







💕**不要害怕前方的未知和困难,因为它们都是你成长的机会。不要过于在意别人的眼光和评价,因为唯有你的内心才知道自己真正的价值。珍惜当下,享受生活的点滴,让自己变得更加坚强、自信、成熟。**💕
🐼作者:不能再留遗憾了🐼
🎆专栏:Java学习🎆
🚗本文章主要内容:前k个高频单词 题解🚗

题目要求
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入: words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出: [“i”, “love”] 解析: “i” 和 “love” 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 “i” 在 “love” 之前。
示例 2:
输入: [“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”,
“is”], k = 4 输出: [“the”, “is”, “sunny”, “day”] 解析: “the”, “is”,
“sunny” 和 “day” 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
class Solution {
public List<String> topKFrequent(String[] words, int k) {
}
}
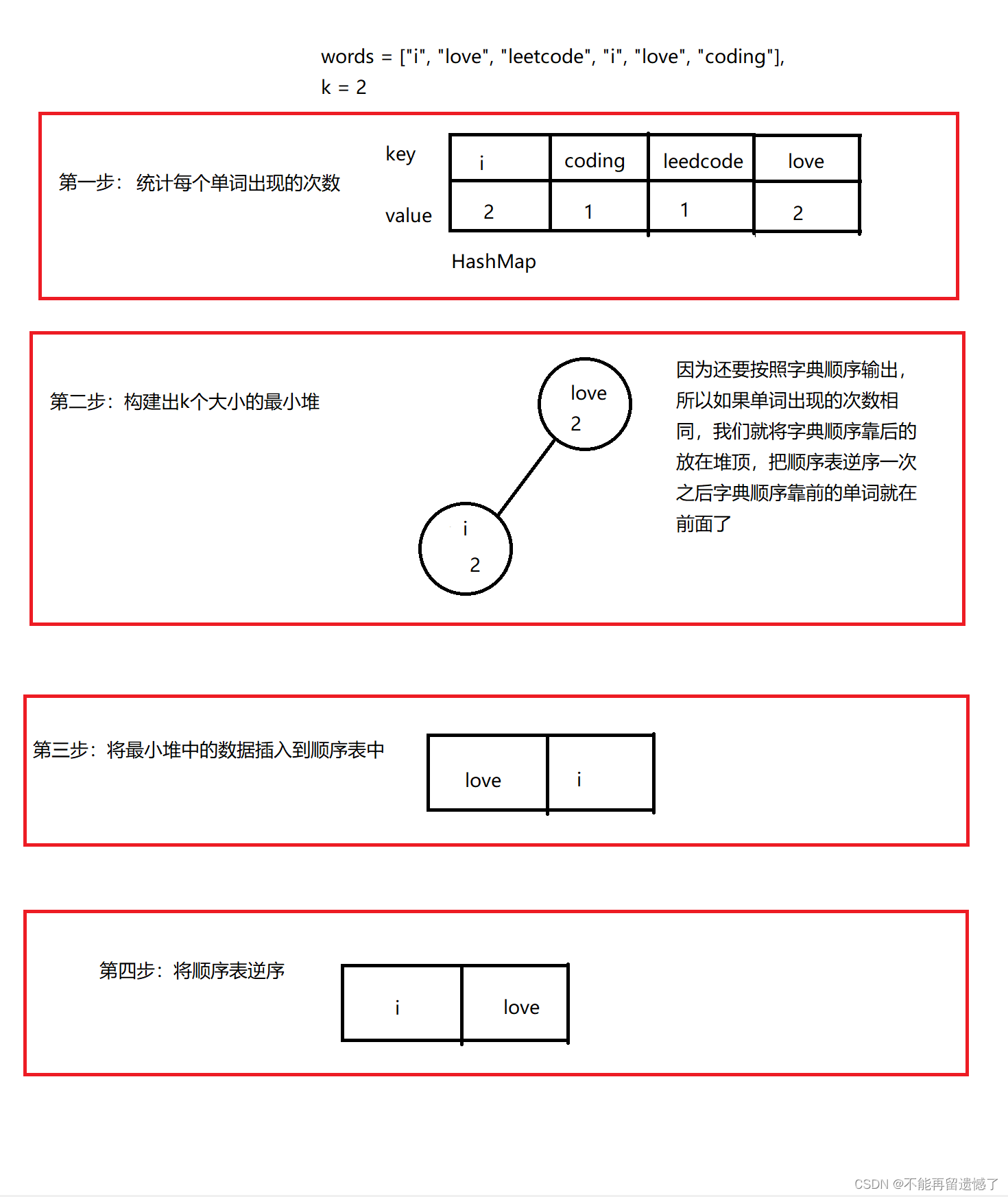
做题思路
首先,当我们看到题目TopK的问题时,就会想到使用堆来解决,如果大家不了解堆,可以看看我的这篇文章什么是堆以及堆是怎样创建的。如果TopK是前K个最大的值,那么就需要使用构建最小堆来解决,如果TopK是前K个最小的值,那么就需要构建最大堆来解决。很显然这道题是求前K个高频单词,所以我们构建最小堆来解决问题。
在知道了使用什么结构来解决,我们还需要知道,怎样才能知道每个单词出现的次数呢?很多人第一想法可能是通过创建一个类来实现,类里面有这个单词以及单词出现的次数,但是太麻烦了,不推荐。那么怎样做才最简单呢?那就是使用我们的HashMap的Key — Value模型,将单词作为Key,次数作为Value。
在统计完每个单词出现的次数之后,我们就创建k个大小的最小堆,每次进堆就与最小堆的根节点所代表的单词出现的次数比较,如果待进堆的单词出现的次数大于堆的根节点单词出现的次数,那么就先出堆,然后再将待插入的数据入堆,调整最小堆。
当HashMap中的数据都遍历完成后,我们就需要将最小堆中的k个数据出堆,我们都知道每次从最小堆中出来的都是堆顶的也就是堆中最小的数据,但是我们再仔细看题目要求可以知道按单词出现的频率的高低排序。所以我们需要先将HashMap中的数据都插入到一个顺序表中,然后再将整个顺序表逆序一次就得到了我们想要的结果。
代码实现
统计单词出现的次数
Map<String,Integer> hashmap = new HashMap<>();
for(String s : words) {
if(hashmap.get(s) == null) {
hashmap.put(s,1);
}else {
hashmap.put(s,hasnmap.get(s) + 1);
}
}
创建大小为k的最小堆
因为Java提供的PriorityQueue默认是最小堆,所以我们可以直接使用Java提供的方法。先将k个数据放入最小堆中,后面再放入数据的时候,需要比较待插入的单词出现的次数与堆顶单词出现次数的大小,如果待插入的单词出现的次数大于堆顶单词出现的数据,那么就先出堆,然后再将这个单词入堆;如果待插入单词出现的次数等于堆顶单词出现的次数,那么就需要比较带插入单词与堆顶单词的字典顺序了,如果待插入单词的字典顺序在前面,那么就先出堆然后再入堆,反之就不需要对对做出调整。
