






代码
简单的爬虫(60)
导入库urllib 导入模块request 函数urlopen()
Url=“www.douban.com”
Import urllib.request
response=Urllib.request.urlopen(www.douban.com”)
Response.read().decode()
强化版爬虫(70)
导入库urllib 导入模块request 函数urlopen()
函数Request()
导入模块parse 函数urlencode({kw:name}) kw=name
函数quote(name) name
‘www.douban.com/f?%%%%%%’
Url=“www.douban.com”+%%%%%%
头部信息的拼接,user-agent
用户输入
Import urllib.parse
Import urllib.request
Name=Input(“请你输入要爬取的关键字”)
kw=Urllib.parse.quote(name)
url=“www.douban.com/f?”+kw
Header={user-agent:...}
New_url=Urllib.request.Request(url=url,headers=header)
response=Urllib.request.urlopen(new_url)
Response.read().decode()
复杂版爬虫——(80)
#请你定义类tieba 定义方法 发送请求 解析 保存
Clsaa tieba:
Def get_data(){
Pass}
Def parse_data(){
Pass}
Def save_data(){
Pass}
百度贴吧
import urllib.parse
import urllib.request
print('大数据2203王姁')
class BaiduTiebaspiader:
def __init__(self):#放一些初始化的函数
self.header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
self.url='https://new.qq.com/search?query={}&page={}'
def get_html(self,url):#发送请求获取响应
req=urllib.request.Request(url=url,headers=self.header)
res=urllib.request.urlopen(req)
html=res.read().decode()
return html
def parse_html(self):#解析页面提取想要的标题
pass
def save_html(self,filename,html):#保存用的
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
def run(self):#控制
name=input('请你输入要抓取的名称:')
params=urllib.parse.quote(name)
start=int(input('请你输入起始页:'))
end=int(input('请你输入终止页:'))
for page in range(start,end+1):
pn=(page-1)*50
url=self.url.format(params,pn)
html=self.get_html(url)
filename='{}_第{}页.html'.format(name,page)
self.save_html(filename,html)
if __name__=='__main__':#是否是系统变量,是模块的标识符
spider=BaiduTiebaspiader()
spider.run()
八个知识点
1、 请你利用所学知识完成任意网站的爬虫操作
import urllib.request
from urllib import request
url='https://tieba.baidu.com'
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.54'}
new_url=urllib.request.Request(url=url,headers=header)
response=urllib.request.urlopen(new_url)
html=response.read().decode()
print(html)
2、请你利用所学知识完成任意网站的爬虫操作,要求涉及用户输入及编码转换;要求涉及User-agent头部信息的拼接,头部信息可用{User-agent: mozilia"}代替
import urllib.parse
import urllib.request
url1='https://tieba.baidu.com/'
name=input("请输入要爬取的主题:")
url2=urllib.parse.quote(name)
url=url1+url2
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
new_url=urllib.request.Request(url=url,headers=header)
response=urllib.request.urlopen(new_url)
html=response.read().decode()
print(html)
