






一.简介
性能测试的种类
1.基准测试:狭义上是单个用户测试,广义上是多个用户测试。
2.负载测试:测试在满足性能指标下可以承受的最大极限,例如:在响应时间为2秒内最大极限。
3.压力测试:测试在极限状态是是否会发生同步问题,内存泄漏等。
4.并发测试:多个用户同时测试同一个应用,同一个模块,并发测试一般没有标准,只是测试并发时会不会出现意外情况,例如可能出现写入错误,访问错误等。
5.配置测试:调整软件系统的软硬件环境,测试各种环境对系统性能的影响,例如什么样的cpu。
6.稳定性测试:在强负载下持续运营,例如哔哩哔哩需要一年356天持续运营。
7.容量测试:在一定的条件下测试最大的用户数量,储存数量。
性能测试的指标
1.响应时间, 2.吞吐量, 3.并发用户数量, 4.QPS(系统每秒响应查询的数量)和TPS(系统每秒能处理的事务数量), 5.点击率, 6.错误率, 7.资源利用率。
二.JMeter的使用
添加测试计划
虽然每次进入都有一个新的测试计划,但是可以通过左上角来进行新建
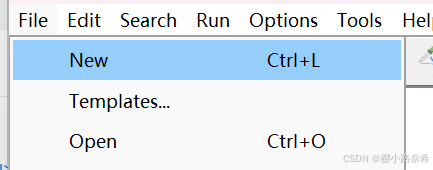
添加线程
只需要右键测试计划,便可以按照内种寻找到
线程中下面三个按顺序分别代表执行的用户数量,执行当前用户在多少时间内完成,循环次数。

一但选择,便可以设定循环时间,时间结束才会停止,同时也可以选择延迟的时间(例如为了让用户并发,可以给一个十秒的延迟,等到所有用户准备好便可以同时进行)

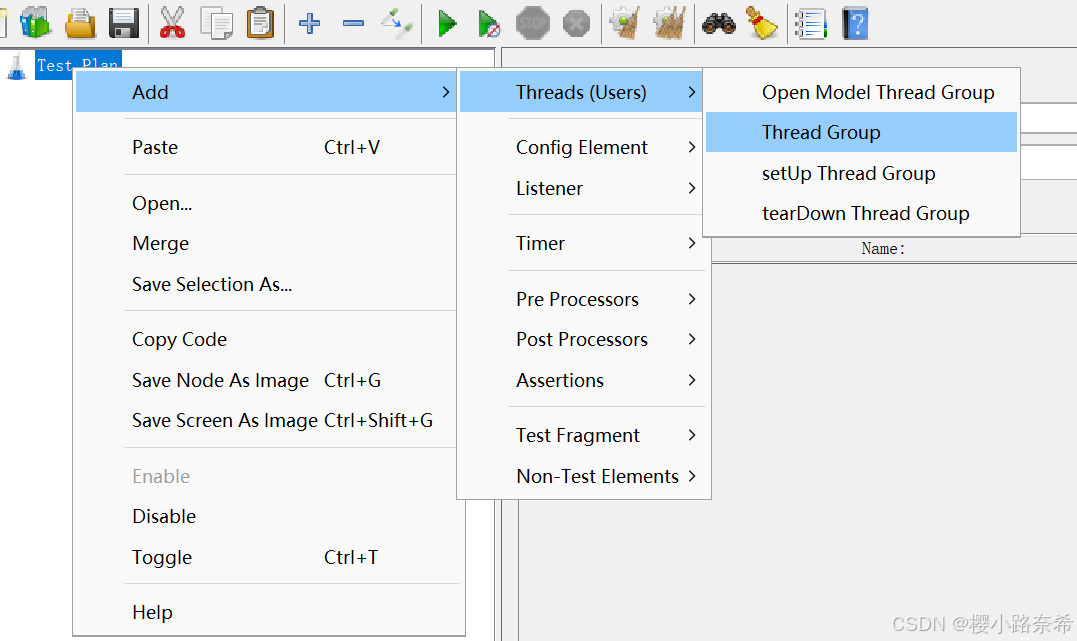
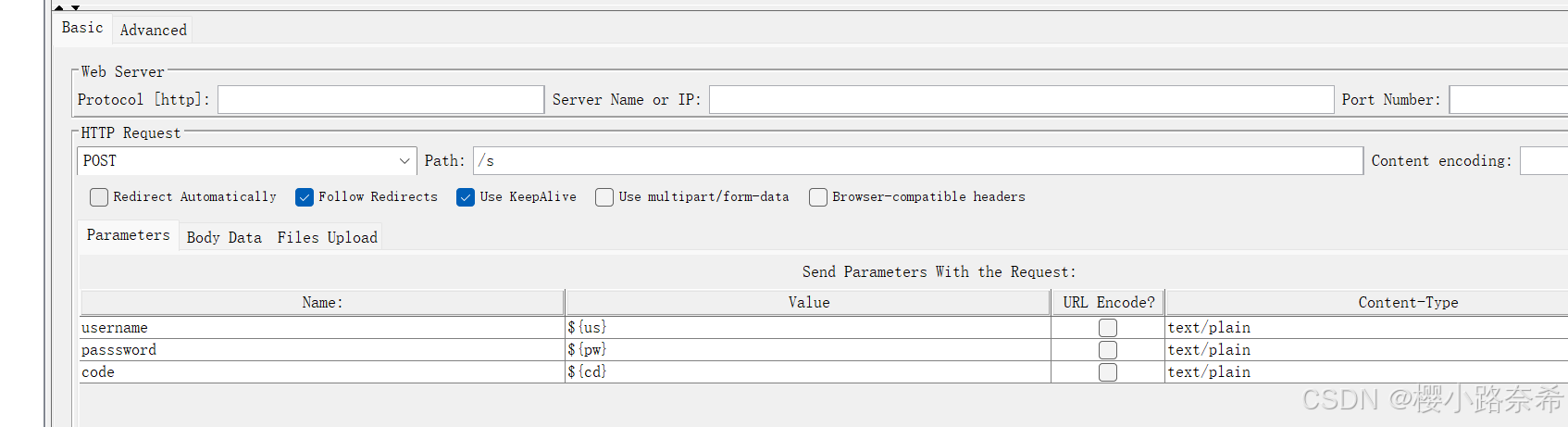
添加HTTP请求
只需要右键线程便可以添加

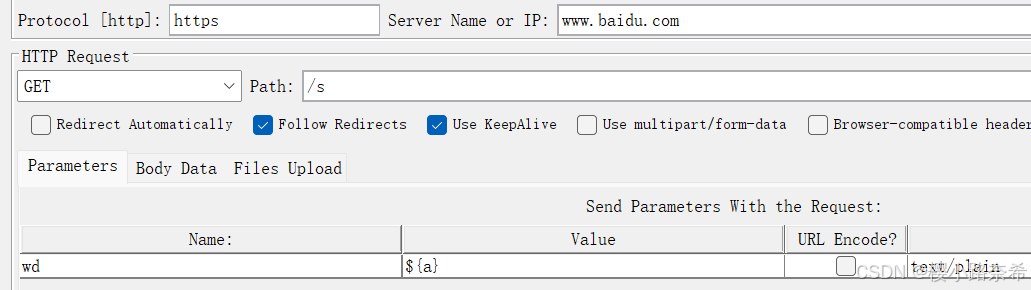
上方内容有:请求的页面需要添加协议(默认http),URL(网址,只需要写出www.到第一个斜线之前),端口号(默认与协议相同),方法(例如请求get),地址(第一个斜线后的内容,要带上第一个斜线,内容代表着存放数据的服务器地址),内容编码(默认UTF-8)

