






Warning!!!本文仅为个人笔记,可能会有错漏,仅供参考。图片与公式均来自论文原文。
论文:《Contrastive Modality-Disentangled Learning for Multimodal Recommendation》
目录
一、简要概括
提出了对比模态解耦学习(CMDL)。
1、首先构建每种模态的语义图以生成初始表示,CMDL将每个初始表示分解为模态不变和模态独特表示。模态不变表示可以对齐跨模态数据,模态特定表示则补充了模态共享知识,提供了特定模态中的独特信息。这种解耦使得模型能更准确地捕捉用户偏好,生成更个性化的推荐。
2、提出一种基于交互信息估计的正则化方法,引入一种新的对比学习方法来有效近似MI上界,通过优化这种正则化,CMDL可以促使模态不变表示和模态特定表示分别捕获模态共享知识和模态唯一知识,并在统计上相互独立。这种对比学习机制能最大化模态间的共享信息,并确保模态特定表示不被模态共享信息干扰,从而提高推荐的准确性和多样性。
3、将从用户-项目交互中学习到的协作关系(物品内在特征和用户偏好)整合到多模态学习中,使CMDL能够捕获模态不变和模态特定表示的细粒度偏好信息,进而生成更准确和个性化的推荐。
二、为什么需要CMDL
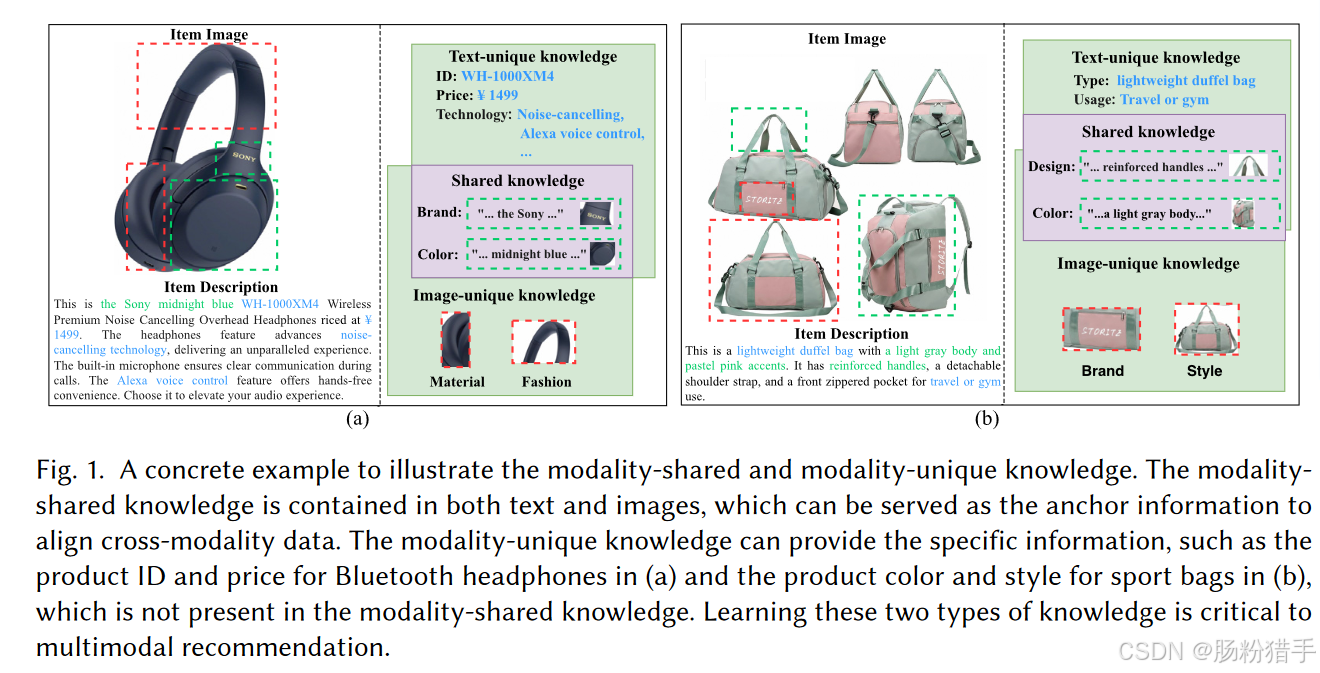
1、模态间知识学习不足。大多数方法专注于设计强大的编码器,从多模态内容中提取有用的特征,并简单地将学习到的特征聚集在一起进行预测,无法有效学习模态间的知识(包括模态共享知识和模态独特知识,下图是关于这两种知识的解释)
2、现有方法在学习多模态特征时,往往没有明确区分模态共享和模态独特信息,导致生成的特征表示中混杂了不同模态的信息。这会导致模型难以捕捉到每个模态的独特贡献,从而在推荐时无法充分利用每个模态的优势,影响准确性和多样性
