






基于深度学习CNN和PyQt5的表情识别系统研究与实现
一、摘要
本文介绍了一个基于深度学习CNN和PyQt5的表情识别系统的设计与实现。该系统能够实时识别人脸表情,支持多种表情类别,具有较高的识别准确率和良好的用户体验。
二、前言
随着人工智能技术的快速发展,计算机视觉在人机交互领域的应用越来越广泛。表情识别作为情感计算的重要分支,在智能教育、心理健康、人机交互等领域有着广泛的应用前景。本文将详细介绍一个基于深度学习的表情识别系统的设计与实现过程,希望能为对这一领域感兴趣的读者提供一些参考。
三、项目概述
在日常生活中,表情是人类情感表达的重要方式之一。我们开发的这个表情识别系统能够通过摄像头实时捕获人脸,并准确识别出7种基本表情:愤怒、厌恶、恐惧、高兴、悲伤、惊讶和中性表情。
系统采用CNN卷积神经网络模型进行表情分类,通过PyQt5构建友好的用户界面,可以直观展示识别结果和各表情的概率分布,使用户能够方便地体验表情识别的全过程。
1、系统架构
(1)文件架构
├── .idea/ # IDE配置文件
├── assets/ # 资源文件
├── dataset/ # 数据集目录
├── input/ # 输入图像目录
├── models/ # 模型存储目录
│ ├── cnn3_best_weights.h5 # 预训练CNN模型
│ └── tips.txt # 模型说明
├── output/ # 输出目录
├── src/ # 源代码目录
│ ├── blazeface/ # BlazeFace人脸检测模块
│ │ ├── __init__.py
│ │ ├── blazeFaceDetector.py
│ │ ├── blazeFaceUtils.py
│ │ └── weights/ # 检测模型权重
│ ├── ui/ # 用户界面相关代码
│ │ └── ui.py # UI实现(PyQt5)
│ ├── data.py # 数据处理模块
│ ├── Gabor.py # Gabor滤波器特征提取
│ ├── gui.py # GUI主程序
│ ├── LBP.py # 局部二值模式特征提取
│ ├── model.py # CNN模型定义
│ ├── paper.py # 论文图表生成
│ ├── preprocess.py # 图像预处理
│ ├── recognition.py # 图像表情识别
│ ├── recognition_camera.py # 实时摄像头表情识别
│ ├── test.py # 测试模块
│ ├── utils.py # 工具函数集
│ └── visualize.py # 可视化模块
├── .gitignore # Git忽略配置
├── env.sh # 环境变量设置
├── requirements.txt # 项目依赖包
└── 测试tensorflow运行速度.py # 性能测试
