







前言:本博客讲解的内容为我们平时写的代码是怎样一步步地构建成一个可执行程序并运行
通过理解代码的一生
面对多文件的代码(跨文件的代码)时,编译器是怎么处理的
更好地理解平时的报错:什么是编译错误,什么是链接错误
目录
简要说明
每一个可执行程序都是从我们写的代码中演变过来的
代码在演变过程中需要经历两个的环境
-
翻译环境
- 执行环境
演变过程:源代码(我们平时写的)→ 汇编代码 → 二进制指令
在多个文件的情况下,由下图示:
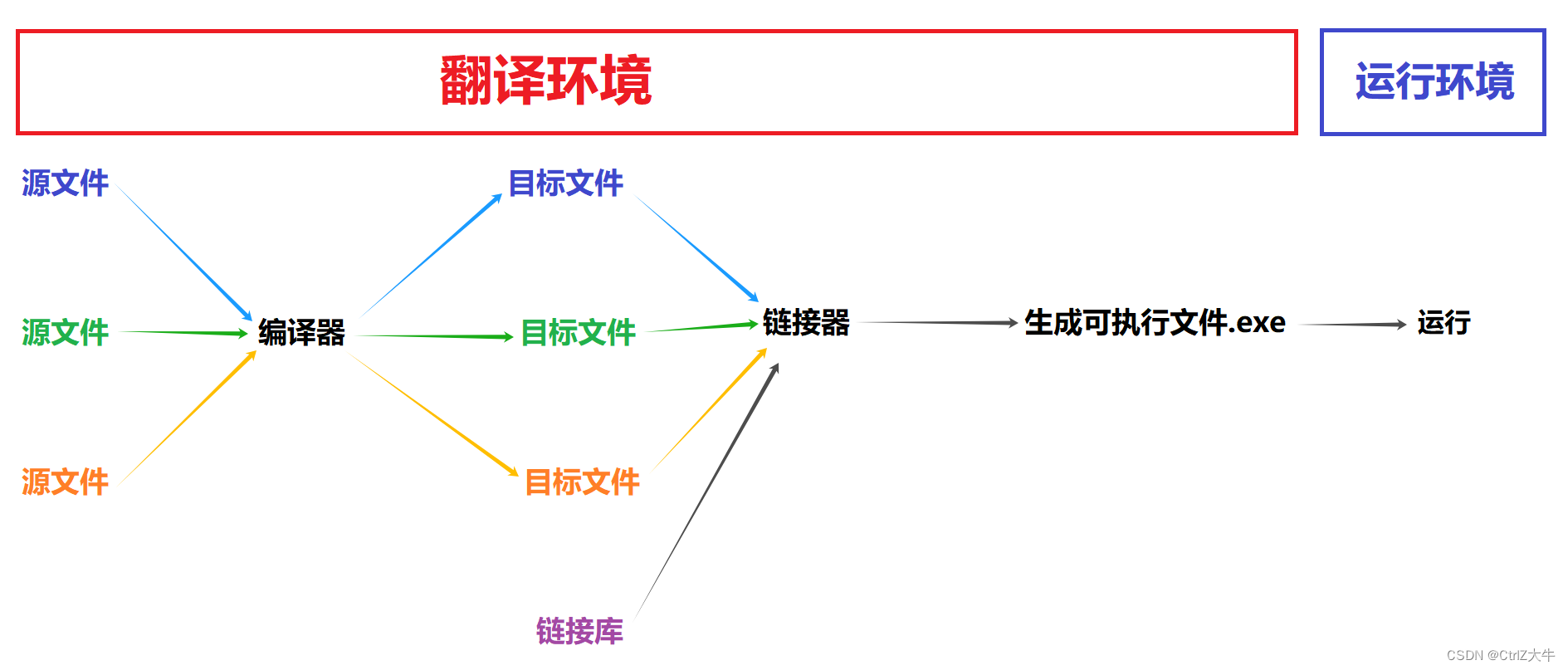
多个源文件依次经过编译器的处理,变成目标文件
多个目标文件一块经过链接器的处理,变成可执行文件
科普:链接库
链接库是什么?链接库里有什么?
