







目录
设计数据库
设计过程
- 需求分析
- 概念数据库设计
- 逻辑数据库设计
- 物理数据库设计
阶段描述
- 设计方法学
- 需求表述
- E-R 建模
- 将ER model 映射成 relation model
- 采用一个数据库管理系统,实现一个数据库,搭建起一个数据库服务器
ER建模
- 实体(Entity) 客观存在并可相互区分的事物叫实体。如学生张三、工人李四、计算机系、数据库概论
- 属性(Attribute) 实体所具有的某一特性,一个实体可以由若干个属性来刻画。例如,学生可由学号、姓名、年龄、系等组成
- 域(Domain) 属性的取值范围。例如,性别的域为(男、女),月份的域为1到12的整数
- 联系(Relationship) 实体之间的相互关联。如学生与老师间的授课关系,学生与学生间有班长关系;联系也可以有属性,如学生与课程之间有选课联系,每个选课联系都有一个成绩作为其属性
- 元或度(Degree)参与联系的实体集的个数称为联系的元。如学生选修课程是二元联系,供应商向工程供应零件则是三元联系
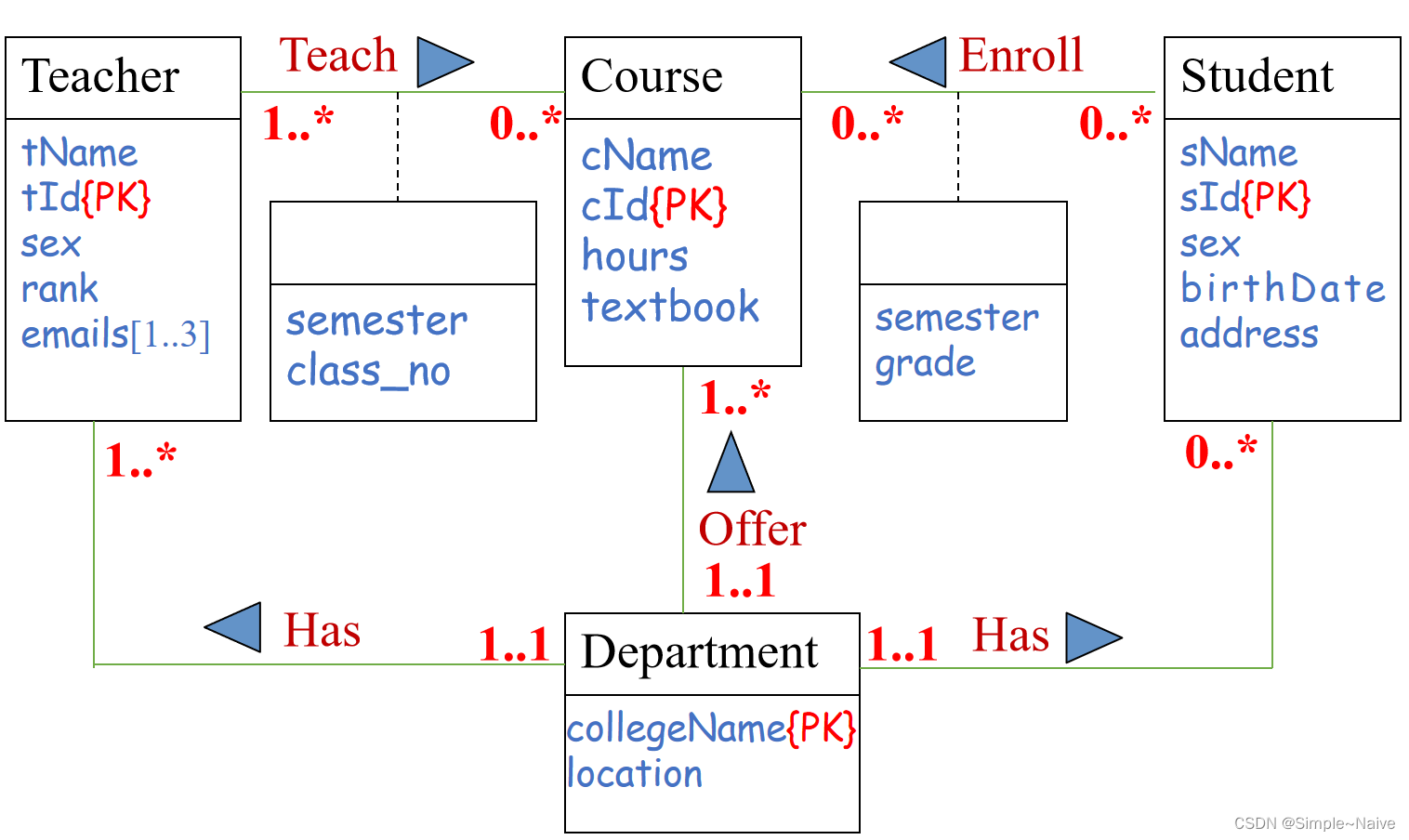
联系的种类
- 一对一联系(1:1):实体集A中的每一个实体,实体集B中至少有一个实体与之联系,反之亦然
- 一对多联系(1:n):实体集A中的每一个实体,实体集B中有 n (n ≥ 0)个实体与之联系,而对于B中的每个实体,A中至多只有一个实体与之联系
- 多对多联系(m:n):实体集A中的每一个实体,实体集B中有 n (n ≥ 0)个实体与之联系,而B中的每一个实体,A中有 m (m ≥ 0)个实体与之联系
