






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
本次文章本应该介绍分类的几种机器学习方法,不过我认为评价的标准是比方法本身更重要的,所以本次文章介绍一些分类问题的评价指标。
提示:以下是本篇文章正文内容,下面案例可供参考
一、分类评估有哪些评价指标?
最简单的评价指标就是总共测试了多少个样本,预测正确了多少个样本,这也是我们常用到的评价指标,英文名accury,不过有没有思考过一个问题,这种评价方法并不是很好用,如果你现在想用机器学习去判断这一百个病人有谁是真正患病了的,如果本身有3个人患病,预测了有2个人患病,那么accury就是百分之九十九吧,这个accury很高吧,但是他是一个很好的学习机器吗,显然不是,这一个预测错误的病人因此而没有及时治疗而丧命,对于这种问题,单一的accury并不能解决问题,便会有混淆矩阵的诞生。
1.混淆矩阵
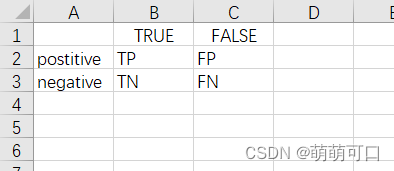
正例,反例:对于你想预测的目标,比如预测患病的人,那么患病就是正例,不患病就是反例
TP:成功预测正例为真
TN:成功预测反例子为假
FP:错误预测反例为真
FN:错误预测正例为假
precision:即查准率 =TP(TP+TN)
recall:即查全率=TP(TP+FP)
F1=2precisionrecall(precision+recall)
有了这些评价指标才能更好的帮助我们对分类问题有一个好的认识。
二、不平衡分类问题
在日常的分类任务大多属于不平衡的分类问题,什么是不平衡的分类问题,简单来说就是正例和反例数量差别太大,比如患病问题,患病的人是比较少的,这就是不平衡分类问题。如何解决这种问题呢
1.改变数据集
数据集不平衡那就多收集一点数据,这是最容易想到的办法,但实际中并没有那么理想,发现数据少了还能再收集,于是便会有样本重采样。
样本过采样:1随机采样,对训练样本的特征进行扰动,产生新的数据。
2线性采样,根据线性关系产生新的数据点。
样本欠采样:1对样本进行聚类保留质心
2对样本进行邻近将边界的点剔除
3对样本进行近邻只保留边界的点
混合采样
2.拟合问题
在机器学习中不单单是分类问题,都会遇到欠拟合问题和过拟合的问题。欠拟合就是没学好在训练和测试的都表现的不满意,过拟合就是在训练的时候表现的很好,但是在测试的时候表现的不好。
对于拟合问题应该如何解决。
解决过拟合问题
寻找更多的数据,减少特征数,使用更简单的机器学习方法
解决欠拟合问题
增加特征数,使用更复杂的机器学习方法
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文介绍了分类的相关指标,以及过拟合和欠拟合问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









