







文章目录
手把手教你部署K210本地Mx_yolov3环境(最新)
一、下载软件
import 创客连接
链接:https://pan.baidu.com/s/1Gl3Qfw5s8LZuu2wc1GTITg 提取码:dvsf
4.0.0更新信息(2023/4/3)
非常感谢大佬的软件,让小白部署本地环境方便了很多
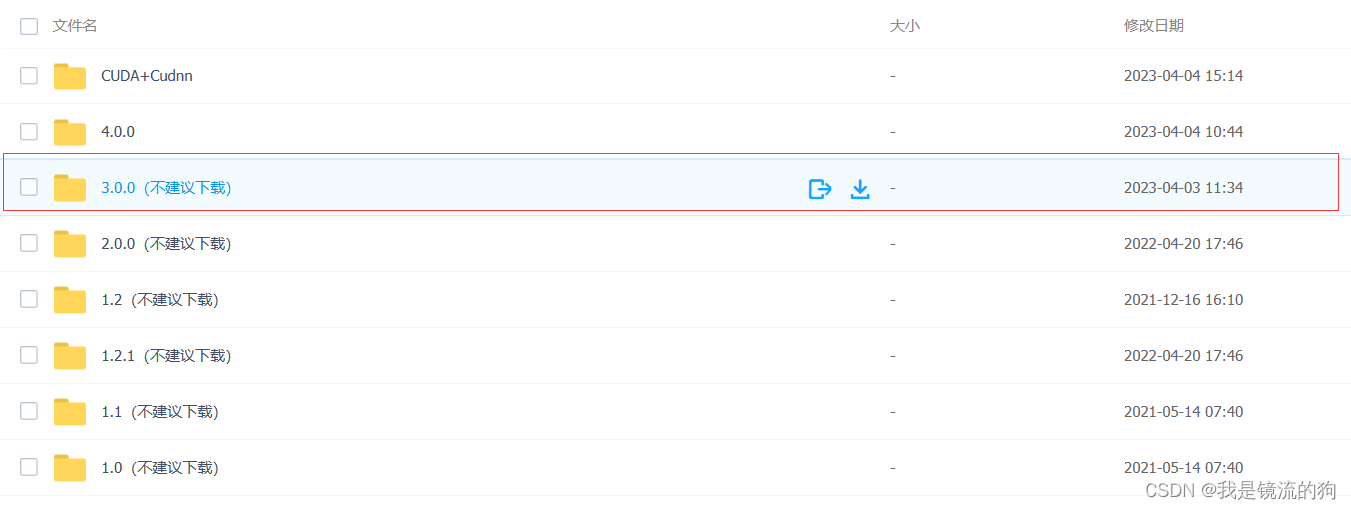
下载3.0版本,因为该版本不需要配置环境
下载好直接安装就行,不需要再搭建其他环境,如果想使用GPU训练模型,请往下看
二、下载CUDA和安装
(一)下载
CUDA:https://developer.nvidia.com/cuda-downloads
(这网站登上去很慢,可以使用梯子登上去)
1.首先登上网站后是最新版本的CUDA,但是Mx_yolov3 3.0并不支持CUDA12,所以我们需要下载CUDA11版本(这里我替大家试过了,真不行)
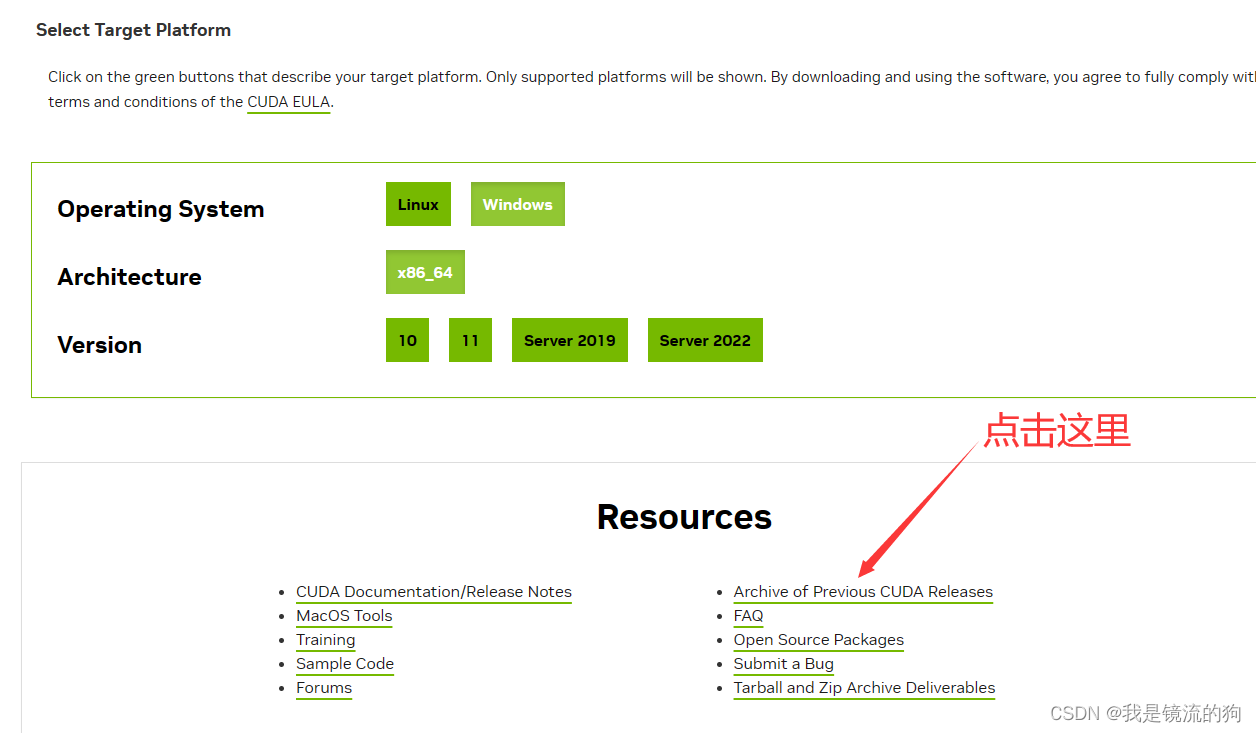
注意:点进去后请关闭浏览器的自动翻译功能,因为很可能因为浏览器的自动翻译而找不到下载11版本的超链接

比如这样,就丢失了一部分版本的超链接下载。
如果是Edge浏览器可以点击地址栏进行显示原文
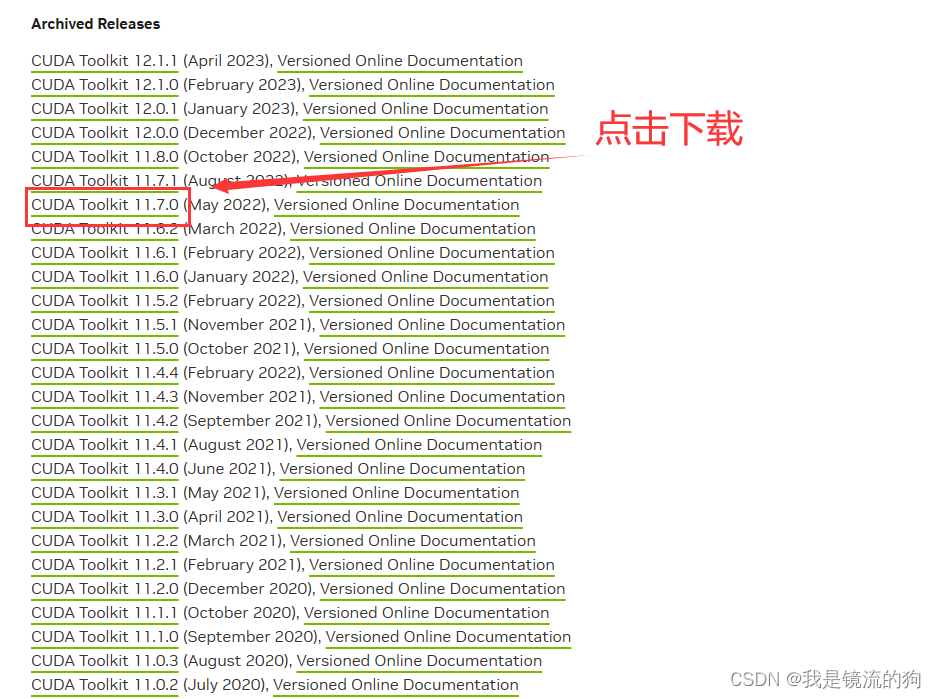
如图所示,点击下载即可(这里我试过11.7和11.6版本的,这两个版本都行,其他版本我尚未试过,不过根据import 创客对Mx_yolov3 2.0版本更新所说,在2.0版本时就已经支持CUDA11.2版本及以上了,想必Mx_yolov3 3.0也同样如此)
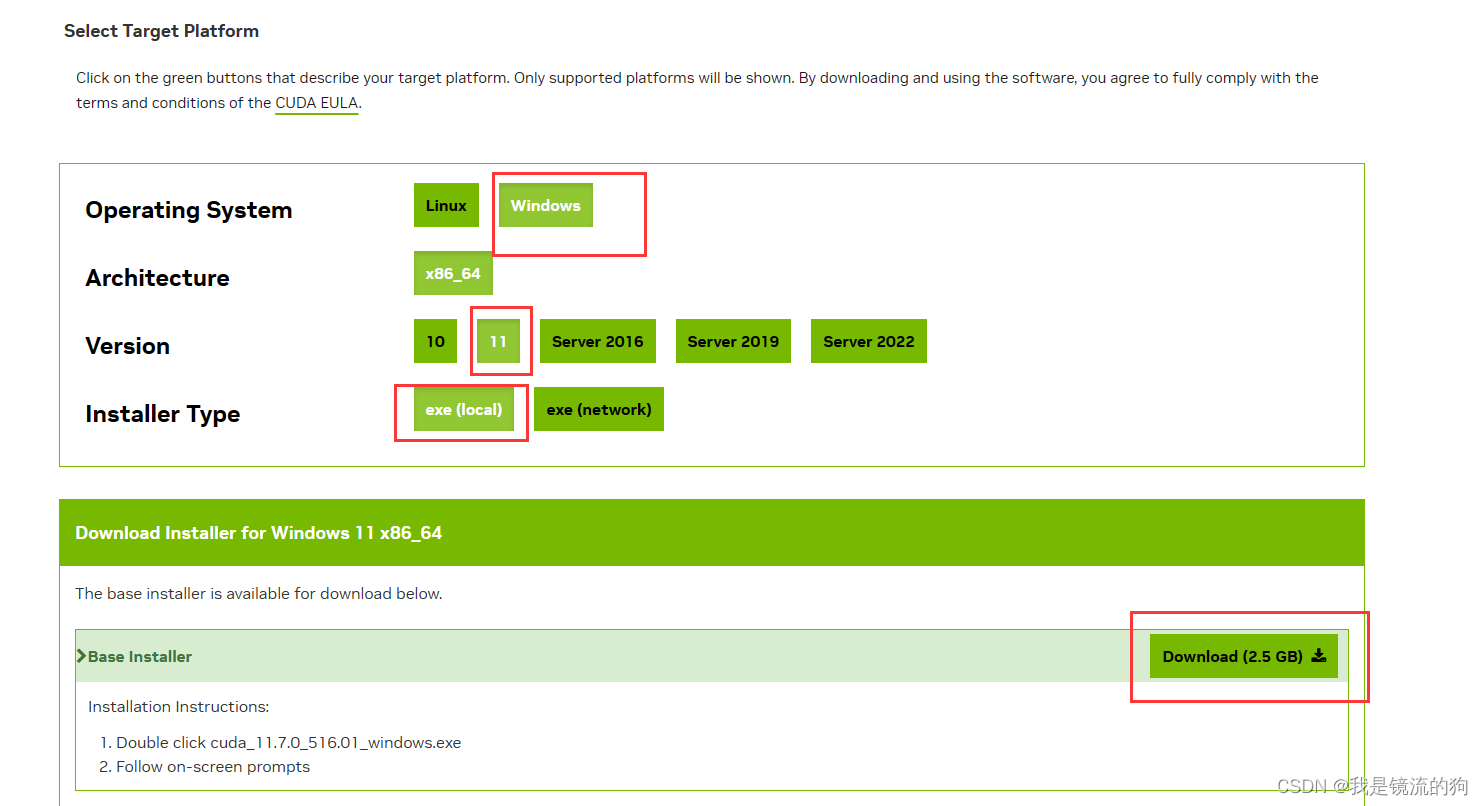
然后根据自己的系统下载即可
(二)安装