三、大致方法
CMDL的框架如下图,对应1~4的内容。
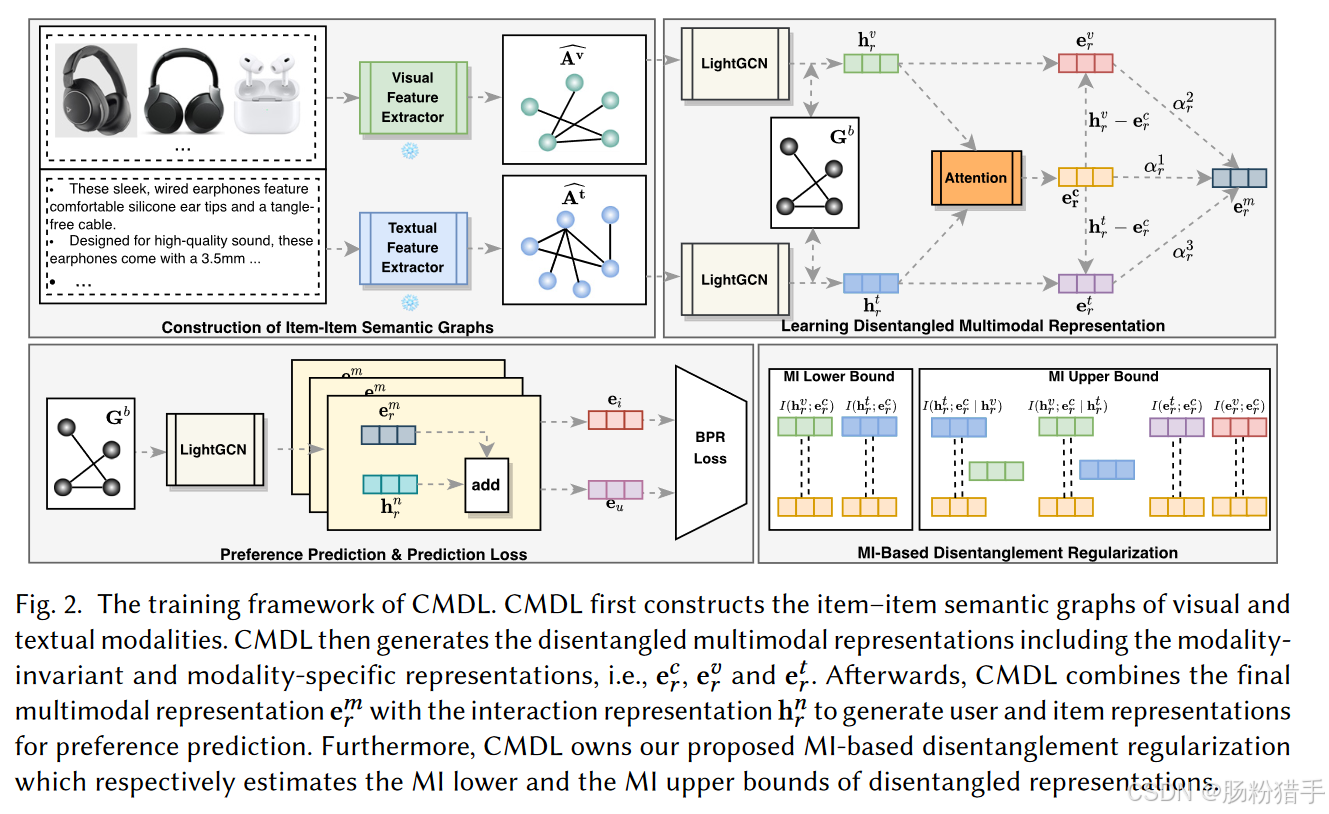
0、估计交互信息。
即确保模态不变表示和模态特定表示在统计上相互独立,同时最大化模态间的共享信息。
首先要衡量两个随机变量X和Y之间的依赖关系,定义如下:
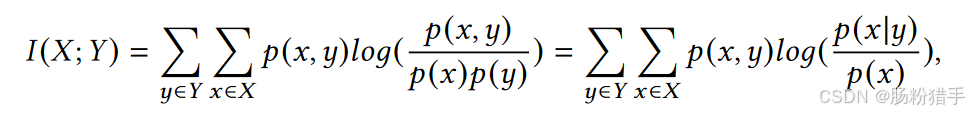
p(x, y)为联合概率,p(x)和p(y)分别是X和Y的边缘概率。
也可以通过熵来定义:
![]()
其中H(X)和H(Y)是X和Y的边缘熵,H(X|Y)和H(Y|X)是条件熵。
但需要注意的是,直接计算交互信息不可行,因为需要用到的这些分布,在高维空间中的估计非常复杂,需要近似的方法来估计。
CMDL使用InfoNCE损失来估计交互信息的下界。其基于对比学习,通过最大化正样本对之间的相似度,同时最小化负样本对之间的相似度来估计交互信息。
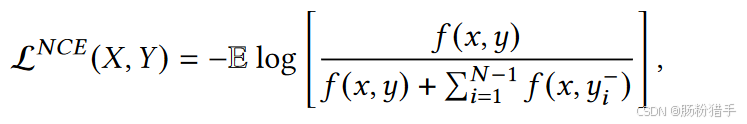
f(x, y)是相似度函数,代表神经网络的输出,表示x和y之间的相似度。
进一步的推导如下:
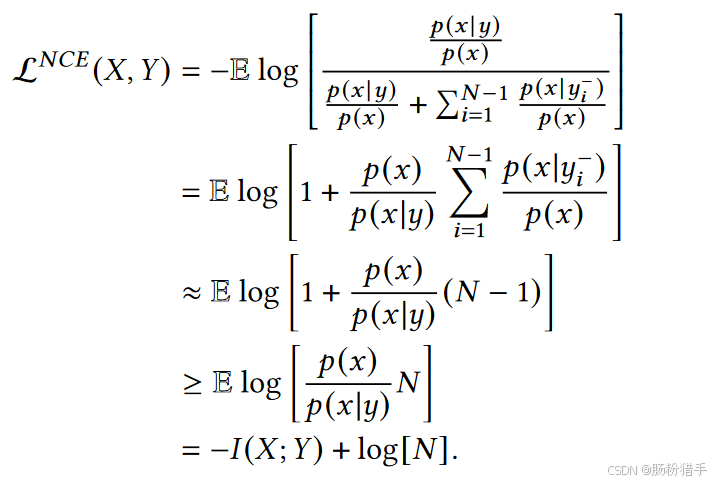
通过最小化InfoNCE损失,可以近似最大化交互信息的下界:
![]()
1、多模态特征预处理
对多模态特征进行预处理(将不同模态的特征对齐到同一特征空间),并利用它们构建视觉和文本模态的“项”-“项”语义图,以便更好地捕捉物品之间的高阶语义关系。
(1)特征对齐
CMDL用一个多层感知机MLP将不同模态特征映射到同一低维空间。以下是视觉特征对齐和文本特征对齐的公式:
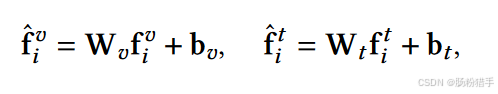