在公司里,我们并不会把函数的声明和定义放到同一个源文件中
我们一般都会将函数进行声明和定义的分离
这样的话,当我们需要使用的时候,我们就只需要包含那个有函数声明的头文件(以Add.h为例)就可以了
而函数的具体实现(函数的定义)就放到另一个源文件(Add.c文件)下就好了
我们平时之所以可以很平常的使用printf或者scanf,就是因为包了头文件<stdio.h>
而<stdio.h>里面并没有函数的定义,只有函数的声明,原因和上面的一样(进行了函数的声明和定义的分离)
所以,链接库里面其实就装着<stdio.h>等头文件的实现
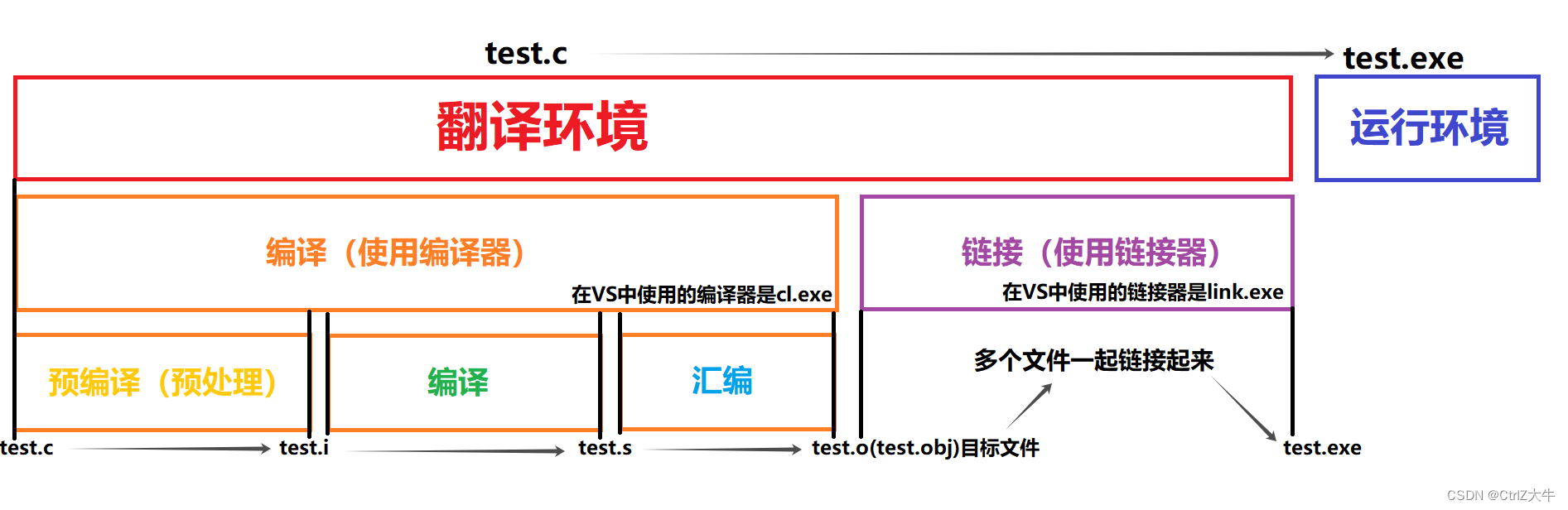
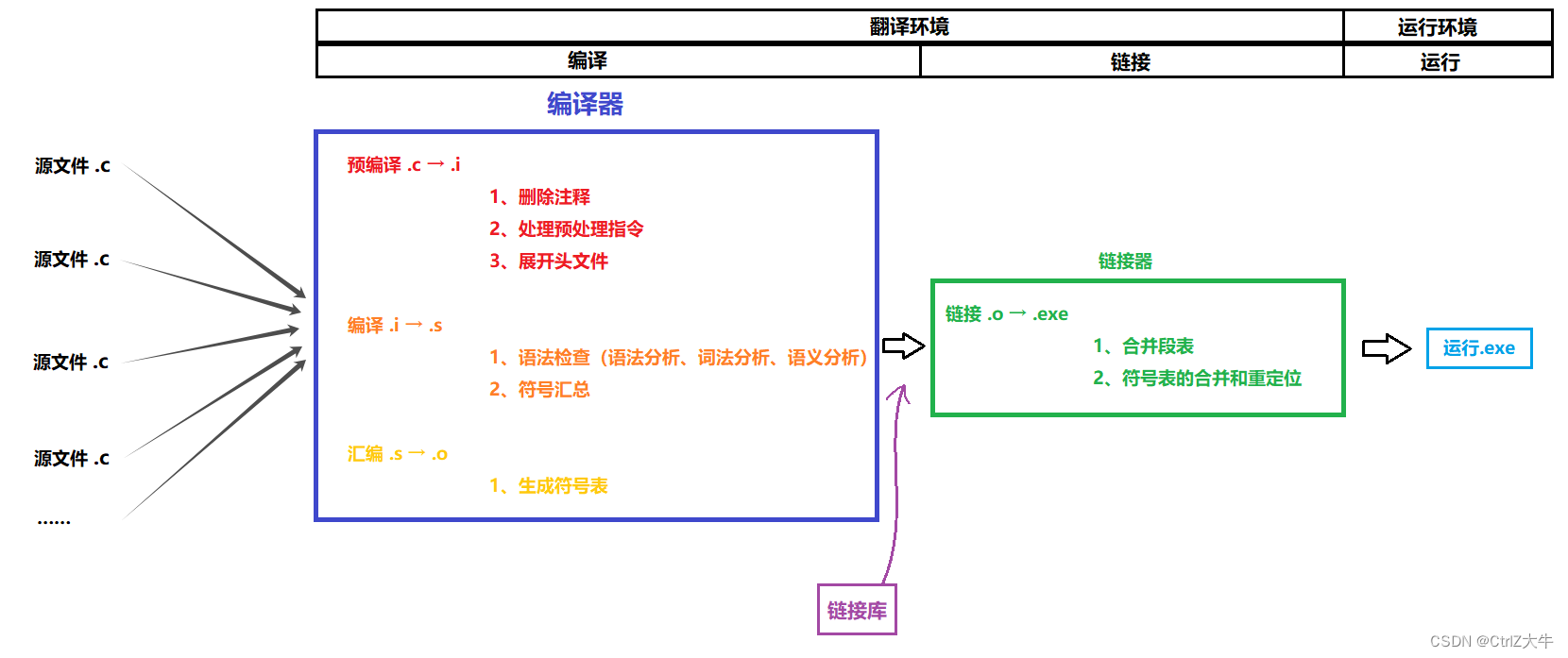
翻译环境详解
翻译环境被分为两部分
- 编译
- 链接
而编译又可以被分为三部分
- 预编译(预处理)
- 编译
- 汇编
图解如下:
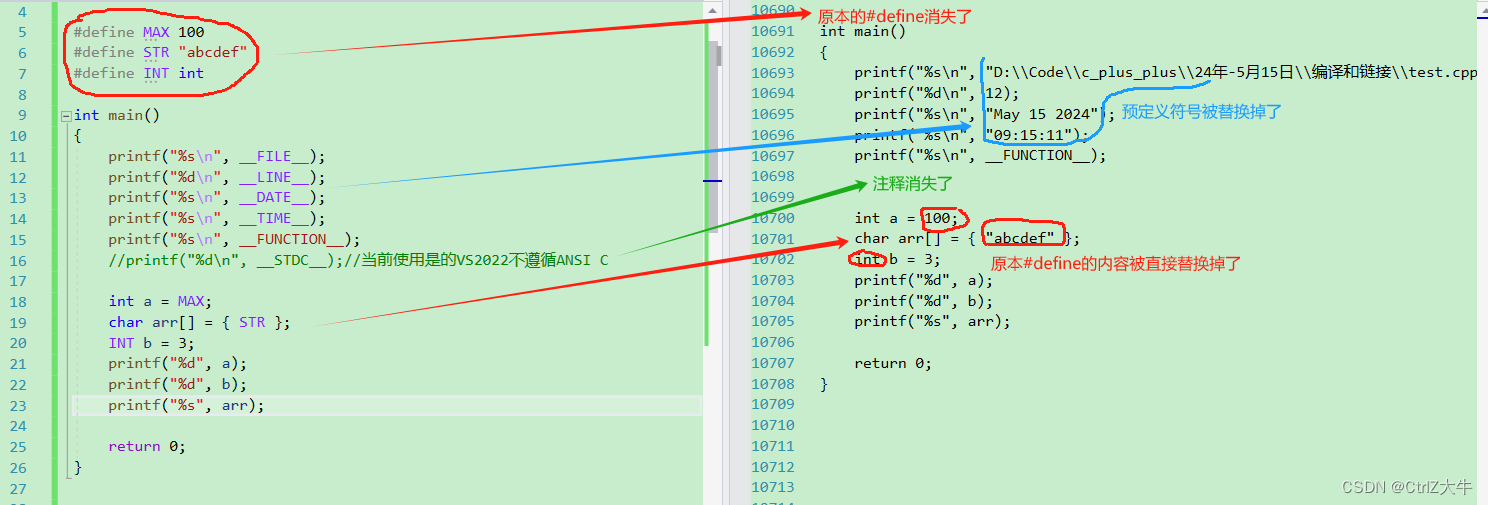
预编译(.c → .i)
即:删除了一些东西,拷贝进去了一些东西,替换了一些东西
工作内容(文本操作)
