






 本文详细介绍了如何使用JavaAPI操作Hadoop分布式文件系统(HDFS)的实验原理,包括配置Hadoop环境、引入依赖、创建FileSystem对象以及执行基本的文件操作,如上传、下载、创建目录和查看文件信息。
本文详细介绍了如何使用JavaAPI操作Hadoop分布式文件系统(HDFS)的实验原理,包括配置Hadoop环境、引入依赖、创建FileSystem对象以及执行基本的文件操作,如上传、下载、创建目录和查看文件信息。
-
(1)实验原理
使用Java API操作HDFS的实验原理如下:
配置Hadoop环境:首先需要配置Hadoop的环境,包括设置Hadoop的安装路径、配置core-site.xml和hdfs-site.xml等文件,以便Java程序能够连接到HDFS。
引入Hadoop依赖:在Java项目中,需要引入Hadoop的相关依赖,包括hadoop-common、hadoop-hdfs等依赖,以便能够使用Hadoop提供的API。
创建Configuration对象:使用org.apache.hadoop.conf.Configuration类创建一个Configuration对象,该对象包含了Hadoop的配置信息。
创建FileSystem对象:使用org.apache.hadoop.fs.FileSystem类的静态方法get(),传入Configuration对象,创建一个FileSystem对象,该对象用于与HDFS进行交互。