多元关系中的约束标记方法
对于多元关系,它至少有三个端,当标记某一端的约束时,其它端的实例对象数都设为1,然后从最悲观和最乐观视角来确定约束。 当标注Staff的参与情况时,假设Branch出一个,Client也出一个,再来决定参与情况

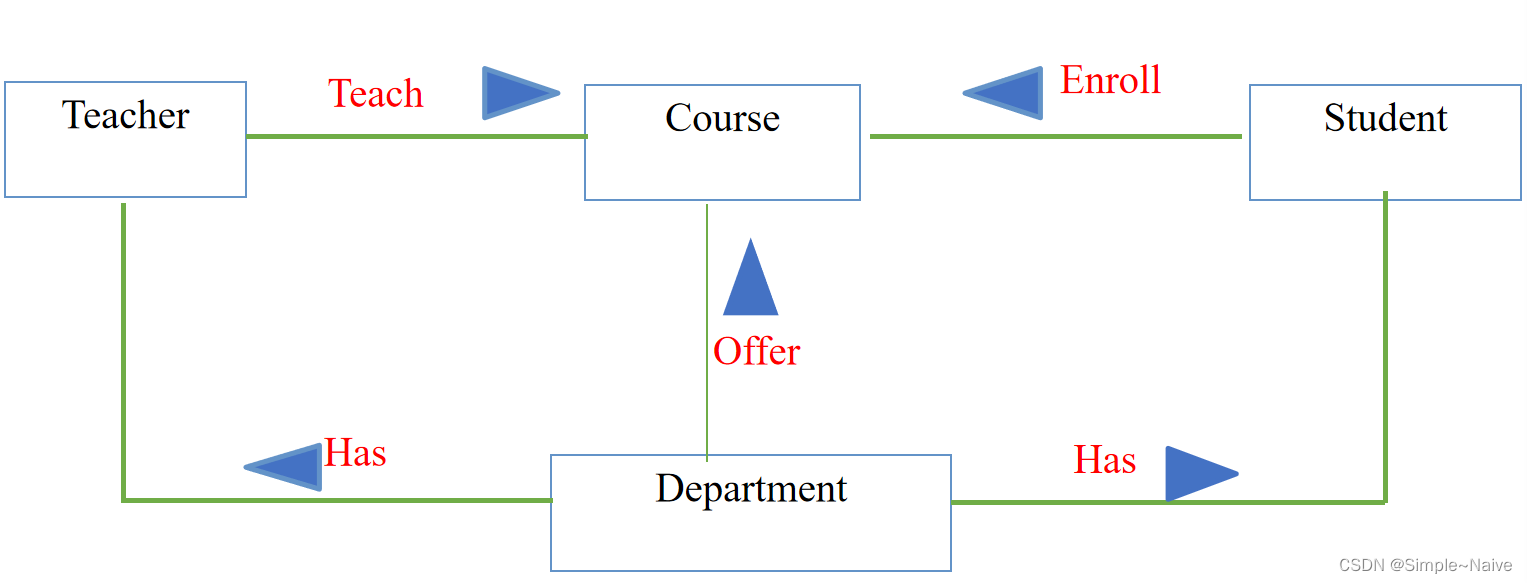
ER建模过程:
标识实体

标识关系
(方向:主动参与指向被动 )
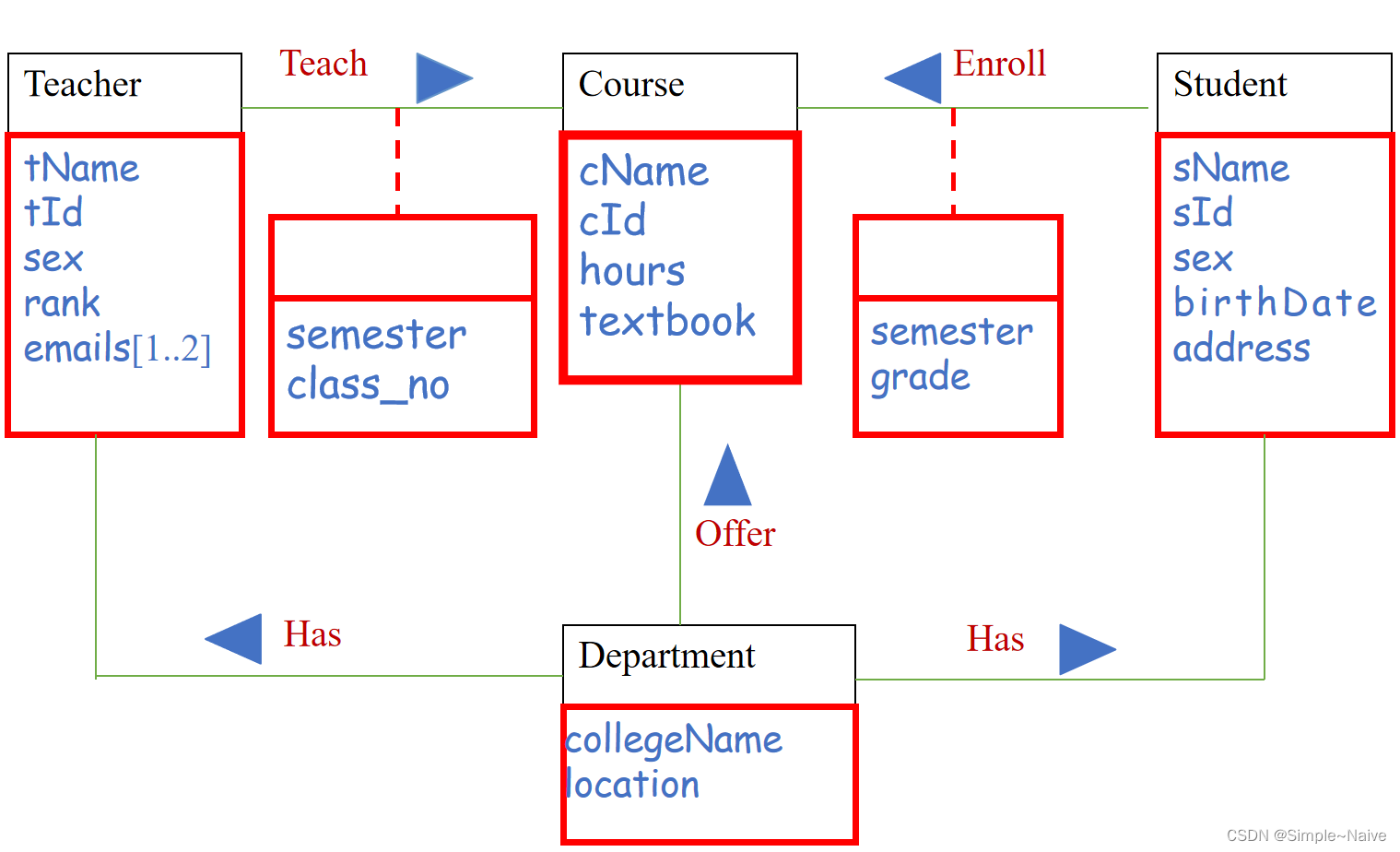
标识属性
(实体的属性 + 联系的属性 )
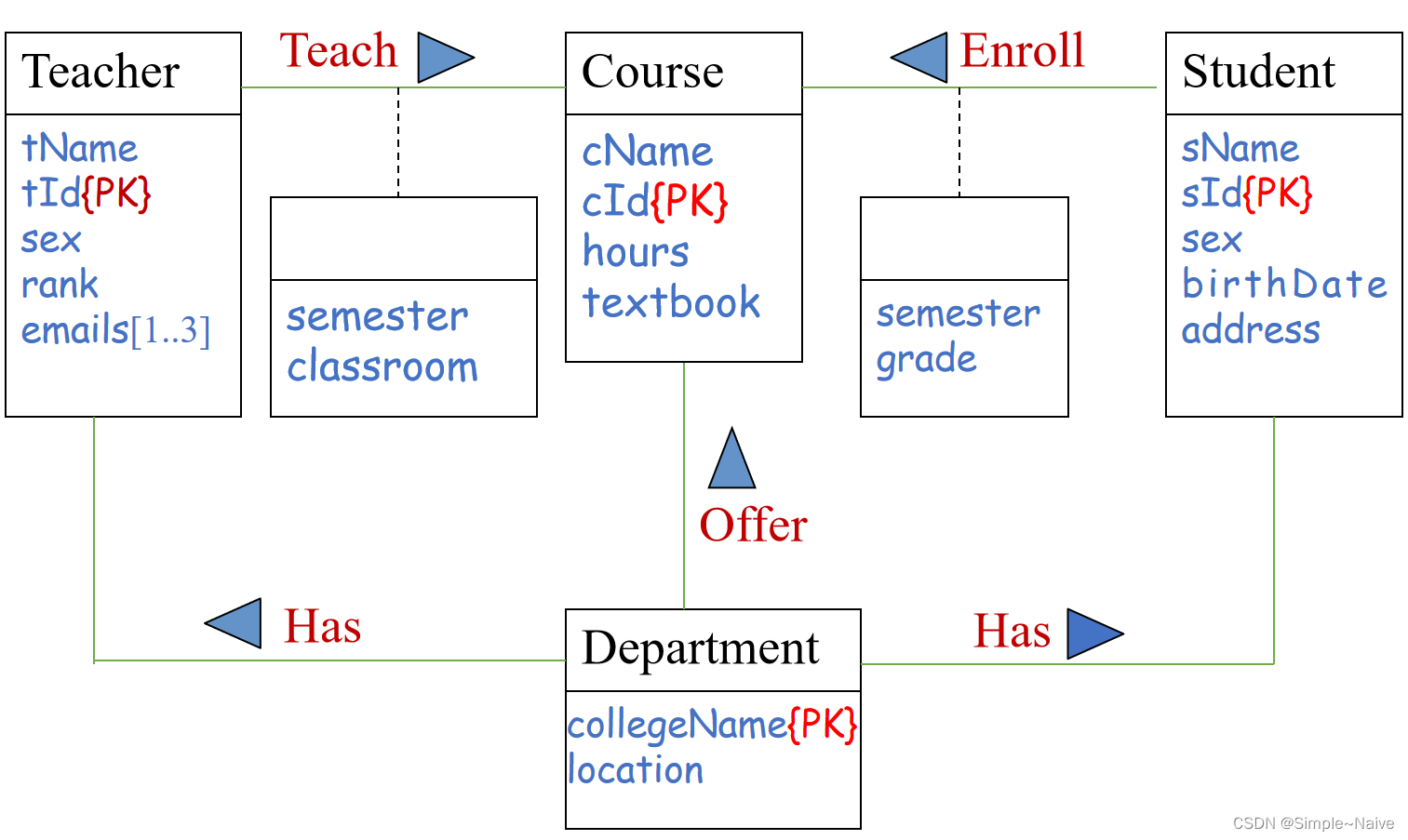
标识实体约束
(标识主键)
标识关系约束
(实体之间的联系)
ER图转换关系模式
将ER图转换成对应的关系模式有如下步骤。
转换步骤
将每个强实体转换成一个关系
强实体的主键,也是关系的主键
将每个弱实体转换成一个关系
将弱实体所依赖的强实体的主键将加入到弱实体对应的关系中,作为关系的主键的组成部分
处理一对一关系
将一对一关系所涉及的两个实体所对应的两个关系模式,将其一的主键加入到另一个关系模式中,作为外键
处理一对多关系
将一对多关系所涉及的两个实体所对应的两个关系模式,将”一”那边的主键加入到”多”那边的关系模式中,作为外键
处理多对多关系
单独创建一个关系来表达多对多关系,将多对多关系所涉及的两个实体所对应的两个关系的主键加入到新创建的关系中,作为该关系主键的组成部分
处理多值属性
单独创建一个关系来表达,将其所属的关系的主键,加进所创建的关系中,作为主键的组成部分