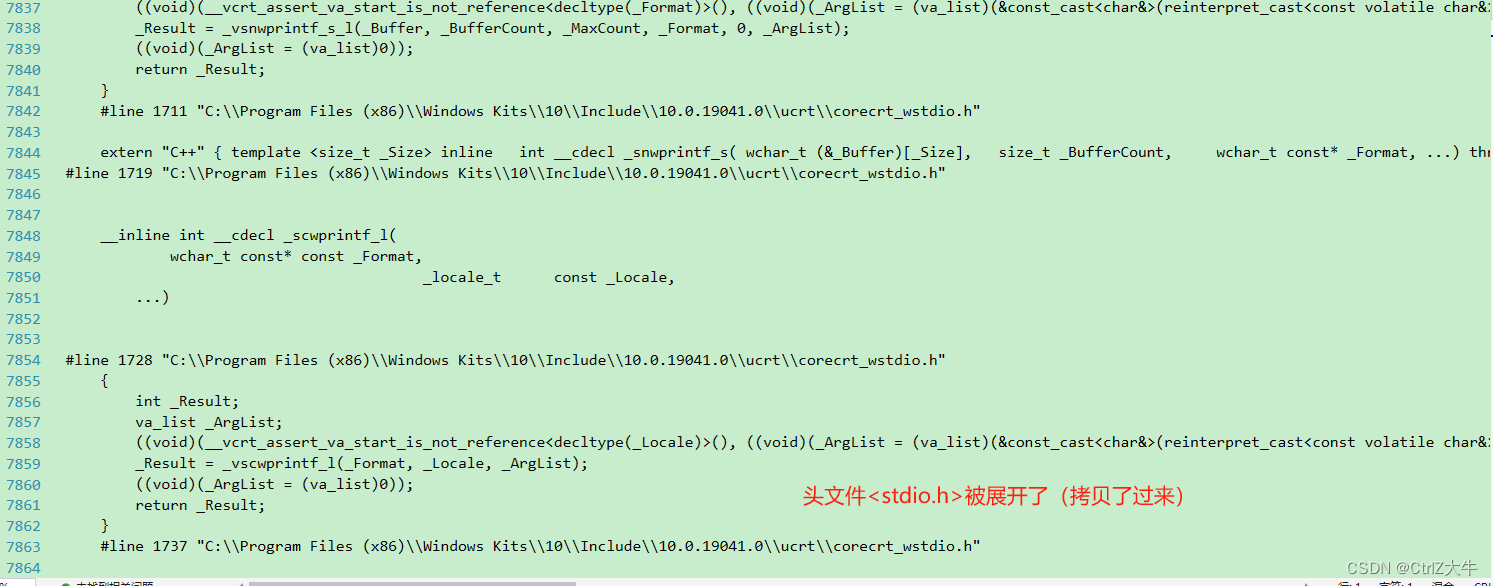
- 头文件展开(#include):将头文件的内容全部拷贝过来
- 处理预处理指令(#define符号的替换,预定义符号)
- 去掉注释(注释替换成了空格)
(预处理指令:#开头的都叫预处理指令,所以,其实#include也是预处理指令)
左侧为预处理之前,右侧为预处理之后
↓↓↓
头文件被拷贝过来了
↓↓↓
当源文件test.c经过了预处理后,后缀就修改了,就变成了test.i
(test.c → test.i)
编译(.i → .s)
工作内容:
- 语法检查
- 符号汇总
语法检查被分为三个板块
- 语法分析
- 语义分析
- 词法分析
语法检查
这三个板块实际过程十分复杂,此处大概有个印象就好了
以下我们浅浅了解一下语法检查的三个板块
假设对以下代码进行语法检查
array[index]=(index+4)*(2+6);首先进行词法分析:将上面的代码的每一个记号都拆开来,组成下面的表
之后进行语法分析:将以上表格中的记号组成下面的语法树
最后进行语义分析:对表达式的语法层面分析。编译器所能做的分析是语义的静态分析。静态语义分析通常包括声明和类型的匹配,类型的转换等。这个阶段会报告错误的语法信息。