3、请你利用xpath完成大案例的解析要求:定义类及函数首先完成当前页的爬取;其次对当前页进行解析解析提取当前页的标题和标题对应的url地址然后解析提取下一页的url地址 ,并对标题和标题对应的url地址进行保存操作根据下- -页的url地址继续爬取,继续进行以上步骤
from urllib import request,parse
from lxml import etree
class Tieba(object):
def __init__(self,name):
self.url = 'https://tieba.baidu.com/f?kw=%E7%94%B5%E5%BD%B1%E7%A5%A8%E6%88%BF'
self.headers = {'user-agent': 'Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)'}
def get_data(self,url):
req=request.Request(url=url,headers=self.headers)
res=request.urlopen(req)
response=res.read().decode()
return response
def parse_data(self,data):
html=etree.HTML(data)
el_list=html.xpath('//*[@id="thread_list"]/li/div/div[2]/div[1]/div[1]/a')
print(len(el_list))
data_list=[]
for el in el_list:
temp={}
temp['title'] = el.xpath('./text()')[0]
temp['link'] = 'https://tieba.baidu.com/' + el.xpath('./@href')[0]
data_list.append(temp)
try:
next_url='https:'+html.xpath('//a[contains(thext(),"下一页“)]/@href')[0]
except:
next_url=None
return data_list,next_url
def save_data(self,data_list):
for data in data_list:
print(data)
def run(self):
next_url=self.url
while True:
data =self.get_data(next_url)
data_list,next_url=self.parse_data(data)
data_list,next_url=self.parse_data(data)
self.save_data(data_list)
print(next_url)
if next_url==None:
break
if __name__=='__main__':
tieba=Tieba('')
tieba.run()
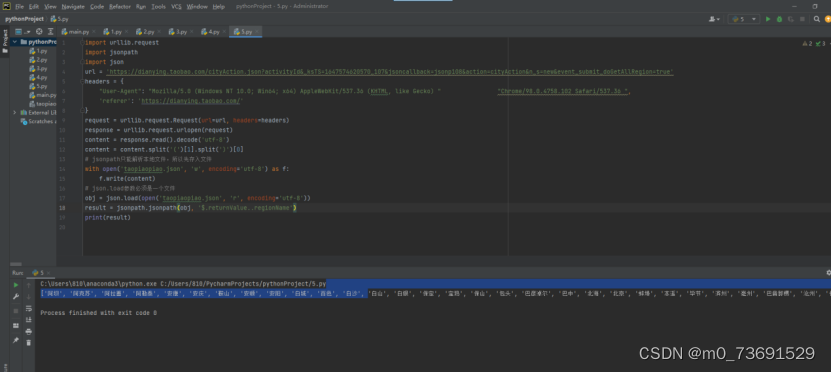
4使用jsonpath对任意网站内容解析并提取内容
JSONPath 是一种查询语言,用于从 JSON 格式的数据中提取信息。
以下是一个简单的 Python 示例,使用 requests 和 jsonpath 库来抓取网页内容并使用 JSONPath 提取数据:
首先,安装所需的库:
pip install requests jsonpath
使用以下代码抓取网页内容并提取数据:
import requests
from jsonpath import jsonpath
# 抓取网页内容
url = ---; # 替换为你要抓取的网页URL
response = requests.get(url)
html_content = response.text
# 将HTML内容转换为JSON格式
json_content = requests.get(f'https://html2json.com/?html={html_content}').json()
# 使用JSONPath提取数据# 例如,提取所有的链接
links = jsonpath(json_content, '$..a[@href]')
for link in links:
print(link['href'])
注意:上述代码中的 https://html2json.com/ 是一个在线服务,它将 HTML 转换为 JSON。你可以使用这个服务或其他类似服务将 HTML 转换为 JSON。
此外,JSONPath 的语法可能会根据你使用的库或工具略有不同。上述示例中使用的是 jsonpath 库的语法。如果你使用其他库或工具,请确保查阅相关文档以了解正确的语法。
5正则
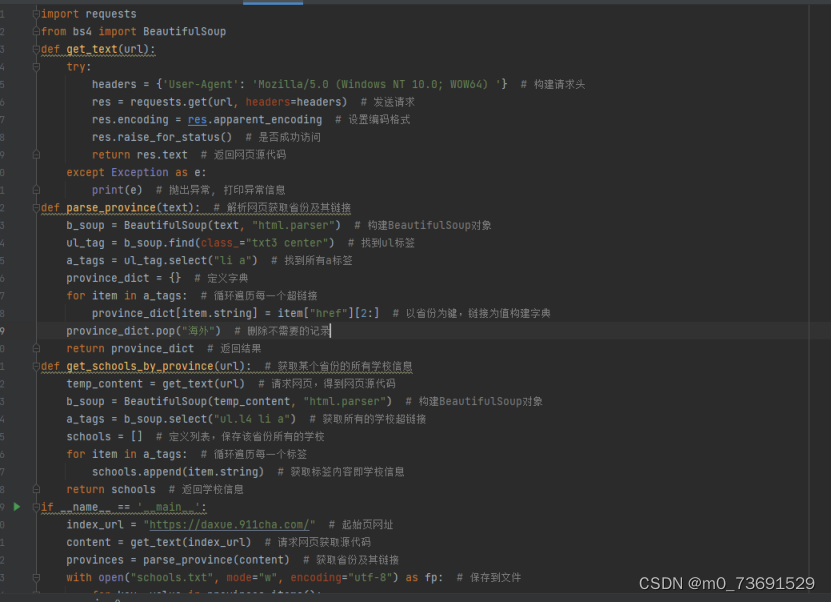
import requests
from bs4 import BeautifulSoup
def get_text(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '} # 构建请求头
res = requests.get(url, headers=headers) # 发送请求
res.encoding = res.apparent_encoding # 设置编码格式
res.raise_for_status() # 是否成功访问
