






在python的数据处理时,我们常常会用到pandas,它比起numpy来说可以处理的数据范围更广。
pandas中series的了解
series类似于字典,拥有数据和索引。
1.series的创建,例:
import pandas as pd
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题
np.set_printoptions(precision=1, floatmode='fixed') # precision 表示的是小数点保留的位数
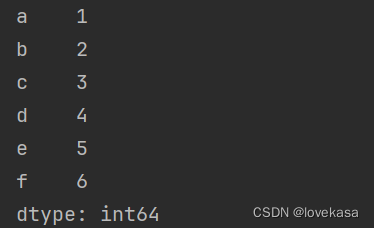
t1 = pd.Series([1,2,3,4,5,6],index=list("abcdef"))
print(t1)数据为1-6,索引为a-f。
创建类型2:
t1 = pd.Series({"name":"大帅哥","age":30,"tel":10086}) 
2.dataFrame的创建
创建一个3行4列的DataFrame,行索引为abc,列索引为wxyz。
t = pd.DataFrame(np.arange(12).reshape(3,4),index = list("abc"),columns= list("wxyz"))创建类型2:
#形式一:
t = pd.DataFrame({"name":["小明","小强"],"age":[20,32],"tel":[10086,10010]})
print(t)
#形式二:
t1 = pd.DataFrame([{"name":"小明","age":32,"tel":10086},{"name":"小李","tel":10010},{"age":23,"tel":32322}])
print(t1)运行结果:
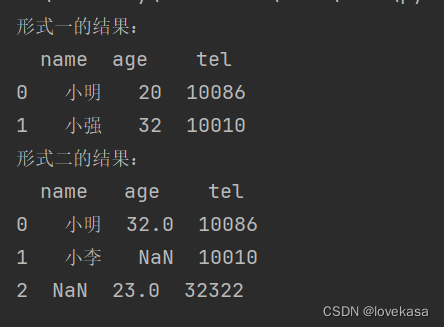
由结果可知,利用形式二来创建更加便利,因为不需要一一对应。















 4669
4669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