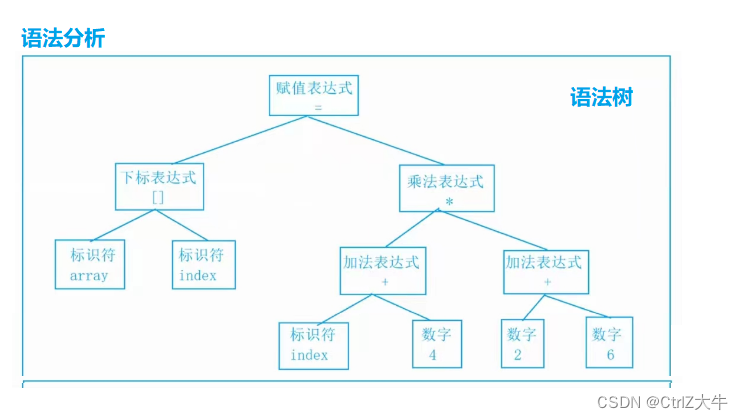
因此,如果出现了语法错误,编译器就会报错说“编译错误”;
常见的语法错误:
- 拼写错误(Typos)
- 缺少分号(Missing Semicolons)
- 括号不匹配(Mismatched Parentheses)
- 语法错误的运算符使用(Incorrect Operator Usage)
- 未声明的变量或函数(Undeclared Variables or Functions):直接使用连声明都没有的函数
- 不正确的标识符命名(Incorrect Identifier Naming):标识符必须遵循语言的命名规则,例如不能以数字开头,不能包含特殊字符等。违反这些规则会导致语法错误。
- 不完整的语句(Incomplete Statements)
- 函数参数不匹配(Mismatched function parameters)
除了语法检查,编译环节还有一项很重要的工作是
符号汇总
从上文,我们已经得知,每个源文件在变成目标文件时都会单独经过编译器处理
在这个过程中,编译器会把当前文件的符号汇总出来
汇总的符号都是全局的符号(全局函数,全局变量)