return res.text # 返回网页源代码
except Exception as e:
print(e) # 抛出异常, 打印异常信息
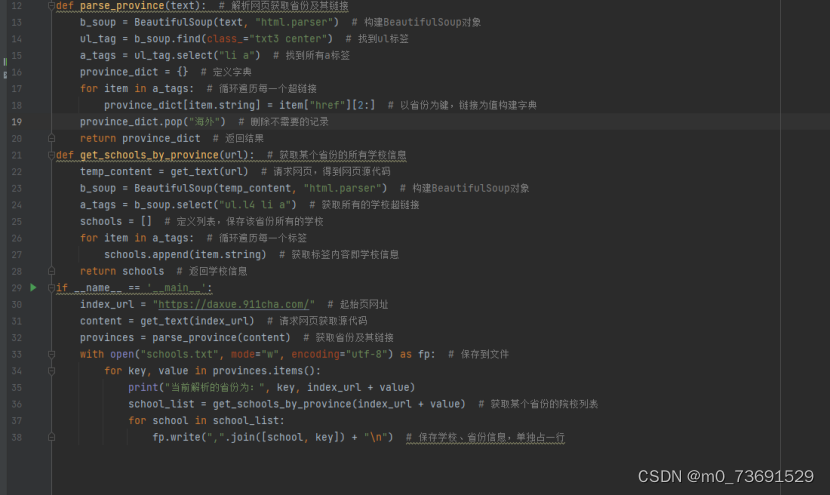
def parse_province(text): # 解析网页获取省份及其链接
b_soup = BeautifulSoup(text, "html.parser") # 构建BeautifulSoup对象
ul_tag = b_soup.find(class_="txt3 center") # 找到ul标签
a_tags = ul_tag.select("li a") # 找到所有a标签
province_dict = {} # 定义字典
for item in a_tags: # 循环遍历每一个超链接
province_dict[item.string] = item["href"][2:] # 以省份为键,链接为值构建字典
province_dict.pop("海外") # 删除不需要的记录
return province_dict # 返回结果
def get_schools_by_province(url): # 获取某个省份的所有学校信息
temp_content = get_text(url) # 请求网页,得到网页源代码
b_soup = BeautifulSoup(temp_content, "html.parser") # 构建BeautifulSoup对象
a_tags = b_soup.select("ul.l4 li a") # 获取所有的学校超链接
schools = [] # 定义列表,保存该省份所有的学校
for item in a_tags: # 循环遍历每一个标签
schools.append(item.string) # 获取标签内容即学校信息
return schools # 返回学校信息
if __name__ == '__main__':
index_url = "https://daxue.911cha.com/" # 起始页网址
content = get_text(index_url) # 请求网页获取源代码
provinces = parse_province(content) # 获取省份及其链接
with open("schools.txt", mode="w", encoding="utf-8") as fp: # 保存到文件
for key, value in provinces.items():
print("当前解析的省份为:", key, index_url + value)
school_list = get_schools_by_province(index_url + value) # 获取某个省份的院校列表
for school in school_list:
fp.write(",".join([school, key]) + "\n") # 保存学校、省份信息,单独占一行
jsonpath’
命令行 输入pip install jsonpath
6、利用beautifulsoup完成数据解析( 只作了解。函数的功能和用法)
7、scrapy框架的理论知识三点
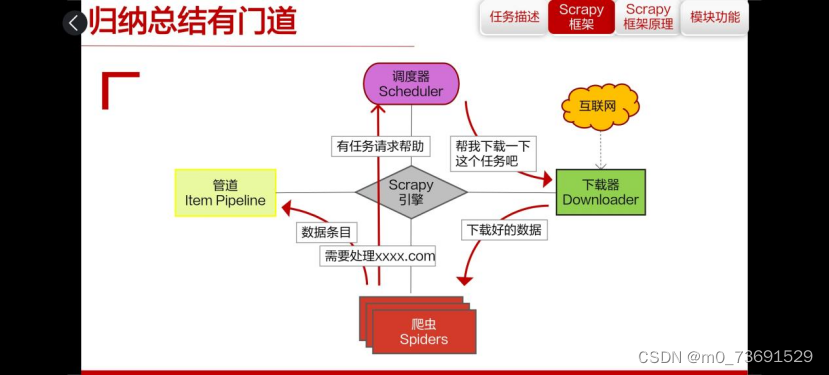
架构和组件:Scrapy使用一个事件驱动的架构,由几个核心组件组成,包括Scrapy引擎、调度器、下载器、爬虫、项目管道等。这些组件协同工作,共同完成网络爬虫的任务。
请求和响应:在Scrapy中,请求和响应是核心对象,用于在爬虫和目标网站之间进行交互。请求代表向特定URL发送的HTTP请求,而响应则代表服务器对请求的响应。Scrapy提供了强大的工具来处理和操纵这些请求和响应。
选择器和提取器:选择器用于从HTML或XML响应中提取数据,而提取器则是用于从选择器中选择数据。Scrapy支持多种选择器,如CSS选择器和XPath选择器,用户可以根据需要选择最适合其任务的选择器。
8、利用scrapy框架对任意网站实现爬取及解析操作
安装Scrapy:首先,确保你的Python环境已经安装了Scrapy框架。你可以使用pip来安装Scrapy,运行以下命令:
pip install scrapy
创建Scrapy项目:使用Scrapy命令行工具创建一个新的Scrapy项目。运行以下命令:
scrapy startproject myproject
这将创建一个名为myproject的新目录,其中包含一个默认的项目结构。
创建爬虫:进入项目目录,并使用以下命令创建一个新的爬虫:
cd myproject
scrapy genspider myspider example.com
这将创建一个名为myspider的爬虫文件,用于爬取example.com网站的数据。
编写解析规则:在爬虫文件中,你需要编写解析规则来提取网站数据。Scrapy使用XPath或CSS选择器来提取数据。你可以在parse()方法中编写解析规则。以下是一个简单的示例:
import scrapy
class Myspider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
# 使用XPath选择器提取数据
title = response.xpath('//title/text()').get()
description = response.xpath('//meta[@name="description"]/@content').get()