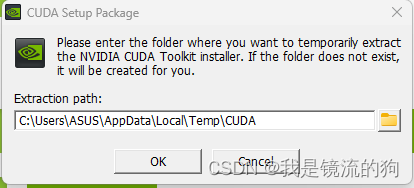
选择默认路径即可,想安装到其他地方的,请一定要记住安装路径,因为后面会用到
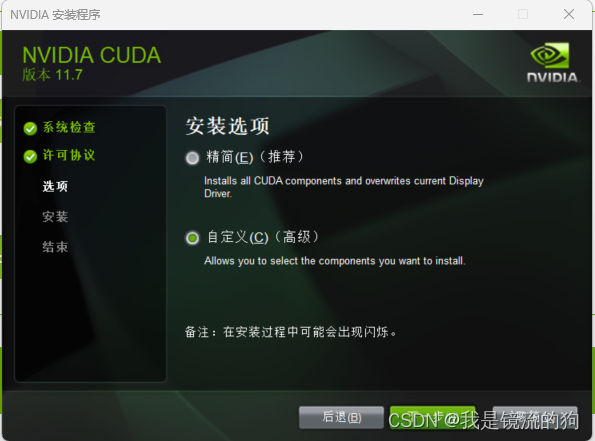
选择自定义安装,因为选择精简安装会把全家桶下载下来
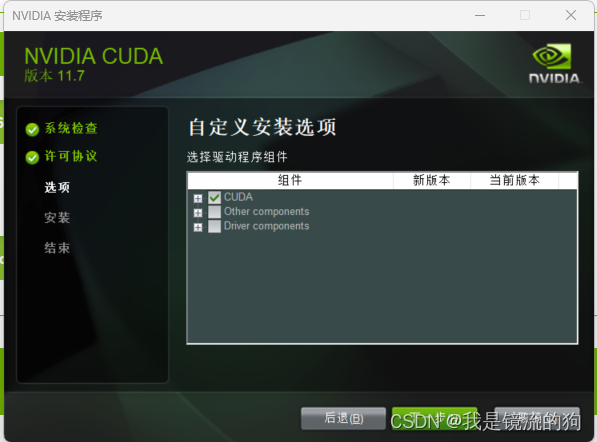
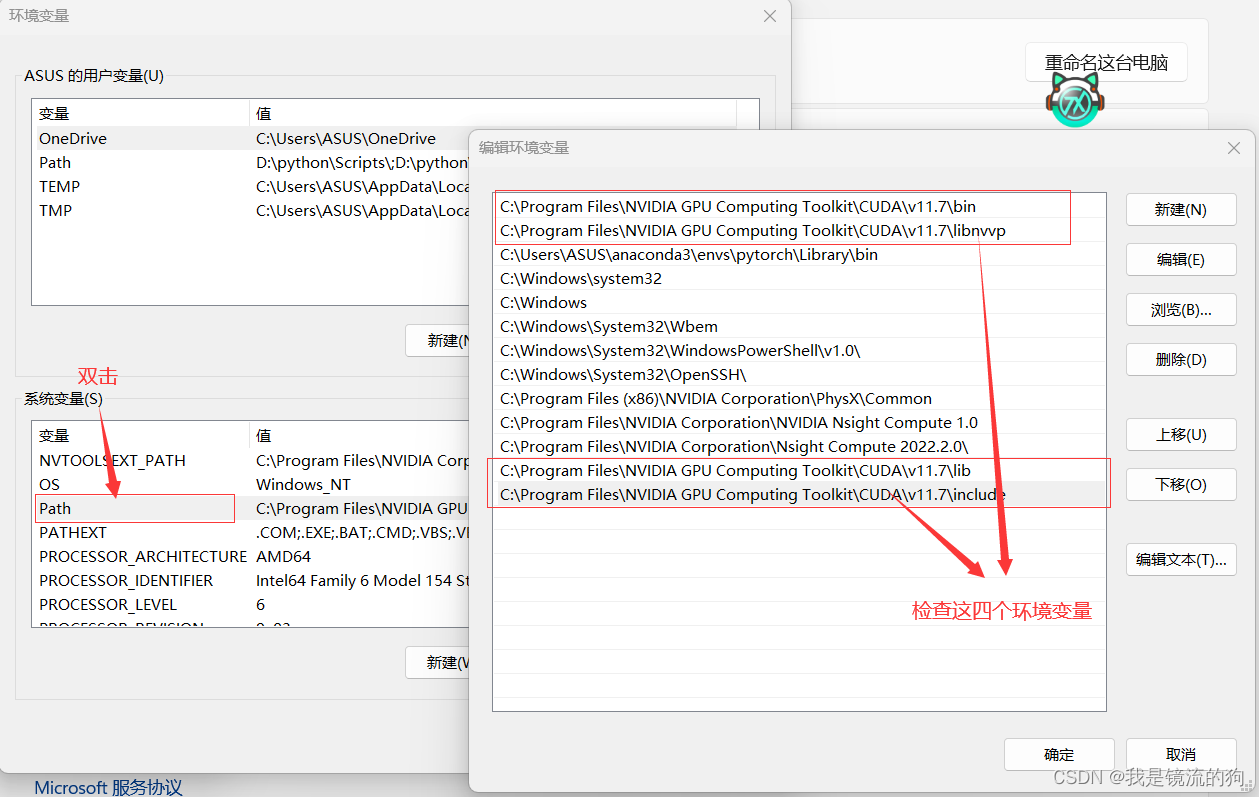
只选择CUDA即可,然后就是一路默认安装就行。完成后检查下是否增加了环境变量(我的电脑->右键属性->高级系统设置->环境变量)
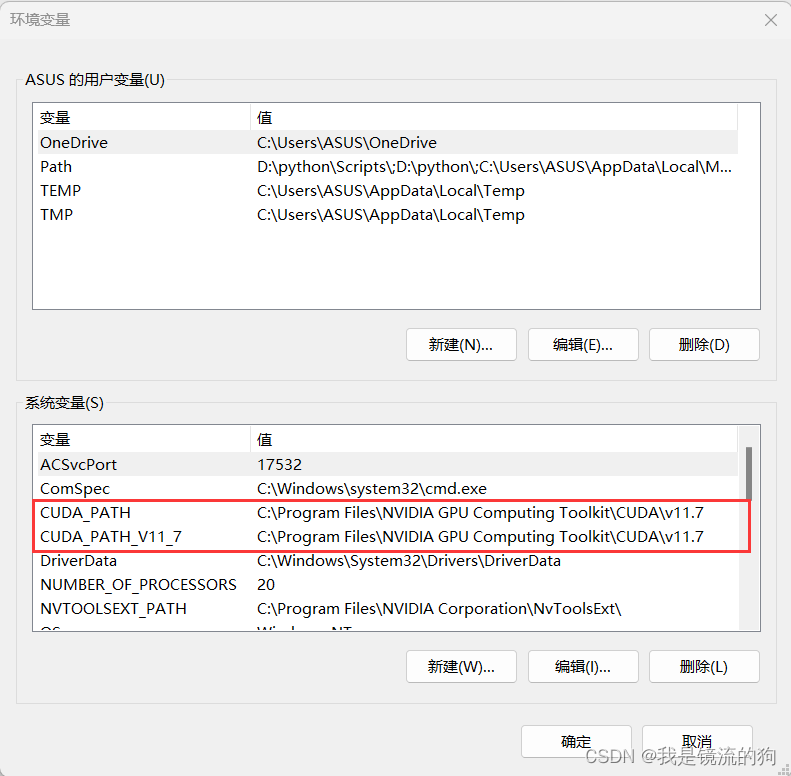
最后打开cmd检查自己有没有安装
nvcc --version
nvcc -V
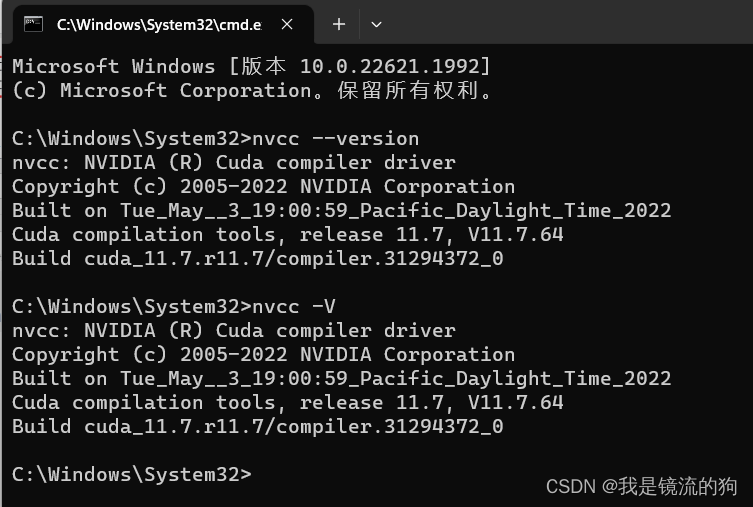
看到版本信息就算成功
三、cuDNN下载与安装
(一)下载
cuDNN:https://developer.nvidia.com/rdp/cudnn-download
下载cuDNN时需要注册一个账号,根据流程走完就可以下载了
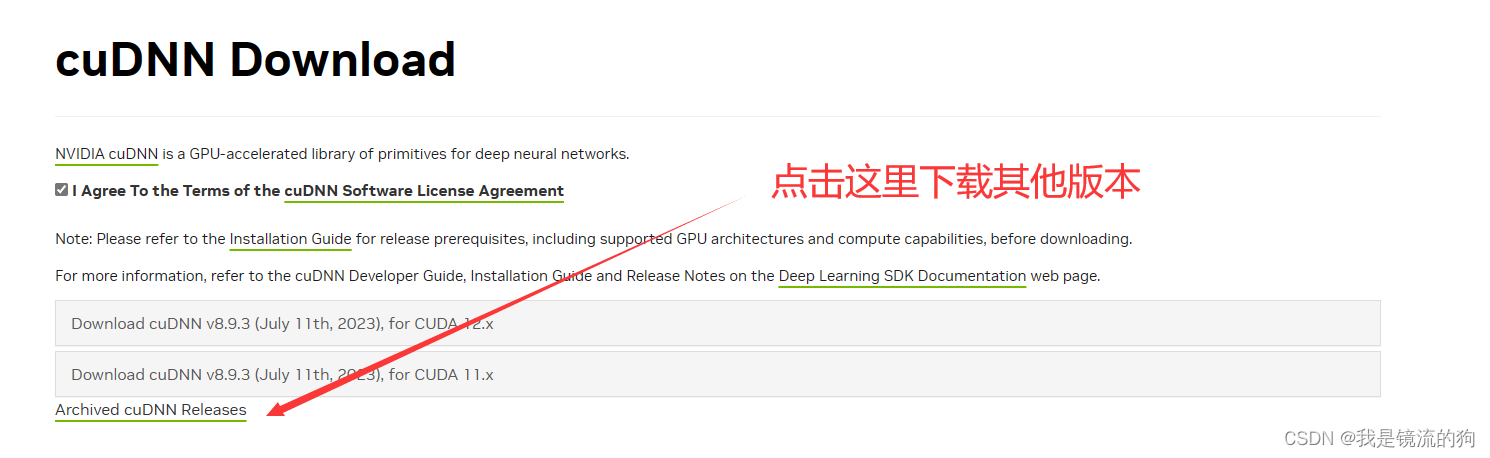
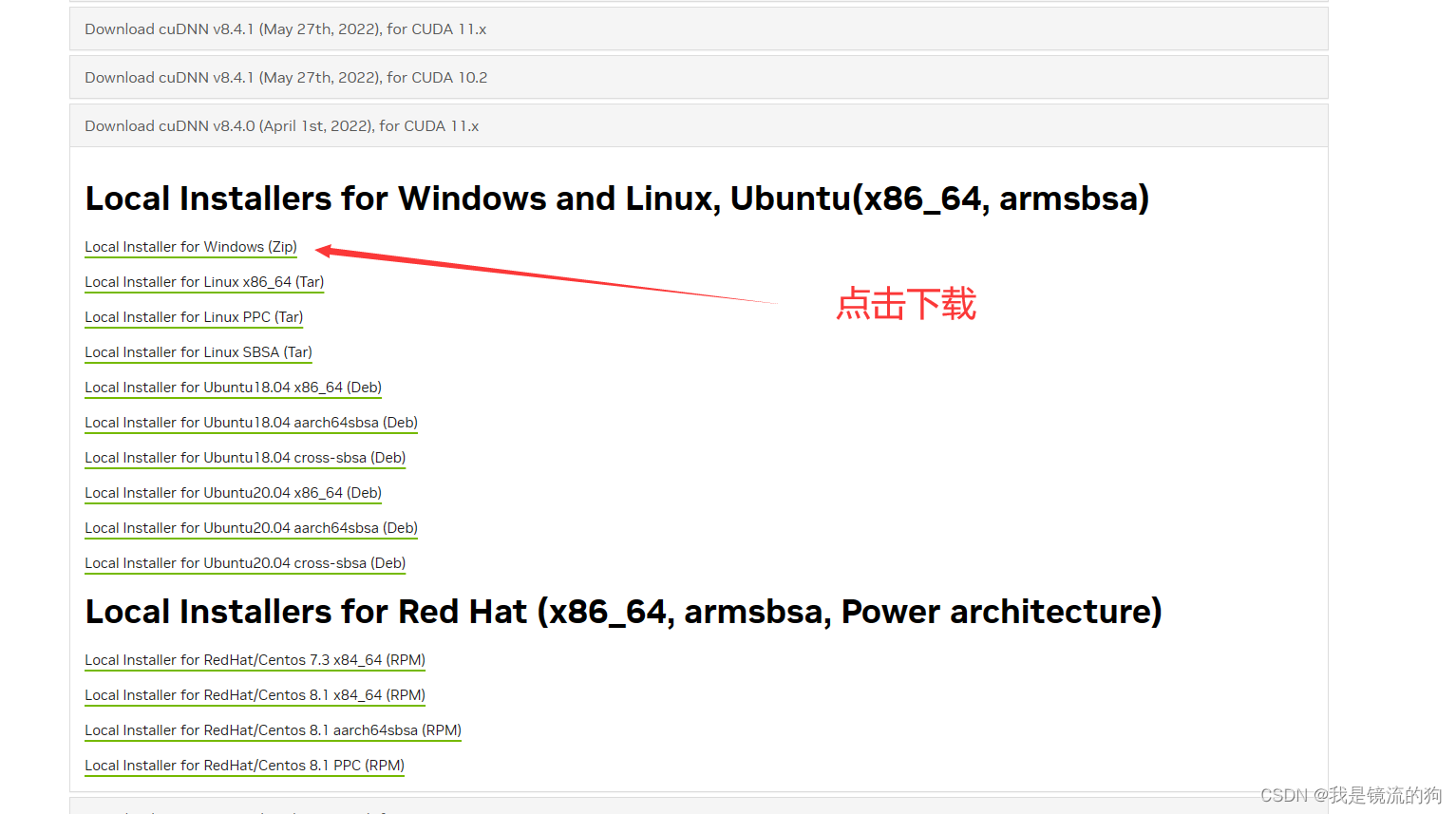
根据自己的系统下载即可,我这里是Windows
注意:下载cuDNN时要根据CUDA版本下载,就是下载以for CUDA 11.x结尾的版本
解压后把bin、lib、include三个文件夹复制到这个路径下。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7
(这是刚刚CUDA默认下载的路径,如果你更改了CUDA的默认路径,放到该路径即可)
最后添加环境变量,对比我的看看哪个少了就添加哪个就行
