






 文章介绍了使用C++编程语言实现的埃拉托斯特尼筛法筛选素数,并利用unordered_map高效存储素因子及其出现次数,优化查找过程。通过示例展示了如何计算给定整数n的素因子,满足特定条件的因子个数。
文章介绍了使用C++编程语言实现的埃拉托斯特尼筛法筛选素数,并利用unordered_map高效存储素因子及其出现次数,优化查找过程。通过示例展示了如何计算给定整数n的素因子,满足特定条件的因子个数。


方法一
参考:
思路
采用埃拉托斯特尼筛法(埃氏筛素数法)
- 从2开始,将2的倍数标记为合数,然后找到下一个未被标记的数,将其倍数标记为合数,重复这个过程,直到达到预定范围。
- 在每次标记过程中,未被标记的数即为质数。
这里需要知道这样一个素数原理:
任意的大于0整数,其质因子分解最多只有1个质因子大于 , 且该因子一定是一次幂。因此只需要筛一下2~1000以内的素数即可。
#include<bits/stdc++.h>
using namespace std;
int q;
long long n,k,ans;
vector<long long> Sushu;
//判断素数
void is_prime(){
bool isPrime[1001];
for(int i=2;i<=1000;i++){
isPrime[i]=true;
}
for(int i=2;i*i<=1000;i++){
if(isPrime[i]){
for(int j=i*i;j<=1000;j+=i){
isPrime[j]=false;
}
}
}
for(int i=2;i<=1000;i++){
if(isPrime[i]){
Sushu.push_back(i);
}
}
}
int main(){
is_prime();
cin>>q;
while(q--){
cin>>n>>k;
ans=1;
int flag=0,curK=0;
while(n>1&&flag<Sushu.size()){
if(n%Sushu[flag]==0){
curK ++;
n/=Sushu[flag];
}else{
if(curK<k){
curK=0;
flag++;
continue;
}
for(int i=0;i<curK;i++){
ans*=Sushu[flag];
}
curK=0;
flag++;
}
}
if(curK>=k){
for(int i=0;i<curK;i++){
ans*=Sushu[flag];
}
}
cout<<ans<<endl;
}
}方法二
关于unordered_map:
- unordered_map是一个将key和value关联起来的容器,它可以高效的根据单个key值查找对应的value。
- key值应该是唯一的,key和value的数据类型可以不相同。
- unordered_map存储元素时是没有顺序的,只是根据key的哈希值,将元素存在指定位置,所以根据key查找单个value时非常高效,平均可以在常数时间内完成。
- unordered_map查询单个key的时候效率比map高,但是要查询某一范围内的key值时比map效率低。
- 可以使用[]操作符来访问key值对应的value值。
思路
1、定义一个哈希表用来存储,key表示素因子,value表示该素因子的个数。
2、循环,从j=2开始依次向后判断,可以被n除尽则就是n的一个素因子,n也相应缩小j倍。maps用来记录。在此说明,除完2开始除3,然后是4,4一定不能被整除,因为如果能被4整除则一定会被2整除,后面的也是这样。
3、再说一下循环结束条件一定是n,n的大小一直在成倍的缩小,而除数的值永远都不能大于n,因此循环判断条件为j<=n。
4、最后根据阈值跳过那些不符合要求的素因子进行相乘。
关注这种思路中筛出素因子方法。
map.first是key值,map.second是value值
运行时在编译环境中加入以下内容,更改为c++11版本
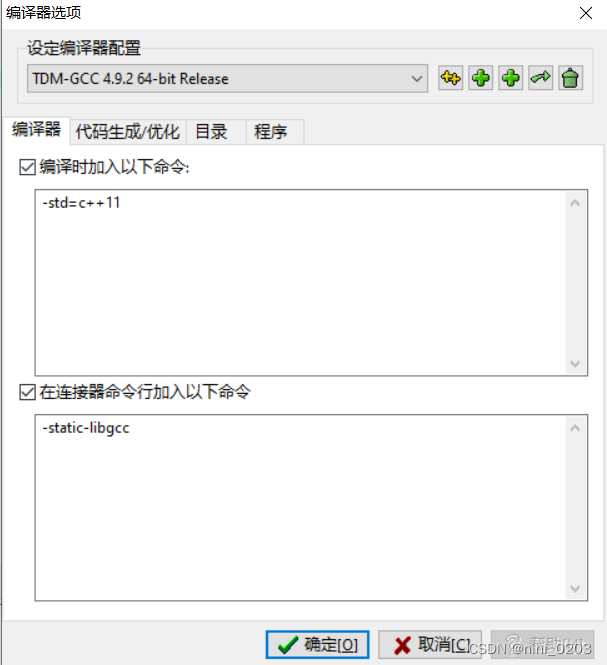
#include<bits/stdc++.h>
using namespace std;
int main() {
int q;
cin >> q;
for (int i = 0; i < q; ++i)
{
long long n, res = 1;
int k;
cin >> n >> k;
unordered_map<int, int>maps;
for (int j = 2; j <= n; ++j)
{
while (n % j == 0)
{
++maps[j];//j对应的指数加一
n /= j;//n缩小 j倍
}
}
for (auto s : maps)
{
if (s.second < k)
continue;
res *= pow(s.first, s.second);
}
cout << res << endl;
}
}结果

















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