(毕竟全局的符号才涉及跨文件问题嘛)
例: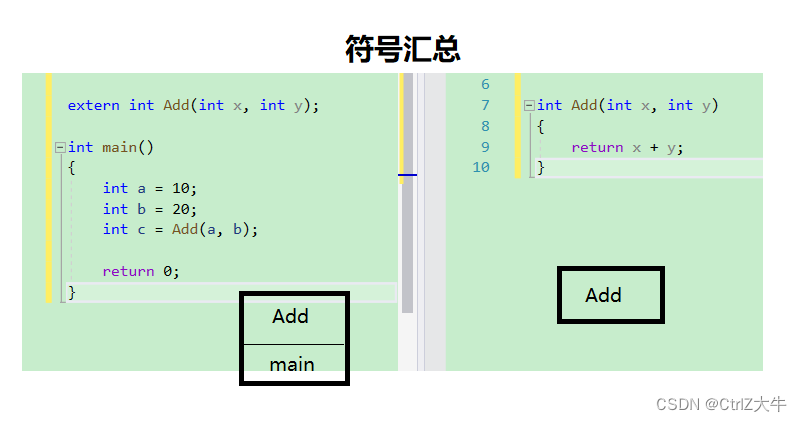
编译前后的代码图示:

当源文件test.i经过了预处理后,后缀就修改了,就变成了test.s
(test.i → test.s)
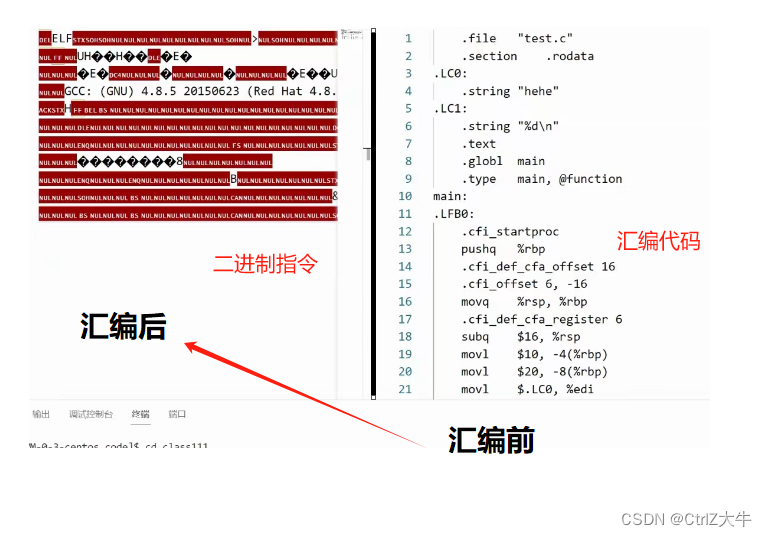
汇编(.s → .o)
工作内容:
- 将汇编代码转换成二进制指令
- 生成符号表
汇编前后的代码图示:
生成符号表
在之前符号汇总那里得到的符号再加上他们的地址,由此形成符号表
(如果函数仅仅有声明而没有定义,那就会暂时放一个空指针进去)
例:
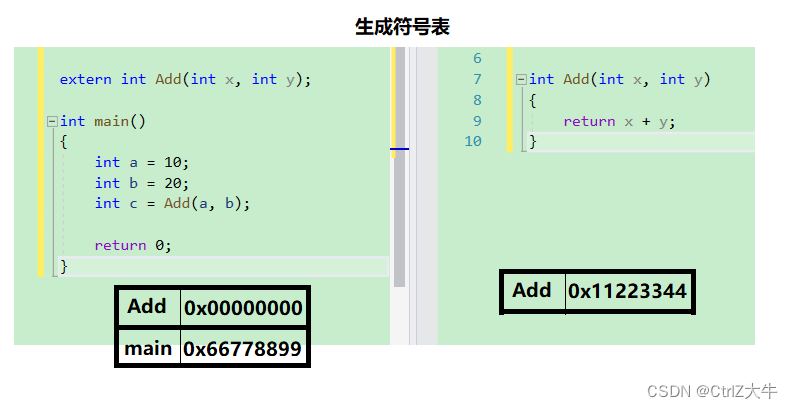
当源文件test.s经过了汇编后,后缀就修改了,就变成了test.o
(windows环境下生成的目标文件是.obj,而linux是.o(都是一样的意思))
(test.s → test.o)
链接(.o → .exe)
工作内容:
- 合并段表
- 符号表的合并和重定位
在此,我们需要抛出一个问题
Add.c文件和test.c文件是两个单独的文件
