






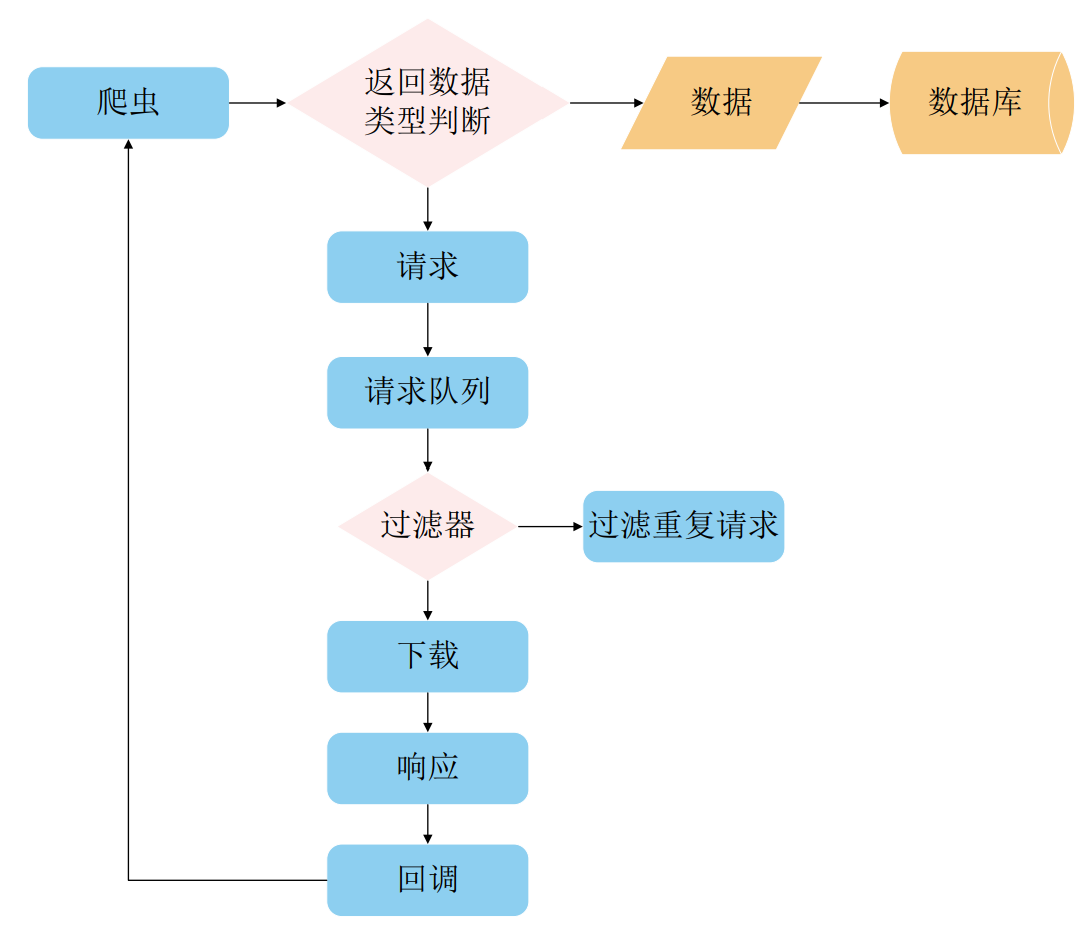
自设计爬虫框架的工作流程
1. 爬虫组件(起点)
- 负责定义爬取逻辑
- 处理页面解析
- 生成新的请求或提取数据
2. 返回数据类型判断
- 判断爬虫返回的内容类型
- 两种主要类型:
- 新的请求(需要继续爬取的URL)
- 数据(已提取的目标信息)
3. 请求处理流程 如果是请求类型:
- 生成请求对象
- 将请求放入请求队列
- 通过过滤器进行过滤
4. 过滤器机制
- 对请求进行去重判断
- 处理无效请求
- 生成重复请求时进行过滤
- 支持重试机制(过滤重复请求)
5. 下载处理
- 执行实际的网络请求
- 处理请求超时
- 处理网络错误
- 获取响应内容
6. 响应处理
- 处理下载得到的响应
- 解析响应内容
- 检查响应状态
7. 回调处理
- 将响应传递给爬虫处理
- 执行用户定义的回调函数
- 继续生成新的请求或数据
8. 数据处理流程 如果是数据类型:
- 数据清洗和格式化
- 数据验证
- 存储到数据库
出入队组件核心功能
那么,根据流程图分析,出入队组件应该完成以下核心功能:
1. 请求队列管理
- 入队:接收新的请求并加入队列
- 出队:提供下一个要处理的请求
- 队列状态监控:判断队列是否为空
2. 请求过滤功能
- 实现请求去重机制
- 过滤无效或重复的URL
- 处理被过滤请求的重试逻辑
import asyncio
from asyncio import PriorityQueue, TimeoutError
from typing import Optional, Set
from My_Spider.utils.pqueue import SpiderPriorityQueue
class Scheduler:
def __init__(self):
self.request_queue: Optional[SpiderPriorityQueue] = None
self.seen_requests: Set[str] = set() # 用于去重的集合
self.retry_times = 3 # 重试次数
def open(self):
self.request_queue = SpiderPriorityQueue()
self.seen_requests.clear()
async def next_request(self):
request = await self.request_queue.get()
return request
async def enqueue_request(self, request):
# 实现请求过滤
if not self._filter_request(request):
return False
# 将请求指纹加入去重集合
self.seen_requests.add(self._get_request_fingerprint(request))
# 入队
await self.request_queue.put(request)
return True
def _filter_request(self, request) -> bool:
# 判断是否是重复请求
fp = self._get_request_fingerprint(request)
if fp in self.seen_requests:
return False
return True
def _get_request_fingerprint(self, request) -> str:
# 生成请求的唯一标识,这里简单使用URL
# 实际使用时可能需要考虑更多因素,如请求方法、参数等
return request.url
def idle(self) -> bool:
return len(self) == 0
def __len__(self):
return self.request_queue.qsize()后续还可以添加的功能:
1. 请求优先级管理
2. 请求延迟处理
3. 请求超时重试机制
4. 请求频率限制
5. 分布式去重支持(如使用Redis替代本地set)
6. 更复杂的请求指纹生成算法
这样的设计能够更好地控制爬虫的请求流程,避免重复请求,提高爬虫效率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