# 处理提取到的数据...
在上面的示例中,我们使用XPath选择器提取了标题和描述。你可以根据目标网站的结构和数据布局调整选择器。
运行爬虫:一旦你编写了解析规则,你可以运行爬虫来爬取网站数据。在项目目录中,使用以下命令运行爬虫:
scrapy crawl myspider
这将启动爬虫并开始爬取指定网站的数据。
处理提取到的数据:在上述示例中,我们只是简单地提取了标题和描述,但你可以根据需要进一步处理和操作提取到的数据。你可以使用Python的内置函数、Scrapy提供的工具或第三方库来处理和存储数据。
理论
Scrapy

爬虫概念:
按照一定规则,自动请求万维网,并获取网页内容
爬虫规范:robots君子协议
爬虫限制:非法不允许(密码 明令禁止的)
服务器会做什么:反爬(检查你的信息(修改头部信息);
速度(降低速度);半永久封号(代理ip);验证码)
爬虫的分类:通用爬虫和聚焦爬虫
爬虫是一种程序,可以根据一定的规则自动抓取互联网上的信息。爬虫可以分为通用爬虫、聚焦爬虫、增量式爬虫等。
区别和联系:
通用爬虫:是搜索引擎的重要组成部分,需要遵守robots协议,网站通过此协议告诉搜索引擎哪些页面可以抓取,哪些页面不可以抓取。通用爬虫需要处理大量的网页,所以它的抓取速度很快,但可能会抓取到很多与需求无关的网页。
聚焦爬虫:是面向特定需求的一种网络爬虫程序,它与通用爬虫的区别在于,聚焦爬虫在实施网页抓取的时候会对网页内容进行筛选和处理,尽量保证只抓取与需求相关的网页信息。由于保存的页面数量少所以更新速度很快。
爬虫的原理:模拟的正常网站的使用
Python爬虫抓取网页的流程
确定目标网页:首先需要确定你要抓取的网页,你可以手动输入网页的URL,也可以使用一些工具来自动获取网页的URL。
发送请求:使用Python的HTTP库(如requests)向目标网页发送请求,获取网页的HTML代码。
解析网页:使用HTML解析器(如BeautifulSoup或lxml)解析HTML代码
存储数据:将提取出的数据存储到本地文件或数据库中,以便后续使用。
域名 ip地址
统一资源定位符url:http://127.0.0.1:8080/subject/python/project.shtml
协议头 服务器地址和端口 文件路径
http和https的区别:SSL
http默认端口80 --- https默认端口443
ip地址(http://180.97.33.107)—为每一台计算机提供一个编号,非常不容易记忆和理解
所以发明了域名(http://www.baidu.com)代替ip地址
域名和ip地址之间的对应关系表—DNS服务器,完成ip地址和域名之间的映射
DNS解析是将域名转换为IP地址的过程。DNS解析的作用是将用户输入的域名转换为相应的IP地址,以便能够找到并访问相应的网站。DNS解析是由DNS服务器完成的,DNS服务器是一个分布式数据库系统,存储了域名和IP地址之间的映射关系。当用户输入一个域名时,DNS服务器会将其转换为相应的IP地址,然后返回给用户。
Robots:是道德层面的约束。
为什么选择python做爬虫?