凭什么在Add.c文件里面定义的函数可以在test.c文件中使用?(以下我们将解释这个问题)
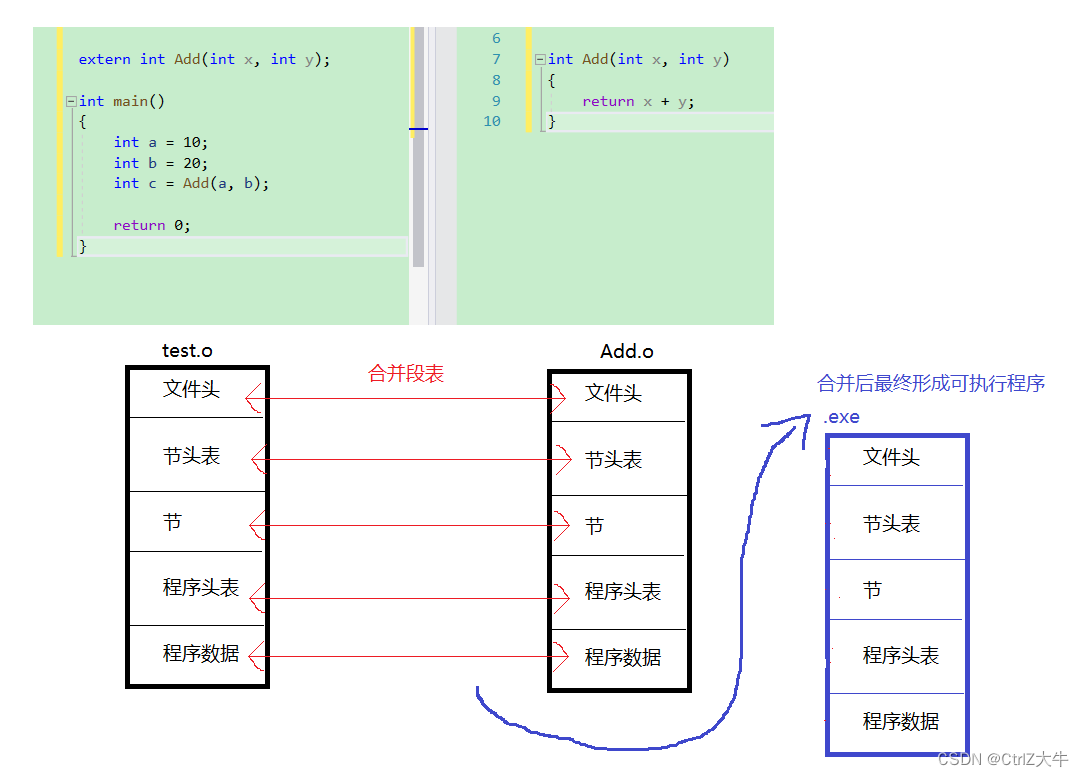
合并段表
科普:test.o,Add.o这些目标文件在形成的时候,都是按照一定格式形成的(不同编译器的形成格式不同)
以下以gcc编译器为例:
gcc编译器生成的文件都是按照elf这种文件格式组织的elf
在test.o中,编译器将文件分成多段
因为都是经过gcc编译形成的文件,所以Add.o中的格式一定与test.o的格式差不多
合并段表就是将他们相同段的数据进行合并,合并后生成一个二进制的可执行文件(这个二进制文件的格式也和Add.o和test.o的格式差不多)
符号表的合并和重定位
在进行合并段表的时候,符号表也要进行合并
(将同名的合并起来)
例:
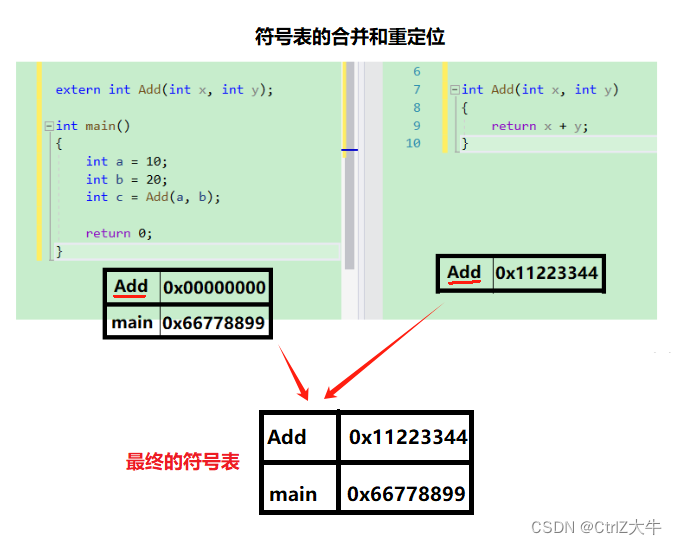
合并之后,就生成了最终的有效的符号表
未来,当编译器遇到了某个函数,他就会在符号表里根据名字找这个函数,根据其所对应的地址,就可以找到那个函数了