下方内容有:参数体,数据体,上传文件,至于作用需要时在解释。

添加察看结果树
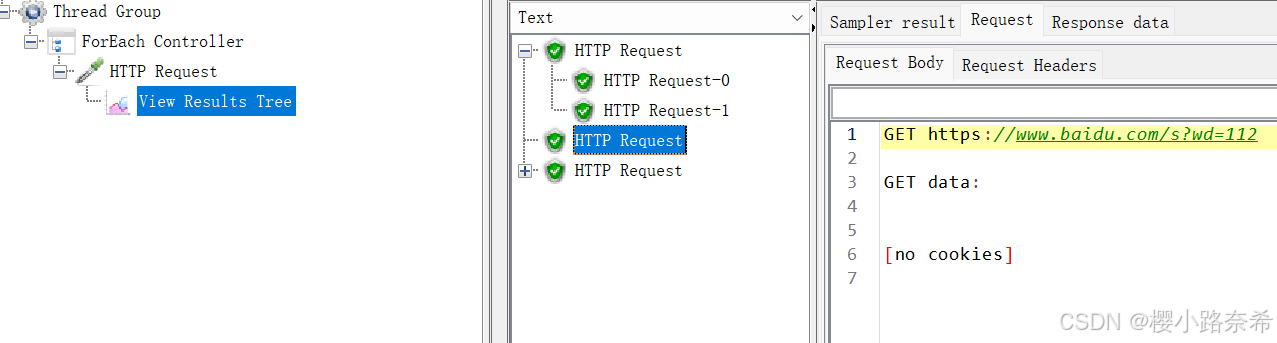
同样只需要右键便可以找到,注意的是在不同的位置结果树覆盖的结果不同,若在http请求中加入,只会查看该请求的结果,若在线程下添加,则查看该线程下所有的请求。
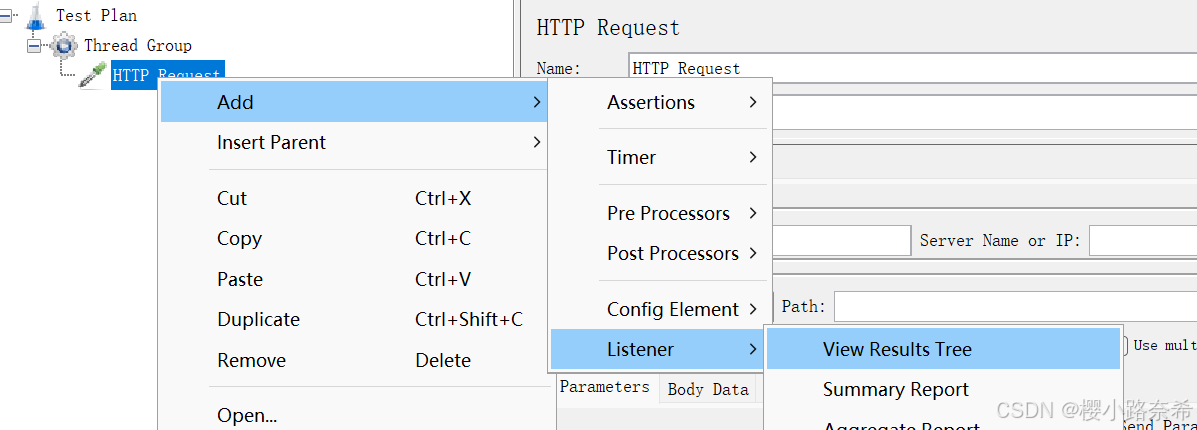
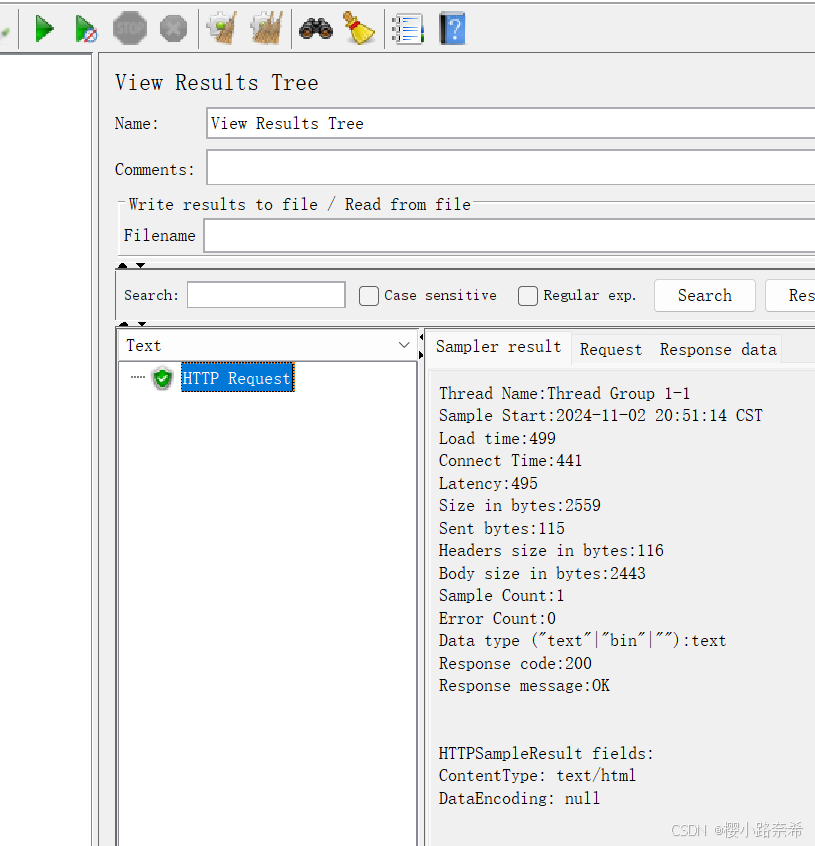
只要通过绿色箭头访问百度网址便可以得出下面的结果,代表成功执行,而右边有有着各种信息。
三.JMeter的核心组件
取样器
要用JMeter发送一个请求,有着两种方法,其他方法同样适用,第一个代表地址,第二个代表地址后参数,用第二种方法时记得将路径加上。

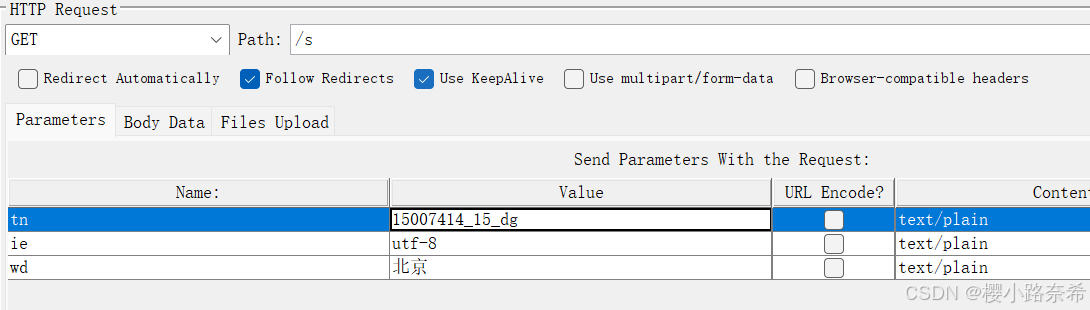
监听器
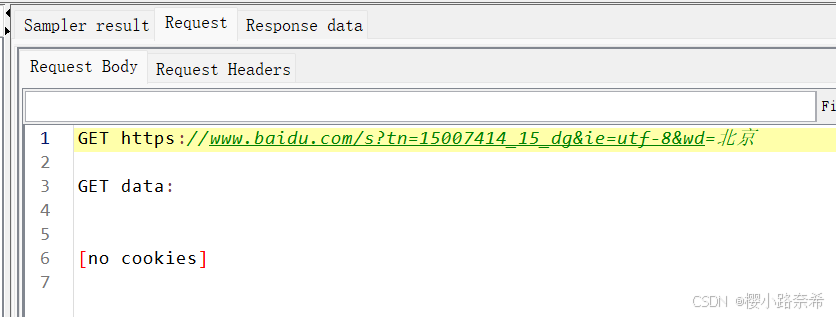
结果树左边代表着三个不同的信采样结果(有着各种信息,例如运行的日期,响应的时间),请求,响应数据
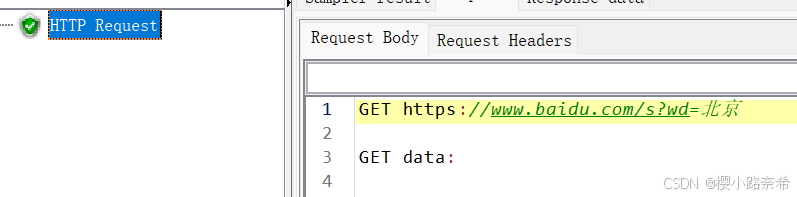
对于请求来说分为两个部分:请求体,请求头。
在请求体中有着请求的URL以及得到的数据,因为没有设置任何的请求头,所以data中并没有内容。
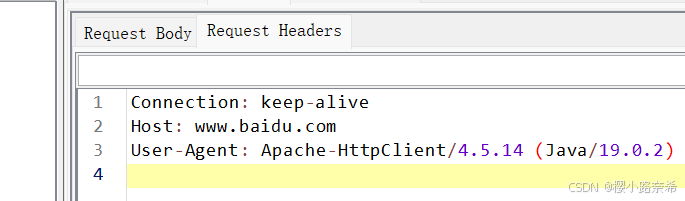
在请求头中则有着链接方法,主机,用户代理。
聚合报告
只需要按照图中顺序便可以创建。
这是运行后的聚合报告,分别有着:
1.标签(请求的类型) 2.样本(发送到服务器的请求数量) 3.平均响应时间
4.响应时间的中位数 5.90%小于该响应时间 6.95%小于该响应时间
7.99%小于该响应时间 8.最小响应时间 9.最大响应时间 10.错误率
11.吞吐量(每秒处理的请求) 12.接受kb/sec(服务器每秒接收的数据量)
13.发送kb/sec(服务器每秒发送的数据量)