执行HDFS操作:通过FileSystem对象,可以执行各种HDFS操作,如创建目录、上传文件、下载文件、删除文件、重命名文件等。具体操作可以使用FileSystem对象提供的方法,如create()、copyFromLocalFile()、copyToLocalFile()、delete()、rename()等。
关闭FileSystem对象:在操作完成后,需要调用FileSystem对象的close()方法关闭与HDFS的连接,释放资源。
通过以上步骤,就可以使用Java API操作HDFS,实现对HDFS文件系统的管理和操作。
-
(2)实验环境
要使用Java API操作HDFS,需要搭建以下实验环境:
安装Java Development Kit (JDK):首先需要安装JDK,建议使用Java 8或更高版本。
安装Hadoop:在本地或远程服务器上安装Hadoop。可以从Hadoop官方网站下载最新版本的Hadoop,并按照官方文档进行安装和配置。
设置Hadoop环境变量:将Hadoop的安装路径添加到系统的环境变量中,以便Java程序能够找到Hadoop的相关依赖库和配置文件。
引入Hadoop依赖:在Java项目中,需要引入Hadoop的相关依赖,包括hadoop-common、hadoop-hdfs等依赖。可以使用Maven或Gradle等构建工具来管理依赖。
编写Java代码:使用Java编写代码,通过Hadoop提供的Java API来操作HDFS。在代码中需要配置Hadoop的相关参数,如HDFS的URL、配置文件路径等。
编译和运行Java程序:使用Java编译器将Java代码编译成字节码文件,然后使用Java虚拟机(JVM)运行编译后的字节码文件。
在实验环境搭建完成后,就可以使用Java API操作HDFS,实现对HDFS文件系统的管理和操作
(3)实验步骤
一.创建Maven项目
首先,打开IDEA,点击新建项目,在左侧中选择Maven,然后直接点击next
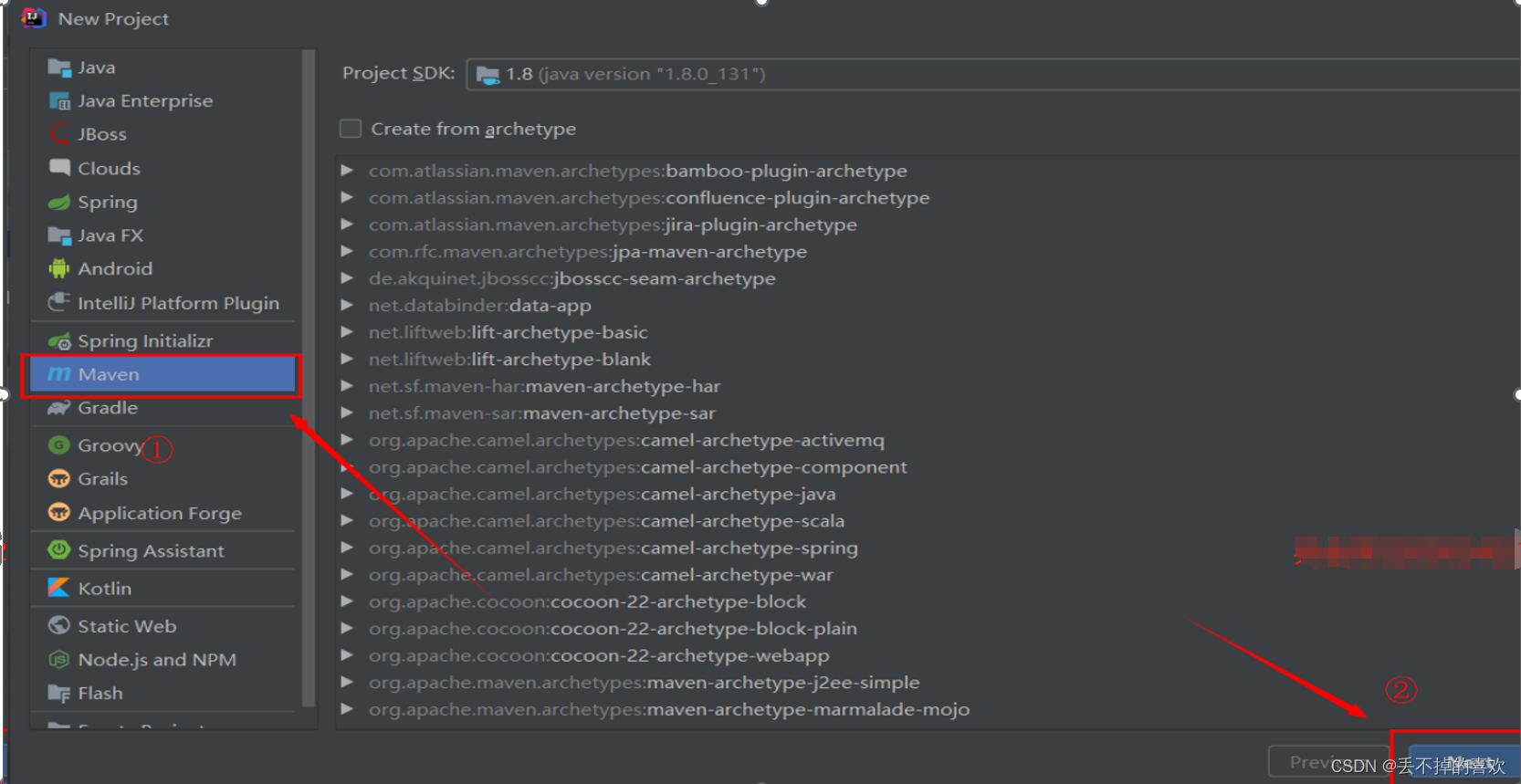
设置项目名称为HadoopDemo,点击Finish
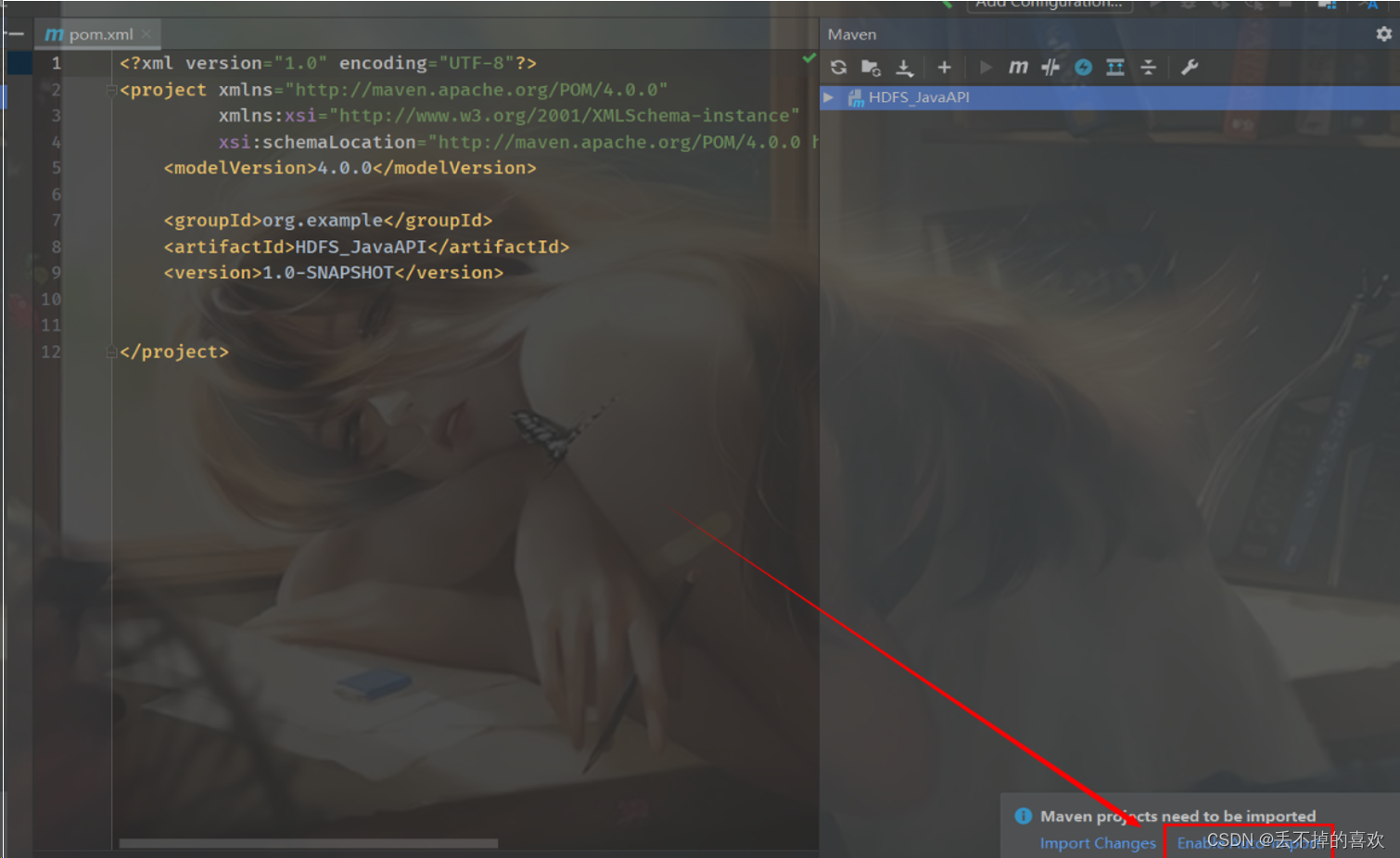
点击右下角的 Enable Auto-Import(自动导入Jar包文件),一个空的Maven项目就创建完毕啦
二、导入依赖
首先编辑pom.xml(Maven项目的核心文件)文件,添加如下内容,导入依赖(所需jar包)
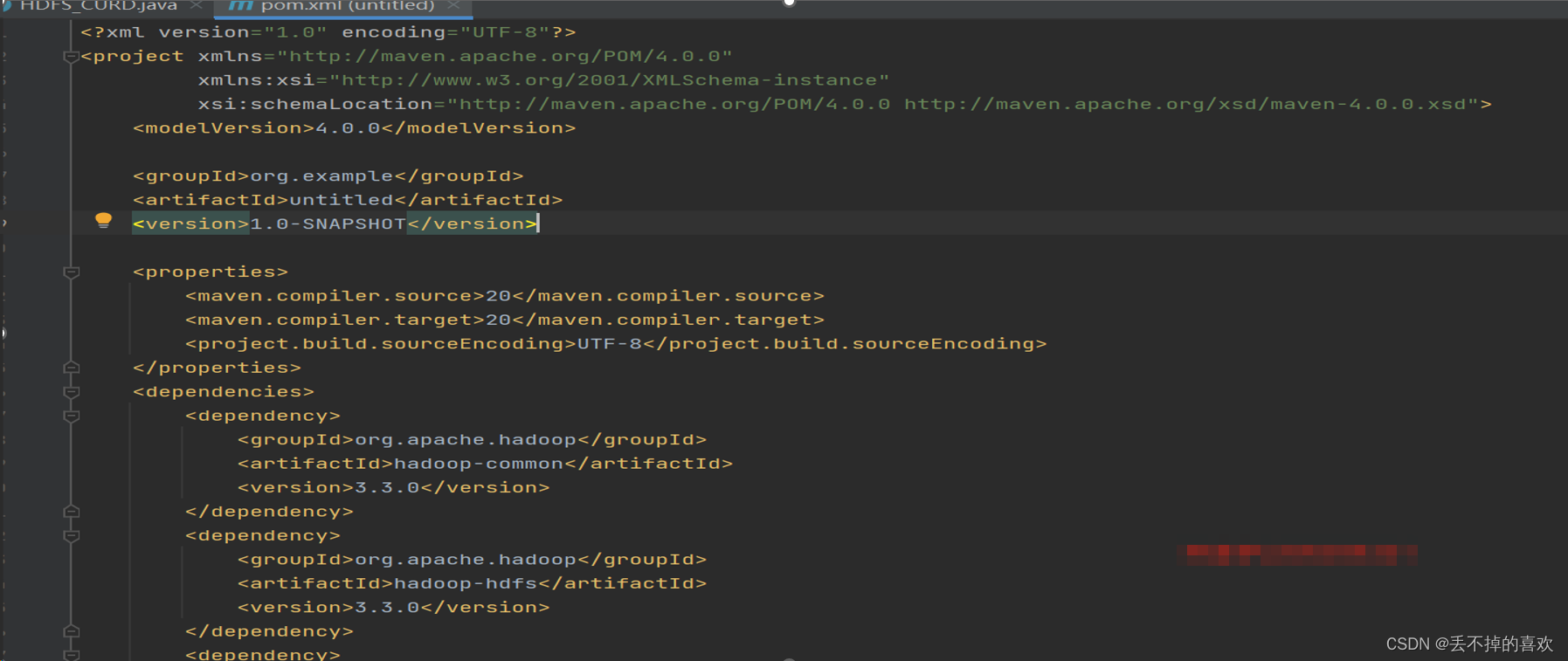
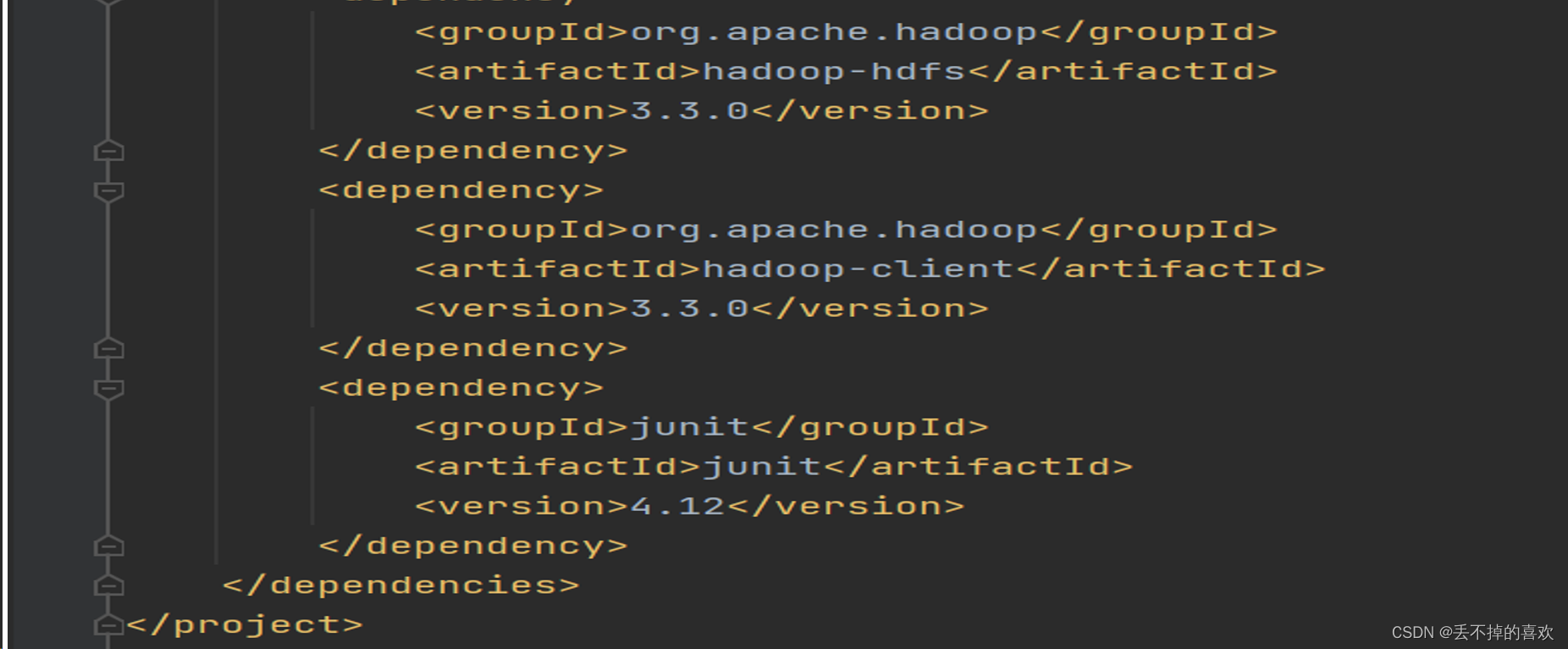
代码显示
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>untitled</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>20</maven.compiler.source>