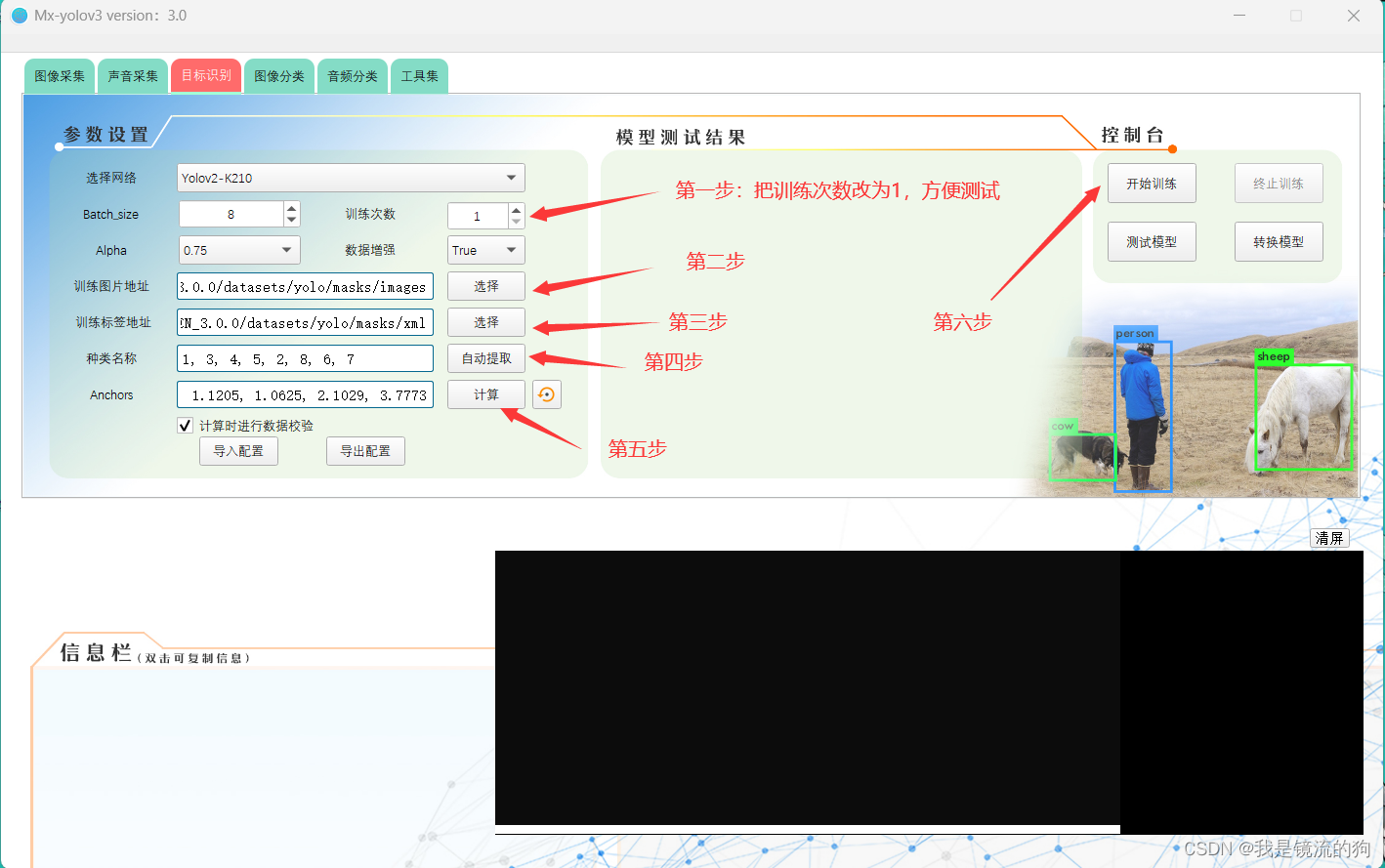
四、测试Mx_yolov3
先不要急着训练模型,先使用软件自带的历程测试一下能不能使用
训练图片地址选择:D:\mx-yolov3\Mx-yolov3_EN_3.0.0\datasets\yolo\masks\images
训练标签地址选择:D:\mx-yolov3\Mx-yolov3_EN_3.0.0\datasets\yolo\masks\xml
(根据自己安装的Mx_yolov3路径来定)
PS:如果打开Mx——yolov3时终端和软件分别为两个画面,使用管理员身份运行即可
(1)运行Mx_yolov3报错Could not locate zlibwapi.dll
下载该文件并配置
下载地址:http://www.winimage.com/zLibDll/
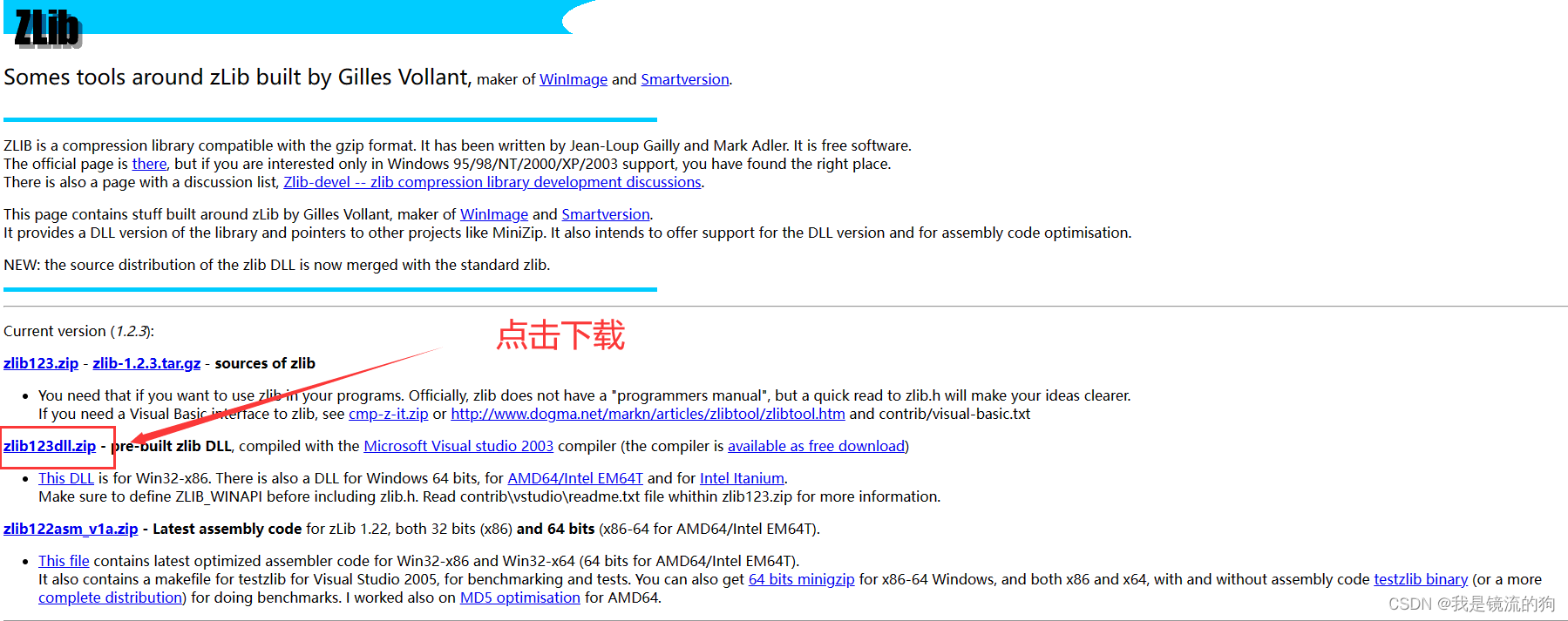
解压后把
zlibwapi.lib 复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib
zlibwapi.dll 复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\bin
再次运行就可以了

如果这里出现该条语句就说明正在使用GPU训练了
当然我这里也有一个报错,但并不影响使用
2023-07-21 17:49:42.703443: W tensorflow/stream_executor/gpu/redzone_allocator.cc:314] INTERNAL: ptxas exited with non-zero error code -1, output:
Relying on driver to perform ptx compilation.
