






一、数据结构与算法2
2、队列
队列(queue)是另一种限定性的线性表,它只允许在表的一端插人元素,而在表的另一端删除元素,所以队列具有先进先出(first in first out, FIFO)的特性。这与我们日常生活中的排队是一样的,最早进人队列的人最早离开,新来的人总是加人队尾。在队列中,允许插入的一端称为队尾(rear), 允许删除的一端则称为队头(fronl)。假设队列为q=(a₁,a₂,...,aₙ), 那么a₁就是队头元素,aₙ则是队尾元素。队列中的元素是按照a₁,a₂,...,aₙ顺序进人的,退出队列也必须按照同样的次序依次出队,也就是说,只有在a₁,a₂,...,aₙ₋₁都离开队列之后,aₙ才能退出队列。
【算法思想】在操作系统中,循环队列经常用于实时应用程序。例如,当程序正在执行其他任务时,用户可以从键盘不断输人内容,很多字处理软件就是这样工作的。系统在采用这种分时处理方法时,用户输人的内容不能在屏幕上立刻显示出来,直到当前正在工作的进程结束为止。但在该进程执行时,系统是在不断地检查键盘状态,若检测到用户输人了一个新的字符,就立刻把它存到系统的输入缓冲区中,然后继续运行原来的进程。在当前工作的进程结束后,系统就从缓冲区中取出用户输入的字符,并按要求进行处理。这里的系统输人缓冲区采用了循环队列。队列的特性保证了输入字符先输人、先保存、先处理的要求,循环结构又有效地限制了缓冲区的大小,并避免了假溢出问题。
【问题描述】有两个进程同时存在于一个程序中。其中第一个进程在屏幕上连续显示字符“A”, 与此同时,程序不断检测键盘是否有输人,如果有则读人用户输人的字符并保存到输人缓冲区中。在用户输人时,输人的字符并不立即回显到屏幕上。当用户输人一个逗号“,”或分号“;”时,表示第一个进程结束,第二个进程从缓冲区中读取那些已输入的字符并显示到屏幕上。第二个进程结束后,程序又进入第一个进程,重新显示字符“A”,同时用户又可以继续输入字符,直到用户输人一个分号键才结束第一个进程,同时也结束整个程序。
【算法描述】键盘输入循环缓冲区问题
#include<stdio.h>
#include<conio.h>
//提供控制台输入输出函数
#include<queue.h>
//用于实现链表、尾队列和循环列表等数据结构
main()
{/*模拟键盘输入循环缓冲区*/
char ch1,ch2;
SeqQueue Q;
int f;
InitQueue (&Q);/*队列初始化*/
for(;;)
{
for(;;)/*第一个进程*/
{
printf("A");
if(kbhit())
{
ch1=getch();/*读取键入的字符,但屏幕上不显示*/
if(ch1==';'||ch1==',') break;/*第一个进程正常中断*/
f=EnterQueue (&Q,ch1);
if(f==FALSE)
{
printf("循环队列已满\n");
break;/*循环队列满时,强制中断第一个进程*/
}
}
}
while (!IsEmpty(Q))/*第二个进程*/
{
DeleteQueue (&Q,&ch2);
putchar(ch2):/*显示输入缓冲区的内容*/
}
if(ch1==';') break;/*整个程序结束*/
}
}二、Hadoop入门2:
1、HDFS模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
SecondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
2、单机运行内存至少是8G,集群运行内存至少是16G
3、集群一键启动
/onekey/my-start-all.sh
集群一键关闭
/onekey/my-stop-all.sh