<maven.compiler.target>20</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
</project>IDEA会自动保存文件并且导入依赖包,点击右侧的Maven,展开Dependencies,可以看到四个依赖包以及导入进来了
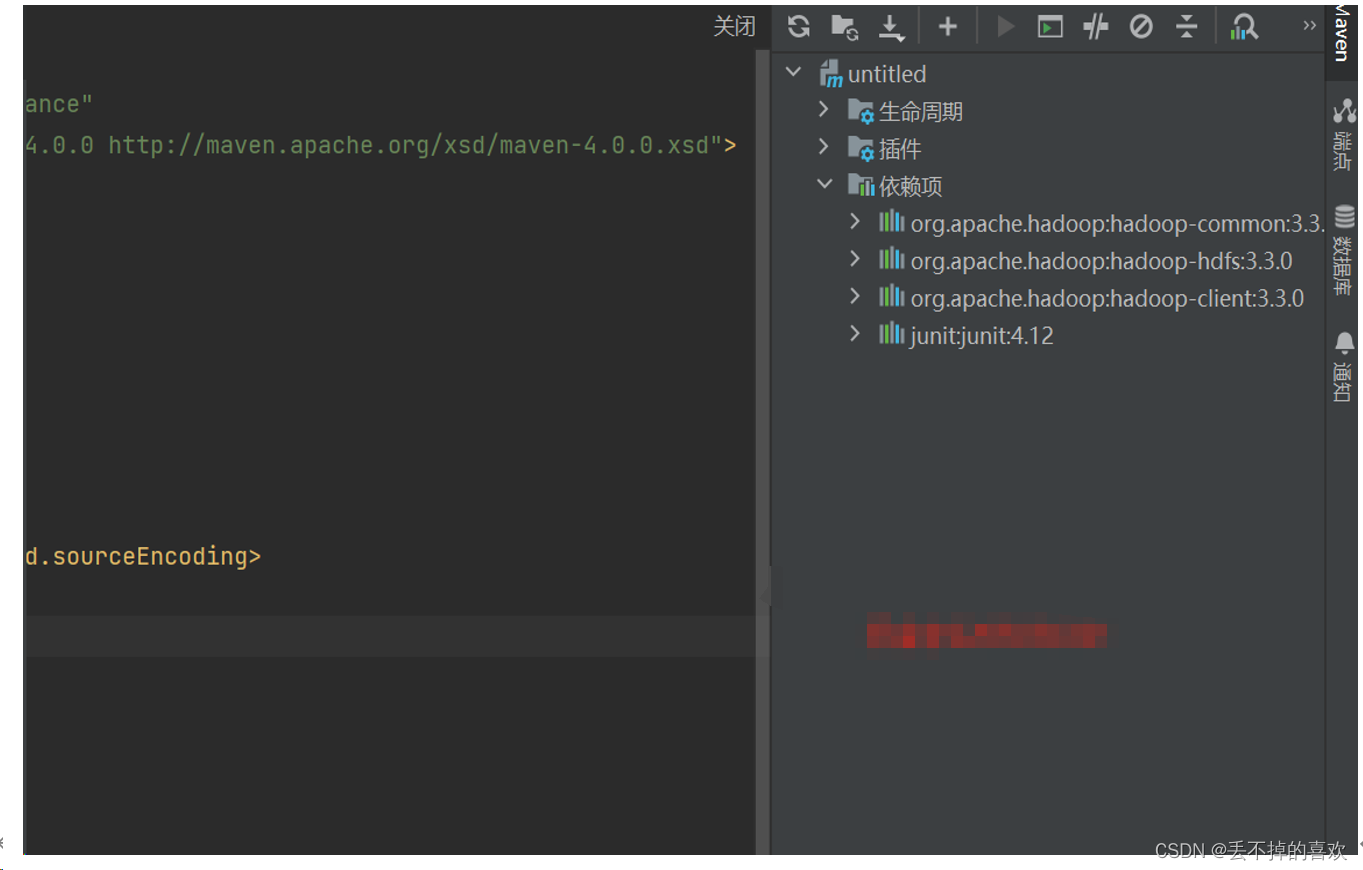
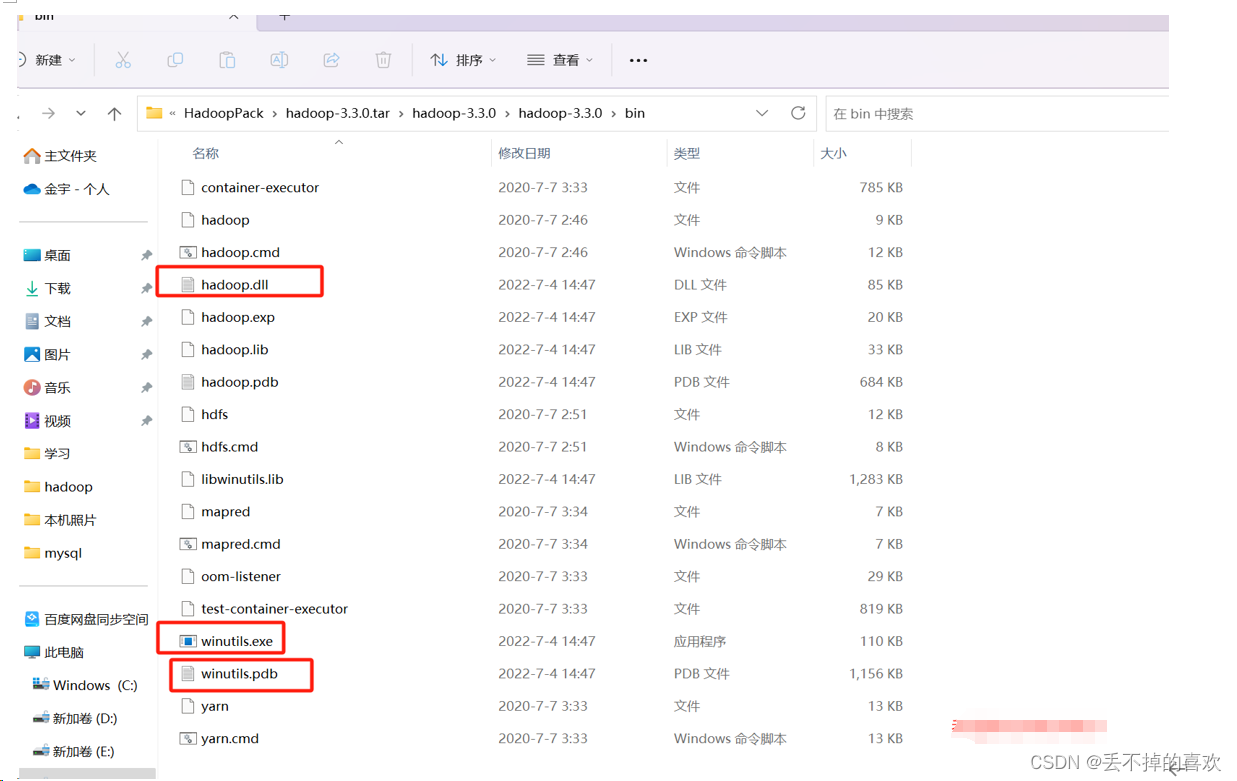
三.在windows中配置Hadoop运行环境
找到下载的hadoop安装包解压后,在Hadoop的安装路径的bin目录下添加winutils.exe,winutils.pdb,Hadoop.dll 文件
下载的Hadoop安装包想要的关注我找我要。
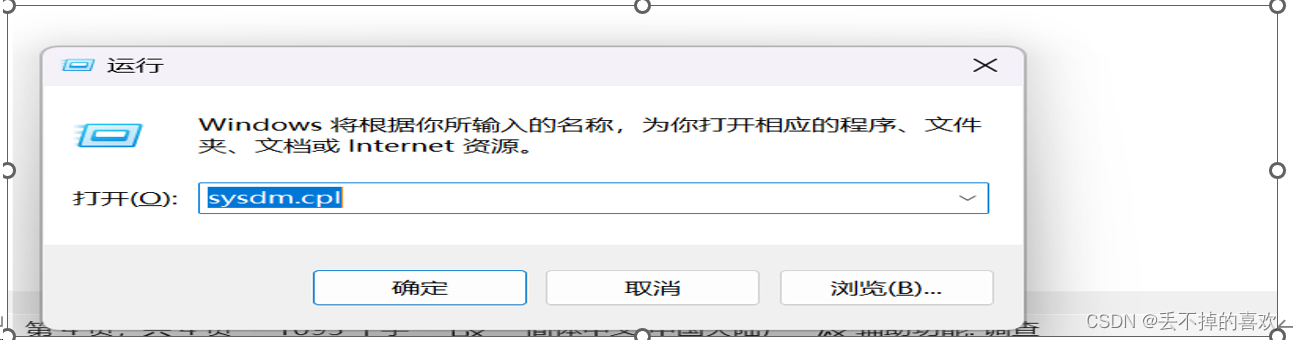
四.配置环境
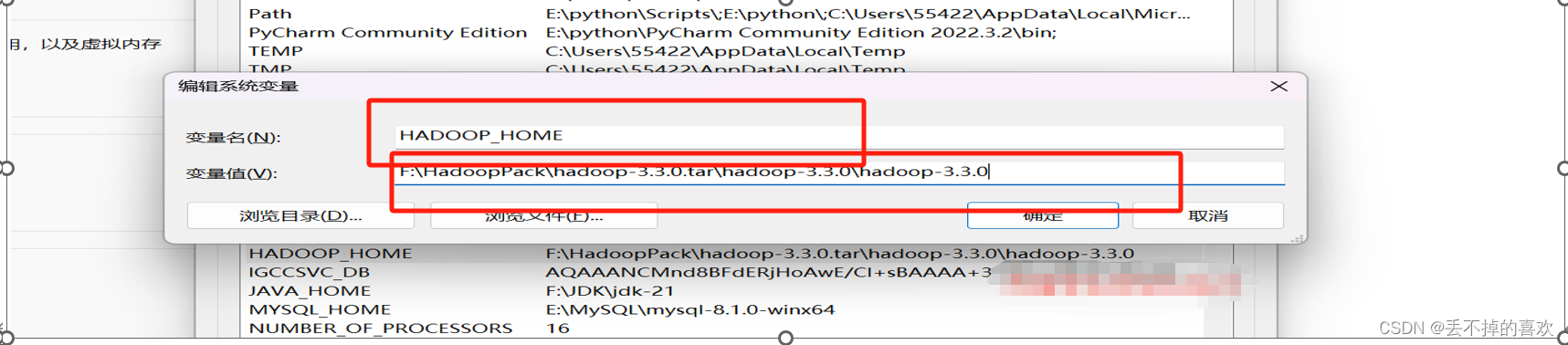
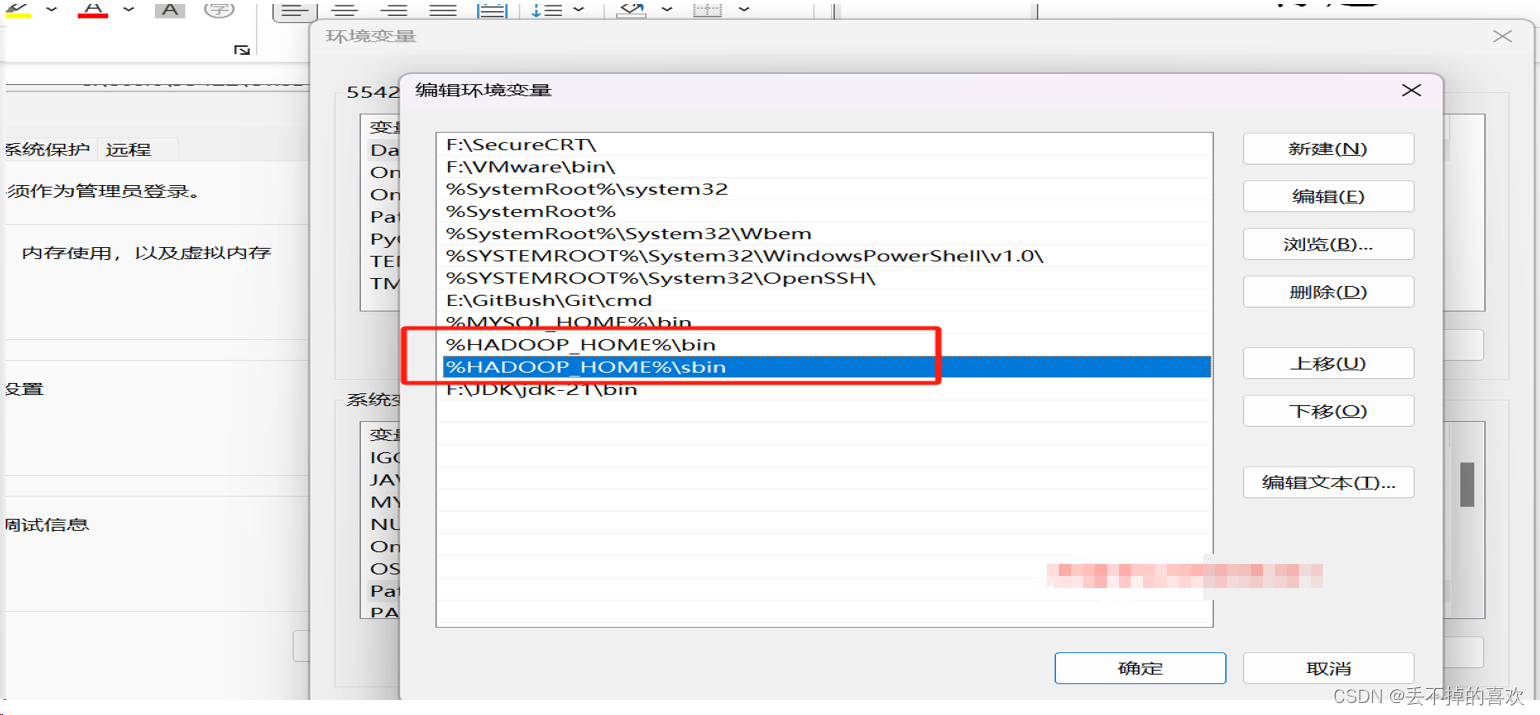
配置成功显示
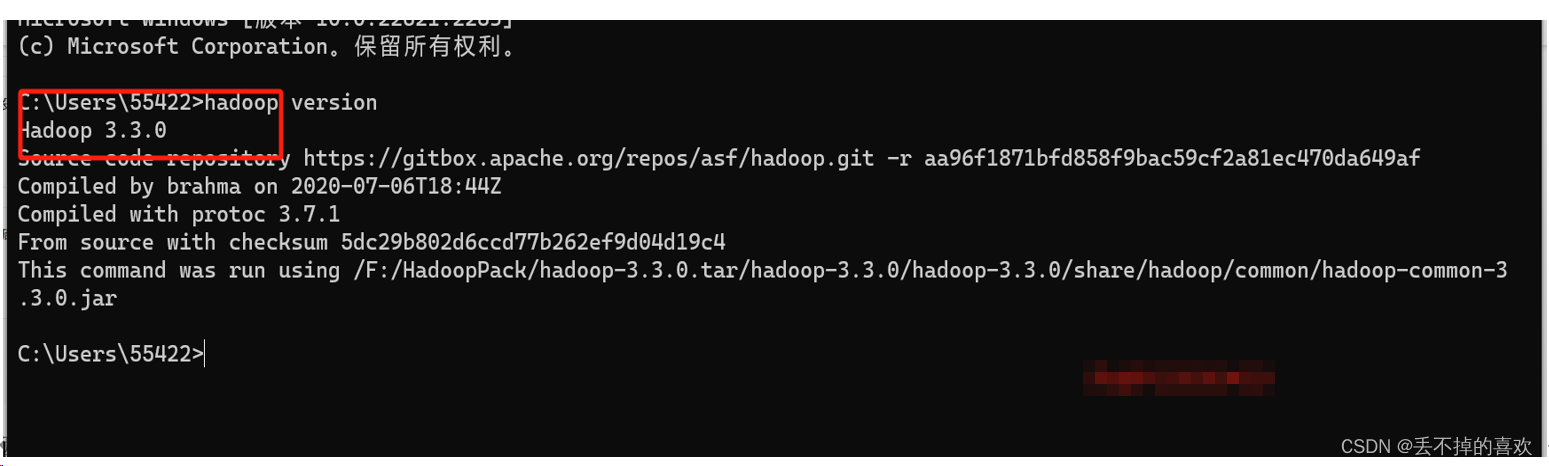
三、初始化
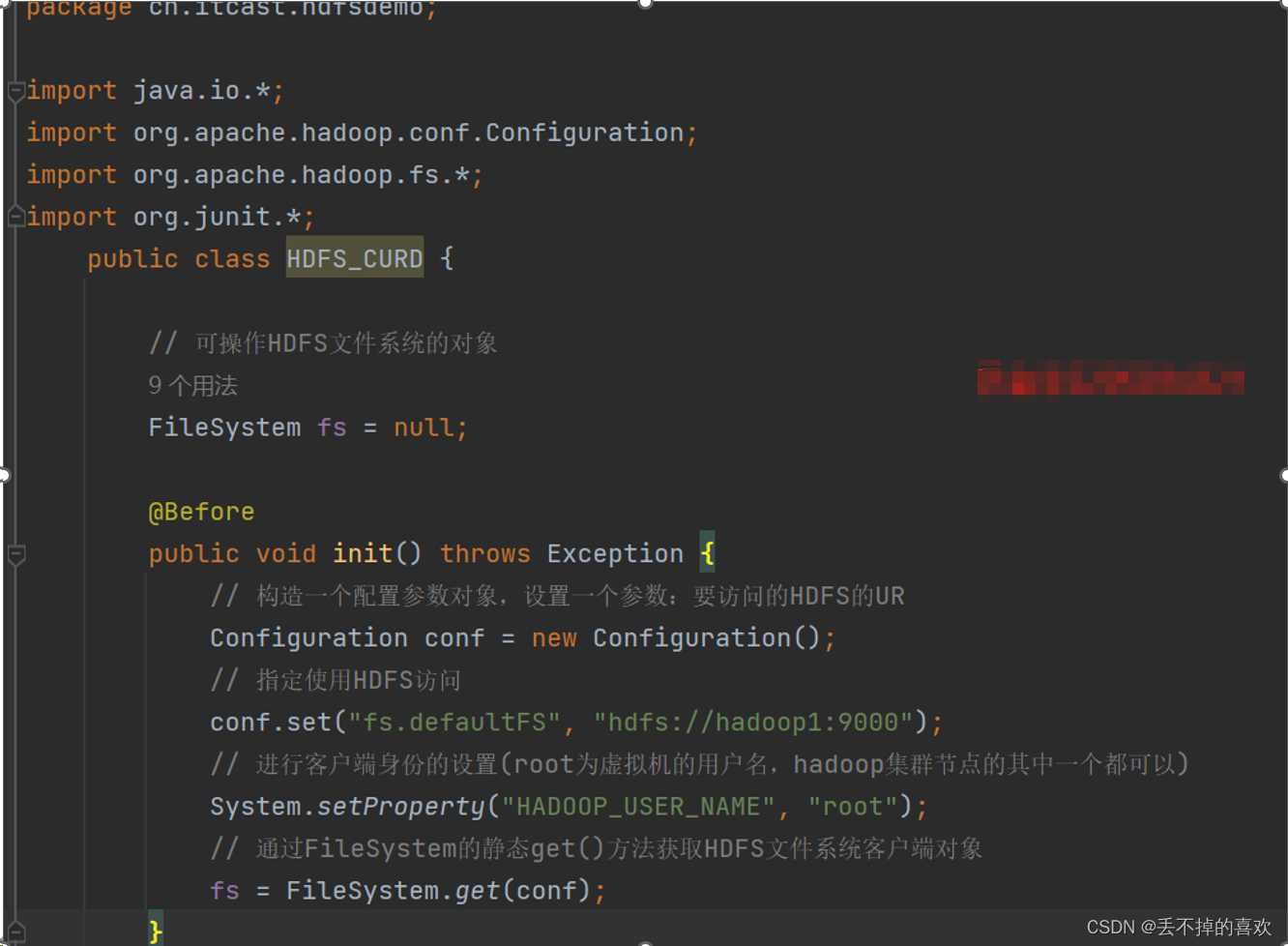