语言简单易学:Python的语法清晰、简洁,易于理解,使得它很容易上手,特别是对于那些没有编程经验的人。
强大的社区支持:Python有一个庞大且活跃的开发者社区,这意味着遇到问题时可以找到大量的资源和解决方案。同时,Python的开源项目和框架非常丰富,为爬虫开发提供了强大的支持。
丰富的库和工具:Python拥有大量用于各种任务的库和工具,包括网络请求、HTML解析、数据存储等,这使得Python成为编写爬虫的理想语言。例如,Scrapy和BeautifulSoup是Python中常用的爬虫库,它们提供了许多功能和工具来处理网页数据。
跨平台性:Python可以在多种操作系统中运行,包括Windows、Linux和Mac OS。这意味着无论使用哪种操作系统,Python爬虫都可以轻松运行。
可扩展性:如果需要处理更复杂的任务,如机器学习和数据分析,Python可以轻松地与其他语言(如C++或Java)集成,从而提高了爬虫的扩展性和性能。
灵活的自动化:Python还具有很强的自动化功能,可以通过与其他工具和框架的集成来实现自动化处理和监控。
Python是爬虫开发领域的常用语言,它的易用性、社区支持、库和工具、跨平台性、可扩展性和自动化功能使得Python成为开发爬虫的首选语言。
反爬措施----应对策略:
动态加载内容:有些网站使用JavaScript来动态加载内容,这种内容无法通过常规的requests库获取。-----这种情况下,需要使用像Selenium这样的工具来模拟浏览器操作并获取动态内容。
检测并限制请求频率:网站可能会检测并限制来自同一IP地址的请求频率,以防止恶意爬取。----为了应对这种限制,可以使用代理IP或使用Scrapy的代理功能来改变IP地址。同时,可以在请求之间设置适当的延迟来模拟正常用户行为。
验证码验证:一些网站可能会要求用户通过验证码验证才能继续访问。-----这种情况下,可以使用第三方验证码识别服务或手动输入验证码来解决。
检测User-Agent:有些网站会检查请求的User-Agent头,以确定是否为浏览器请求。如果User-Agent被识别为爬虫,可能会被拒绝访问。-----可以通过伪装User-Agent头来模拟浏览器请求。
动态生成网页内容:网站可以使用各种JavaScript框架来动态生成网页内容,这些内容无法通过常规的requests库获取。-------同样,需要使用Selenium等工具来模拟浏览器操作并获取动态内容。
使用验证码:网站可能在整个页面或者在特定的请求中加入验证码,以防止爬虫的访问。
-----可以使用第三方验证码识别服务或手动输入验证码来解决。
使用IP黑名单:一些网站会将频繁访问的IP地址加入黑名单,禁止其访问。
------------使用代理IP或更换IP地址来避免被屏蔽。
检查请求头:有些网站会检查请求头中的信息,如referer、user-agent等,不符合规定的请求可能会被拒绝。确保请求头信息正确。
数据解析技术
数据分为两类:结构化的 非结构化的
结构化的:xml json(现有模型 再有数据)
非结构化的:办公文档 文本 图像 部分html(现有数据 再有模型)
根据网页类型不同,将数据解析技术分为以下几种:
针对文本的解析:正则表达式 ‘asdfghjkl’
针对html或者xml数据解析:xpath、beautifulsoup、正则
针对json的解析:jsonpath
improt re
title='你好,hello,世界'
pattern=re.compile(r"[\u4e00-\u9fa5]+")#查找中文
result=pattern.findall(title)
print(result)
Xml html(“<html><a><b>”)——Xpath
lxml urllib
Etree
Beautifulsoup
安装pip3 install beautifulsoup4
导入类 from bs4 import Beautifulsoup
初始化Beautifulsoup(被解析,语法规则)
Json
Json .loads() .dump()
Jsonpath jsonpath(被寻址的内容,“$..”