(2)系统流程图
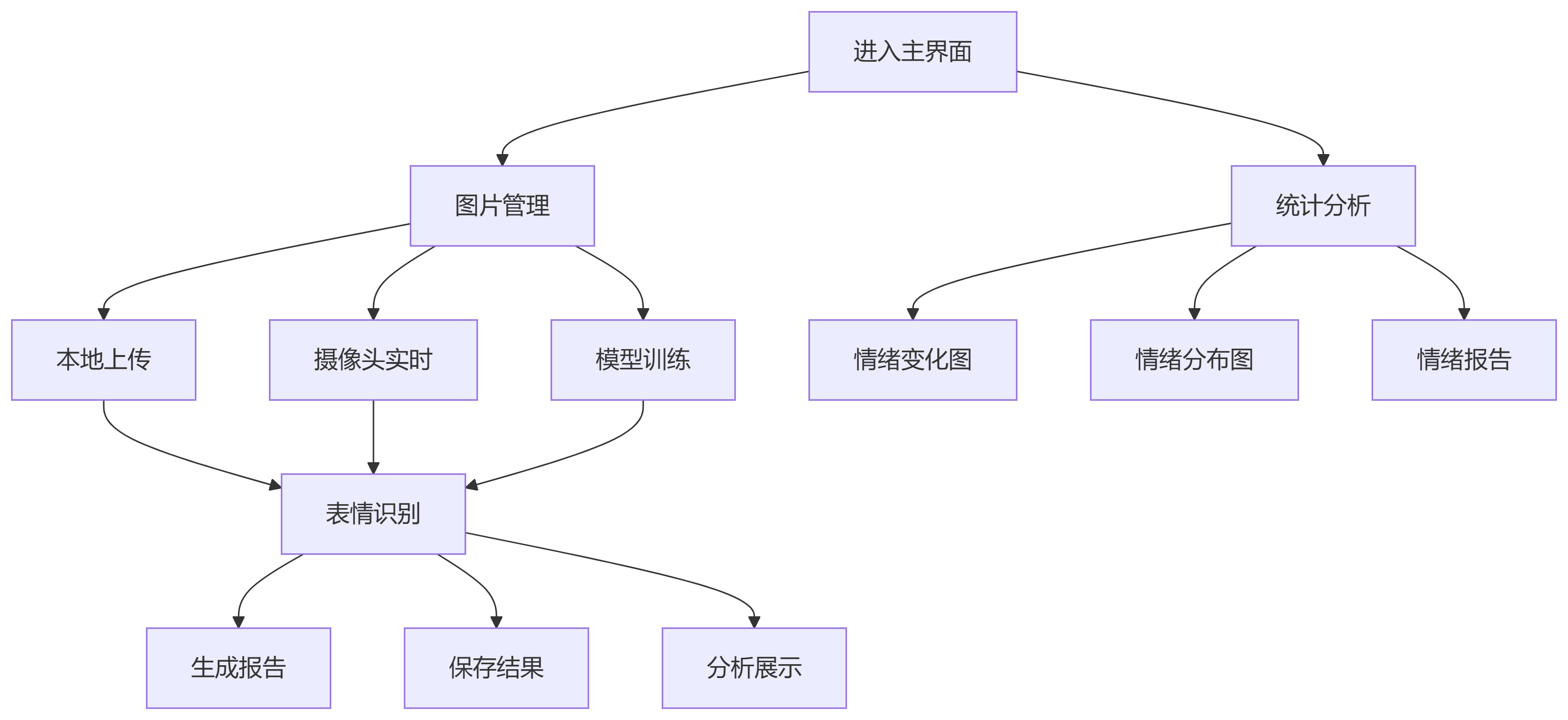
整个系统由四个主要模块组成,彼此协同工作,形成一个完整的表情识别流程:
数据处理模块:负责读取和预处理表情数据集,为模型训练提供高质量的数据。
模型训练模块:实现CNN模型的定义和训练,是系统的核心部分。
表情识别模块:对输入图像进行人脸检测和表情识别,实现系统的主要功能。
可视化界面:提供用户友好的操作界面,展示识别结果,提升用户体验。
这种模块化的设计使系统具有良好的可维护性和可扩展性,各模块可以独立开发和测试,也可以根据需要进行替换或升级。
2、数据集选择
选择合适的数据集对模型的训练至关重要。我们的系统支持多种常用的表情数据集:
fer2013:这是一个包含48×48像素人脸灰度图像的大型数据集,共有7种表情类别,约35,000张图像。由于其规模和多样性,是表情识别领域的标准数据集之一。
JAFFE:日本女性表情数据集,虽然规模较小,但图像质量高,表情标准,适合作为补充训练集。
CK+:扩展版Cohn-Kanade数据集,包含123个受试者的593个表情序列,每个序列从中性表情开始,逐渐发展到目标表情的峰值。
使用多个数据集进行训练可以提高模型的泛化能力,使系统在各种复杂环境下都能保持良好的识别效果。
3、深度学习模型设计
经过多次实验和优化,我们最终实现了三种CNN模型结构,每种结构都有其特点和适用场景:
1、 CNN1:轻量级VGG风格网络
这个模型基于VGG的设计思路,但进行了简化和调整。主要特点是感受野较小,以避免获取过多噪声信息。这对于表情识别非常重要,因为表情主要体现在眼睛、嘴巴等局部特征上,过大的感受野可能会引入无关信息。
2、 CNN2:1×1卷积增强网络
参考了"Going deeper with convolutions"论文的思想,在输入层后加入1×1卷积层,增强网络的非线性表示能力。这种设计可以在不增加太多计算量的情况下,提高模型对复杂表情的识别能力。
3、CNN3:紧凑型鲁棒网络
基于"A Compact Deep Learning Model for Robust Facial Expression Recognition"论文实现的模型,是系统默认使用的网络结构。这个模型在保持较小规模的同时,通过特殊的层设计提高了对光照变化、姿态变化等干扰因素的鲁棒性。
4、训练模型
# 当选择fer2013数据集时执行的代码块
if opt.dataset == "fer2013":
# 加载FER2013数据集
# expressions: 表情类别标签列表
# x_train/y_train: 训练集图像数据和标签
expressions, x_train, y_train = Fer2013().gen_train()
# 加载验证集(_表示忽略返回的表情标签列表)
_, x_valid, y_valid = Fer2013().gen_valid()