我们通过junit来进行测试,首先创建一个类,添加如下内容
四、HDFS代码操作
(1)上传文件到HDFS文件系统
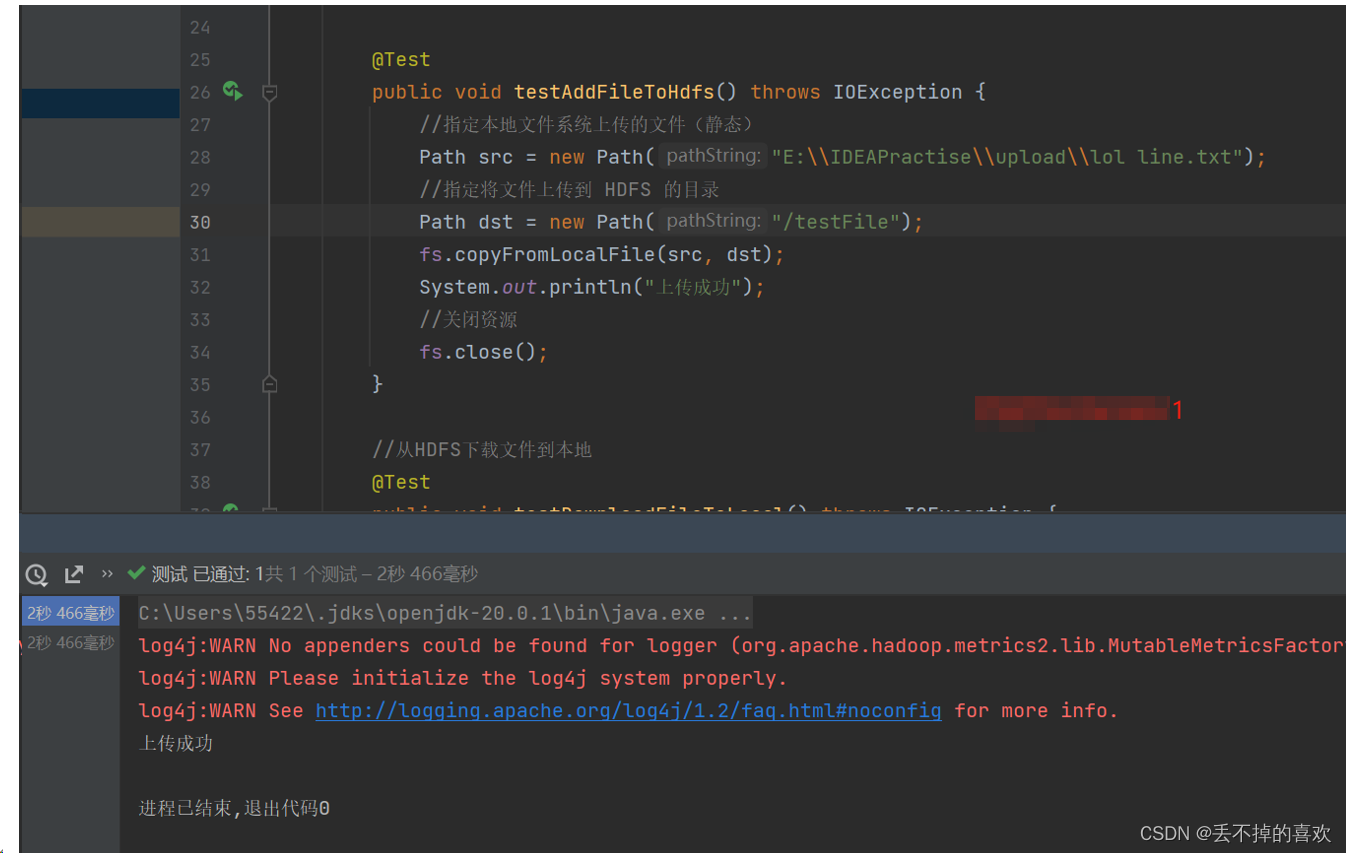
显示成功上传
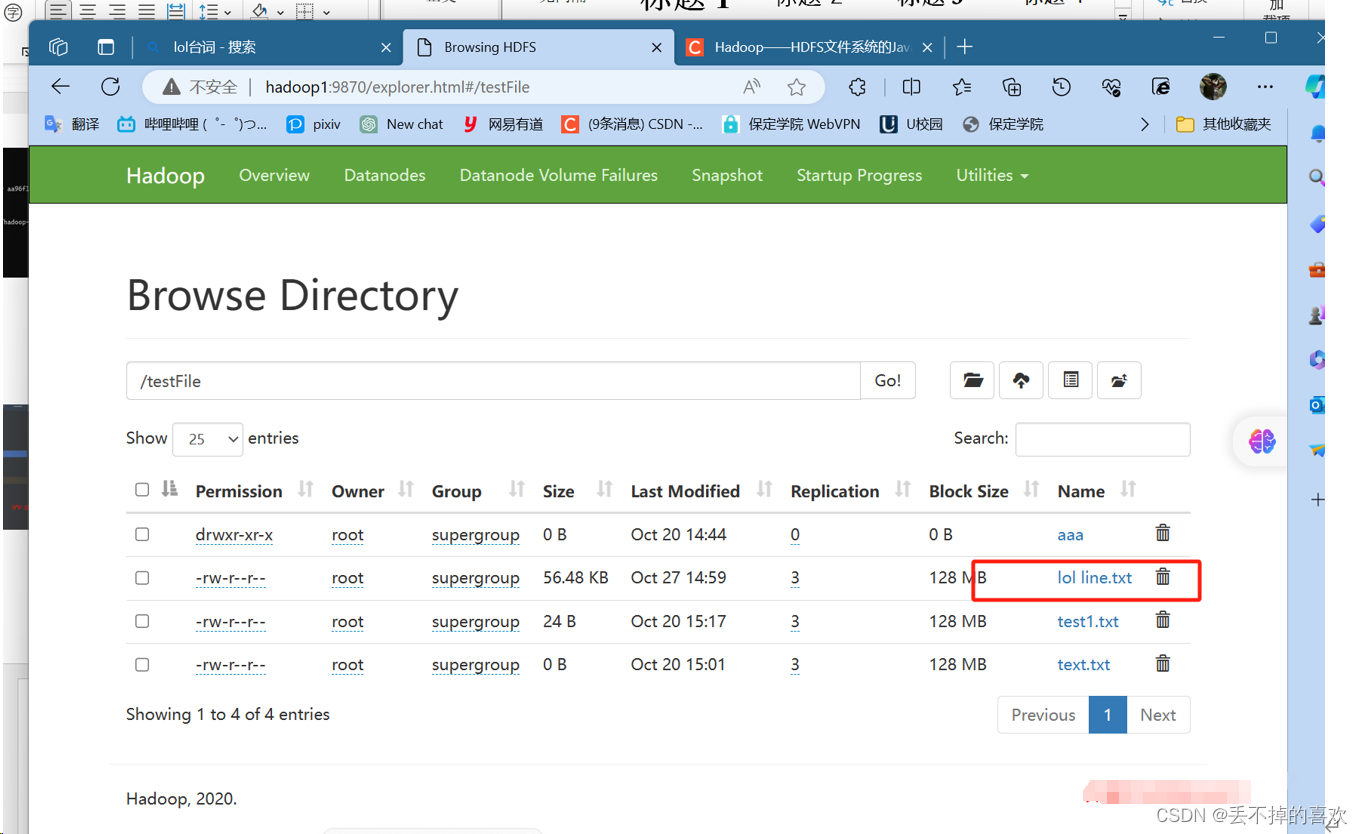
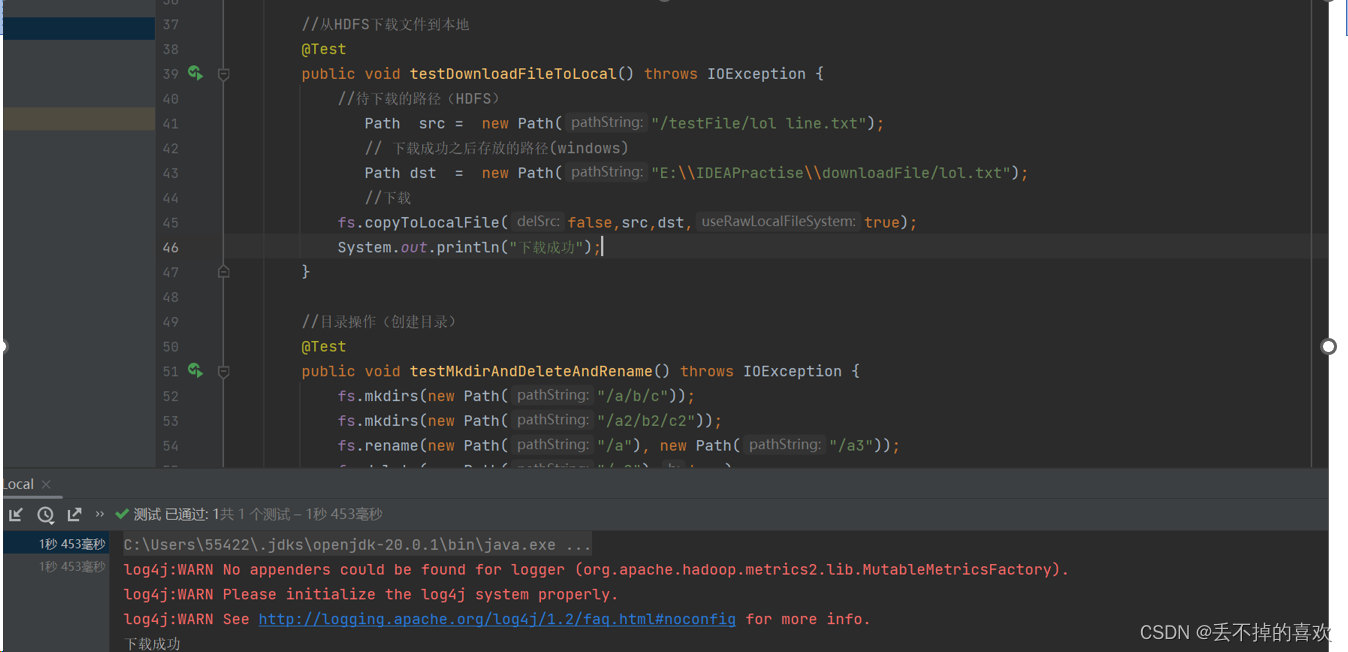
(2)从HDFS下载文件到本地
把刚才传送到HDFS的lol lineTxt文件再传送到电脑上

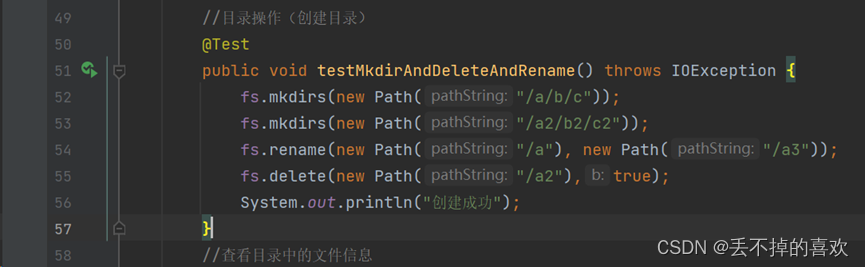
(3)创建目录
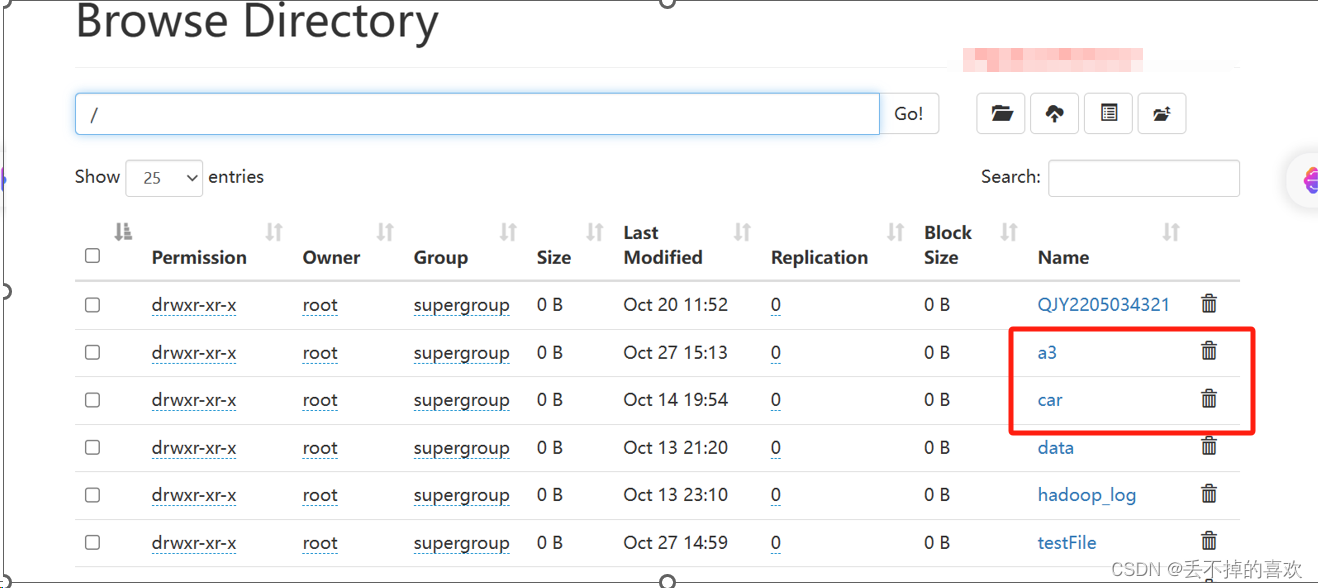
(4)查看HDFS目录中的文件信息
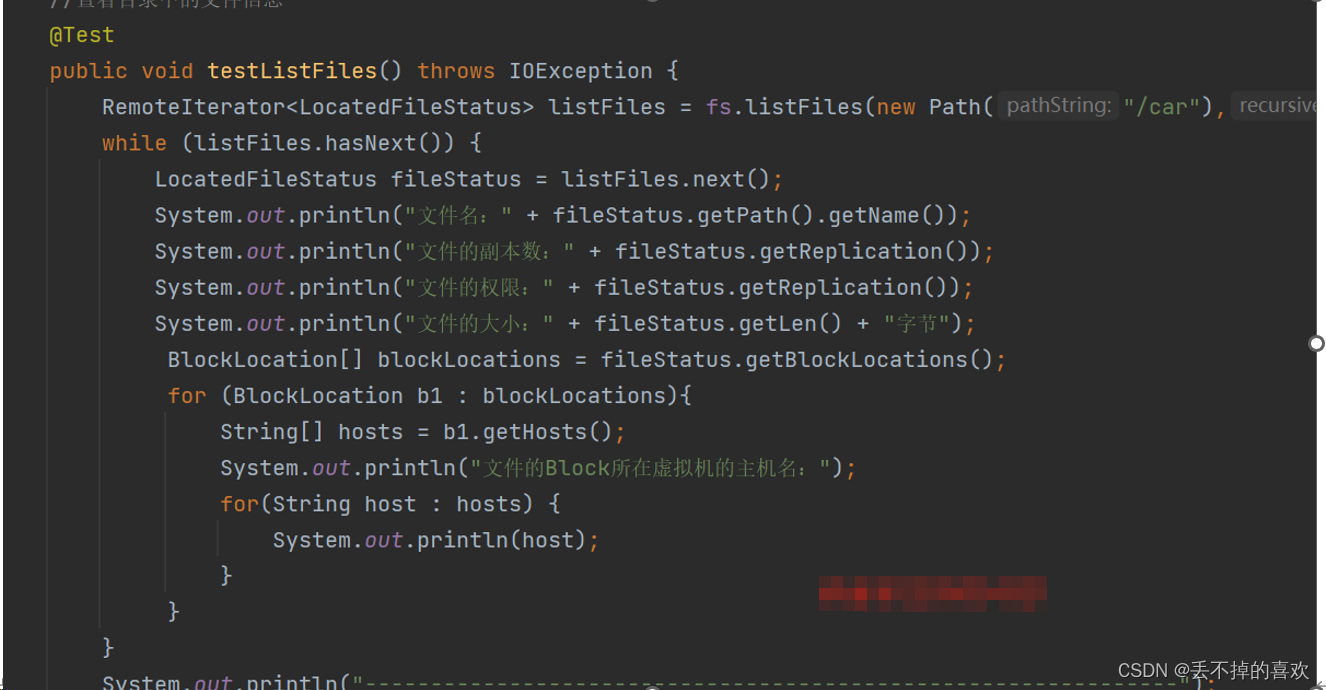
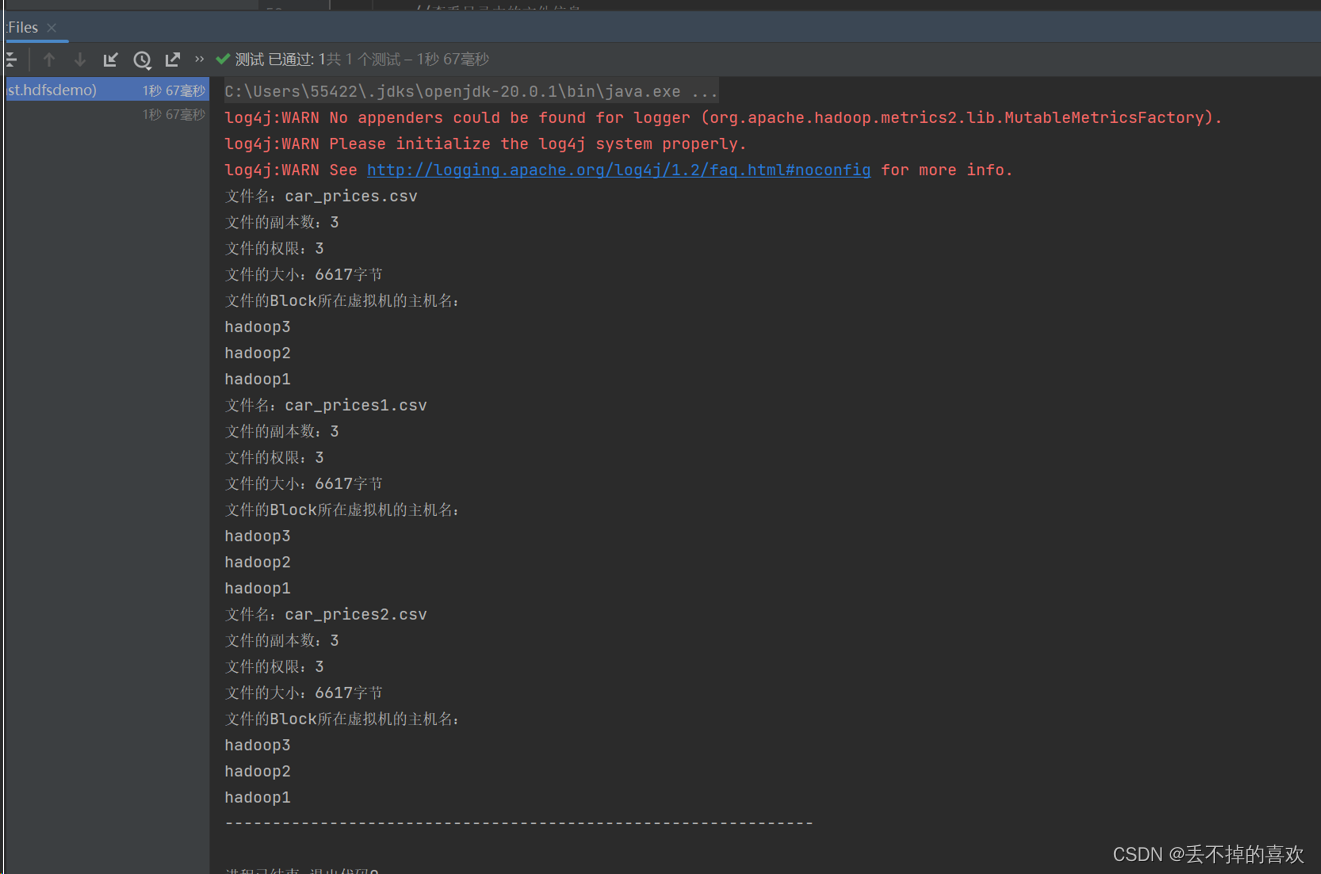
全部代码如下
package cn.itcast.hdfsdemo;
import java.io.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.*;
public class HDFS_CURD {
// 可操作HDFS文件系统的对象
FileSystem fs = null;
@Before
public void init() throws Exception {
