






题目要求:
在给定的资源中一共有50个文件夹,每个文件夹含有5张人脸照片。
要求:使用程序编写(语言不限)解决,检测上述这些人脸照片识别出这批照片共有男性多少人、女性多少人,共有多少人戴眼镜以及识别该照片人的年龄大小。
其中男性、女性的检测以某个文件夹出现次数最多的为主,例如一个文件夹若出现检测男性为3次,女性为2次,则该照片应判断为男性;戴眼镜则以佩戴一次为标准,即有一张照片佩戴则该人为戴眼镜;年龄则以5张照片求取算数平均数为最终结果。
最后程序运行的结果要在控制台输出如下语句:
(1)本次检测共有{}人,其中男性{}人,女性{}人,佩戴眼镜人数为{}人。
(2)请以Excel或文本形式输出如下表格,要求该表格以年龄的升序排列输出下列信息:
例:
序号 名称 性别 是否戴眼镜 年龄
1 000 男 是 35
2 001 男 否 37
提交要求:
- 提交以Word格式的报告,报告包括关键代码,即显示下列评分标准的代码,需在代码中给出完成了评分标准X,并给出对应的截图
提示:题目描述完了,这道题的完成需要用到百度云里的,人体分析中的人体检测和属性识别。
当然阿里云和其他的也可以呦。
期待你能跟菜鸟 ,一起完成实现对于文件中的多个照片进行识别吧。
要学会实现读文档的能力。
首先,根据百度云要求:
根据代码获取AK和SK,所以AK,SK的本质是什么东西勒?
这里,就为大家好好说一说吧。(~0^0~)
通过API Key(AK)和Secret Key(SK)获取的access_token
通过API Key和Secret Key获取的access_token是一个用于验证身份的凭据,通常用于保护API接口的安全。
具体来说,当一个应用程序需要访问一个API接口时,它需要向API提供一些身份验证信息,以确保它有权访问该接口。这个身份验证信息通常包括API Key和Secret Key。API Key是应用程序的唯一标识符,而Secret Key是与API Key相关联的密钥,用于验证应用程序的身份。
当应用程序提供正确的API Key和Secret Key后,API会返回一个access_token作为响应。这个access_token是一个随机生成的字符串,它表示应用程序的授权状态。一旦应用程序获得了access_token,它就可以在随后的请求中使用该token来证明自己的身份并访问API接口。
需要注意的是,access_token是有时效性的,通常只有几分钟到几小时的有效期。一旦access_token过期,应用程序需要重新获取新的token。为了保护API接口的安全,开发者需要妥善保存和管理access_token,并确保在每个请求中都使用最新的有效token。
先按照步骤,创建应用,得到AK,SK,要登录哦~
是新人的话可以免费尝鲜,每个月都可以申请一次免费尝鲜。
创建应用,根据需要勾选相应的功能哦~


将上述获得的AK,SK直接带入相应的Access token 代码,运行可获得。
API文档中有获取Access token的代码,因此我们将代码试着运行一下。
代码如下:
api_key=你所获得的
secret_key=你所获得的
token_url = 'https://aip.baidubce.com/oauth/2.0/token'#注意这里用了2.0版的
def get_access_token():
url = f"{token_url}?grant_type=client_credentials&client_id={api_key}&client_secret={secret_key}"
payload=""
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
json_response = json.loads(response.text)
access_token = json_response.get('access_token')
#print("Access Token=", access_token)
return access_token
 第一步完成喽!P(O^O)P
第一步完成喽!P(O^O)P
很好大家都很激动吧》》》》》哇咔咔咔咔咔,哈哈哈哈哈哈
范进中举不过如此,嘿嘿
实现对于照片转64编码,调用函数实现对于一张照片的识别
选出type中的gender,age,glasses等你所需要的属性参数值选择输出哦。因为,在不选择输出的情况下,会默认全部输出。
以下为文档中的,相关属性。