# 加载测试集
_, x_test, y_test = Fer2013().gen_test()
# 将标签转换为one-hot编码格式
# 例如:类别3 -> [0,0,0,1,0,0,0,0](假设共8类)
y_train = to_categorical(y_train).reshape(y_train.shape[0], -1)
y_valid = to_categorical(y_valid).reshape(y_valid.shape[0], -1)
# 数据集对齐处理:增加一个全零列(可能用于适配其他数据集的维度)
y_train = np.hstack((y_train, np.zeros((y_train.shape[0], 1))))
y_valid = np.hstack((y_valid, np.zeros((y_valid.shape[0], 1))))
# 打印数据集加载成功信息和统计信息
print("成功加载fer2013数据集,包含{}训练图像和{}验证图像".format(y_train.shape[0], y_valid.shape[0]))
# 初始化CNN模型(假设是自定义的三层卷积神经网络)
# 输入形状:48x48像素的灰度图像(通道数为1)
# 分类数量:8类
model = CNN3(input_shape=(48, 48, 1), n_classes=8)
# 配置SGD优化器参数
sgd = SGD(
lr=0.01, # 初始学习率
decay=1e-6, # 权重衰减系数
momentum=0.9, # 动量参数
nesterov=True # 启用Nesterov动量
)
# 编译模型(配置损失函数和评估指标)
model.compile(
optimizer=sgd,
loss='categorical_crossentropy', # 分类交叉熵损失
metrics=['accuracy'] # 监控准确率指标
)
# 定义训练回调函数
callback = [
ModelCheckpoint(
'./models/cnn2_best_weights.h5', # 模型保存路径
monitor='val_acc', # 根据验证准确率保存最佳模型
verbose=True, # 显示保存信息
save_best_only=True, # 只保存最佳模型
save_weights_only=True # 仅保存权重不保存整个模型
)
]
# 创建图像数据生成器(数据增强)
train_generator = ImageDataGenerator(
rotation_range=10, # 随机旋转角度范围(度)
width_shift_range=0.05, # 水平平移幅度比例
height_shift_range=0.05, # 垂直平移幅度比例
horizontal_flip=True, # 启用水平翻转