Modify $PATH to customize ptxas location.
This message will be only logged once.
希望大佬看到后教我如何解决,十分感谢
训练结束前会弹出一个窗口,把他叉掉不久就会提示训练结束,然后弹出模型文件
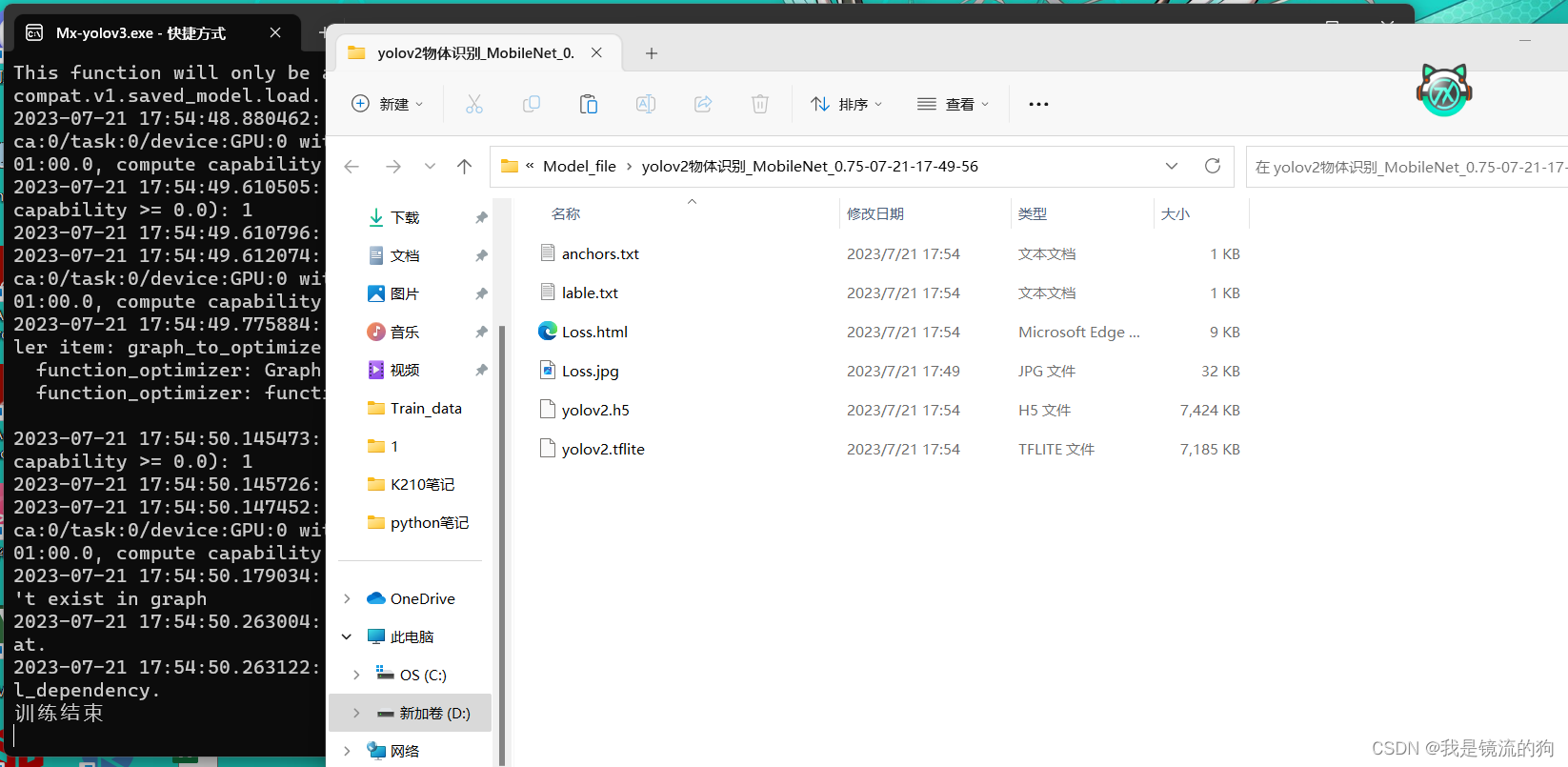
如果到这一步,说明你的本地环境就部署结束啦。(★,°:.☆( ̄▽ ̄)/$:.°★ 撒花)
五、使用Mx_yolov3训练自己的模型
(一)采集图片
方法一:使用MaixHub采集图片(强烈推荐)
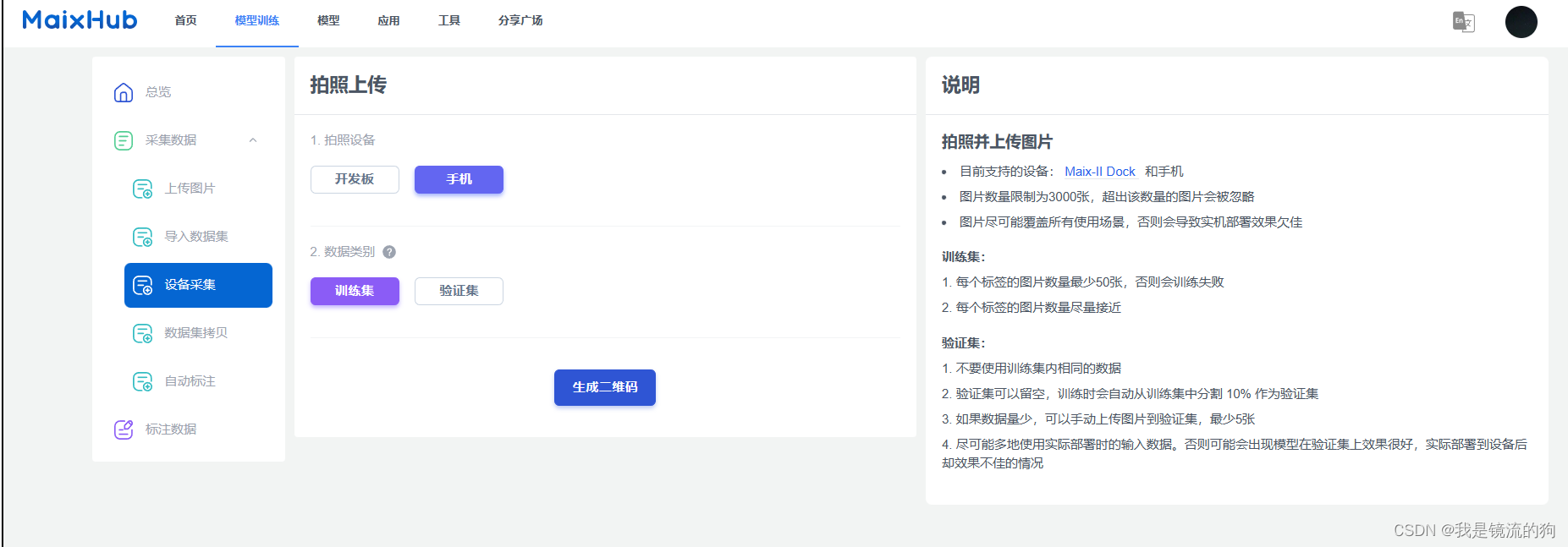
这个网站采集图片十分方便,而且使用手机采集的图片是320*320格式的,直接上传到网站,采集完下载即可,在后续的图片格式转换时,转换的效果特别好
唯一缺点:一天内下载图片为6次,且用且珍惜(解决办法:用其他人的号)
方法二:K210离线采集
详情参考https://maixhub.com/app/3
方法三:手机采集后上传到电脑(不推荐)
PS:特别不推荐,因为手机采集的图片像素太高,在后面图片格式转化后效果较差,转化完图片会特别花
方法四:Mx_yolov3自带的图片爬取工具
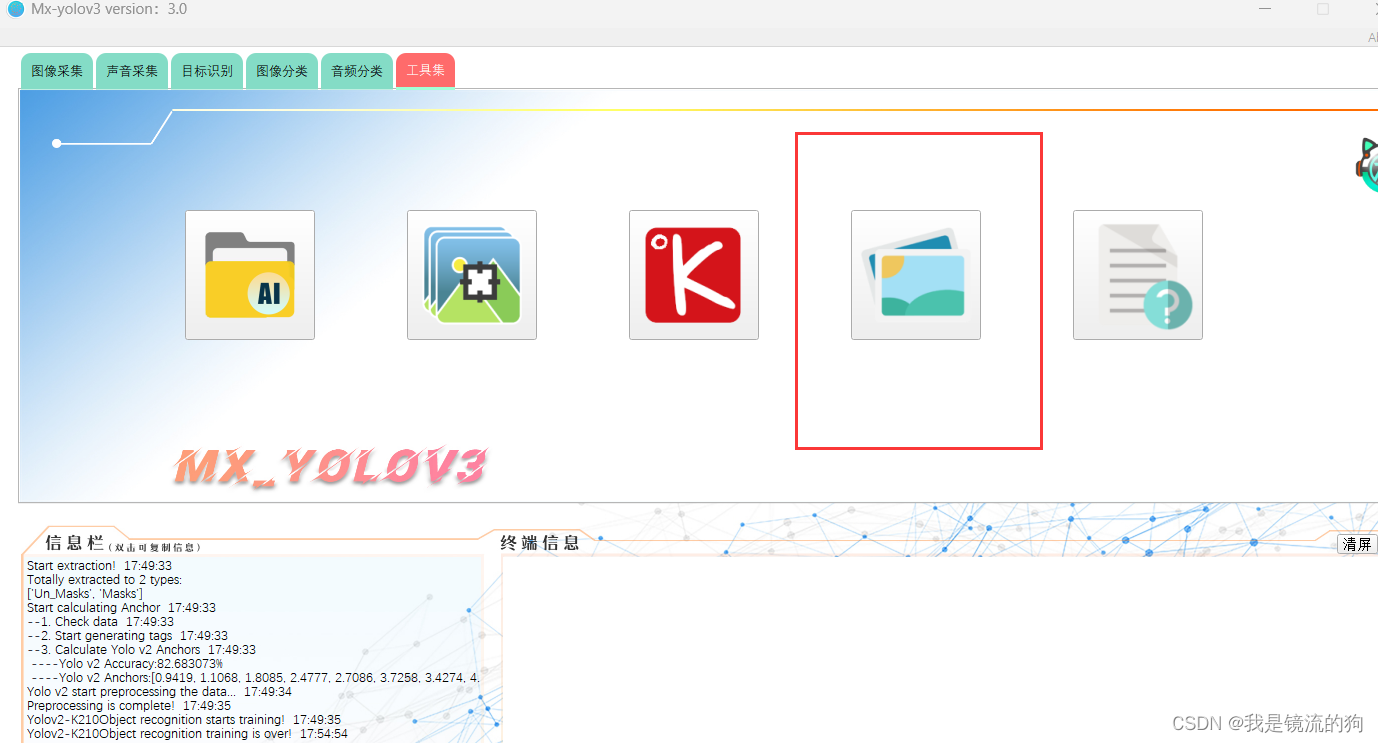
但这个工具总是下载一点就自动退出了,我也不知道解决办法
如果有其他方法欢迎评论区留言
(二)图片格式转换
为什么要进行图片格式转换呢?