配置元件
1.定义变量
创建方法
只需要在其中添加便可以,前面代表名字,中间代表数值,最后则是注释

使用变量方法,只需要在${}中加入变量名字便可以使用。

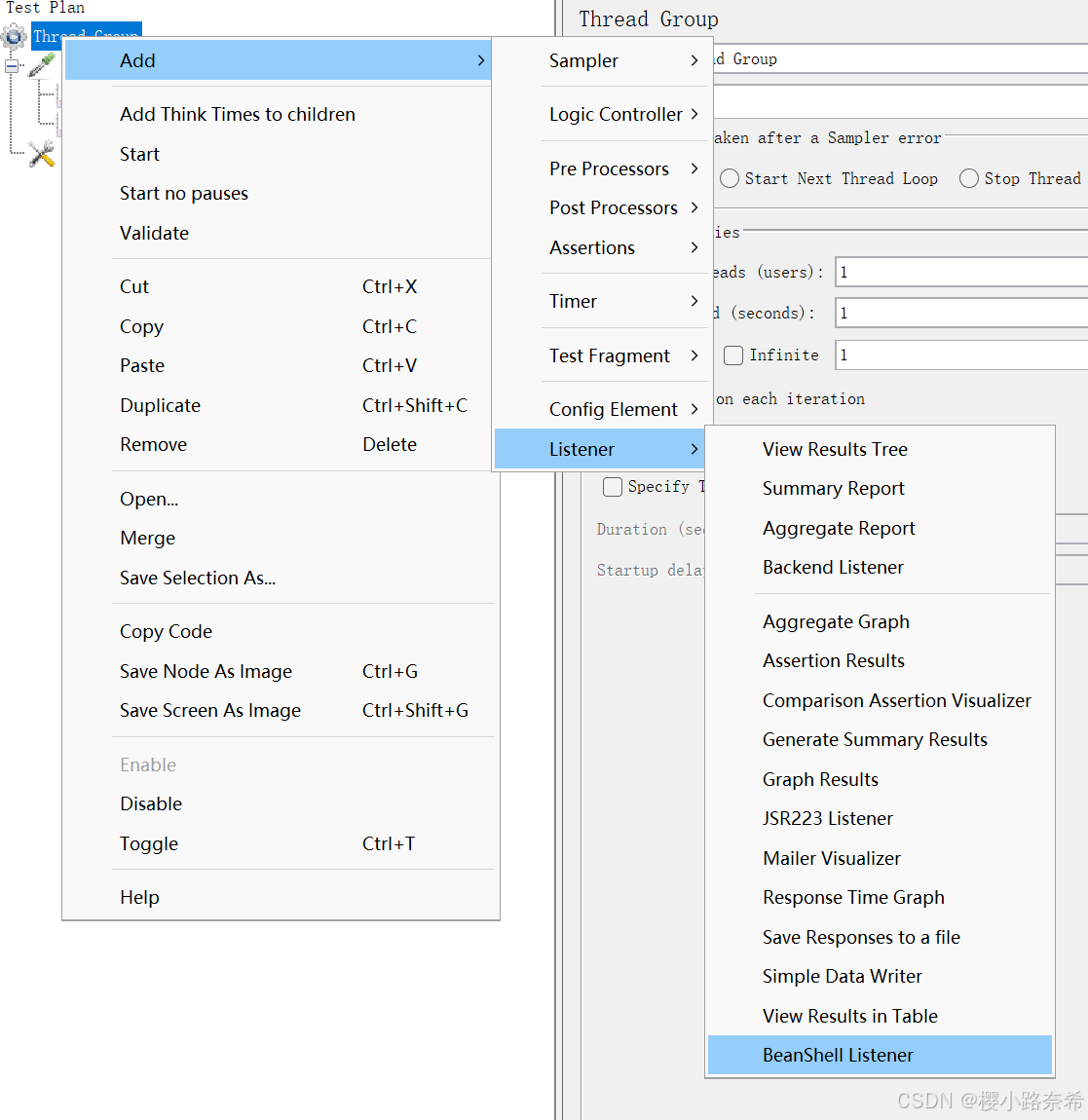
2.信息头
信息头的创建,制造在其影响的范围内,都有着该信息头。
查看结果树
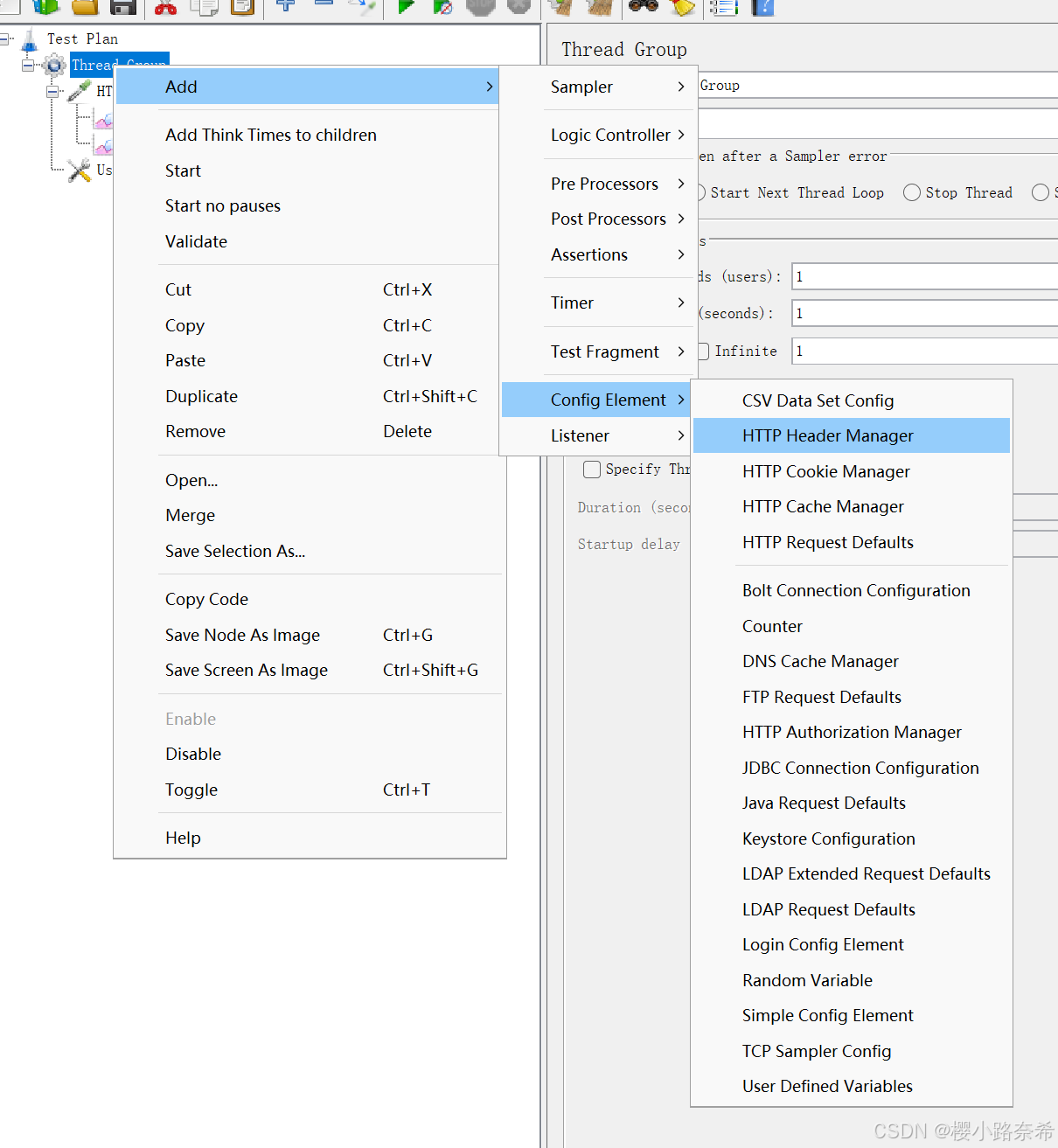
3.HTTP请求默认值
只需要在其中创建便可以,同样前面名称,后面数值。