f^i_v是从预训练的VGG16模型中提取的4096维视觉特征。
f^i_t是从预训练的S-Transformer模型中提取的384维文本特征。
然后过滤与推荐任务无关的信息(CMDL使用门控机制):
![]()
xi是物品i的ID嵌入,σ为Sigmoid激活函数。
(2)语义图构建
CMDL构建了视觉和文本模态的语义图,帮助理解物品之间的相似性和关联性。
关于两种模态下,物品之间的语义相似性,采用余弦相似度计算:

为了减少计算复杂度和噪声,对语义图进行稀疏化,只保留每个物品的前K个最相似物品:
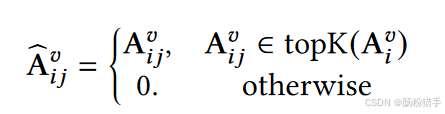
最后CMDL对稀疏化后的邻接矩阵进行归一化,得到![]()
2、解耦纠缠多模态表示
将初始表示分解为模态不变表示和模态特定表示,然后基于这些解耦纠缠表示,捕捉模态共享知识和模态独特知识。
(1)初始图表示
在构建语义图后,CMDL使用GNN来学习初始的物品和用户表示。
首先归一化邻接矩阵:
![]()
其中,Dv和Dt分别是稀疏化后的视觉和文本邻接矩阵的对角矩阵。用到对角矩阵是因为对角线上的元素表示每个节点在视觉/文本模态下的邻接点数量。
然后使用LightGCN进行特征传播,通过聚合邻接节点的信息来更新当前节点的信息。
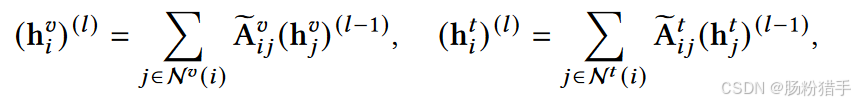
对于物品i的视觉表示h^v_i(l),聚合其在视觉图中的邻接节点j的视觉表示h来更新。每个邻接节点的贡献通过归一化的邻接矩阵元素A加权(这个权重代表物品i和j之间的视觉相似性)。
文本表示与视觉表示同理。
再通过聚合初始物品表示生成初始用户表示:
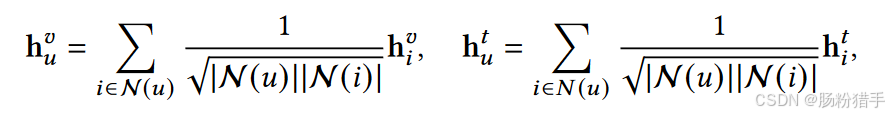