因为K210上识别的照片模式为224*224,我们找到的图片不全是这种格式的,所以要转换才能更好的识别,训练效果才更好
而且图片像素越高,训练速度越慢(真的巨慢,慢到我自己怀疑是不是没使用GPU训练又装了一天的CUDA,最后才发现是图片像素的问题)
方法一:使用Mx_yolov3自带的图片转换工具
这个工具在这个路径下:D:\mx-yolov3\Mx-yolov3_EN_3.0.0\Image_tool
如果是像素高的图片不推荐这个软件,转换效果巨差,如果是像素低的,这个软件转换效果还行
方法二:使用万能格式转换器(强烈推荐)

优点:
- 对于任意像素的图片转换效果非常好
- 还支持各种图片的相互转换,比如openmv的jpg转pgm格式,免费且不限量转
缺点:
- 该软件用CPU转换的时候,CPU资源占的比较高
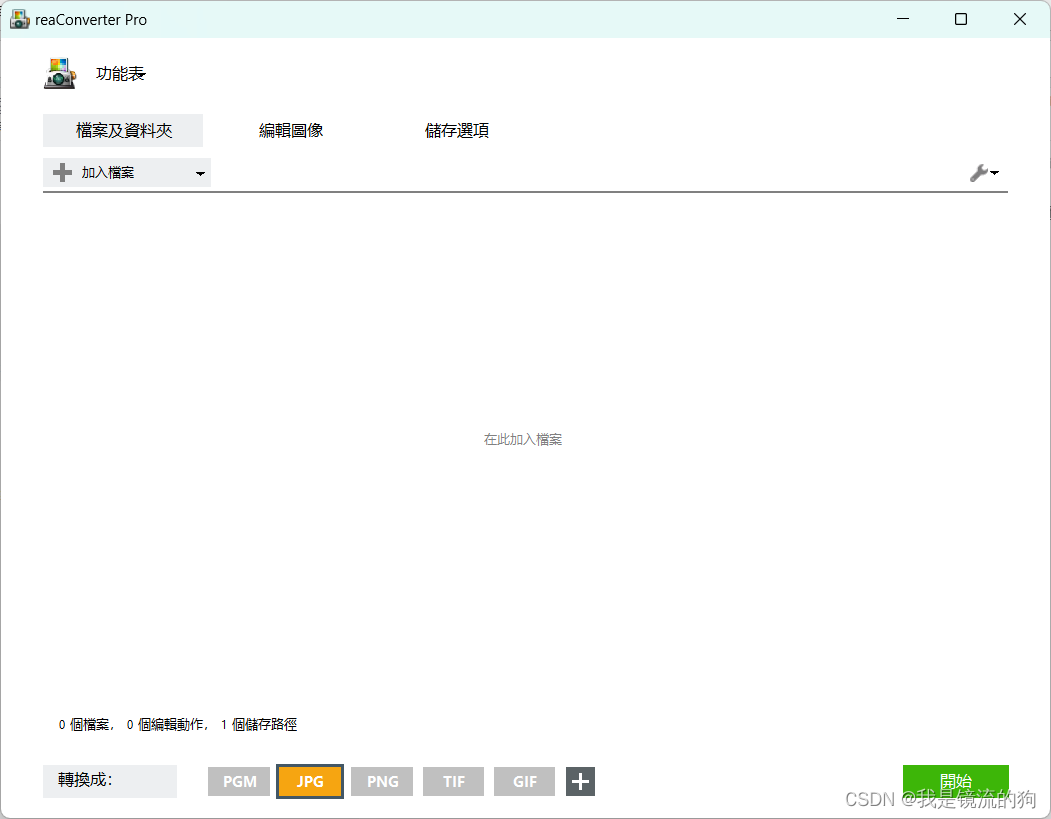
点击加入档案,选择文件夹,ctrl+A全选
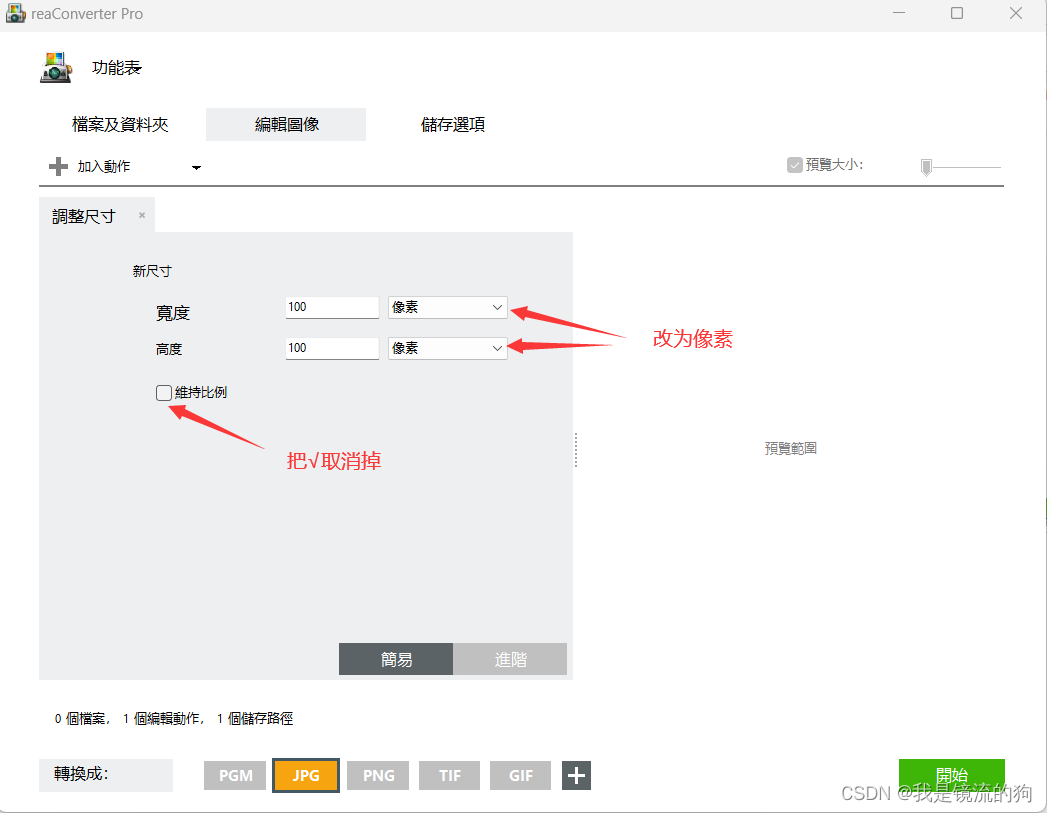
如图所示将图像设置为224*224后点开始转换即可,然后就可以在源文件夹中的Result文件中找到转换好的图片了
需要该软件的可以在评论区留言
(三)将图片进行目标识别
这里和测试Mx_yolov3一样,就不多赘述了,这里我来讲讲参数如何设置吧
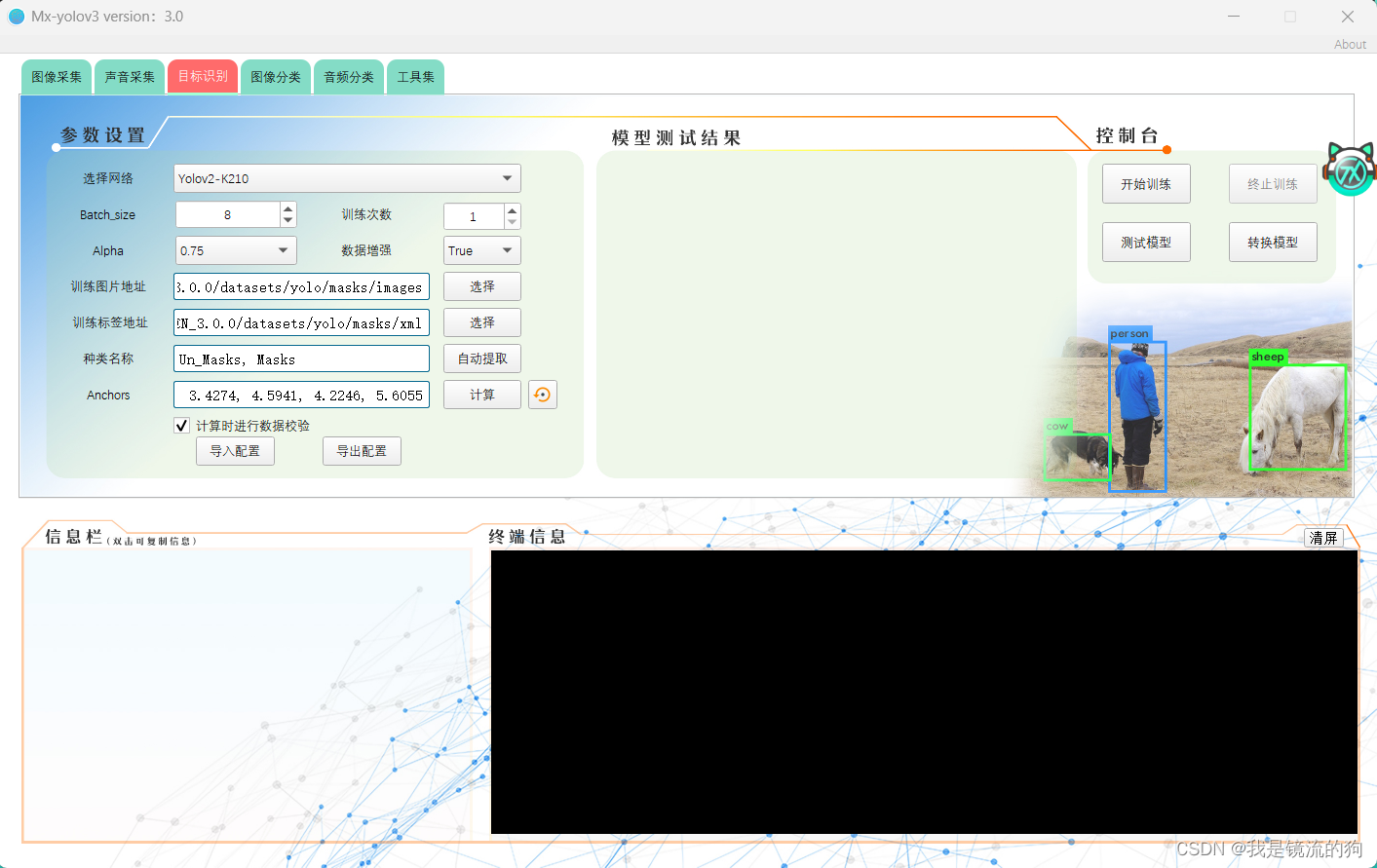
- Batch_size:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练
举个例子,训练集有1000个样本,batchsize=10,那么:
训练完整个样本集需要:
100次iteration,1次epoch。(epoch:1个epoch等于使用训练集中的全部样本训练一次)
1)batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。
2)随着batchsize增大,处理相同的数据量的速度越快。
3)随着batchsize增大,达到相同精度所需要的epoch数量越来越多。
4)由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5)由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
6)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。