shear_range=0.2, # 剪切变换强度
zoom_range=0.2 # 随机缩放范围
).flow(x_train, y_train, batch_size=opt.batch_size) # 生成增强后的训练数据批次
# 验证集生成器(不做数据增强)
valid_generator = ImageDataGenerator().flow(x_valid, y_valid, batch_size=opt.batch_size)
# 开始模型训练
history_fer2013 = model.fit_generator(
generator=train_generator, # 训练数据生成器
steps_per_epoch=len(y_train) // opt.batch_size, # 每个epoch的迭代步数
epochs=opt.epochs, # 总训练轮次
validation_data=valid_generator, # 验证数据生成器
validation_steps=len(y_valid) // opt.batch_size, # 验证步数
callbacks=callback # 训练回调函数
)
his = history_fer2013 # 保存训练历史记录
# 测试阶段
pred = model.predict(x_test) # 对测试集进行预测
pred = np.argmax(pred, axis=1) # 获取预测类别(取概率最大的类别)
# 计算测试准确率
test_acc = np.sum(pred.reshape(-1) == y_test.reshape(-1)) / y_test.shape[0]
print("测试集准确率:", test_acc)4、系统功能展示
我们的表情识别系统提供了丰富的功能,满足不同场景下的使用需求:
(1) 图像识别:
用户可以上传任意包含人脸的图片,系统会自动检测图片中的人脸并识别表情。这对于批量处理图片数据非常有用。
(2)实时识别:
通过连接摄像头,系统可以实时捕获用户的面部表情并进行识别。这种交互方式更加直观,用户可以即时看到自己表情的识别结果。
(3)结果可视化:
系统不仅会给出最终的表情类别,还会以图表形式展示各种表情的概率分布,让用户了解识别的置信度和可能性。
5、技术实现细节
(1)人脸检测技术
人脸检测是表情识别的第一步,我们实现了两种检测方法:
OpenCV的Haar级联分类器:这是一种传统但高效的人脸检测方法,适用于计算资源有限的场景。
BlazeFace模型:谷歌开发的轻量级人脸检测模型,检测速度快,准确率高,适合实时应用。
用户可以根据实际需求选择合适的检测方法。
(2)表情预测流程
完整的表情预测流程包括以下几个步骤:
(1)图像读取与灰度化:将输入图像转换为灰度图,简化后续处理。
(2)人脸检测与裁剪:定位图像中的人脸区域并裁剪出来。