2、Get和Post方法
Get和Post方法在客户端程序写法的区别(重要)
明确GET POST方法的区别:url地址的拼接,安全性;
Get和Post方法在服务器端获取数据的方式完全一致(路由选择),Get和Post方法在路由选择中,默认选择的为get 指定post方式如何指定 两种均可如何指定;
利用Get和Post方法实现多个参数的设置利用&进行拼接。
3、正则表达式
import urllib.request
url='https://www.baidu,com/'
response=urllib.request.urlopen(url)#封装
print(response)
req=response.read()#bytes数据类型
print(req)
result=req.decode()#字符串类型
print(type(result))
爬虫(从左往右的过程)
解析(从右往左的过程)
from lxml import etree
root1=etree.XML("<root><a x='123'>xtext</a></root>")#把字符串转换为xml
root2=etree.HTML("<root><a x='123'>xtext</a></root>")#把字符串转换为html
root3=etree.fromstring("<root><a x='123'>xtext</a></root>")#把字符串转换为xml
print(root1)
print(root2)
print(root3)
print(etree.tostring(root1))#完善结构
print(etree.tostring(root2))
print(etree.tostring(root3))
1、数据解析
针对字符串——正则表达式
针对html xml ——xpath beautifulsoup
针对json——jsonpath
2、正则表达式
import re
r引导“遵循语法”
\d : 匹配数字0-9
b\d+: +多个(最少一次),b开头,匹配多个数字0-9
ab* :*多个(最少0次)
ab? : ?重复?前边的字符(0次或者1次)
a.b :字符a和字符b之间 可以放置任意的字符
ab|ba:满足ab字符可以,满足ba字符也可以
\n占据一个字符位置
空白符占据一个字符位置
\b表示匹配结尾空白位置
[0-9]表示0-9之间的字符任意一个均可
上尖括号出现在[]中的第一个位置,表示对整个[]中的内容取反(不取)
\s表示匹配空格(区别\b,可以表示非结尾 中间位置)
\w:大小写字母 数字均能匹配
上尖括号单独出现,不与[]联合出现,以上尖括号后边的字符作为开头
$表示以$前边的字符作为结尾
3、xpath
(1)xpath语法结构
/ //
. 选取当前节点
.. 选取当前节点的父节点
@属性
[1]第一个
[last()]最后一个
last()-1倒数第二个
position()<3位置的前两个
/a[@lang="title"]
/a[@lang="title"]/b
(2)lxml解析库
目的:
response=urllib.request.urlopen(url)
res=response.read().decode()
print(type(res))
字符串——正则表达式
去字符串
牵涉到的三个类:
网页的解析
爬下来
解析1——当前页的标题和标题对应的url地址 .xpath(xpath语法结构)
For循环 {} data_list=[] [].append()
解析2——下一页的url地址 .xpath(xpath语法结构) //a[contains(text(),”下一页”)]/@href
(3)Element类——去节点字符串
lxml etree
urllib request
from lxml import etree
root=etree.Element('root')
print(root)
print(a.tag)#.tag表示获取节点的名称
添加属性1——创建节点 并为该节点添加属性
root=etree.Element('root',intersting='totally')
print(root)
print(type(etree.tostring(root)))
添加属性2——在原有节点基础之上 添加节点属性
root.set('age','30')
print(root)
print(etree.tostring(root))
(4)小函数-text()
root=etree.Element('root')
root.text='hello world'
print(root.text)
print(etree.tostring(root))
(5)
ElementTree类——去字符串(网页树结构)
三个函数:
fromstring()-从字符串中解析XML文档,返回根节点
XML()-从字符串中解析XML文档,返回根节点
HTML()-从字符串中解析HTML文档,返回根节点-自动加html body节点
(6)
ElementPath类——树结构的寻址
find()方法
root=etree.XML('<root><a x='123'>xtext</a></root>')
print(root.find('a').tag)
print(root.findall(".//a[@x]")[0].tag)
.urlopen()——response对象
.read()——读操作,bytes数据类型(节点)
.decode()——转码,格式保留 中文正常显示(字符串)
ElementTree类——去字符串(网页树结构)
ElementPath类——树结构的寻址
案例:
from lxml import etree
text = '''
<div>
<ul>
<li class="item-1">
<a href="link1.html">first item</a>
</li>
<li class="item-1">
<a href="link2.html">second item</a>
</li>
<li class="item-inactive">
<a href="link3.html">third item</a>
</li>
<li class="item-1">
<a href="link4.html">fourth item</a>
</li>
<li class="item-0">
<a href="link5.html">fifth item</a>
</li>
</ul>
</div> '''
result = etree.HTML(text)
result.xpath('具体的xpath语法规则')
html=etree.HTML(text)
print(html.xpath('//li[2]/a/text()'))
print(html.xpath('//li[1]/a/@href'))
#beautifulsoup和xpath很多一样,设计的目的解析xml html
#字符串——正则 html xml——xpath beautifulsoup json——jsopath
#直接拿过来就可以用
实例
# from bs4 import BeautifulSoup
# markup='<a href="http://example.com" rel="external nonfollow" rel="external nonfollow" rel="external nonfollow">l ike to <i>example.com</i></a>'
# soup=BeautifulSoup(markup,'lxml')
# # print(soup)
# # print(soup.prettify())
# print(soup.find_all('i'))
# print(soup.find_all('i','a'))
# print(soup.find_all(['i','a']))
# print(soup.find_all(rel="external nonfollow"))
#json模块——键值对
#jsonpath寻址——多层嵌套字典 直接进行数据提取