//创建k个大小的最小堆
//我们这里传入一个比较器并重写compare方法,因为Java提供的compare方法的比较是基本数据类型之间的
PriorityQueue<Map.Entry<String,Integer>> minHeap = new PriorityQueue<>(
k,new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o1.getValue().compareTo(o2.getValue());
}
}
);
for(Map.Entry<String,Integer> entry: hashmap.entrySet()) {
//先在堆中存放k个节点
if(minHeap.size() < k) {
minHeap.offer(entry);
}else {
if(minHeap.peek().getValue().compareTo(entry.getValue()) < 0) {
minHeap.poll();
minHeap.offer(entry);
}else if(minHeap.peek().getValue().compareTo(entry.getValue()) == 0) {
//当出现的次数相同时就比较单词的字典顺序
if(minHeap.peek().getKey().compareTo(entry.getKey()) > 0) {
minHeap.poll();
minHeap.offer(entry);
}
}
}
}
这里我们的比较器构造的有问题,我们先看会出现什么问题
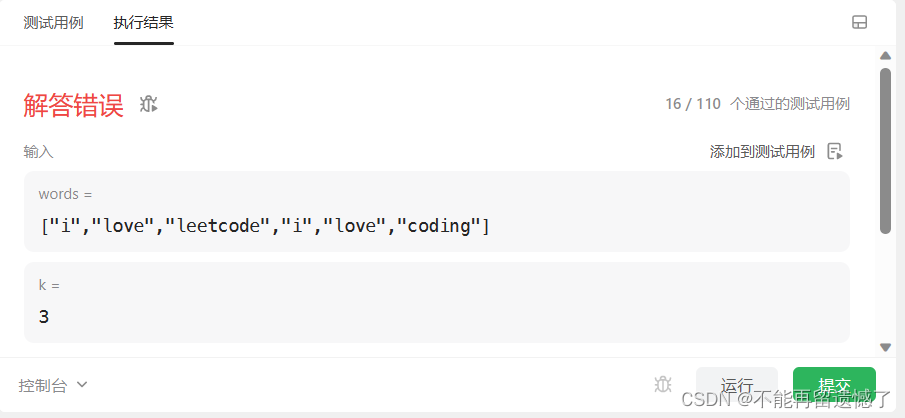
当k为3的时候为什么会出错呢
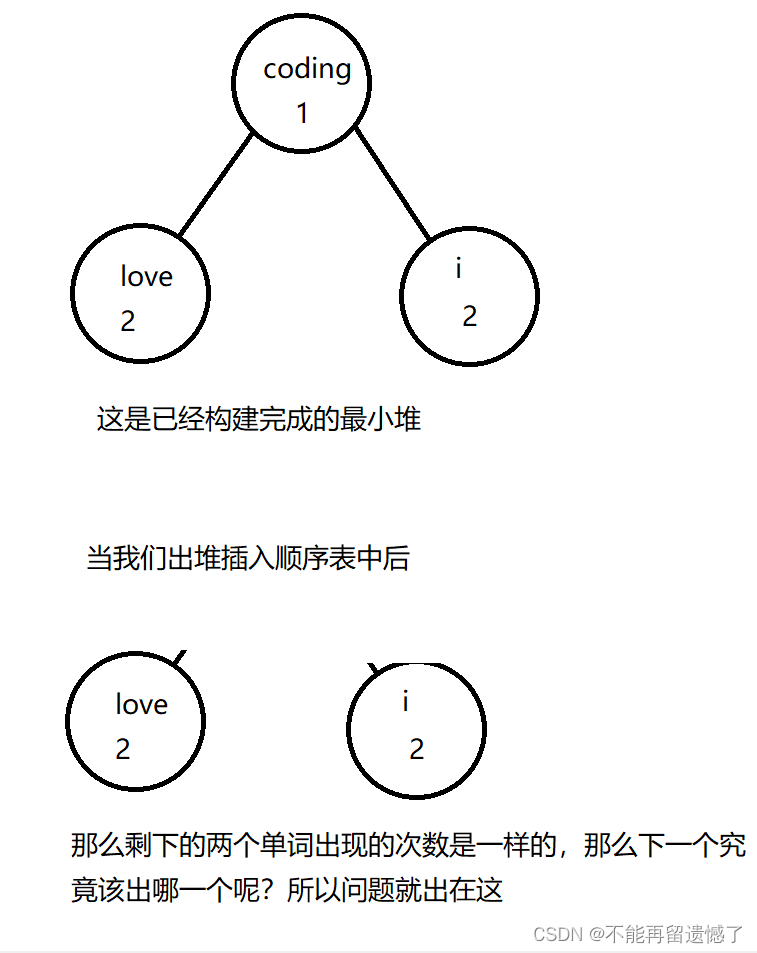
所以我们的构造器还需要添加一个条件,当单词出现的次数相同时就比较单词出现的字典顺序。
修改构造器
//创建k个大小的最小堆
//我们这里传入一个比较器并重写compare方法,因为Java提供的compare方法的比较是基本数据类型之间的
PriorityQueue<Map.Entry<String,Integer>> minHeap = new PriorityQueue<>(
k,new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if(o1.getValue().compareTo(o2.getValue()) == 0) { //因为堆顶的节点先出,后面再逆序后就被调整到后面了,所以我们将字典序靠后的放在堆顶
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue().compareTo(o2.getValue());
}
}
);
for(Map.Entry<String,Integer> entry: hashmap.entrySet()) {
//先在堆中存放k个节点
if(minHeap.size() < k) {
minHeap.offer(entry);
}else {
if(minHeap.peek().getValue().compareTo(entry.getValue()) < 0) {
minHeap.poll();
minHeap.offer(entry);
}else if(minHeap.peek().getValue().compareTo(entry.getValue()) == 0) {
//当出现的次数相同时就比较单词的字典顺序