http请求可以这样创建,创建后在其影响的范围内不特意写明则默认变为所设置的内容。
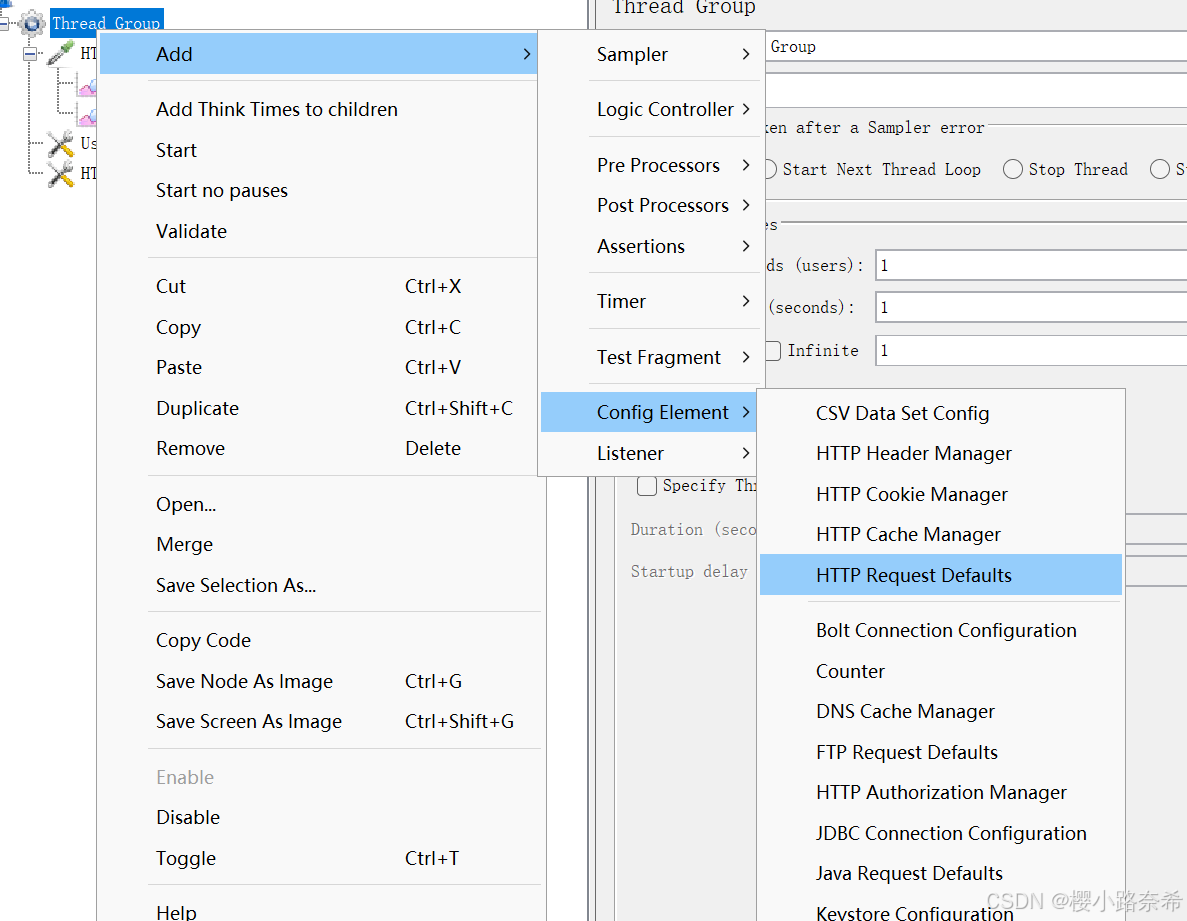
例如原本默认的http,会变成https。
而URL则默认www.baidu.com

4.csv文件数据设置
创建
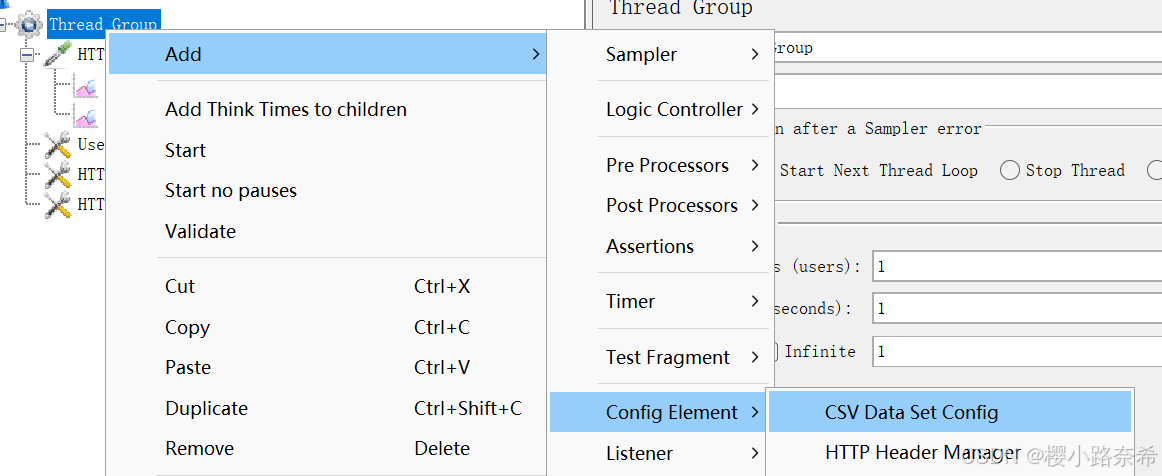
使用介绍
第一代表文件所在位置
第二个代表文件编码
第三个代表自定义的变量名称
第四个看是否需要忽略首行(因为csv文件中第一行可能是给数据的解释所以需要忽略)
第五个是变量分隔的方法
后面则是分别代表:是否允许带引号?遇到文件结束符再次循环?遇到文件结束符停止线程?
线程共享模式(通常作用全局)
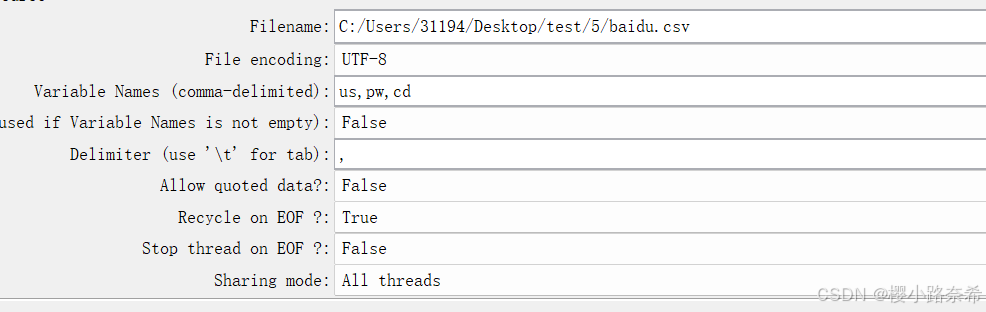
csv文件格式内容如下

