







参考文章: 小傅哥,公众号:bugstack 虫洞栈 《java面经手册》
先来了解一下什么是hashCode?
hashCode在Java中所代表的是一种方法,是获得hash值的一种方法。
hash 翻译做“散列”,也可直译为“哈希”,就是把任意长度的值输入,通过hash()函数输出固定长度的消息摘要。 hash函数也有很多种,包括:直接取余法,乘法取整法,平方取中法,暂时先了解有这些方法即可。
hash表是啥? hash表是由hash值组成的。
HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的(用HashCode来代表对象就是在hash表中的位置)。
阅读源码
关于获得haashCode的函数非常之多,我们我截取java.util包中的Arrays类给大家瞅一瞅:
public static int hashCode(long a[]) {
if (a == null)
return 0;
int result = 1;
for (long element : a) {
int elementHash = (int)(element ^ (element >>> 32));
result = 31 * result + elementHash;
}
return result;
}
在获取 hashCode 的源码中可以看到,有一个固定值 31,在 for 循环每次执行时 进行乘积计算,循环后的公式如下; s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
那么这里为什么选择 31 作为乘积值呢?
收集到的资料主要有两个观点:
第一种观点:
- 31 是一个奇质数,如果选择偶数会导致乘积运算时数据溢出。
- 另外在二进制中,2 个 5 次方是 32,那么也就是 31 * i == (i << 5) - i。这主要是说乘积运算可以使用位移提升性能,同时目前的 JVM 虚拟机 也会自动支持此类的优化。
第二种观点:
经过大量测试,如果用超过 5 千个单词计算 hashCode, 这个 hashCode 的运算使用 31、33、37、39 和 41 作为乘积,得到的碰撞结果,31 被使用就很正常了。
虫洞栈做了一下实验: 统计出不同的乘积数对 10 万个单词的 hash 计算结果。
Hash 计算函数 :
public static Integer hashCode(String str, Integer multiplier) {
int hash = 0;
for (int i = 0; i < str.length(); i++) {
hash = multiplier * hash + str.charAt(i);
}
return hash;
}这个过程比较简单,与原 hash 函数对比只是替换了可变参数,用于我们统计不同乘积数的计算结果。
Hash 碰撞概率计算 :
想计算碰撞很简单,也就是计算那些出现相同哈希值的数量,计算出碰撞总量即可。这里的实现方式有很多,可以使用 set、map 也可以使用 java8 的 stream 流 统计distinct。
private static RateInfo hashCollisionRate(Integer multiplier, List<Integer> hashCodeList) {
int maxHash = hashCodeList.stream().max(Integer::compareTo).get();
int minHash = hashCodeList.stream().min(Integer::compareTo).get();
int collisionCount = (int) (hashCodeList.size() - hashCodeList.stream().distinct().count());
double collisionRate = (collisionCount * 1.0) / hashCodeList.size();
return new RateInfo(maxHash, minHash, multiplier, collisionCount, collisionRate);
}这里记录了最大 hash 和最小 hash 值,以及最终返回碰撞数量的统计结果。
单元测试 :
@Before
public void before() {
"abc".hashCode();
// 读取文件,103976 个英语单词库.txt
words = FileUtil.readWordList("E:/itstack/git/github.com/interview/interview01/103976 个英语单词库.txt");
}
@Test
public void test_collisionRate() {
List<RateInfo> rateInfoList = HashCode.collisionRateList(words, 2, 3, 5, 7, 17,31, 32, 33, 39, 41, 199);
for (RateInfo rate : rateInfoList) {
System.out.println(String.format("乘数 = %4d, 最小 Hash = %11d, 最大
Hash = %10d, 碰撞数量 =%6d, 碰撞概率 = %.4f%%", rate.getMultiplier(), rate.getMinHash(), rate.getMaxHash(), rate.getCollisionCount(), rate.getCollisionRate() * 100));
}
}- 以上先设定读取英文单词表中的 10 个单词,之后做 hash 计算。
- 在 hash 计算中把单词表传递进去,同时还有乘积数;2, 3, 5, 7, 17, 31, 32, 33, 39, 41, 199,最终返回一个 list 结果并输出。
- 这里主要验证同一批单词,对于不同乘积数会有怎么样的 hash 碰撞结果。
最终得到结果:


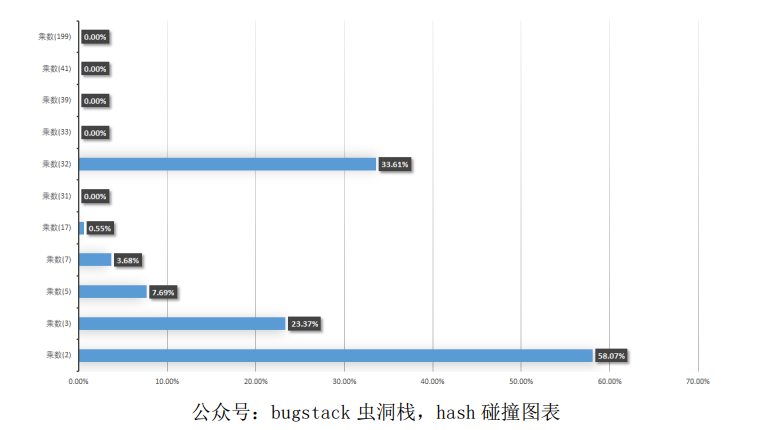
- 以上就是不同的乘数下的 hash 碰撞结果图标展示,从这里可以看出如下信息;
- 乘数是 2 时,hash 的取值范围比较小,基本是堆积到一个范围内了,后 面内容会看到这块的展示。
- 乘数是 3、5、7、17 等,都有较大的碰撞概率
- 乘数是 31 的时候,碰撞的概率已经很小了,基本稳定。
- 顺着往下看,你会发现 199 的碰撞概率更小,这就相当于一排奇数的茅坑量多,自然会减少碰撞。但这个范围值已经远超过 int 的取值范围 了,如果用此数作为乘数,又返回 int 值,就会丢失数据信息。
Hash 值散列分布
除了以上看到哈希值在不同乘数的一个碰撞概率后,关于散列表也就是 hash, 还有一个非常重要的点,那就是要尽可能的让数据散列分布。只有这样才能减少 hash 碰撞次数 。
那么怎么看散列分布呢?如果我们能把 10 万个 hash 值铺到图表上,形成的一张 图,就可以看出整个散列分布。但是这样的图会比较大,当我们缩小看后,就成 一个了大黑点。所以这里我们采取分段统计,把 2 ^ 32 方分 64 个格子进行存 放,每个格子都会有对应的数量的 hash 值,最终把这些数据展示在图表上。
哈希值分段存放
public static Map<Integer, Integer> hashArea(List<Integer> hashCodeList) {
Map<Integer, Integer> statistics = new LinkedHashMap<>();
int start = 0;
for (long i = 0x80000000; i <= 0x7fffffff; i += 67108864) {
long min = i;
long max = min + 67108864;
// 筛选出每个格子里的哈希值数量,java8 流统计;https://bugstack.cn/itstack-demoany/2019/12/10/%E6%9C%89%E7%82%B9%E5%B9%B2%E8%B4%A7-Jdk1.8%E6%96%B0%E7%89%B9%E6%80%A7%E5%AE%9E%E6%88%98%E7%AF%87(41%E4%B8%AA%E6%A1%88%E4%BE%8B).html
int num = (int) hashCodeList.parallelStream().filter(x -> x >= min && x < max).count();
statistics.put(start++, num);