7)具体的batch size的选取和训练集的样本数目相关。
这里参考了该位博主的文章,他讲的很好
- Alpha:置信度阈值
Alpha用于过滤掉检测到的目标中置信度低于阈值的候选框。只有置信度高于阈值的候选框才会被认为是有效的检测结果。通过调整Alpha的值,可以控制对目标检测结果的准确性和召回率的折衷。 - Anchors:预定义的一组边界框的尺寸和比例
YOLOv2使用锚框(Anchors)来预测目标的位置和大小。每个锚框都与特征图的一个位置相关联,并且每个位置都会预测一定数量的锚框。这些锚框的尺寸和比例是在训练过程中根据训练数据集进行学习和确定的。
通过与锚框进行比较,YOLOv2可以预测目标的位置和大小。每个锚框都会生成一个边界框,用于表示检测到的目标的位置和尺寸。通过使用不同尺寸和比例的锚框,YOLOv2可以更好地适应不同大小和形状的目标。锚框的选择对于目标检测算法的准确性和召回率具有重要影响。
训练完后
- 点击测试模型
模型文件在D:\mx-yolov3\Mx-yolov3_EN_3.0.0\Model_file路径下 - 并将刚刚生成的模型文件复制到源文件夹的Train_data(在训练时自动生成)中
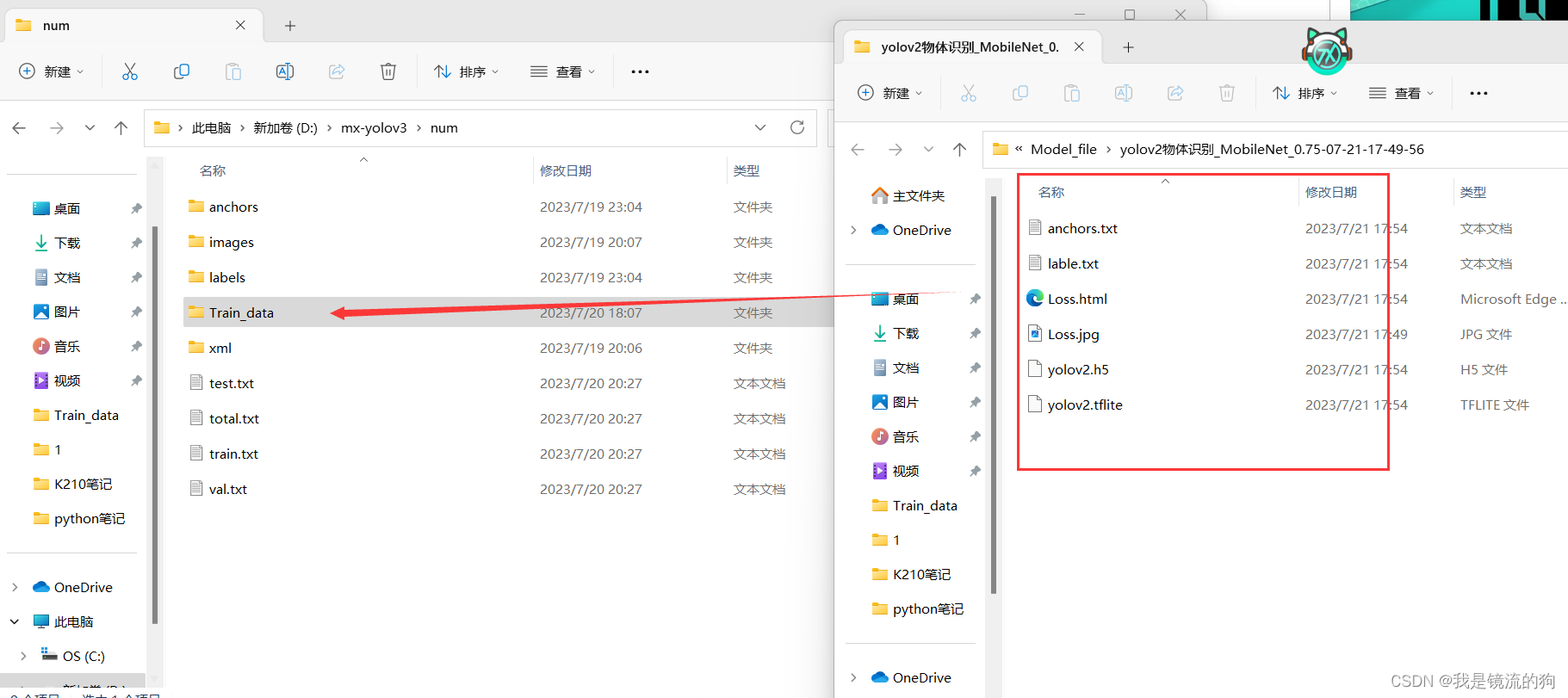
(四)模型转换
注意:转换模型的输入输出以及量化图片路径不能带有空格,不然会转换失败
我之前因为文件名是Digital recognition就转换失败了,现在改为了num
第一步:选择模型输入路径
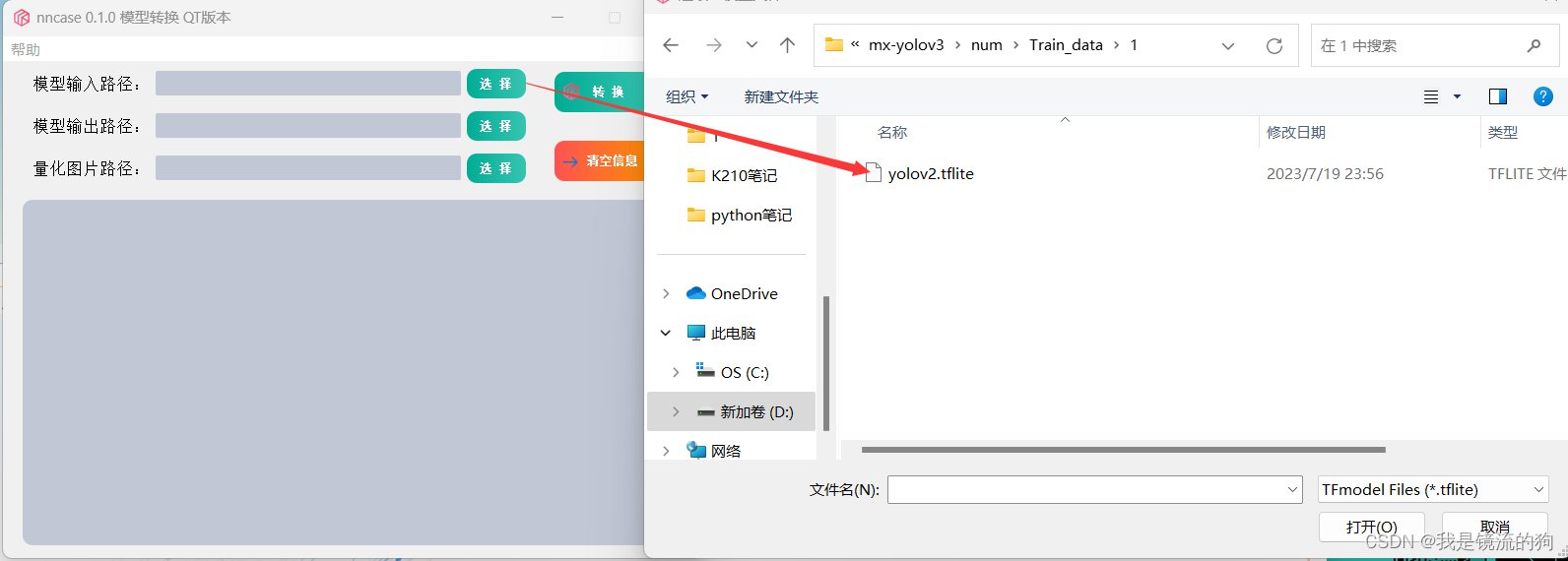
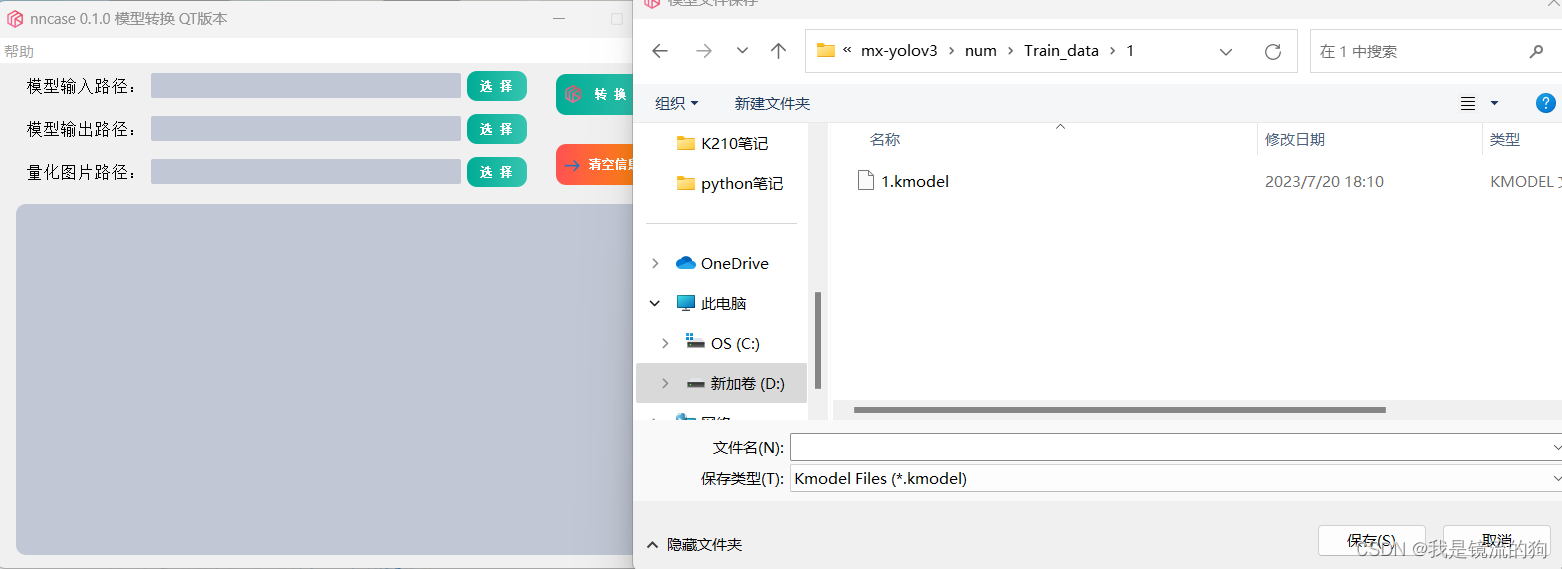
第二步:选择模型输出路径,任意路径都可,我这里已经转换过了,所以有.kmodel模型文件
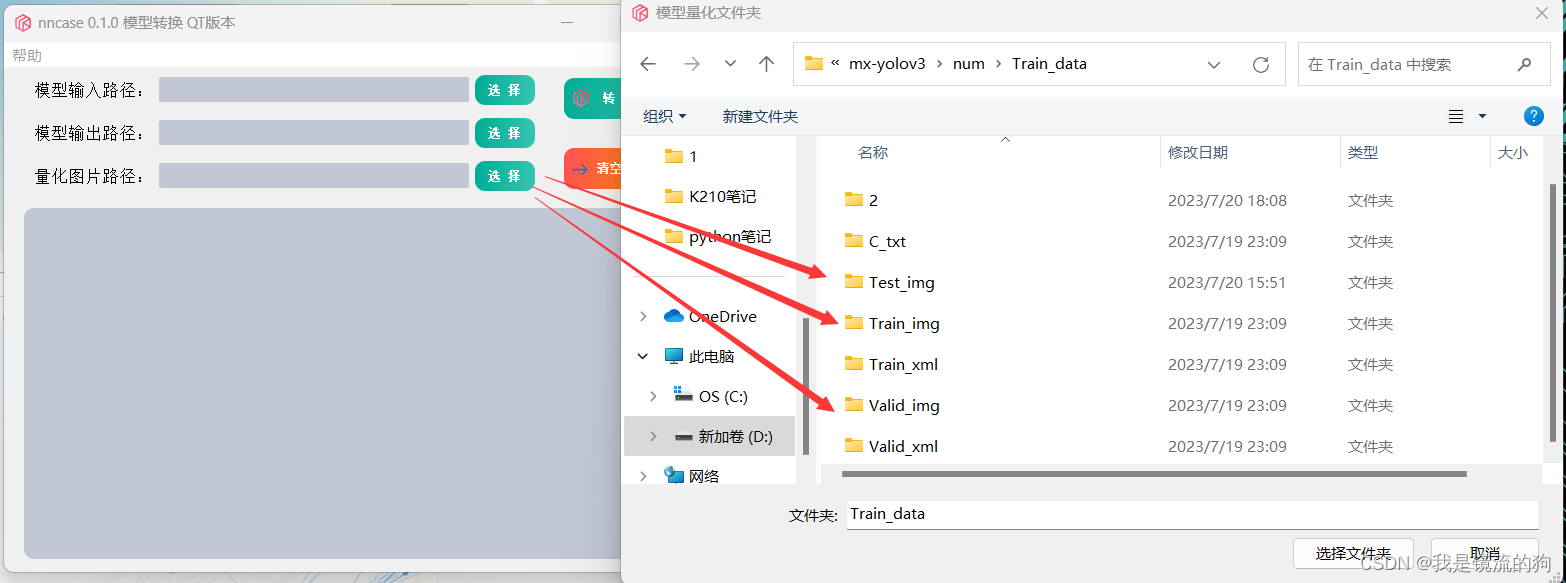
第三步:选择量化图片路径,选择这三个中任意一个都可,我也不是很清楚选择这三个有什么区别,欢迎大佬进行解答
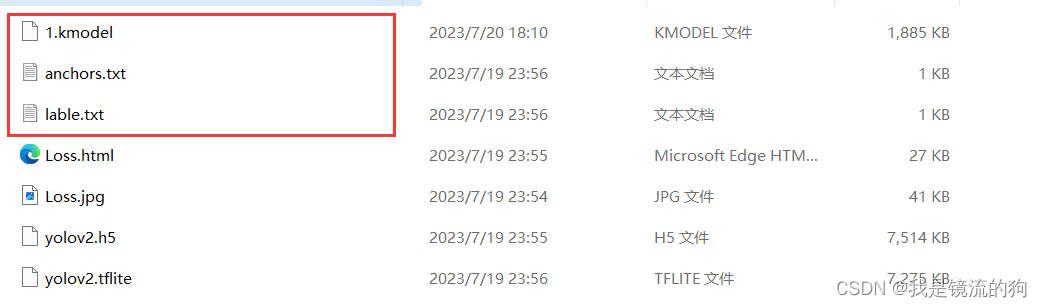
(五)部署模型文件到K210上
方法一:使用SD卡
使用读卡器将这三个文件放到SD卡上
在boot.py代码中修改参数
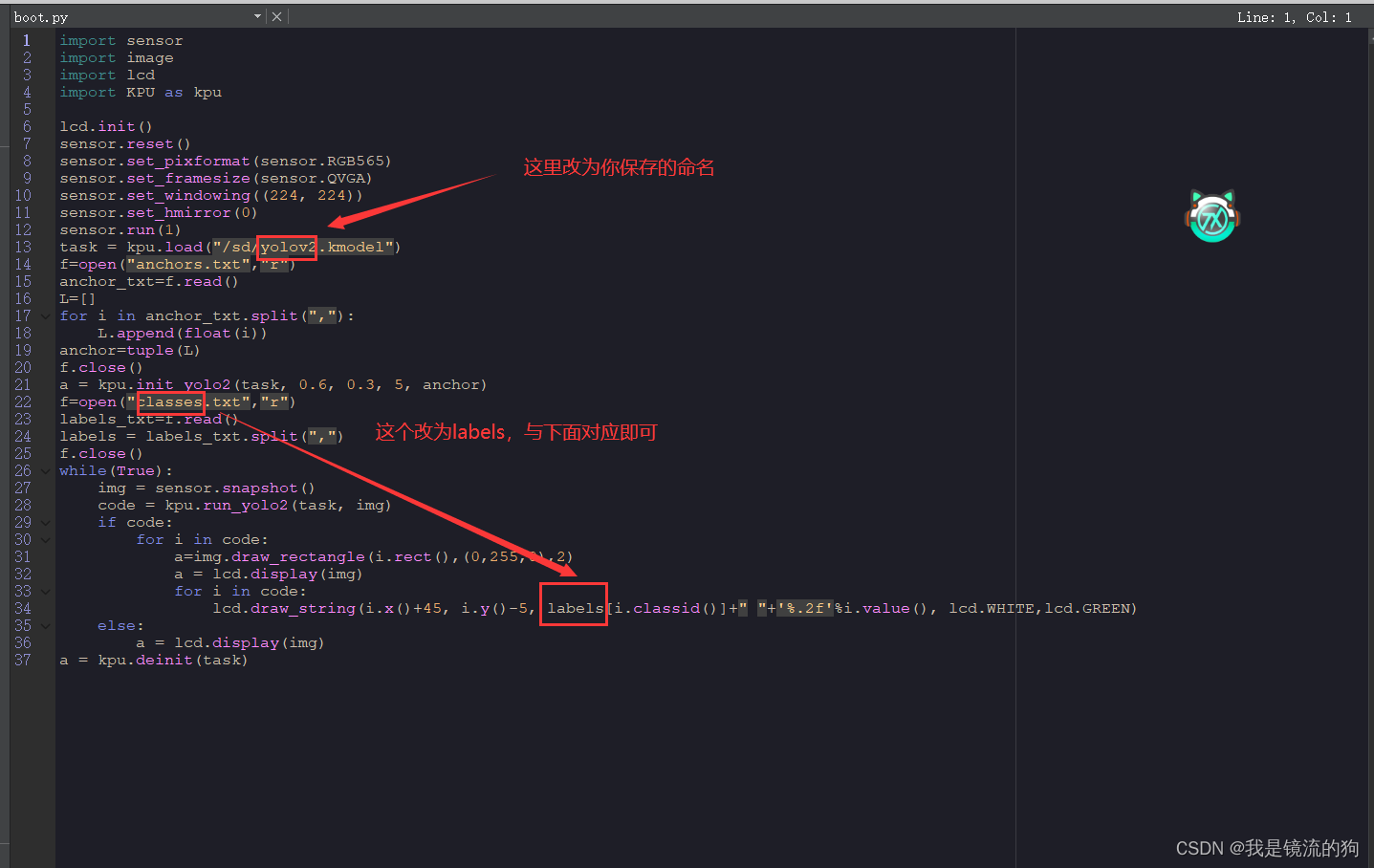
这里我附上代码
import sensor
import image
import lcd
import KPU as kpu
lcd.init()