其中,N(u)和N(i)分别是用户u和物品i在“用户-物品”交互图中的邻接集合,h的系数为归一化权重因子。
(2)模态不变表示和模态特定表示
基于初始表示,CMDL进一步将每个表示分解为模态不变表示和模态特定表示。
首先,使用自注意力机制,为每个模态生成归一化的权重:
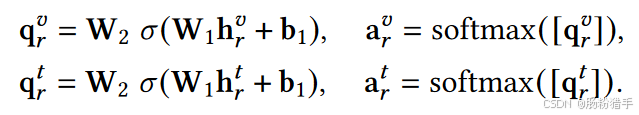
对于视觉模态,首先通过一个线性变化,将初始视觉表示映射到一个新的空间,然后通过激活函数σ引入非线性,得到中间权重向量q。文本模态同理。a即归一化的q。
然后通过加权求和生成模态不变表示,捕捉模态共享信息(这里不区分下标是指用户还是项目):
![]()
通过从初始表示中减去模态不变表示,生成模态特定表示,捕捉模态独特信息:
![]()
(3)解耦正则化
CMDL引入解耦正则化以确保模态不变表示和模态特定表示在统计上相互独立。具体分为两部分:最小化模态特定表示与模态不变表示之间的交互信息、最大化模态不变表示与初始表示之间的交互信息。
(htr为初始文本表示、hvr为初始视觉表示、evr为视觉特定表示、ecr为模态不变表示)
关于第一部分:最小化……,本质上是用链式法则来分解和计算,以视觉模态举例:
![]()
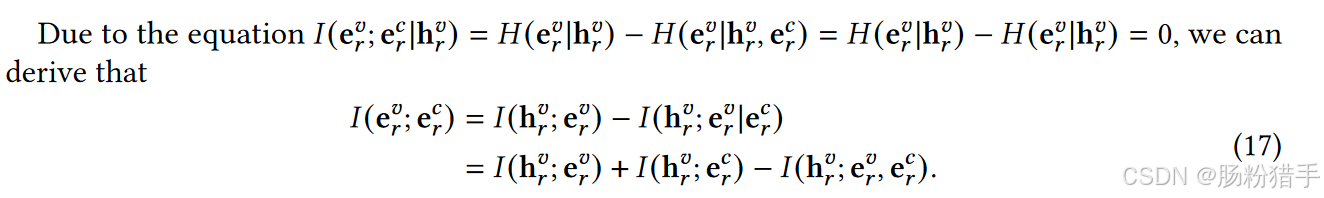
I(evr; hvr | ecr)衡量了在已知模态不变表示ecr的情况下,视觉特定表示evr与初始视觉表示hvr之间的依赖关系,其他项同理。
关于第二部分:最大化……,和第一部分同理。
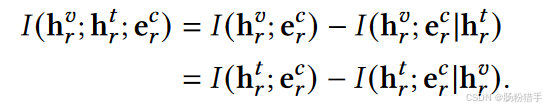
可以进一步扩展,定义一个优化目标:最大化 I(hvr; htr; ecr) 的同时最小化 I(evr; ecr)。
