






- 正则表达式提取器:提取任意格式的响应数据
- Xpath提取器:提取HTML格式的响应数据
- JSON提取器:提取JSON格式的响应数据
正则表达式
位置:测试计划-线程组-http请求-后置处理器-正则表达式
公式格式:左边界(匹配符号)右边界:可以提取出想要获取的数据内容
.: 是通配符,可以代表任意字符(除换行回车)
?: 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找左边界和右边界
.*:匹配规则:找到左边界值后,往右查找右边界,找到最后面的右边界,中间的所有数据都被记录下来
*:代表前面的字符出现0次或者多次
公式格式:左边界(.*?)右边界
- 通过一个正则表达式可以提取多组数据,每组数据设置对应的左边界和右边界即可
- 每一组数据都可以有一个或者多个值
- 格式:(.*?)-(.*?)-(.*?)\n
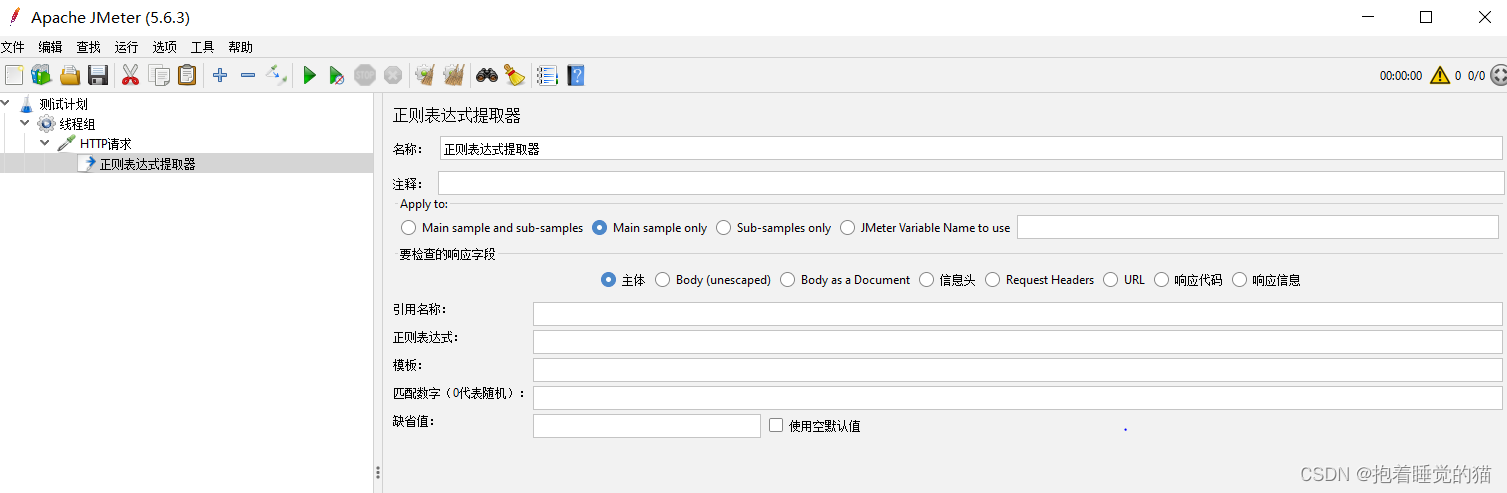
参数介绍:
- 引用名称:存放提取出的值的参数名称,供下一个请求引用,如填写title,则可以用${title}引用他
- 正则表达式:左边界(.*?)右边界
- 模块:用$$引用起来,如果正则表达式中有多个提取值,则可以是$2$$3$等等,表示解析到的第几个值给title.如:$1$表示解析到的第一个值
- 匹配数字:0代表随机取值,-1代表全部取值,1代表取第一个值
- 缺省值:如果参数没有取到值,默认给他一个值取
Xpath 提取器
位置:测试计划-线程组-http请求-后置处理器-xpath提取器