使用方法如下,需要注意的是,因为csv文件中有三个,但是之前在线程中设置的请求数量一直是一个,因此需要将线程中的请求数量最少改成三个,若三个以上,则会重复执行。

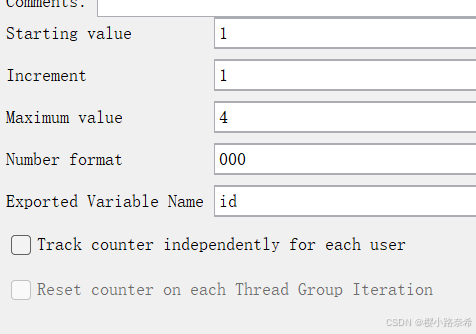
5.计数器
创建
代表意义分别为:开始的数字,每次递增多少,最大值(若超过则会从最开始的数字进行循环),数字格式(例如001,002),引用名称。
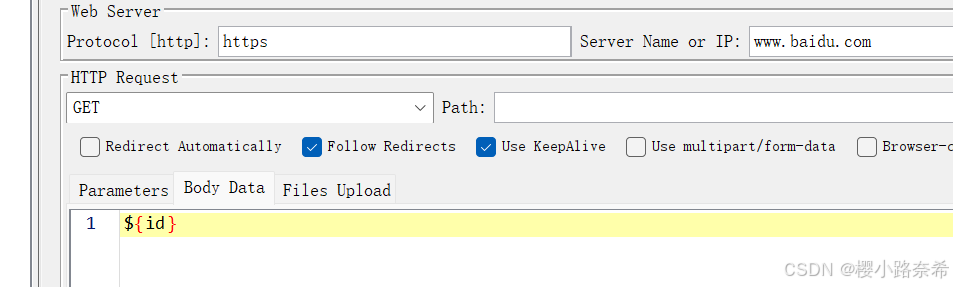
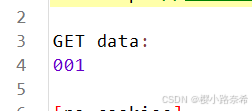
使用方法与结果
断言
1.响应断言
创建
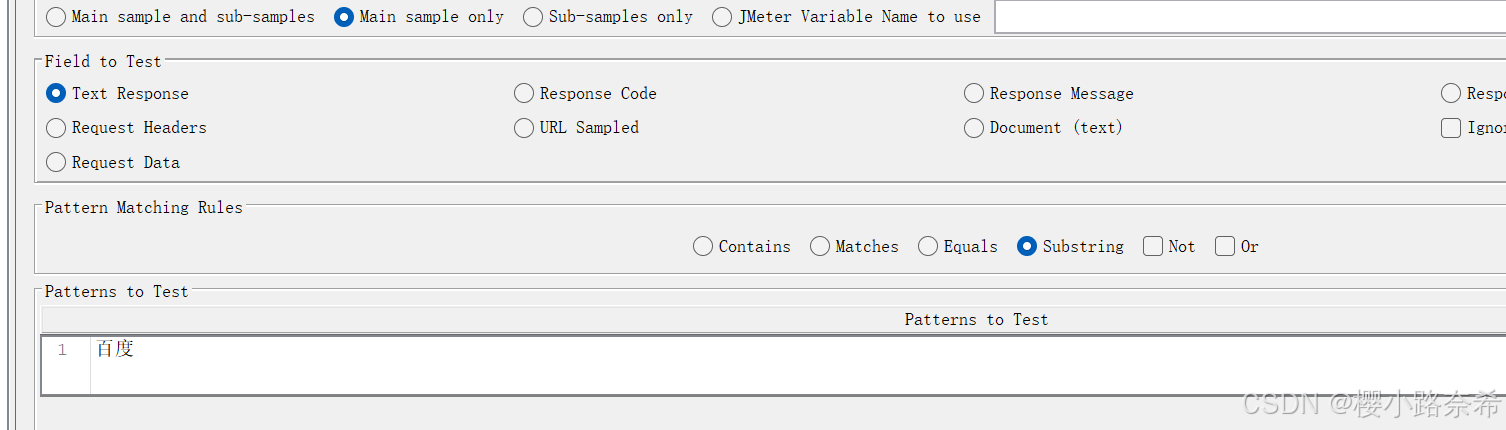
测试字段中有着各种的主要断言的项,匹配规则中包括各种条件,比如等于,取反。
需要注意的是如果成功不会显示任何信息,只有错误时才会提示。
2JSON断言
创建
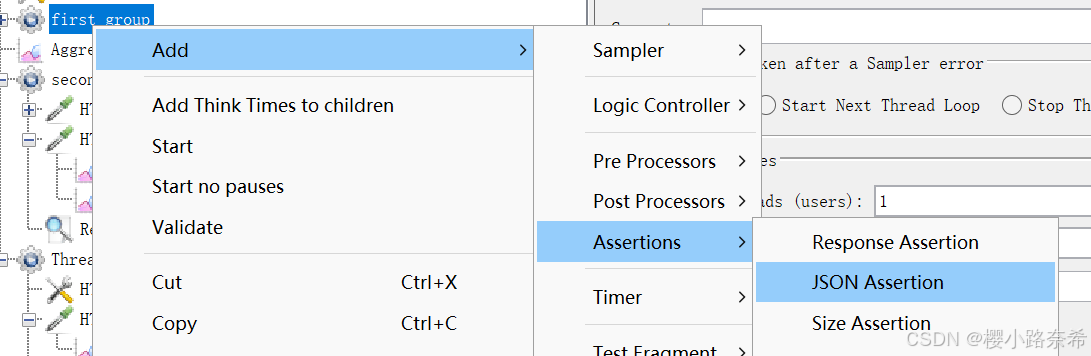
第一个位置是在特定的位置下查找关键词,在$(可以理解为将全部信息收集).weatherinfo.city的下面寻找北京。
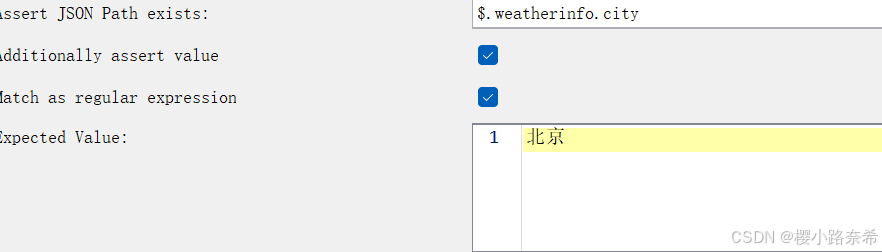
通过这张图便可以发现北京的具体位置。