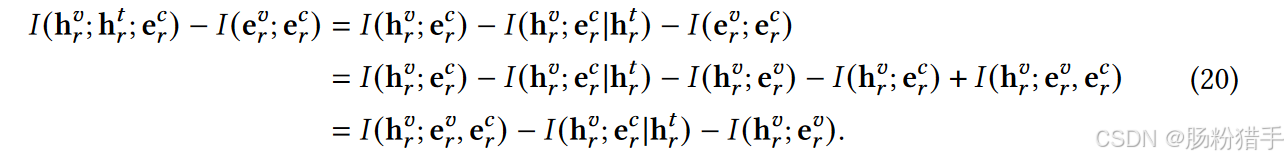
最终的模态解耦正则化目标如下:
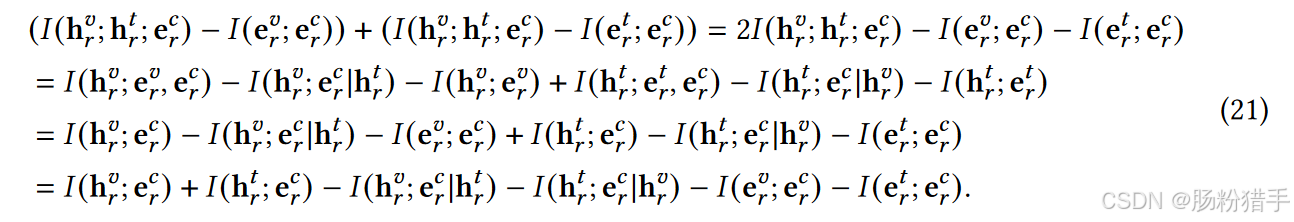
公式21综合了视觉和文本模态的信息,确保ecr能够捕捉到视觉和文本模态之间的共享信息,同时确保evr和etr与ecr在统计上独立。
这个公式的目标:最大化I(hvr; ecr)、最小化I(hvr; ecr | htr)、最小化I(evr; ecr)
3、偏好预测
用户和物品由多个模态的信息融合,最终表示由模态不变表示和模态特定表示组合而成。此处引入三个权重因子,反映不同模态在偏好预测中的重要性。
![]()
三个权重通过“用户-物品”交互图(hn)学习得到:
![]()
用户u和物品i的最终表示eu和ei由“用户-物品”交互图的表示hnu和hni与最终多模态表示emu和emi拼接而成。
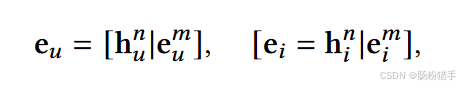
4、模型优化
直接优化公式21较为困难,故引入基于对比学习的近似。
损失分为预测损失和解耦正则化损失:
![]()
接下来要分别计算这两个损失。
关于预测损失:
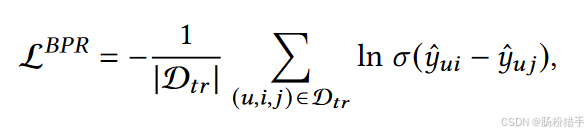
采用贝叶斯个性化排名BPR以优化模型测试性能。BPR旨在最大化用户对正样本(交互过的物品)的偏好分数与负样本(未交互过的物品)的偏好分数之间的差异。Dtr是训练数据集(格式是三元组,包含用户-正样本-负样本),σ(yui - yuj)表示用户u对正样本i的偏好高于负样本j的概率。而后最大化对数似然函数、求平均,即得到预测损失。
关于解耦正则化损失, 需要最大化前两项、最小化后四项,即需最大化如下:
![]()