处理度≧3的关系
单独创建一个关系,将所涉及的主键加入作为主键的组成部分
得到关系模式后,采用范式对得到的关系模式进行合理性验证。验证之后,对照业务需求逐一检查,看设计是否能够满足业务需求。不行的话,对设计(ER图)进行调整和完善。
关系规范化
函数依赖
设R(U)是属性集U上的关系模式,X、Y是U的子集, r是R的任一具体关系,如果对于r的r任意两个元组 t、s,若t[X] = s[X],则t[Y] = s[Y],那么称“X函数决定Y”,或“Y函数依赖于X”,记作X Y
平凡函数依赖
若X Y 是一个函数依赖,且Y
X,则 X
Y 是一个平凡函数依赖
完全函数依赖
若X Y 是一个函数依赖,且对于任意X'
X,X'
Y都不成立,则 X
Y 是一个完全函数依赖,记作X
Y
部分函数依赖
若X Y 是一个函数依赖,但不是完全函数依赖,则为部分函数依赖
传递函数依赖
设R(U)是属性集U上的关系模式,X、Y、Z U,若 X
Y, Y
Z且Y 不能推出 X,Z - Y ≠
,Y - X ≠
,则称Z传递函数依赖于X,记作X
Z
逻辑蕴涵
设F是关系模式R的一个函数依赖集,X、Y是R的子集,若从F的函数依赖中能推出 X Y,则称F逻辑蕴含 X
Y
Armstrong公理系统
设关系R(,
,…,
)和属性集U={
,
,…,
},X、Y、Z、W均是U的子集,F是R上只涉及到U中属性的函数依赖集,则Armstrong公理为:
- 自反律:若Y
X
Y在 R 上成立
- 增广律:若X
- 传递律:若X
函数依赖与属性的关系
设有属性集X,Y和关系模式R