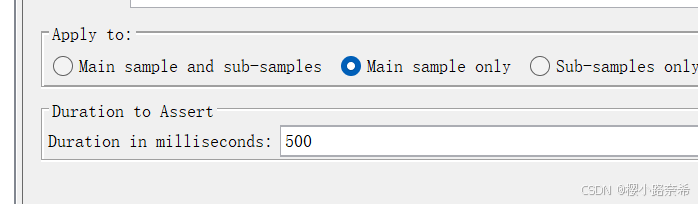
3.断言持续时间
创建
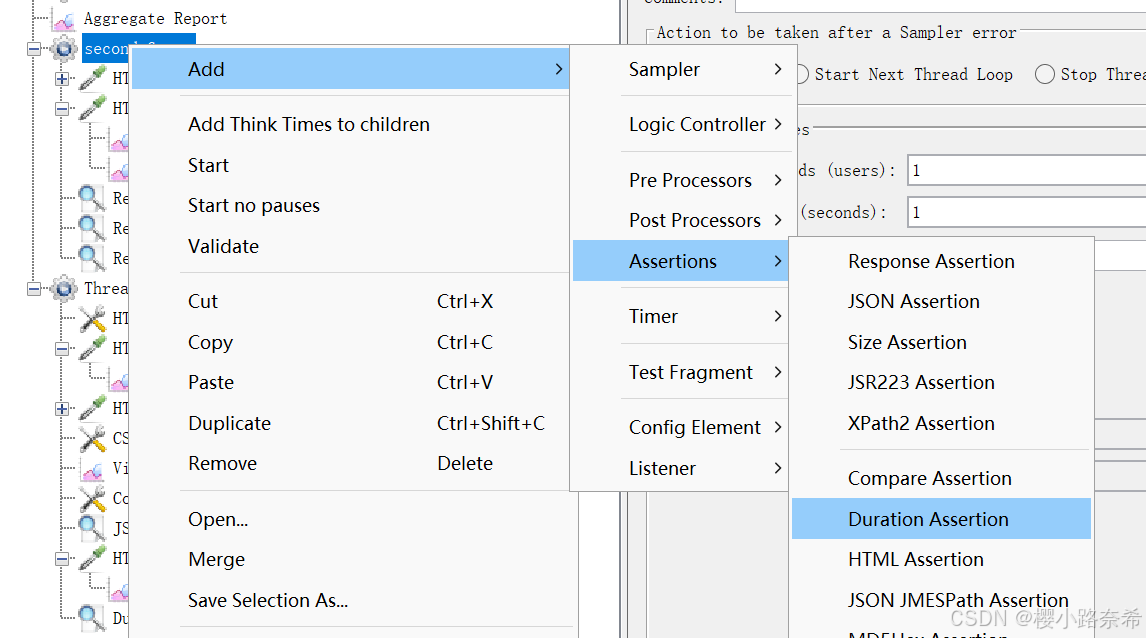
主要断言响应的时间有没有超过这个时间,若为600ms则会报错
前置处理器
用户参数
创建方法
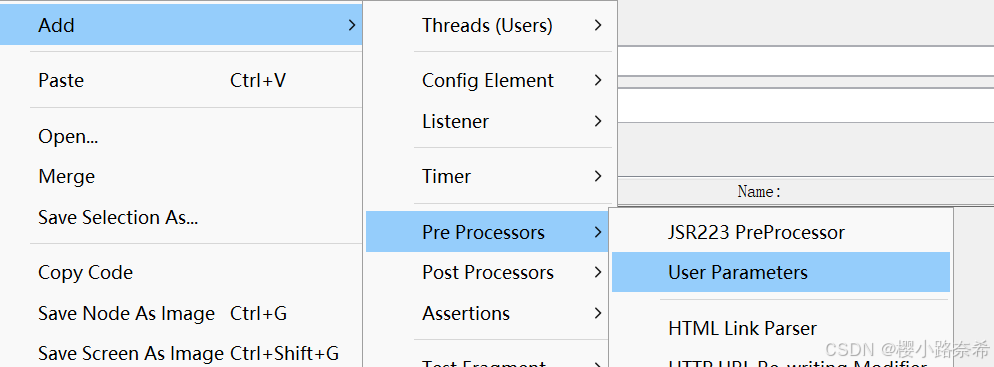
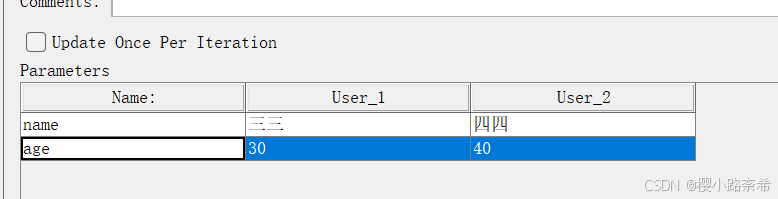
创建两个用户,各两个参数
引用参数
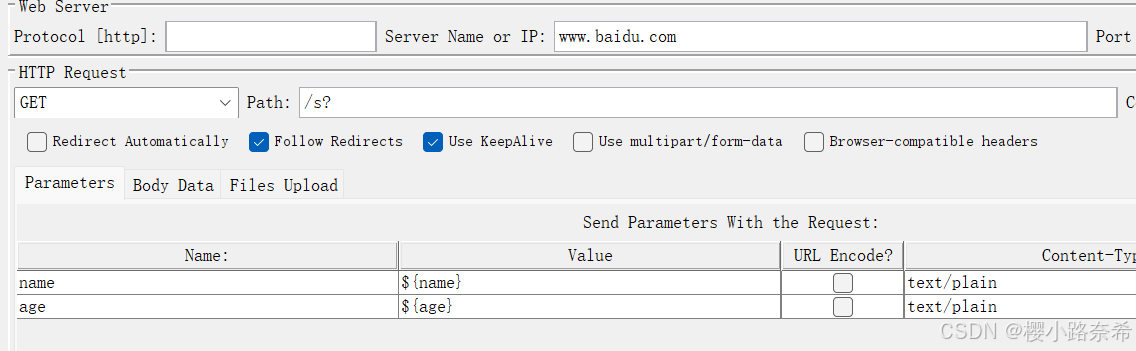
若运行大于用户的次数,则会从头引用。
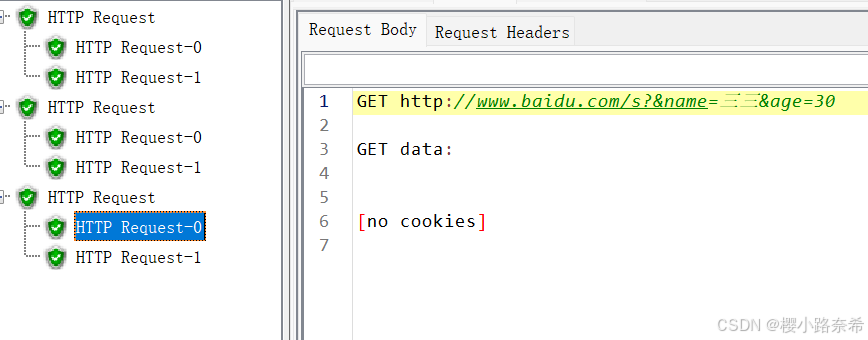
后置处理器
1.正则表达式
2.XPath提取器

如果是HTML格式则需要勾选,如果是XML或XHTML则不需要勾选

以下内容分别为自定义名称,所储存的路径,第n个数据(0为随机,负数为全部),以及若找不到输出的数值
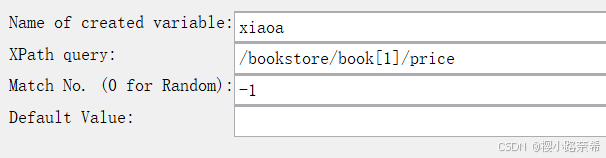
引用方法(先由所输出的数据找到在写出XPath提取器)
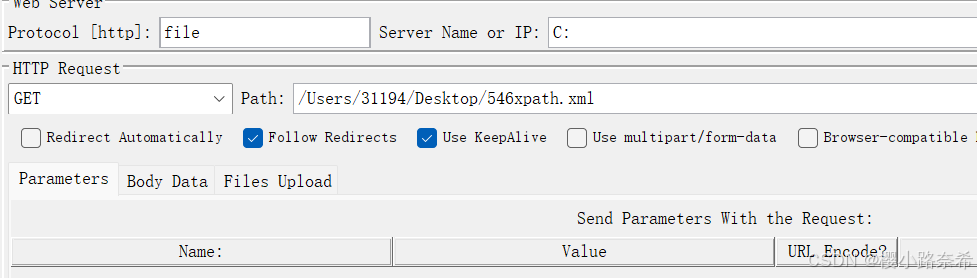

输出结果
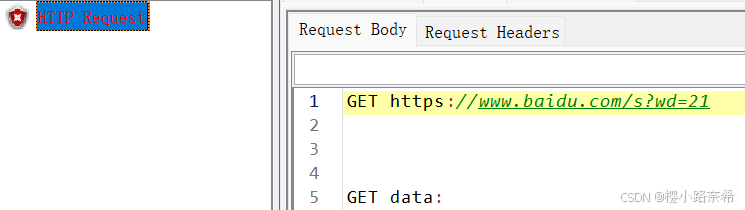
成功输出,但是有着问题,若输入的为/bookstore/book[1]会发现无法输出。
这个原因在于无法提取特殊字符,只能提取例如 <price>下的内容