对于前两项,采用InfoNCE损失,详细可见于第(0)部分公式推导:
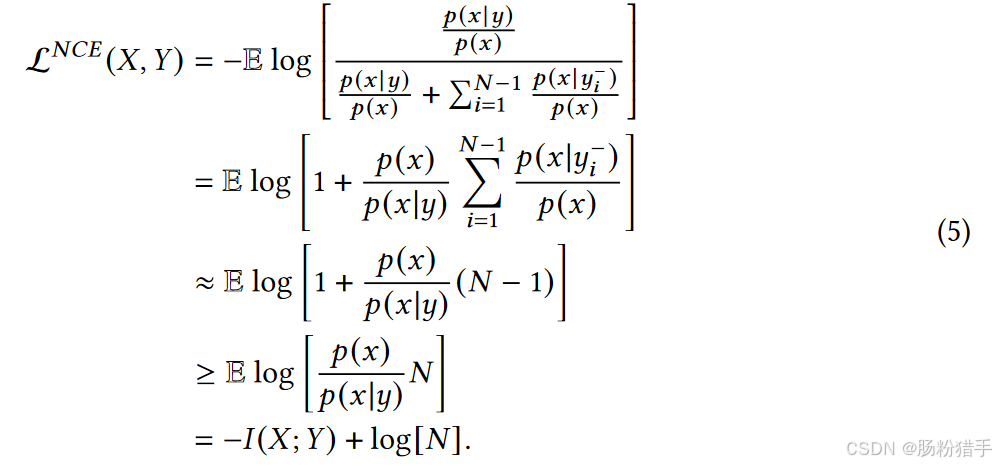
对于后四项,为最小化每个MI项定义一个上界。为了实现这一点,引入如下定理:
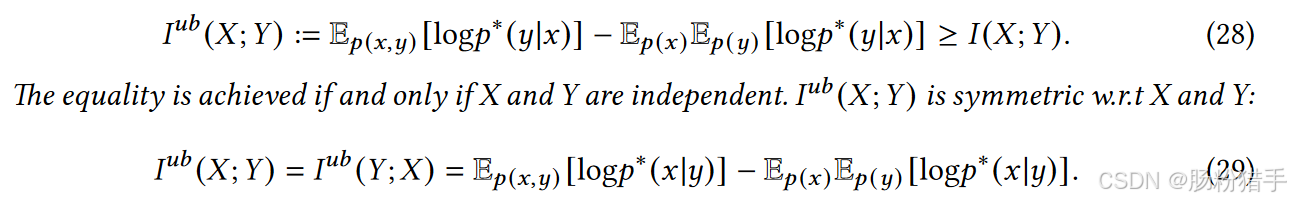
公式28基于条件分布p*(y|x)来近似交互信息。具体来说,通过计算log p*(y|x)的期望值来估计I(X; Y)。当X和Y完全独立时,即p(x, y) = p(x)p(y),等号成立。
但以上公式要求必须提供条件分布,限制了应用。基于以上定理,可以设计一种条件分布的近似策略,得到一个新的MI上界及其具体的损失函数进行优化。
通过最小化InfoNCE损失函数以获得优化的critic函数,并用其近似条件对数似然log p*(x|y)。
公式大致为log f(x, y) = log p(x|y) + f(x)。故以上公式可转变为:
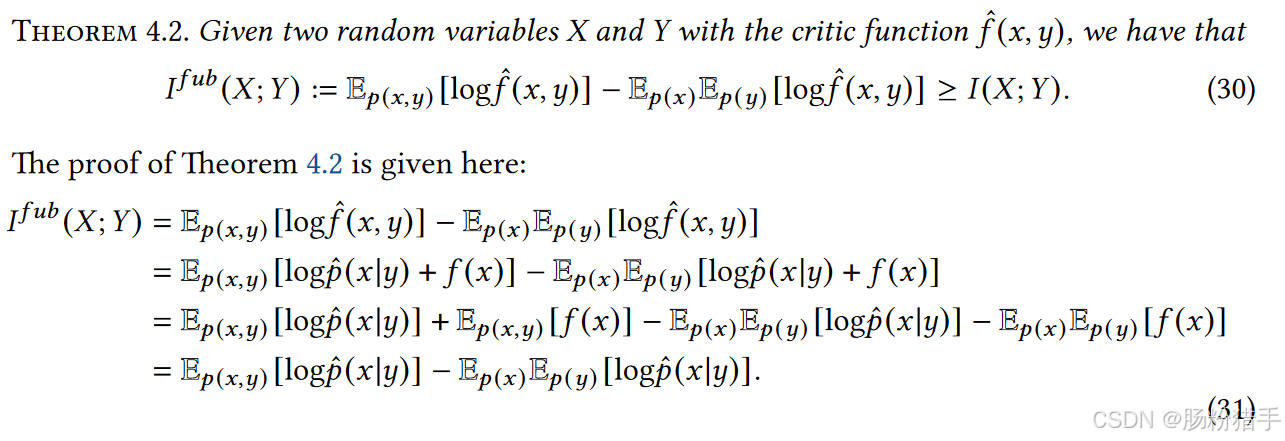
关于为什么Ifub(X; Y)是I(X; Y)的一个上界:
定义增量为Ifub(X; Y)和I(X; Y)之间的差值。
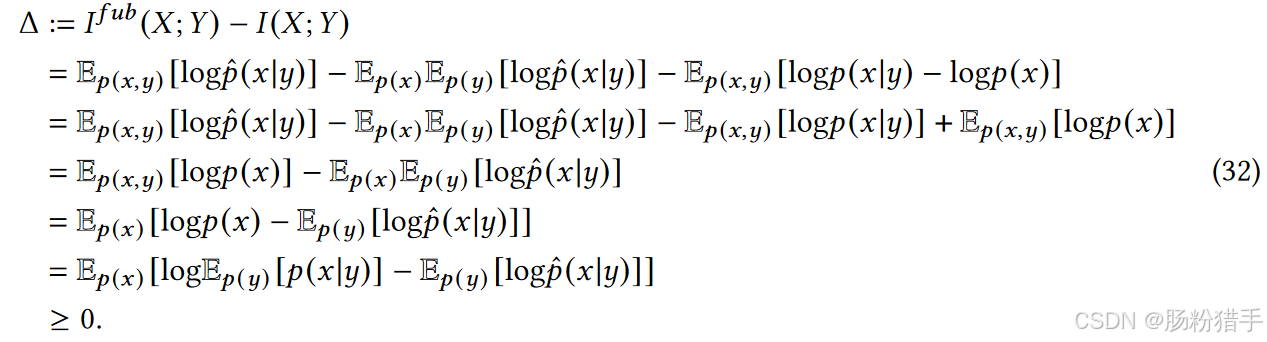
由于log f(x, y) = log p(x|y) + f(x),并且f(x)是一个与y无关的函数,因此:
Ep(x, y)[f(x)] = Ep(x)[f(x)],Ep(x)Ep(y)[f(x)] = Ep(x)[f(x)],这些想在计算差值时会相互抵消。
充分展开并简化后,发现Ep(x, y)[log p(x)]是一个常数项,不影响差值的符号,可以忽略。
然后利用詹森不等式推导出最终结果。
接下来构建和优化MI上界的损失函数Lfub(X, Y):