- 若X,Y之间是1:1关系,则存在函数依赖 X
- 若X,Y之间是n:1关系,则存在函数依赖 X
- 若X,Y之间是n:m关系,则不存在函数依赖
闭包的计算
对于关系模式R和函数依赖集F,则称所有用Armstrong公理从F推出的函数依赖中,
的属性集合为X的属性闭包,记为
算法
- 计算
,且
- 在F中找到函数依赖(箭头)左边是
子集的函数依赖,然后将箭头右边的属性加入到
- 若
,重复2的操作,直到
的子集
函数依赖的等价和覆盖
关系R上有两个函数依赖集F和G,若,则称F和G是等价的,记作
。
若函数依赖集,则称G是F的一个覆盖。
函数依赖集的最小集
对于给定的函数依赖F,其最小依赖集当满足如下条件时成立,记作
的每个依赖的右部都是单个属性
,
与
的真子集
,
与
计算的方法
- 将F每一个函数依赖(箭头)的右边属性分解为单一属性
- 检查每个F中函数依赖左边的非单属性的依赖,求非单属性中每一个属性的闭包,若其包含该函数依赖右边的属性,则可确定其余非单属性为多余属性,将其去除得到新的函数依赖集F
- 从第一个依赖开始,假设将其从F中去除时,在剩下的依赖中求该依赖的左边属性的闭包,若其包含右边属性,则将该依赖真正去除,否则不能去除。
键及属性的关系规范化表示
- 超键:设K为R< U , F >的属性或属性组,若K
- 候选键:设K为R< U , F >的超键,若K
U,则称K为R的候选键
- 主属性(prime attribute):存在于任意一个候选键中的属性,都称作主属性,其它属性(即不存在与任何候选键中的属性)称为非主属性(non-prime attribute)