# data={'key1':{'key2':{'key3':{'key4':{'key5':{'key6':'python'}}}}}}
# print(data['key1']['key2']['key3']['key4']['key5']['key6'])
#
# import jsonpath
# print(jsonpath.jsonpath(data,'$.key1.key2.key3.key4.key5.key6'))
# print(jsonpath.jsonpath(data,'$..key6'))
#json模块去字符串 加字符串
# import json
# json.dump()
# json.loads()
# 序列化:python转成字符串 (操作完 执行保存操作前 序列化) json.dump() json.dumps()
# 反序列化:把字符串转成python(寻址之前 对字符串 进行去字符串的操作) json.loads() json.load()
#json.loads的用法
# import json
# str_list='[1,2,3,4]'
# str_dict='{"city":"北京","name":"小明"}'
# print(type(str_list))
# print(type(str_dict))
# print(type(json.loads(str_list)))
# print(type(json.loads(str_dict)))
#json.dump的用法
# import json
# app_list=[
# {"name":"腾讯qq","link":"http://www.qq.com"},
# {"name":"新浪微博","link":"http://www.xinlang.com"},
# {"name":"吃鸡","link":"http://www.***.com"}
# ]
# with open('app.json','w',encoding='utf-8') as f:
# json.dump(app_list,f,ensure_ascii=False)
import urllib.request
from bs4 import BeautifulSoup
#四、实例
# from bs4 import BeautifulSoup
# markup='<a href="http://example.com" rel="external nonfollow" rel="external nonfollow" rel="external nonfollow">l ike to <i>example.com</i></a>'
# soup=BeautifulSoup(markup,'lxml')
# # print(soup)
# # print(soup.prettify())
# print(soup.find_all('i'))
# print(soup.find_all('i','a'))
# print(soup.find_all(['i','a']))
# print(soup.find_all(rel="external nonfollow"))
理论
浏览器显示完整网页的过程:
在浏览器地址栏中输入網址,例如http://www.baidu.com,
浏览器会发送一个Request请求去获取http://www.baidu.com的HTML页面
服务器会把包含该页面的response对象返回给浏览器
浏览器分析页面中的内容发现其中引用了很多文件,包括image js文件等,所以浏览器会再次发送Request去获取这些图片 js文件、
当所有的文件下载完成,浏览器根据html的语法结构,将网页完整的显示出来
浏览器浏览网页的过程:
浏览器通过DNS域名服务器查找对应的ip地址
向ip地址对应的web服务器发送请求
web服务器响应请求,发回html页面
浏览器解析html内容,并显示出来
状态码
主要:
200请求被成功处理 ;
404没有对应资源 403没有访问权限 500服务器错误。
其他(了解):
100 Continue 表示服务器已收到请求的一部分,客户端应继续发送其余部分。
200 OK 表示请求已成功处理,信息在响应正文中返回。
201 Created 表示请求已被成功创建(如新资源已生成)。
400 Bad Request 请求语法错误或参数无效。
401 Unauthorized 请求未经授权,需要验证身份后再次尝试。
403 Forbidden 服务器拒绝请求,权限不足。
501 Not Implemented 服务器不支持请求的功能。
502 Bad Gateway 作为网关或代理服务器时,从上游服务器接收到无效响应。
503 Service Unavailable 服务暂时不可用,如服务器过载或维护中。
urllib库: python的内置库
urllib库包括三大模块:urllib.request: urllib.error, urllib.parse
urllib.request用于请求
urllib.error: 处理异常
urllib.parse: 用于解析 中文 url编码转换
urllib.robotparser 专门解析robots协议
2.爬虫案例
导入urllib 导入库中的模块request (两种导入方式)
调用库.模块中的具体函数urlopen—该函数功能打开url地址用的 打开url地址返回response对象, 利用.read()函数把对象中的内容读出来
读出来的对象内容为bytes数据类型,利用.decode('utf-8')转码方式把bytes数据类型转化为国际化编码方式,从而保证原格式、中文能正常显示。
3、检查你的速度timesleep休眠时间(后边讲)
服务器是否响应,多久响应,timeout超时,超过此时间服务器不给响应的话,自己终止程序
4三个小函数:geturl()、 getcode()、info()
5、服务器响应:1.正常响应;2.是爬虫报红; 3.是爬虫不报红; 4.是爬虫一直等待
区分好三个ruquest:Request请求: request模块: Request函数
为了更好的爬取页面内容,改头换面:更改urse-agent-Request函数,以下为更改步骤:
(1)首先正常访问页面,右击检查,查看网络中Request header信息中的User-Agent,明确格式为字典值mozilla格式
(2)调用Urllib库中的request模块中的Request函数,实现重构头部信息操作
urllib.request.Request(url=url,headers=header)等号左边均为固定格式,等号右边均为单纯的变单名
(3)重构好头部后,再用重构好头部的这个url地址讲行发送请求和获取响应
6. urllib库中的parse模块,明确作用—一般用于拼接url地址用:例如让用户输入,完成编码,完成拼接url,进行访问
urllibparse.urlencode(),此处urlencode函数要求,被编码的对象应为键值对的形式
urllib.parse.quote(,此处quote函数,不要求被编码对象为键值对形式
二
学习抛出异常与捕获异常try except
异常情况2种:urlerror httperror
爬取百度
import urllib.request
head={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.54'}
url='https://www.baidu.com/'
new_url=urllib.request.Request(url=url,headers=head)
response=urllib.request.urlopen(new_url,timeout=10)
res=response.read().decode('utf-8')
print(res)
拼接地址
import urllib.parse
para1=urllib.parse.urlencode({'User-Agent':'张三'})
para2=urllib.parse.quote('张三')
print(para1)
print(para2)
import urllib.request
import urllib.parse
name=input('请你输入要爬取的主题:')
url2=urllib.parse.urlencode({'wd':name})
url1='https://www.baidu.com/s?'