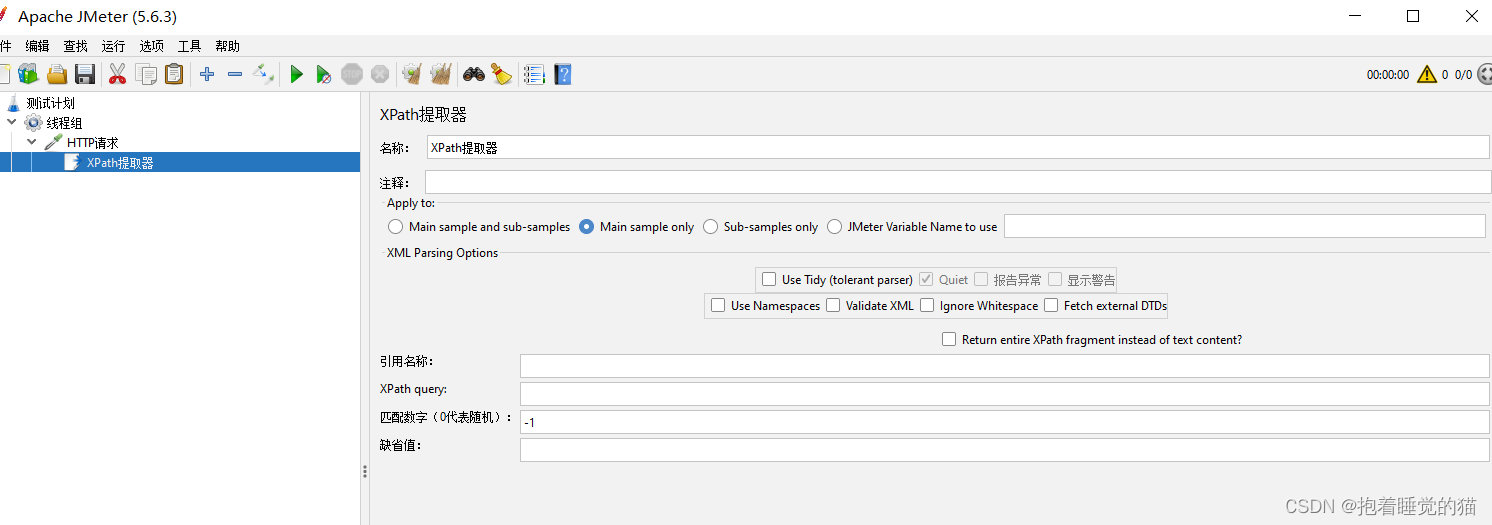
参数介绍:
- use tidy:当需要处理的页面是html格式时,必须选中该选项;当处理页面是xml、xhtml格式取消该选项
- 引用名称:存放提取值的参数名称
- xpath query:用于提取值的xpath表达式
- 匹配数字:如果xpath路径查询出许多结果,则可以选择提取哪个,0表示随机,-1表示提取所有结果,1表示第一个值
- 缺省值:参数的默认值
json提取器
位置:测试计划-线程组-http请求-后置处理器-json提取器
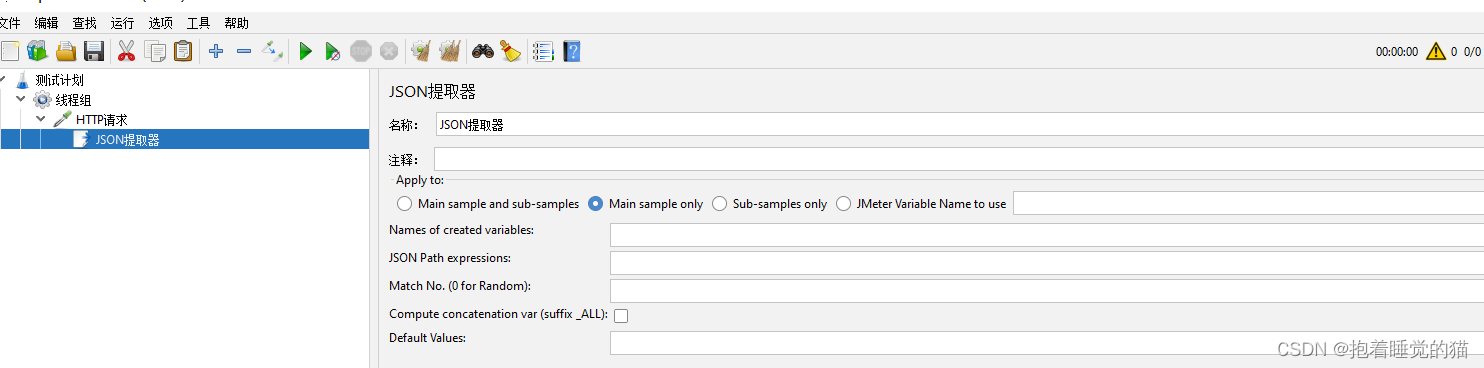
参数介绍:
name of created varibles:存放提取出的值的参数名称
json path expreession:json枯井表达式
defalut values:参数的默认值
jmeter属性
setProperty函数:将值保存成jmeter属性
-需要通过BeanShell取样器来执行
property函数:在其他线程组中使用property函数读取属性
-在其他线程组中使用
步骤:
- 添加线程组1
- 添加http请求-天气
- 添加json取样器
- 添加beanshell取样器
- 添加线程组2
- 添加http请求-百度
- 添加查看结果树















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