![]()
(x, y)是正样本对,表示x和y在联合分布p(x, y)下的样本;
(x, y-)是负样本对,表示x和y在边缘分布p(x)和p(y)下的独立样本。
引入条件变量后:
![]()
基于公式33和34,可以用类似于InfoNCE的方式,通过相应的critic函数,有效优化后四个MI项。得到以下基于MI的解耦正则化表述:
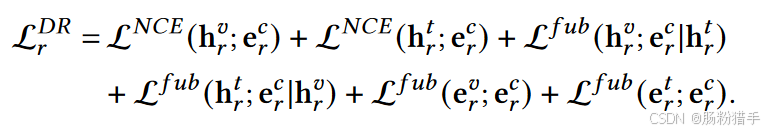
所有critic函数都用mlp实现,以提高效率,最后得到如下式子:
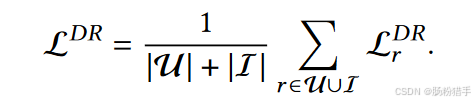
LDR是所有实体(用户和物品)的正则化损失函数的平均值,U和I分别是用户集合和物品集合,通过最小化LDR,模型能够学习到模态不变表示和模态特定表示之间的独立性,提高多模态推荐系统的性能。
四、创新点
1、CMDL能区分模态共享知识和模态独特知识,以更好地融合不同模态的信息,同时避免信息冗余和噪声;
2、引入基于交互信息(MI)估计的解耦正则化,确保模态不变表示和模态独特表示之间的独立性,提升推荐系统的准确性(关于解耦正则化的理论部分是组成本文模型可解释性的重要部分)。
3、利用对比学习框架优化解耦正则化。通过最大化正样本对之间的相似度、最小化负样本对之间的相似度,有效学习数据的表示(即更好地捕捉模态之间的关系)。
4、提出新的交互信息上界估计方法,通过优化这个上界来近似地最小化交互信息,从而实现模态解耦。
(5、CMDL构建了每个模态的“项-项”语义图,用于捕捉高阶语义关系;)
(6、运用维度对齐和门控机制,处理不同模态特征之间的差异。)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