if(minHeap.peek().getKey().compareTo(entry.getKey()) > 0) {
minHeap.poll();
minHeap.offer(entry);
}
}
}
}
将最小堆的数据插入到顺序表中并逆序
List<String> list = new ArrayList<>();
//3.将堆中的数据放入数组中
for(int i = 0; i < k; i++) {
String ret = minHeap.poll().getKey();
list.add(ret);
}
//List继承自collections类,collections类中实现了reverse逆序方法
Collections.reverse(list);
return list;
整体代码展示
class Solution {
public List<String> topKFrequent(String[] words, int k) {
//1.统计每个单词出现的次数
Map<String,Integer> hashmap = new HashMap<>();
for(String s : words) {
if(hashmap.get(s) == null) {
hashmap.put(s,1);
}else {
hashmap.put(s,hashmap.get(s) + 1);
}
}
//创建k个大小的最小堆
//这里记得重写compare方法
PriorityQueue<Map.Entry<String,Integer>> minHeap = new PriorityQueue<>(
new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if(o1.getValue().compareTo(o2.getValue()) == 0) { //因为堆顶的节点先出,后面再逆序后就被调整到后面了,所以我们将字典序靠后的放在堆顶
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue().compareTo(o2.getValue());
}
}
);
for(Map.Entry<String,Integer> entry: hashmap.entrySet()) {
//先在堆中存放k个节点
if(minHeap.size() < k) {
minHeap.offer(entry);
}else {
if(minHeap.peek().getValue().compareTo(entry.getValue()) < 0) {
minHeap.poll();
minHeap.offer(entry);
}else if(minHeap.peek().getValue().compareTo(entry.getValue()) == 0) {
//当出现的次数相同时就比较单词的字典顺序
if(minHeap.peek().getKey().compareTo(entry.getKey()) > 0) {
minHeap.poll();
minHeap.offer(entry);
}
}
}
}
List<String> list = new ArrayList<>();
//3.将堆中的数据放入数组中
for(int i = 0; i < k; i++) {
String ret = minHeap.poll().getKey();
list.add(ret);
}
Collections.reverse(list);
return list;
}
}
















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