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((224, 224))
sensor.set_hmirror(0)
sensor.run(1)
task = kpu.load("/sd/yolov2.kmodel")
f=open("anchors.txt","r")
anchor_txt=f.read()
L=[]
for i in anchor_txt.split(","):
L.append(float(i))
anchor=tuple(L)
f.close()
a = kpu.init_yolo2(task, 0.6, 0.3, 5, anchor)
f=open("classes.txt","r")
labels_txt=f.read()
labels = labels_txt.split(",")
f.close()
while(True):
img = sensor.snapshot()
code = kpu.run_yolo2(task, img)
if code:
for i in code:
a=img.draw_rectangle(i.rect(),(0,255,0),2)
a = lcd.display(img)
for i in code:
lcd.draw_string(i.x()+45, i.y()-5, labels[i.classid()]+" "+'%.2f'%i.value(), lcd.WHITE,lcd.GREEN)
else:
a = lcd.display(img)
a = kpu.deinit(task)
修改后点保存,运行即可
方法二:将模型烧录到SD卡上
因为我们训练出的模型相对来说比较大,使用方法一可能会显示K210内存不够的报错:
ValueError: [MAIXPY]kpu: load error:2006, ERR. NO_ MEM: memory not enough
这个时候就需要更换K210固件库:
运行各种模型,建议使用maixpy_vx.y.z_x_xxx*_minimum_with_ide_support.bin
(MaixPy 固件最小集合, 支持连接 MaixPy IDE, 不包含OpenMV的相关算法和各种外设模块)
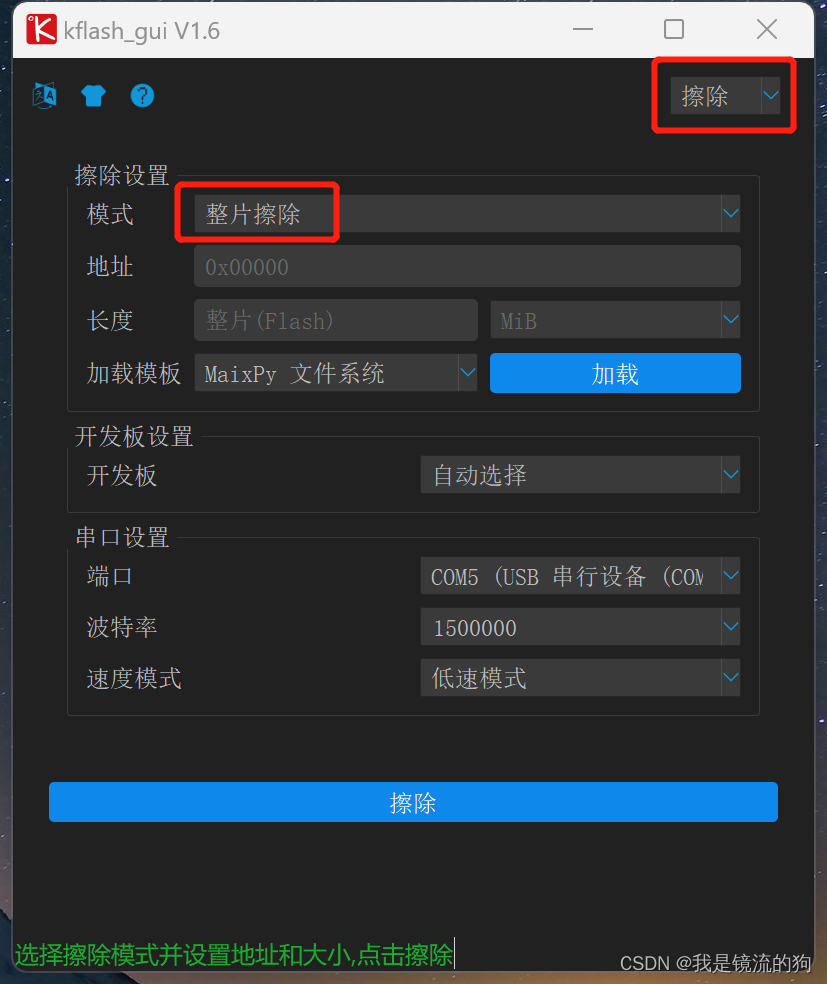
下载地址:https://dl.sipeed.com/MAIX/MaixPy/release/master/
下载前需要先整片擦除
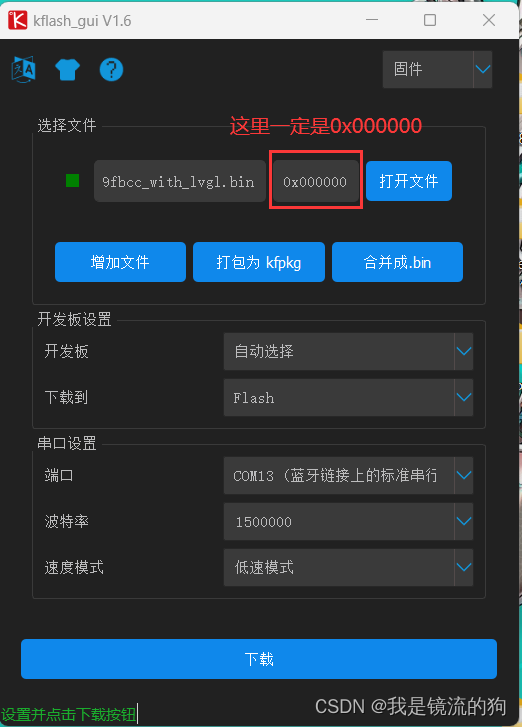