4、终端命令作用:
ll:查看详细列表 等同于ls -l;ls:查看列表文件名
chmod:修改文件或目录的权限
echo:在终端输出文本内容
5、访问端口
hdfs访问:2.x 50070 3.x 9870
运行日志:19888
yarn:8088
6、各文件存放命令
bin:放运行文件
cd -:回到上一次操作的地方
cd ..:回到上层目录
sbin:存放系统管理和系统维护的关键性命令
etc:配置文件
hadoop share:存放测试案例
7、若内存溢出在,可在yarn资源管理器页面复制aplication ID,用yarn aplication -kill杀死yarn上的任务,例:
yarn application -kill application_1628735904594_4607155
8、文件系统shell命令使用格式:
hadoop fs <args>:官方推荐,可以操作hdfs,也可以操作本地的
hdfs dfs <args>:只能操作hdfs
9、HDFS的Shell命令功能:(前缀:hadoop fs)
-rm:删除文件
-rm -r:删除目录
-mkdir:创建目录
-mv:移动或重命名
-cp:将文件拷贝到目标路径
-cat:将参数所指示的文件内容输出到控制台
-put:将本地的文件上传到目标文件
-get:下载
10、Hadoop如何实现分布式
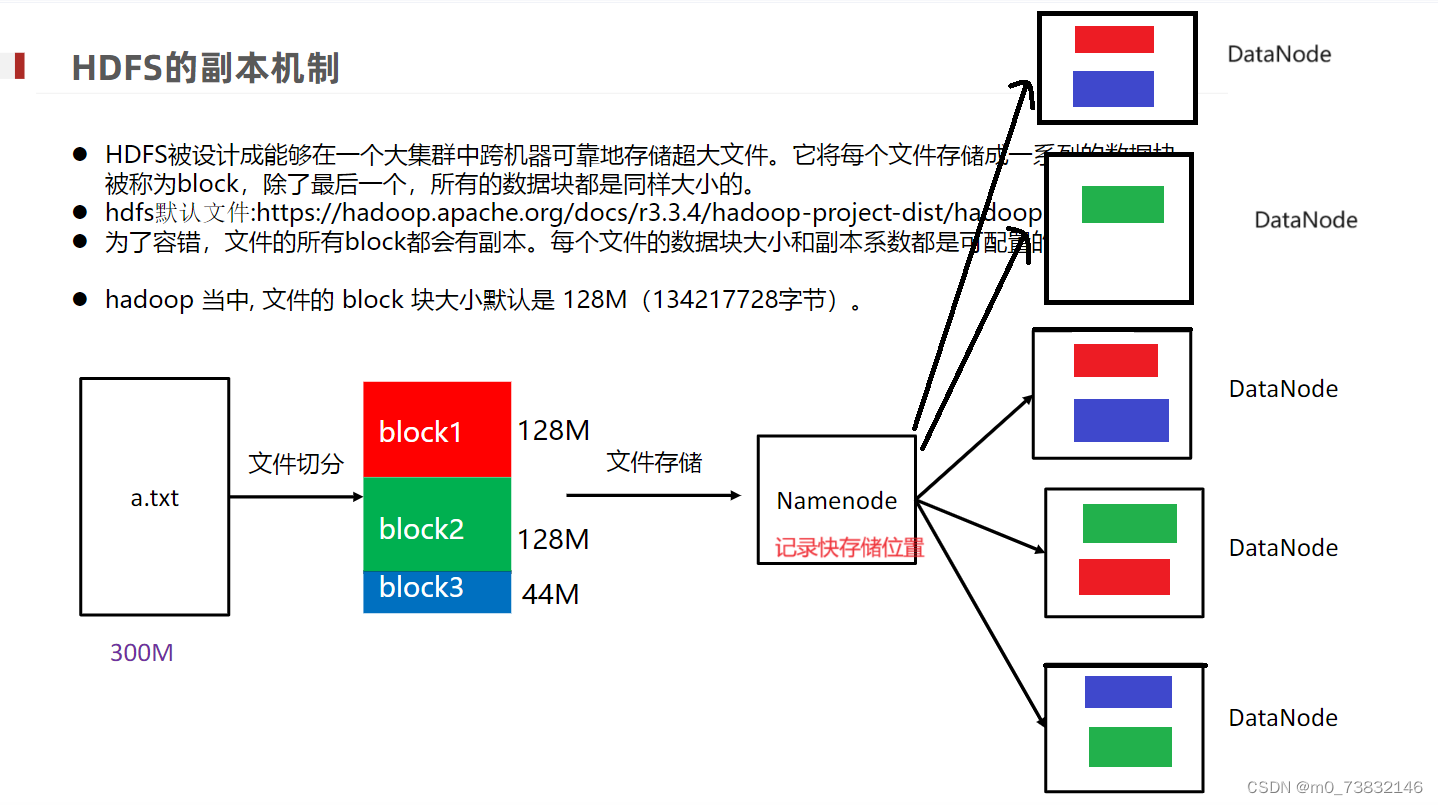
三、Hive
1、Hive是基于Hadoop实现的一个工具
2、Hive将文件转化成表结构,将用于查询的SQL语句转化成MapReduce语句;MapReduce能直接支持Java、Python,不能直接支持SQL
3、描述数据的数据称作元数据
Hive元数据存储用Metastore
Hadoop元数据存储用Namenode
4、Hive Driver驱动程序包括:Parser解析器,Planner任务计划,Execution执行器,Optimizer优化器,MS Client。
补充:
Hive的驱动引擎是其核心部分,负责将HiveQL(Hive Query Language)语句转换为可执行的计划,并最终执行这些计划。以下是Hive驱动引擎的主要组成部分:
1. 解析器:解释器的作用是将Hive SQL语句转换成抽象语法树(AST)。这是从高层次的查询语言到计算机可以理解的结构的第一步。
2. 编译器:编译器进一步将抽象语法树编译为逻辑执行计划。这个计划定义了数据流和操作,但还没有涉及到具体的物理执行细节。
3. 优化器:优化器对逻辑执行计划进行优化,以提高查询的效率。这可能包括重新排列操作的顺序、选择更有效的操作方法等。
4. 执行器:执行器负责调用底层的执行框架,如MapReduce,来执行优化后的逻辑执行计划。执行器将计划转换为实际的任务并分配给Hadoop集群中的节点执行。总的来说,Hive的驱动引擎是一个复杂的系统,它通过多个组件协同工作,将用户的查询请求转换为可以在Hadoop集群上执行的任务。
5、Metastore单独配置、启动使用远程模式,存储在第三方库Mysql中。
6、ifconfig:查看网卡信息
jps -m:查询所有正在运行的进程
注:“-”开头是文件,“d”开头是文件夹
总结:Hive与Mysql的数据查询语言类似 ,Hive不支持即时改写和添加,MySQL支持创建、读取、更新、删除操作;Hive是基于Hadoop实现的一个工具。今天理解了什么是Hive,并且对Hadoop命令语句的功能有了清晰的了解。















 2248
2248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