对要求输出的type属性值,将type参数设定为属性的可选值,并用逗号分隔。
payload = 'type=%2Cage%2Cgender%2Cglasses'
提示:在python中如果在写路径的时候,要用双斜杠,因为但斜杠会被认为是转义符,或者你可以用但斜杠,但是前面要上字母“r”
代码示例:
parent_folder_path = r"C:\Users\Lenovo\Desktop\face"
parent_folder_path = "C:\\Users\\Lenovo\\Desktop\\face"统计文件中所有图片的个数,判断文件是否为图片:
import os
import imghdr
def count_images(directory):
count = 0
for root, dirs, files in os.walk(directory):
for file in files:
if imghdr.what(os.path.join(root, file)): # 如果文件是图片
count += 1
return count
# 用法示例:
directory = 'C:\\Users\\Lenovo\\Desktop\\face' # 替换为你的资源文件夹路径
print(f'在 {directory} 中找到 {count_images(directory)} 个图片文件')
实现对于所有照片的识别,统计,代码示例如下:

直接进入对于图片路径,实现对于图片转为64编码利用:
img = base64.b64encode(f.read())import requests
import json
import base64
import os
api_key = "QXeMLqbBjGMsfKNc9vazdGGv"
secret_key = "ulKmdTrHn51EVCVVezQEvReMQfzVPsHp"
token_url = 'https://aip.baidubce.com/oauth/2.0/token'
def get_access_token():
url = f"{token_url}?grant_type=client_credentials&client_id={api_key}&client_secret={secret_key}"
payload=""
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
json_response = json.loads(response.text)
access_token = json_response.get('access_token')
#print("Access Token=", access_token)
return access_token
person = 0
male = 0
famale = 0
glasser = 0
human = []
def face_trait(folder_path):
request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
total= 0
male_count = 0
image_count = 0
female_count = 0
glass_count = 0
ages = 0
#对于属性人的统计
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
if os.path.isfile(file_path):
if file_path.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
with open(file_path, 'rb') as f: # 使用with语句自动关闭文件
img = base64.b64encode(f.read()) # 将图片内容编码为base64格式并转换为字符串
image_count += 1
total+=1
params = {"image": img, "image_type": "BASE64",
"face_field": "age,glasses,gender"}
access_token =get_access_token()
request_url = request_url + "?access_token=" + access_token
headers = {
'content-type': 'application/json'
}
response = requests.post(request_url, data=params, headers=headers)
if response:
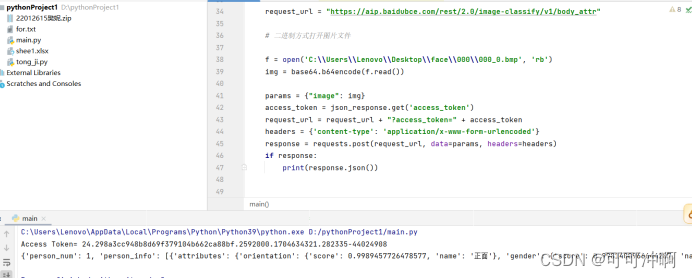
json_response = response.json()#print(json_response)
age = json_response["result"]['face_list'][0]['age']
ages+=age
gender = json_response["result"]['face_list'][0]['gender']['type']
if gender == 'female':
female_count += 1
elif gender == 'male':
male_count += 1
glasses = json_response["result"]['face_list'][0]['glasses']['type']
if glasses == 'common':
glass_count += 1
elif glasses=='none':
glass_count+=0
#print("性别:",gender,"眼镜:",glasses,"年龄:",age)
if image_count == 5: # 每处理完五张图片检查一次男性和女性的数量
person = person + 1
ages=round(ages/5)#对浮点数取整
result_dict={}####一定得创造一个空字典,这样列表才能不空
result_dict['年龄']=ages
if female_count > male_count:
result_dict['性别'] = '女'
famale=famale+1
elif female_count<male_count:
result_dict['性别']='男'
male = male + 1
if glass_count == 0:
result_dict['是否戴眼镜']='否'
elif glass_count >= 1:
result_dict['是否戴眼镜']='是'
glasser=glasser+1
human.append(result_dict.copy())
image_count = 0 # 重置计数器,为下一轮五张图片做准备
male_count = 0 # 重置计数器,为下一轮五张图片做准备
female_count = 0 # 重置计数器,为下一轮五张图片做准备
ages=0
else:
pass
if __name__ == '__main__':
parent_folder_path = r"C:\Users\Lenovo\Desktop\face" # 调用函数对文件夹中的图片进行Base64编码,并统计图片数量
face_trait(parent_folder_path)
将输出利用openpyxl将最后的结果存储在excel文件中
将获得的列表所有,相关的照片属,进行输出,将最后一次输出结果直接粘贴到新代码中,或者你可以用函数传送,因为上述循环和条件判断过多,导致总输出需要不断输出,最后一次会输出总结果。
用Human列表存储最后一次结果;
利用openpyxl进行输出。偶会后续,输出用python的openpyxl库实现对于excel文件中相关数据的操作。哦~
请以Excel或文本形式输出如下表格,要求该表格以年龄的升序排列输出下列信息:
例:
序号 名称 性别 是否戴眼镜 年龄
1 000 男 是 35
2 001 男 否 37
文件输出为