当编译器在test.c文件中遇到了Add函数,就会到符号表里找名为Add的函数,这样的话,即使test.c文件和Add.c文件是两个相互独立的源文件,test.c文件中也可以使用Add.c的函数了
如果将Add的函数屏蔽掉,那么Add.c文件在符号汇总,生成符号表时,就没有Add.c文件里面就没有Add符号了,也就是说,Add.c文件里面的Add函数不会进入符号表
而test.c文件里面还有Add函数的符号
所以,当编译器在test.c文件中遇到Add函数时,只能在符号表里面找到一个地址为空指针的Add了(相当于没找到Add函数了)
然后就会报以下错误:
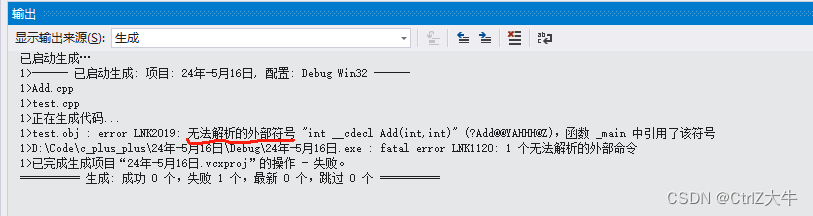
之前我们可能还会疑惑,为什么函数未定义报的错误叫做“无法解析的外部符号”
就是因为在符号表里面,找不到对应的函数
如果Add.c文件里面把Add改为add,也会遇到以上的问题(因为编译器是根据名字来找的)
常见的链接错误
未定义的符号(Undefined Symbols):链接器无法找到符号的定义,通常是因为缺少对应的库或对象文件。
重复的符号(Duplicate Symbols):在链接过程中,出现了多个相同名称的符号,可能是由于多次包含相同的源文件或库引起的。
符号冲突(Symbol Conflicts):当两个或多个库或对象文件中定义了相同名称但含义不同的符号时,链接器无法确定要使用哪一个。
运行环境详解
这个地方也比较复杂,所以也只是大概的说明一下
工作内容
- 将可执行程序.exe加载到内存中(一般由操作系统完成)(没有的话就自己手动完成)
- 开始执行程序,接着便调用main函数
- 开始执行程序的代码,利用一个运行时堆栈来执行代码→(如果对此不清楚,点此跳转)
- 终止程序,正常终止main函数,也有可能是意外终止
常见的意外终止
- 空指针解引用
- 内存泄漏露太多导致内存资源被耗尽
- 对一个数进行除0操作
- 访问了无效地址(段错误)
- 断电
总结
如果说报错是编译错误,那就是遇到了常规的语法错误
如果说报错的的是链接错误,那就是在符号表那里出了问题
ps:该博客目的是为了让读者在读完之后对这一方面有个大概的认识,其中的一些晦涩难懂的内容会被删减,望理解
如果对编译链接感兴趣,想要更加深挖这方面的知识,在此推荐一本书《程序员的自我修养》←点此获取网盘资源
















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