数据库规范化
数据库规范化是根据一系列所谓的规范形式(范式) 构建、完善关系数据库的过程,目的是减少数据冗余,提高数据完整性。
范式
定义:范式是对关系的不同数据依赖程度的要求
通过模式分解将一个低级范式转换为若干个高级范式的过程称作规范化(概念的纯粹化)
第一范式(1NF)
关系中每一分量不可再分,即不能以集合、序列等作为属性值。
要想得到第一范式,需要对原关系拆分或平铺。
第二范式(2NF)
关系是第一范式且每个非主属性都完全依赖于候选键。
要得到第二范式,只需去除所有不完全依赖于候选键的非主属性。
第三范式(3NF)
关系是第二范式且每个非主属性都非传递函数依赖于候选键
得到第三范式的算法
- 计算得到关系
的最小依赖集
- 若
,则输出
终止
- 若
中的某些属性,即
的子集,与
- 对于
,都构成一个关系子关系模式
- 分解终止,输出
BC范式(BCNF)
关系R属于第三范式,其函数依赖集F中每个依赖的决定因素一定包含R的某个候选键
一个满足BCNF的关系范式需要如下条件:
- 所有非主属性对每一个键都是完全函数依赖
- 不包含它的键,也是完全函数依赖
满足3NF而不满足BCNF的基本条件是:
- 至少有两个或以上的组合性候选键
- 候选键之间存在交集,即它们之间有公共属性
分解到3NF大概率就满足了BCNF
得到BC范式的算法
- 令
,
- 如果
中的所有模式都是BCNF,则输出
- 如果
不是BCNF,则
不属于
,
,用
代替
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