// 构造一个配置参数对象,设置一个参数:要访问的HDFS的UR
Configuration conf = new Configuration();
// 指定使用HDFS访问
conf.set("fs.defaultFS", "hdfs://hadoop1:9000");
// 进行客户端身份的设置(root为虚拟机的用户名,hadoop集群节点的其中一个都可以)
System.setProperty("HADOOP_USER_NAME", "root");
// 通过FileSystem的静态get()方法获取HDFS文件系统客户端对象
fs = FileSystem.get(conf);
}
@Test
public void testAddFileToHdfs() throws IOException {
//指定本地文件系统上传的文件(静态)
Path src = new Path("E:\\IDEAPractise\\upload\\lol line.txt");
//指定将文件上传到 HDFS 的目录
Path dst = new Path("/testFile");
fs.copyFromLocalFile(src, dst);
System.out.println("上传成功");
//关闭资源
fs.close();
}
//从HDFS下载文件到本地
@Test
public void testDownloadFileToLocal() throws IOException {
//待下载的路径(HDFS)
Path src = new Path("/testFile/lol line.txt");
// 下载成功之后存放的路径(windows)
Path dst = new Path("E:\\IDEAPractise\\downloadFile/lol.txt");
//下载
fs.copyToLocalFile(false,src,dst,true);
System.out.println("下载成功");
}
//目录操作(创建目录)
@Test
public void testMkdirAndDeleteAndRename() throws IOException {
fs.mkdirs(new Path("/a/b/c"));
fs.mkdirs(new Path("/a2/b2/c2"));
fs.rename(new Path("/a"), new Path("/a3"));
fs.delete(new Path("/a2"),true);
System.out.println("创建成功");
}
//查看目录中的文件信息
@Test
public void testListFiles() throws IOException {
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/car"),true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("文件名:" + fileStatus.getPath().getName());
System.out.println("文件的副本数:" + fileStatus.getReplication());
System.out.println("文件的权限:" + fileStatus.getReplication());
System.out.println("文件的大小:" + fileStatus.getLen() + "字节");
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation b1 : blockLocations){
String[] hosts = b1.getHosts();
System.out.println("文件的Block所在虚拟机的主机名:");
for(String host : hosts) {
System.out.println(host);
}
}
}
System.out.println("--------------------------------------------------------------");
}
}

















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