然后再下载固件,地址一定是0x000000
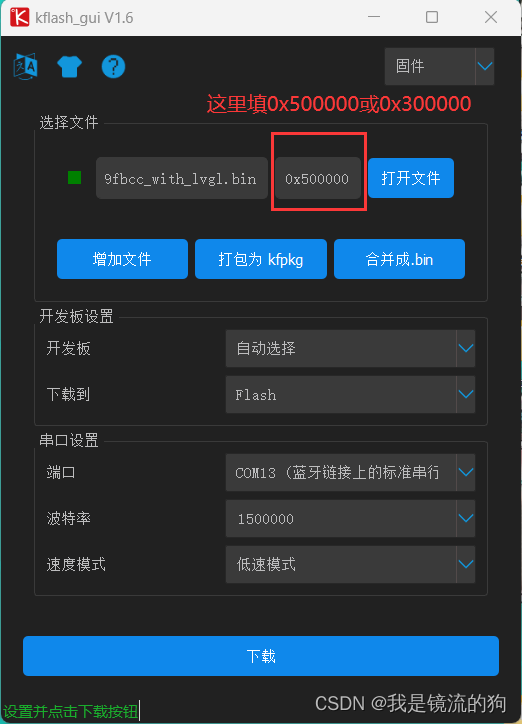
然后再烧录kmodel文件,地址选择0x300000或0x500000
最后再修改boot.py即可
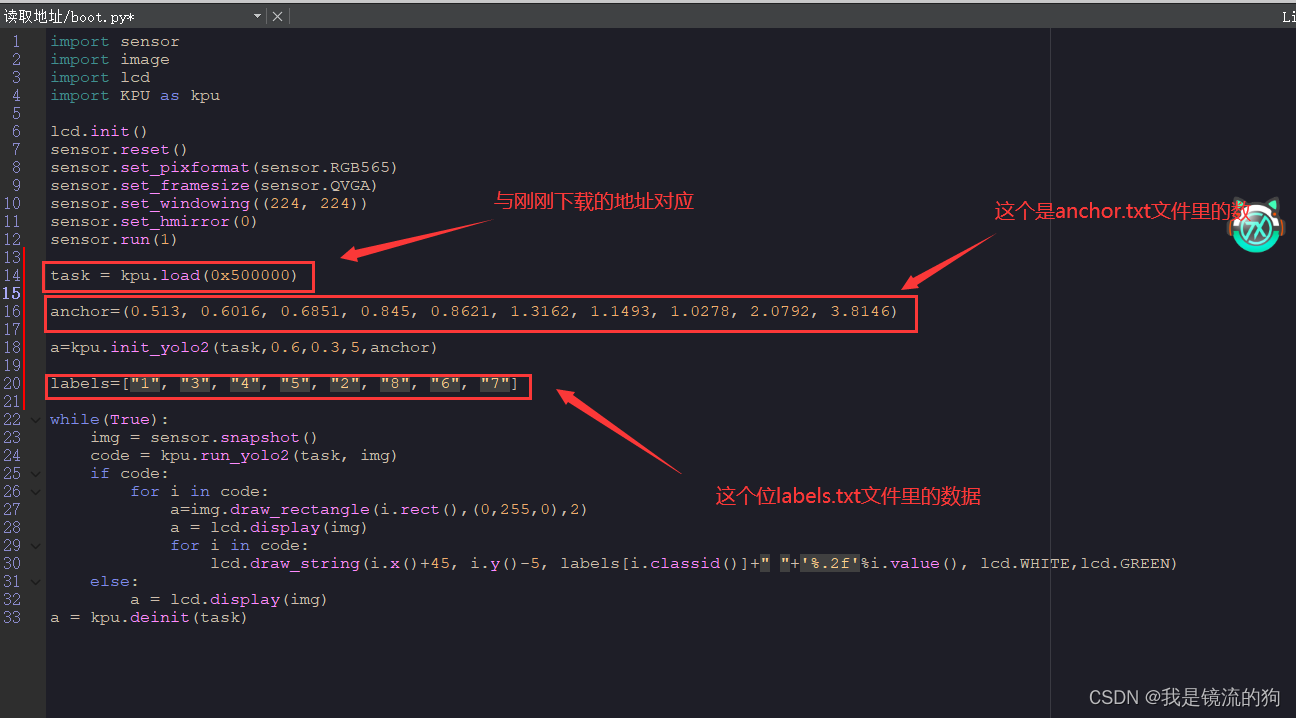
这里我附上代码
import sensor
import image
import lcd
import KPU as kpu
lcd.init()
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((224, 224))
sensor.set_hmirror(0)
sensor.run(1)
task = kpu.load(0x500000)
anchor=(0.513, 0.6016, 0.6851, 0.845, 0.8621, 1.3162, 1.1493, 1.0278, 2.0792, 3.8146)
a=kpu.init_yolo2(task,0.6,0.3,5,anchor)
labels=["1", "3", "4", "5", "2", "8", "6", "7"]
while(True):
img = sensor.snapshot()
code = kpu.run_yolo2(task, img)
if code:
for i in code:
a=img.draw_rectangle(i.rect(),(0,255,0),2)
a = lcd.display(img)
for i in code:
lcd.draw_string(i.x()+45, i.y()-5, labels[i.classid()]+" "+'%.2f'%i.value(), lcd.WHITE,lcd.GREEN)
else:
a = lcd.display(img)
a = kpu.deinit(task)
注意:KPU.init_yolo2(kpu_net, threshold, nms_value, anchor_num, anchor)中anchor_num应为anchor列表元素/2,比如我这里的anchor列表元素为10,所以anchor_num=5
文章到此就结束,这只是个人学习的记录分享,如有错误,请路过的大佬指导指导。
















 1810
1810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