}
return statistics;- 这个过程主要统计 int 取值范围内,每个哈希值存放到不同格子里的数 量。
- 这里也是使用了 java8 的新特性语法,统计起来还是比较方便的。
单元测试
@Test
public void test_hashArea() {
System.out.println(HashCode.hashArea(words, 2).values());
System.out.println(HashCode.hashArea(words, 7).values());
System.out.println(HashCode.hashArea(words, 31).values());
System.out.println(HashCode.hashArea(words, 32).values());
System.out.println(HashCode.hashArea(words, 199).values());
}- 这里列出我们要统计的乘数值,每一个乘数下都会有对应的哈希值数量汇总,也就是 64 个格子里的数量。
- 最终把这些统计值放入到 excel 中进行图表化展示。
统计图表
-
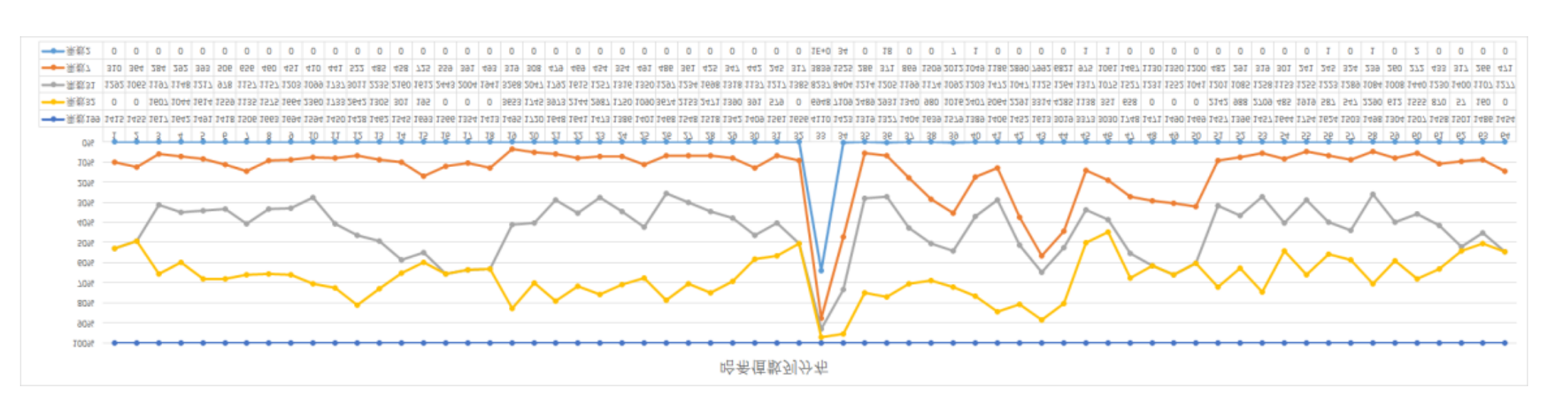
- 以上是一个堆积百分比统计图,可以看到下方是不同乘数下的,每个格子里的数据统计。
- 除了 199 不能用以外,31 的散列结果相对来说比较均匀。

乘数是 2 的时候,散列的结果基本都堆积在中间,没有很好的散列。

乘数是 31 的时候,散列的效果就非常明显了,基本在每个范围都有数据存放。

乘数是 199 是不能用的散列结果,但是它的数据是更加分散的,从图上能看到有两个小山包。但因为数据区间问题会有数据丢失问题,所以不能选择。
总结
- 以上主要介绍了 hashCode 选择 31 作为乘数的主要原因和实验数据验 证,算是一个散列的数据结构的案例讲解,在后续的类似技术中,就可以解释其他的源码设计思路了。
- 看过本文至少应该让你可以从根本上解释了 hashCode 的设计,关于他的 所有问题也就不需要死记硬背了,学习编程内容除了最开始的模仿到深 入以后就需要不断的研究数学逻辑和数据结构。
- 文中参考了优秀的 hashCode 资料和 stackoverflow,并亲自做实验验证结果,大家也可以下载本文中资源内容;英文字典、源码、excel 图表 等内容















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