from openpyxl import load_workbook
Human=[{'年龄': 31, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 25, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 23, '性别': '女', '是否戴眼镜': '否'}, {'年龄': 23, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 27, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 23, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 25, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 22, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 23, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 22, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 23, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 23, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '女', '是否戴眼镜': '否'}, {'年龄': 23, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 27, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 26, '性别': '女', '是否戴眼镜': '否'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 23, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 29, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 23, '性别': '女', '是否戴眼镜': '否'}, {'年龄': 25, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 22, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 28, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 29, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 26, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 25, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 23, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 32, '性别': '女', '是否戴眼镜': '否'}, {'年龄': 32, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 43, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 35, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 47, '性别': '女', '是否戴眼镜': '否'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 24, '性别': '男', '是否戴眼镜': '否'}, {'年龄': 27, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 26, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 23, '性别': '女', '是否戴眼镜': '否'}, {'年龄': 23, '性别': '男', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 24, '性别': '女', '是否戴眼镜': '否'}, {'年龄': 24, '性别': '女', '是否戴眼镜': '是'}, {'年龄': 22, '性别': '男', '是否戴眼镜': '否'}]
workbook = load_workbook("D:\\pythonProject1\\work1.xlsx")
sheet = workbook.active
headers = ['名称', '性别', '是否戴眼镜', '年龄']
for col in range(len(headers)):
sheet.cell(row=1, column=col + 1, value=headers[col])
value_list = [list(d.values()) for d in Human]
sorted_list = sorted(value_list, key=lambda x: x[0])
print(sorted_list)
print(len(Human))
values = [str(i - 1).zfill(3) for i in range(1, len(Human) + 1)]
for row in range(2, len(Human) + 1):
sheet.cell(row=row, column=1, value=values[row - 2])
male = 0
famale = 0
total = 0
glasser = 0
for i in range(len(sorted_list)):
if sorted_list[i][1] == '男':
male += 1
elif sorted_list[i][1] == '女':
famale += 1
if sorted_list[i][2] == '是':
glasser += 1
print("总共有", len(sorted_list), "人,", "男性有:", male,"人,", "女性有:", famale,"人,", "戴眼镜的人:", glasser)
for i in range(2, len(sorted_list) + 1):
sheet.cell(row=i, column=2, value=sorted_list[i - 1][1])
sheet.cell(row=i, column=3, value=sorted_list[i - 1][2])
sheet.cell(row=i, column=4, value=sorted_list[i - 1][0])
workbook.save("D:\\pythonProject1\\work1.xlsx")源码如上
菜鸟还是菜!!!! \(*…^…*)/
请各位大佬留下,您宝贵的意见和相关的代码改进方法哦~
美图献上:
\(QAQ)/ \(QAQ)/ \(QAQ)/ \(QAQ)/ \(QAQ)/ \(QAQ)/ \(QAQ)/ \(QAQ)/ \(QAQ)/ \(QAQ)/

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