JSON提取器
创建方法如下
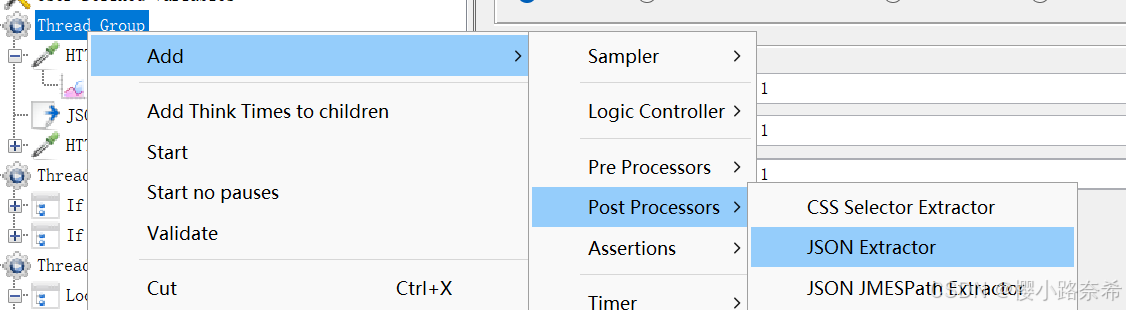
例如提取http://www.weather.com.cn/data/sk/101010100.html中的北京

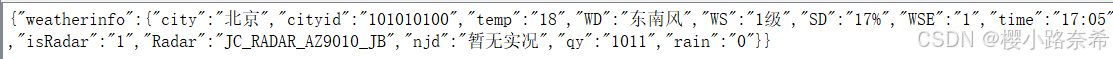
$代表引用全部,后面则表示具体路径,数字代表的含义与之前相同

引用与结果
逻辑控制器
1.如果(if)控制器
添加
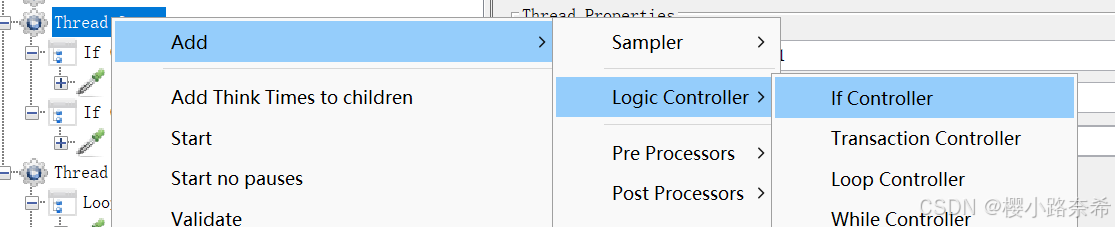
普通if格式

输入使用__jexl3()或者 groovy()函数生成的函数表达式,需要将下方勾选上。
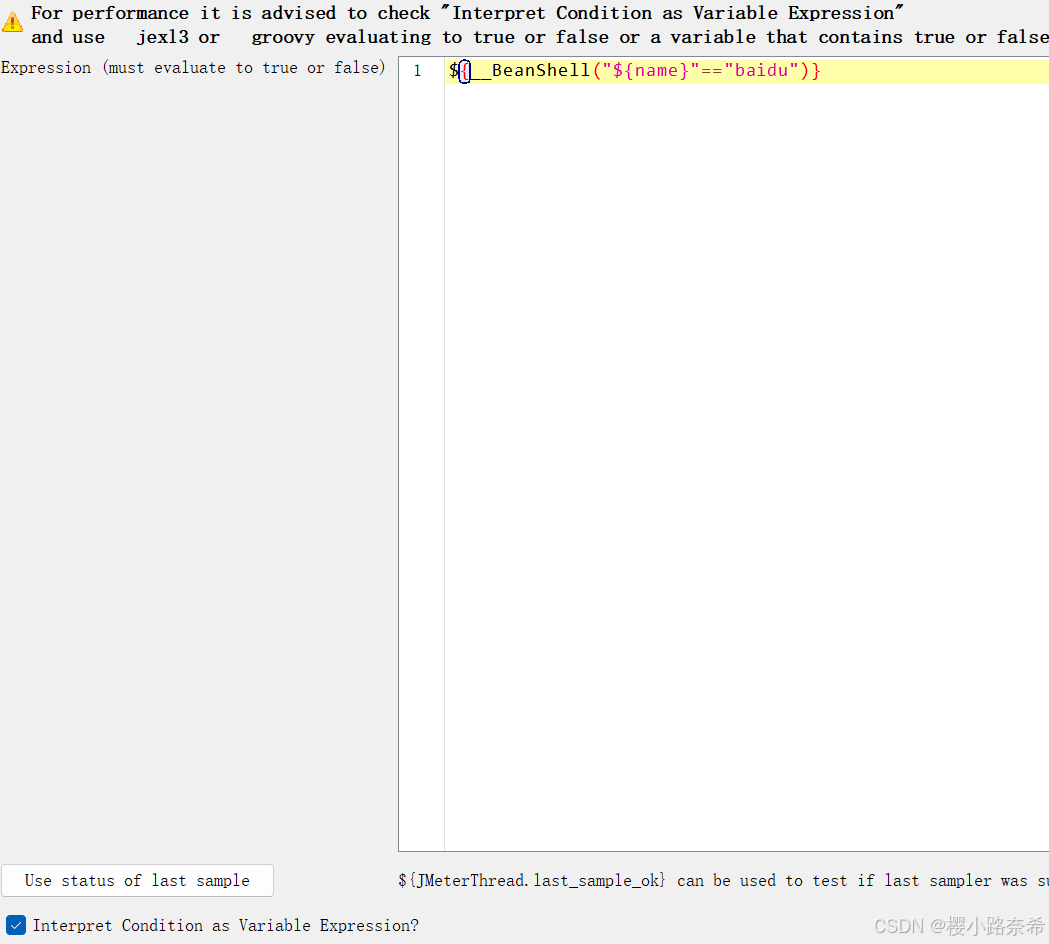
在这种格式下,需要将原本普通的转化为这种格式,方法如下。
![]()
只需要点击生成就可以了,最下方左边的便是所需要的格式。
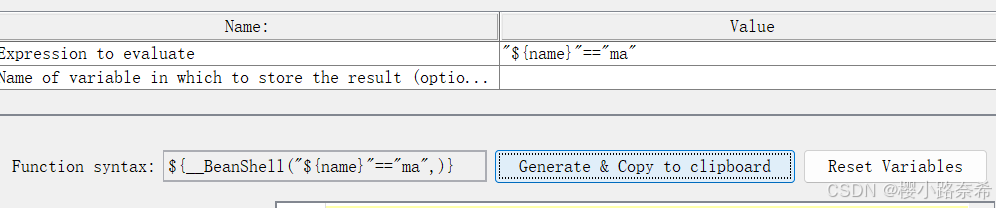
在正式使用之前还要用户自定义变量
定义的如下(如果有两个相同的Name,则只会运行最前面的)