(3)人脸图像预处理与增强:对裁剪出的人脸进行尺寸调整、直方图均衡化等处理,提高识别准确率。
(4)CNN模型预测:将预处理后的人脸图像输入CNN模型,得到各表情类别的概率。
(5)结果可视化与展示:将识别结果以直观的方式呈现给用户。
6、 用户界面设计
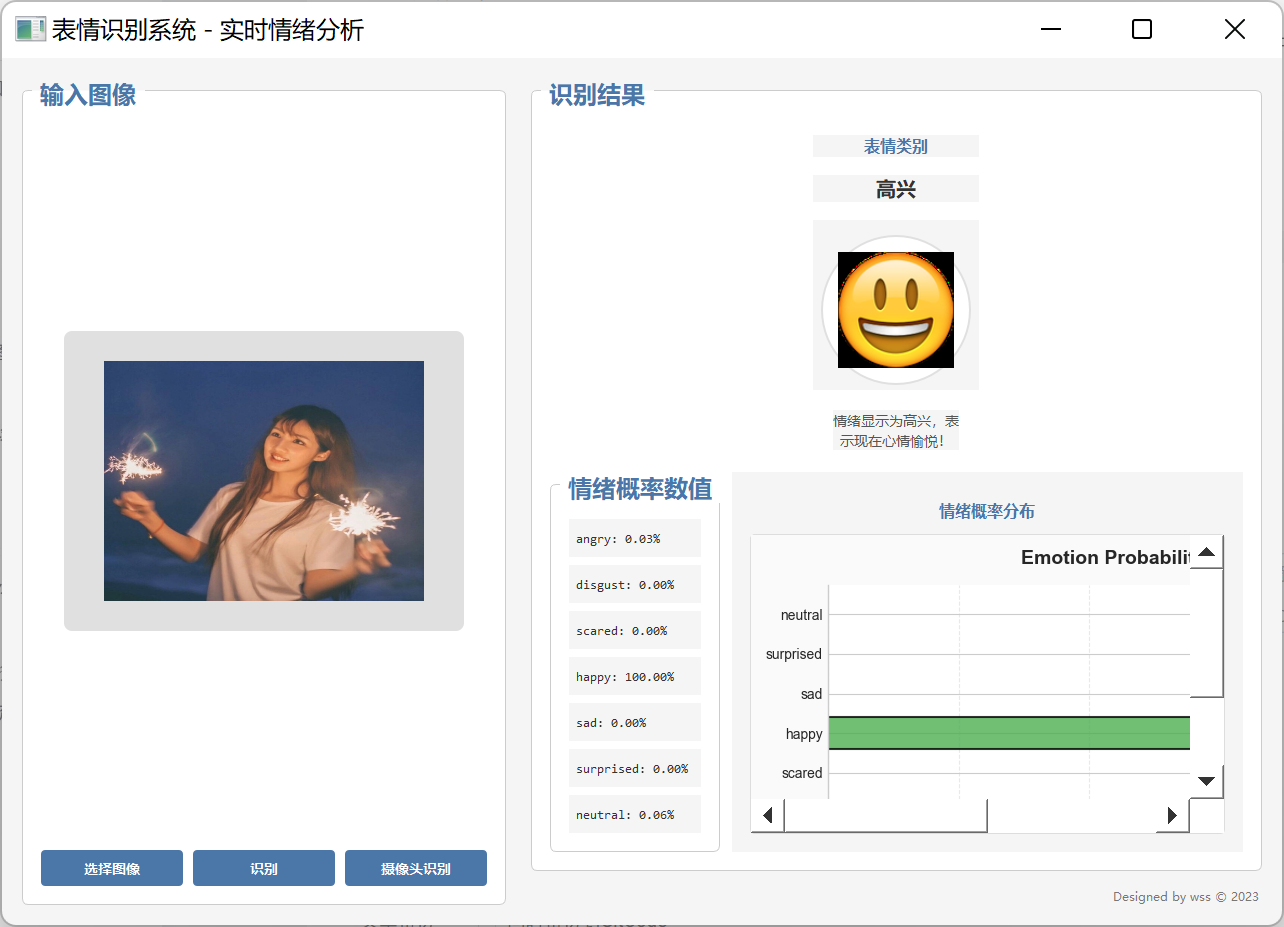
我们使用PyQt5框架实现了一个美观、易用的图形界面,主要包括:
图像显示区域:展示原始图像和识别结果。
操作按钮区域:提供图片上传、摄像头开关等功能。
识别结果显示区域:以文字形式显示识别出的表情类别。
概率分布图表区域:以柱状图形式展示各表情类别的概率分布。
界面设计遵循简洁、直观的原则,即使是非技术用户也能轻松上手使用。
7、 系统优势
相比于其他表情识别系统,我们的系统具有以下几个显著优势:
多模型支持:实现了多种CNN模型结构,用户可以根据需求选择不同的模型,平衡准确率和速度。
多数据集支持:兼容多种表情数据集格式,提高了模型的泛化能力。
实时处理能力:优化的模型结构和算法实现,使系统能够在普通硬件上实现实时表情识别。
直观的结果展示:使用图表清晰展示识别结果,增强用户体验。
友好的用户界面:精心设计的界面布局和交互流程,使系统操作简单,反馈直观。
8、开发技术栈
本系统的开发使用了多种现代技术:
编程语言:Python,其丰富的库和生态系统为项目提供了强大支持。
深度学习框架:TensorFlow和Keras,提供了高效的模型构建和训练能力。
图像处理:OpenCV,用于图像读取、处理和人脸检测。
图形界面:PyQt5,用于构建美观、响应迅速的用户界面。
数据可视化:Matplotlib,用于识别结果的图形化展示。
这些技术的组合使我们能够在保证系统性能的同时,提供良好的用户体验。
9、未来改进方向
尽管当前系统已经具备了较好的功能和性能,但仍有多个方面可以进一步改进:
增加更多表情类别:除了基本表情外,可以考虑增加更细粒度的表情分类,如轻蔑、困惑等。
提高识别准确率:通过引入注意力机制、迁移学习等先进技术,进一步提高模型的识别准确率。
优化模型结构:探索更高效的网络结构,减小模型体积,降低计算资源需求。
改进实时识别性能:优化算法和代码实现,提高系统在实时场景下的响应速度。
支持移动端部署:将系统移植到移动设备上,扩大应用场景和用户群体。
十、 结语
表情识别是情感计算领域的重要研究方向,有着广泛的应用前景。本文介绍的基于深度学习CNN和PyQt5的表情识别系统,通过模块化设计和先进技术的应用,实现了较高的识别准确率和良好的用户体验。
希望这个项目能为情感计算领域的研究和应用提供一些思路和参考,也期待有更多的开发者和研究者加入到这个领域,共同推动表情识别技术的发展和应用。
十一、视频演示
情绪识别


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









