







paper: Squeeze-and-Excitation Networks
paper link:https://arxiv.org/pdf/1709.01507.pdf
repo link:GitHub - hujie-frank/SENet: Squeeze-and-Excitation Networks
摘要:
卷积神经网络(CNNs)的核心构建块是卷积算子,它使网络能够通过融合每层局部感受野内的空间和通道信息来构建信息特征。广泛的先前研究已经调查了这种关系的空间分量,试图通过提高整个特征层次的空间编码质量来增强CNN的代表能力。在这项工作中,我们转而关注通道关系,并提出了一种新的架构单元,我们称之为“Squeeze-and-Excitation”(SE)块,通过显式建模通道之间的相互依赖性,自适应地重新校准通道特征响应。我们展示了这些块可以堆叠在一起形成SENet架构,该架构在不同的数据集之间非常有效地进行推广。我们进一步证明,SE块在略微增加计算成本的情况下,为现有最先进的细胞神经网络带来了显著的性能改进。
核心:SE块可以和其他框架直接组合使用
SE块:
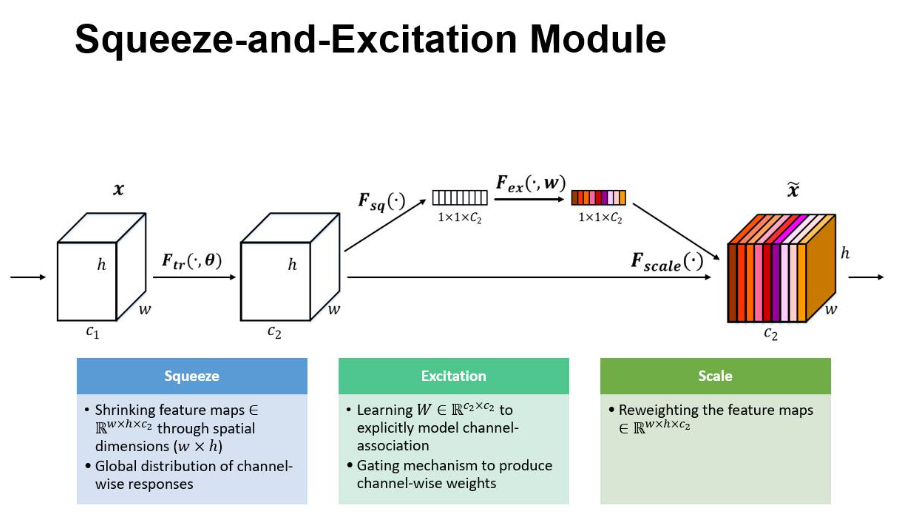
Inception中加入SE模块

ResNet加入SE块

在resnet50中加入SE块模块
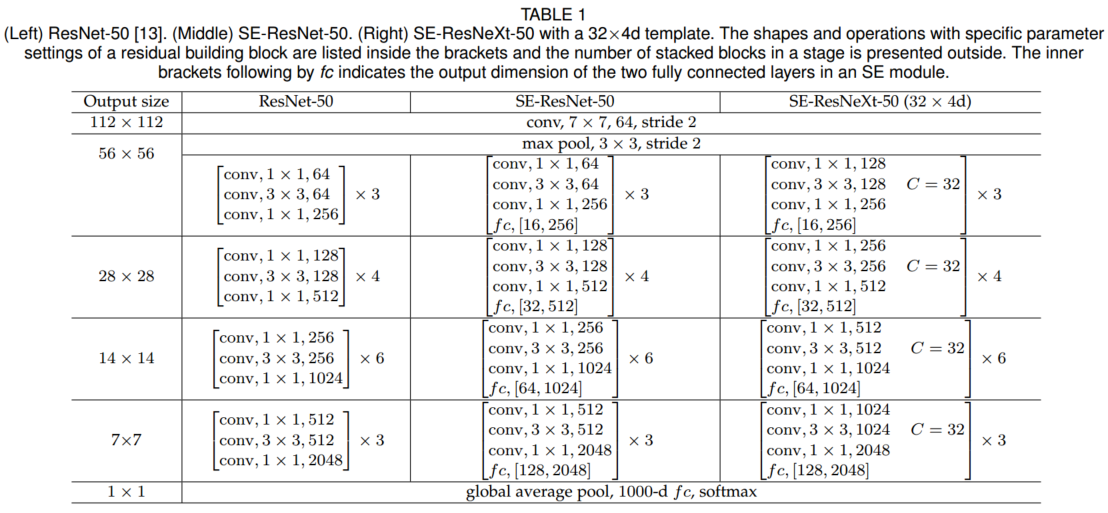
性能对比


SE_code:
class SENet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(SENet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x














 2704
2704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