if所放置的位置
上方是判断baidu,符合预期
2.循环控制器
添加方法
线程循环两次
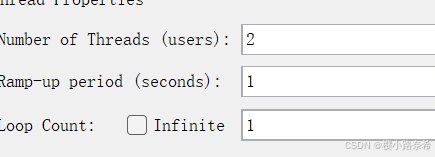
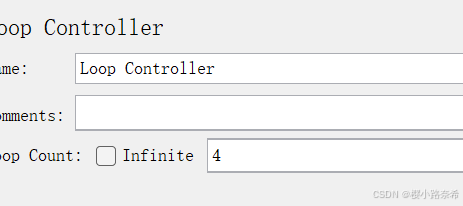
循环器中循环4次(如果勾选Infinite则便是一直循环)
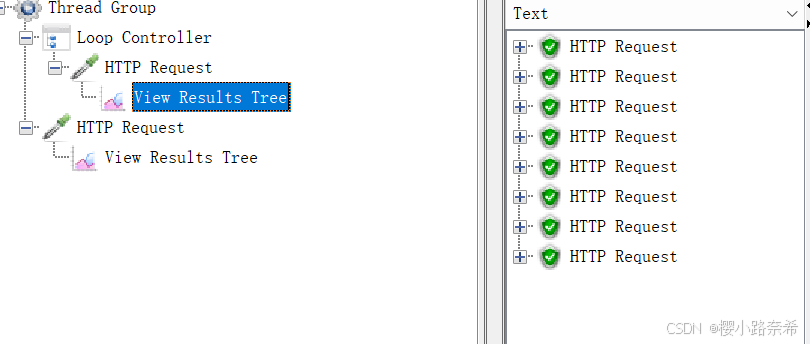
可以发现循环了8次(2*4),
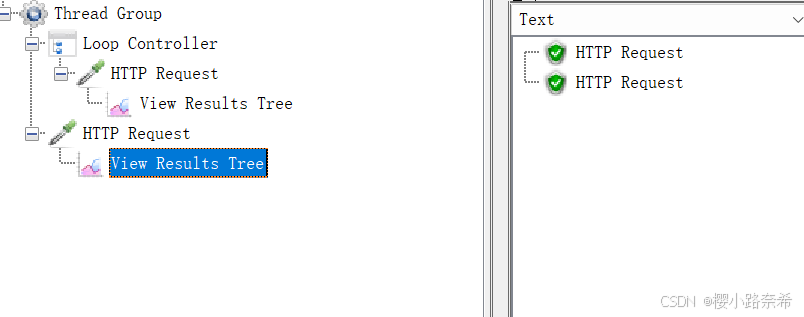
普通的只循环了线程的两次
3.ForEach控制器
添加
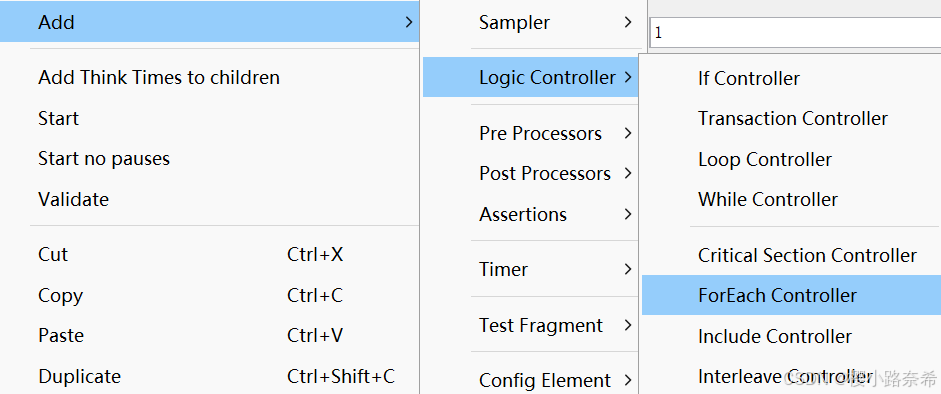
在进行之前需要将用户输入的变量更改成后面携带数字的状况
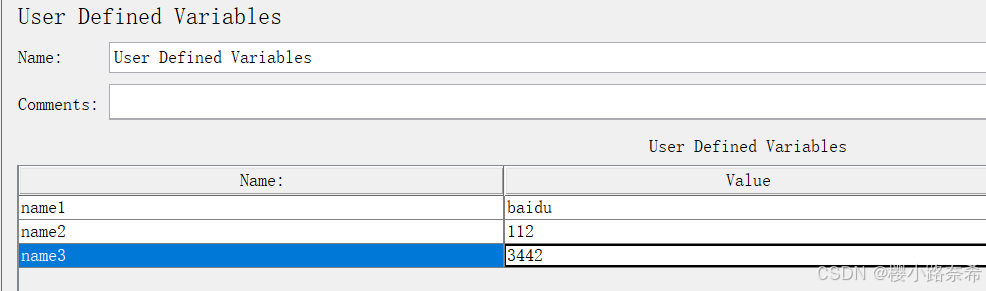
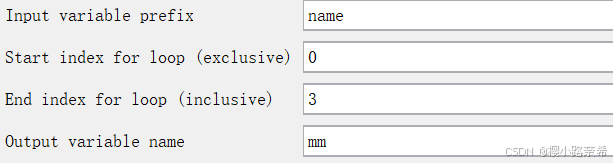
name表示引用的变量,0表示从name1开始,3表示到name3,如果没有name3,则不输出。
mm表示引用时的名称
引用方式
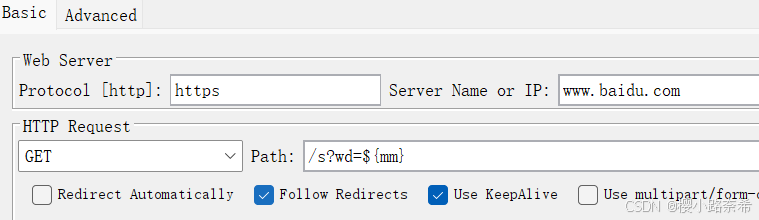
需要注意的是线程只需要运行一次便可以
运行结果
还需要注意的是如果有两个name的变量会引用上方的name变量名称。
定时器
1.同步定时器
添加,注意要放在请求的下面,否则会同并列的请求都会执行相对应的。

线程的设置
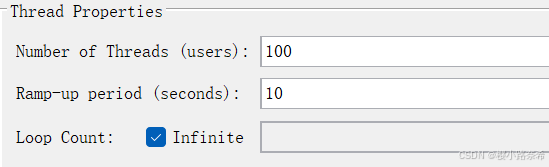
同步定时器的设值,代表20个模拟用户,或者10毫秒只要达到其中一个条件就会进行下一步,与线程中的Specify Thread lifetime有着相似的用处

2.常数吞吐量定时器
添加
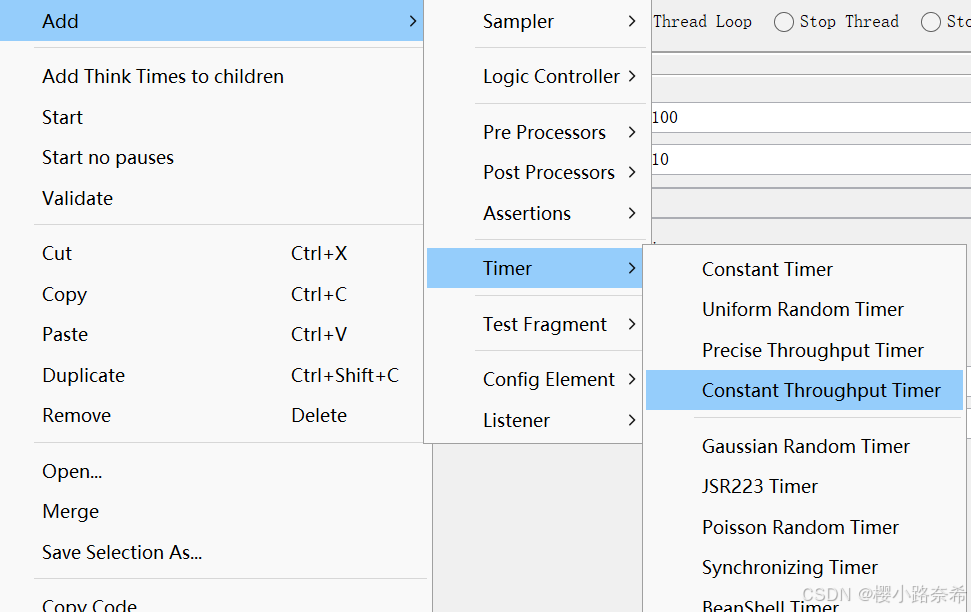
每分钟总攻的吞吐量,如果有一个用户那么该用户便可以每分钟吞吐1200,如果有两个用户,那么每个用户每分钟只能600

运行结果

3.固定定时器
添加
使用JMeter模拟登录iHRM人力资源管理系统,具体登录情况如下。
请求地址:http://ihrm2-test.itheima.net/api/sys/login
请求方式:POST。
请求头:Content-Type:application/json;charset=UTF-8。
请求体:{"mobile":"13800000002","password":"888itcast.CN764%..."}
模拟用户当三次账号密码输入错误后,停止6秒在刺输入
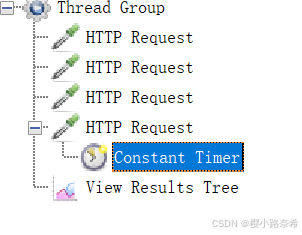
发现输出三次后停止6秒后才进行再次输入


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









