数据间的相似性。
而Embedding 模型就是执行这种转换算法的机器学习模型。
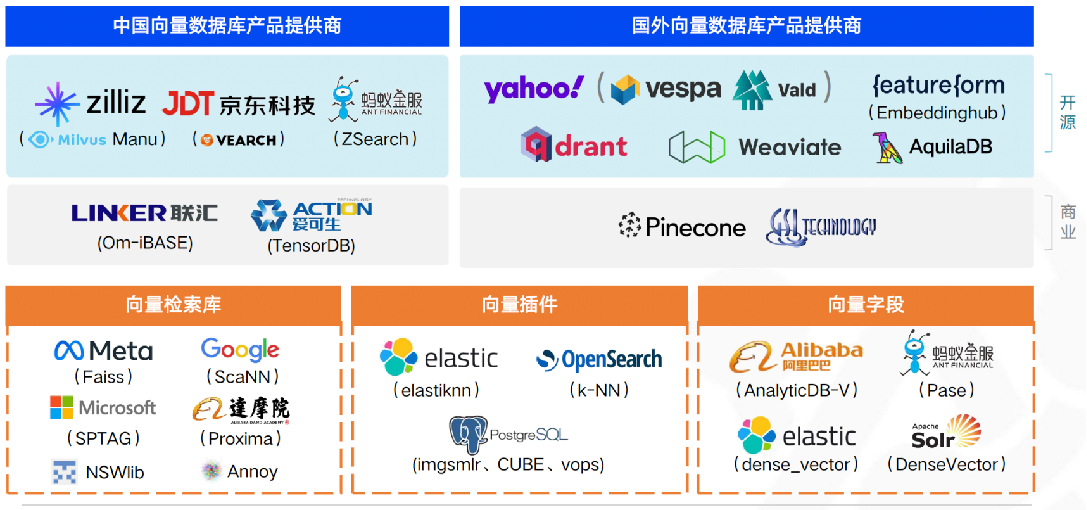
向量数据库
存储向量的数据库🐳
常见的向量数据库:
使用
配置
依赖配置
👉处理其它类型需要引入的依赖,请参考官方文档:
https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>1.0.0</version>
</dependency>
文档分片
从资源目录中加载
有两种分片方式:按页分片和按段落分片,但是实测由图片转换成的pdf按段落分片会出错😅,而由doc转成的
Caused by: java.lang.IndexOutOfBoundsException: Index out of bounds: -1
resources文件结构如下:
resources
documents
interviewHandBook
JavaGuide面试突击.pdf
templates
InterviewHandbook.txt
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.ParagraphPdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
/**
* 自定义pdf文档Reader
*/
@Component
public class CustomPdfDocumentReader {
private final Resource[] resources;
public CustomPdfDocumentReader(
@Value("classpath:documents/interviewHandbook/*.pdf")Resource[] resources) {
if (resources == null)
throw new IllegalArgumentException("resources cannot be null");
this.resources = resources;
}
/**
* 按照页获取pdf文档
* @return
*/
public List<Document> getDocsFromPdfWithPage(){
List<Document> documentList = new ArrayList<>();
for (Resource resource : resources) {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(resource,
PdfDocumentReaderConfig.builder()
//页边距
.withPageTopMargin(0)
//页脚
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
//删除顶部的行数
.withNumberOfTopTextLinesToDelete(0)
.build())
//每页一个文档
.withPagesPerDocument(1)
.build());
documentList.addAll(pdfReader.get());
}
return documentList;
}
/**
* 按照段落获取pdf文档
* //todo 图片转成的pdf,解析会出现异常
* @return
*/
public List<Document> getDocsFromPdfWithCatalog() {
List<Document> documentList = new ArrayList<>();
for (Resource resource : resources) {
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(resource,
PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.build());
documentList.addAll(pdfReader.get());
}
return documentList;
}
}
存入向量内存
该案例实现的向量是基于内存的,仅供学习参考。✨
import jakarta.annotation.Resource;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RagConfig {
@Resource
private CustomPdfDocumentReader customPdfDocumentReader;
@Bean
public VectorStore InMemoryVectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(embeddingModel)
.build();
simpleVectorStore.add(customPdfDocumentReader.getDocsFromPdfWithPage());
return simpleVectorStore;
}
}
使用
只需在配置是添加一个
QuestionAnswerAdvisor即可。
ChatClient:
import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatOptions;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.QuestionAnswerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ChatClientConfig {
@Value("${spring.ai.dashscope.api-key}")
public String apiKey;
@Value("classpath:templates/InterviewHandbook.txt")
public String INTERVIEW_HANDBOOK_PROMPT;
@Resource
ChatMemory InMySqlChatMemory;
@Resource
VectorStore InMemoryVectorStore;
private void checkParams() {
if (apiKey == null)
throw new RuntimeException("apiKey is null");
if (INTERVIEW_HANDBOOK_PROMPT == null)
throw new RuntimeException("INTERVIEW_HANDBOOK_PROMPT is null");
}
@Bean
public ChatClient qwenPlusInMySqlVectorStoreChatClient(){
checkParams();
return ChatClient.builder(new DashScopeChatModel(new DashScopeApi(apiKey),
DashScopeChatOptions.builder().withModel("qwen-plus").build()
))
.defaultSystem(INTERVIEW_HANDBOOK_PROMPT)
.defaultAdvisors(
//基于MySQL持久化的记忆advisor
new MessageChatMemoryAdvisor(InMySqlChatMemory),
//自定义日志advisor
new CustomLoggerAdvisor(),
//基于向量的记忆advisor
new QuestionAnswerAdvisor(InMemoryVectorStore)
).build();
}
}
InterviewHandbookApp:
import jakarta.annotation.Nonnull;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Flux;
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY;
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY;
/**
* 面试宝典ai智能体
*/
@Component
@Slf4j
public class InterviewHandbookApp {
@Resource
private ChatClient qwenPlusInMySqlChatClient;
@Resource
private ChatClient qwenPlusInMySqlVectorStoreChatClient;
public Flux<String> streamChat(@Nonnull String message, @Nonnull String chatId){
ChatClient chatClient;
//当用户使用了向量数据库,则优先使用向量数据库
if (qwenPlusInMySqlVectorStoreChatClient != null) {
chatClient = qwenPlusInMySqlVectorStoreChatClient;
} else {
chatClient = qwenPlusInMySqlChatClient;
}
return chatClient.prompt()
.user(message)
.advisors(spec -> spec
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId) //定义每次会话的ID
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10)) //定义每次会话的记忆长度,这里设置为10条
.stream()
.content();
}
}
InterviewHandbookController:
import jakarta.annotation.Nonnull;
import jakarta.annotation.Resource;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/interview")
public class InterviewHandbookController {
@Resource
private InterviewHandbookApp interviewHandbookApp;
@GetMapping("/simple/chat")
public String simpleChat(String message,@Nonnull String chatId) {
return interviewHandbookApp.simpleChat(message, chatId);
}
@GetMapping("/stream/chat")
public Flux<String> streamChat(String message, @Nonnull String chatId,
HttpServletResponse response) {
response.setCharacterEncoding("UTF-8");
return interviewHandbookApp.streamChat(message,chatId);
}
}
测试
项目启动后日志输出如下,说明进行了文档向量化。

对比输出和原文内容:


相似度还是比较高的,这说明我们成功将pdf文件作为了知识库。👍



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