url=url1+url2
print(url)
二、发送请求 获取响应
1.包装url地址 2.发送请求 3.获取响应
header={'User-Agent':''}
new_url=urllib.request.Request(url=url,headers=header)
response=urllib.request.urlopen(new_url)
html=response.read().decode('utf-8')
print(html)
# 三、保存网页内容
# 容器 内容
filename=name+'.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
百度贴吧 先定义类(简体架构)
class Baidutiebaspide:
def __init__(self):#初始化函数:放一些初始化的量
#头部信息 url的结构
pass
def get_html(self):#发送请求 获取响应
pass
def parse_html(self):#解析
pass
def save_html(self):#保存
pass
def run(self):#控制函数的整体运行
pass
if __name__=='__main__':
spider=Baidutiebaspide()
spider.run()
例子1
import urllib.request
import urllib.parse
name=input('请你输入要爬取的主题:')
url2=urllib.parse.urlencode({'query':name})
url1='https://new.qq.com
/search?'
url=url1+url2
print(url)
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.54'}
new_url=urllib.request.Request(url=url,headers=header)
response=urllib.request.urlopen(new_url,timeout=10)
html=response.read().decode('utf-8')
filename=name+'.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
import urllib.request
try:
reponse=urllib.request.urlopen('https://www.baidu.com/',timeout=0.01)
print(reponse)
except Exception as error:
print(error)
import urllib.request
import urllib.error
req=urllib.request.Request('http://jhfusdfhwefsdhf.com')
try:
urllib.request.urlopen(req)
except urllib.error.URLError as error:
print(error)
import urllib.parse
import urllib.request
class BaiduTiebaspiader:
def __init__(self):
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
self.url='https://tieba.baidu.com/f?kw={}&pn={}'
def get_html(self,url):
req=urllib.request.Request(url=url,headers=self.header)
res=urllib.request.urlopen(req)
html=res.read().decode()
return html
def parse_html(self):
pass
def save_html(self,filename,html):
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
def run(self):
name=input('请你输入要抓取的名称:')
params=urllib.parse.quote(name)
start=int(input('请你输入起始页:'))
end=int(input('请你输入终止页:'))
for page in range(start,end+1):
pn=(page-1)*50
url=self.url.format(params,pn)
html=self.get_html(url)
filename='{}_第{}页.html'.format(name,page)
self.save_html(filename,html)
if __name__=='__main__':
spider=BaiduTiebaspiader()
spider.run()
使用data_list 存放数据,提取下一页url地址进行爬取
from urllib import request,parse
from lxml import etree
class Tieba(object):
def __init__(self):
self.url = 'https://tieba.baidu.com/f?kw=%E7%94%B5%E5%BD%B1%E7%A5%A8%E6%88%BF'
self.headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'}
def get_data(self,url):
req=request.Request(url=url,headers=self.headers)
res=request.urlopen(req)
response=res.read().decode()
return response
def parse_data(self,data):
html=etree.HTML(data)
el_list=html.xpath('//*[@id="thread_list"]/li/div/div[2]/div[1]/div[1]/a')
print(len(el_list))
data_list=[]
for el in el_list:
temp={}
temp['title']=el.xpath(',/text()')[0]
temp['link']='https://tieba.com/'+el.xpath('./@href')[0]
data_list.append(temp)
try:
next_url='https:'+html.xpath('//a[conteains(tect(),"下一页")]/@href')
except:
next_url=None
return data_list,next_url
def save_data(self,data_list):
for data in data_list:
print(data)
def run(self):
next_url=self.url
while True:
data=self.get_data(next_url)
data_list,next_url=self.parse_data(data)
self.save_data(data_list)
print(next_url)
if next_url==None:
break
if __name__ == '__main':
tieba=Tieba('')
tieba.run()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









