







1.网络配置
(1)查看ip地址:ifconfig
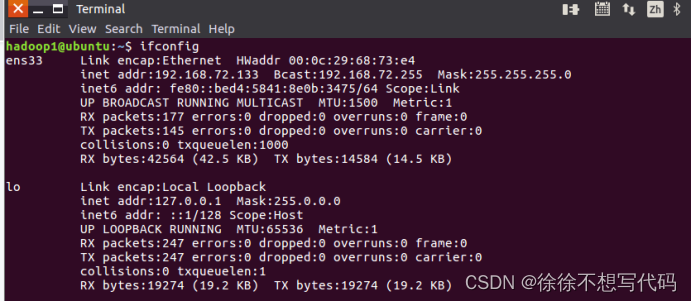

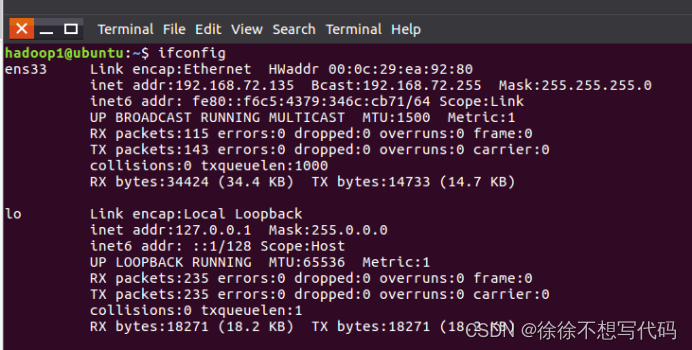
(2)修改主机名sudo gedit /etc/hostname




然后,重新启动

修改成功!
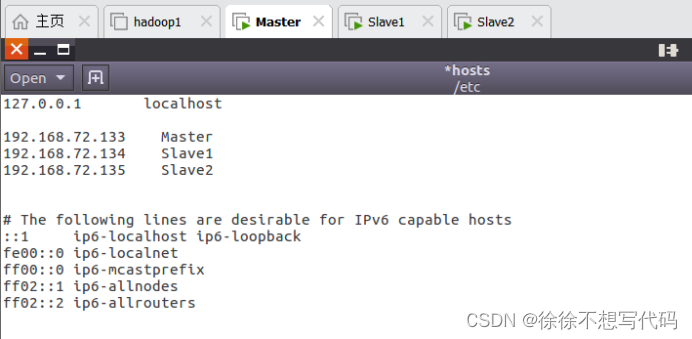
(3)打开并修改节点中的“/etc/hosts”文件

(4)在Master、Slave1\Slave2中hosts文件中添加三条IP地址和主机名的映射关系
192.168.72.133 Master
192.168.72.134 Slave1
192.168.72.135 Slave2


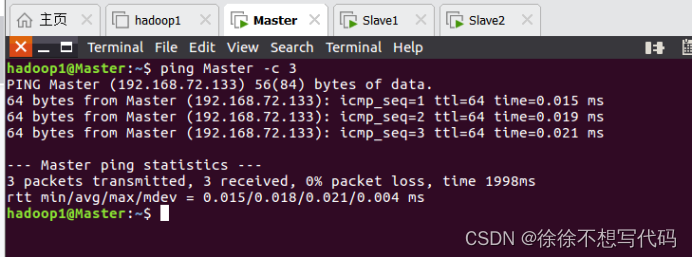
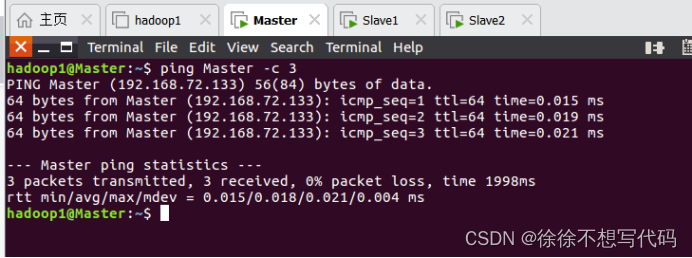
(5)测试Master,Slave1,Slave2三者之间是否相通
Master:相通(其他两个方法相同)

2.无密码登录节点
(1)删除之前生成的公钥(如果存在的话)

(2)生成密钥

(3)在Master节点将上公匙传输到Slave1节点和Slave2节点

(4)在Slave1节点和Slave2节点上,将SSH公匙加入授权


(5)在Master上检验(exit退出)


3.配置PATH变量
(1)使用vim编辑器打开“~/.bashrc”文件

(2)在最上面,添加指定语句,保存(:wq)

(3)执行命令source ~/.bashrc,使配置生效
![]()
4.配置集群/分布式环境(在/usr/local/hadoop/etc/hadoop目录下完成)
(1)修改文件workers
打开workers文件,删除原有内容,添加如下内容

(2)修改文件core-site.xml
打开core-site.xml文件,将内容修改为如下所示

(3)修改文件hdfs-site.xml
打开hdfs-site.xml文件,修改为如下所示
(因为有两个节点作为数据节点,即集群中有两个数据节点,数据保存两份,所以 ,dfs.replication的值设置为 2)

(4)修改文件mapred-site.xml
首先,将mapred-site.xml.template文件重命名为mapred-site.xml
(此处文件名称直接是mapred-site.xml,所以省略这一步)
然后,修改mapred-site.xml文件内容

(5)修改文件 yarn-site.xml

(6)配置好Master中的文件后,将文件复制到各个节点
(6.1)首先在Master上执行


(6.2)在Slave1和Slave2上执行


(6.4)首次启动Hadoop集群时,需要先在Master节点执行名称节点的格式化(只需要执行这一次,后面再启动Hadoop时,不要再次格式化名称节点
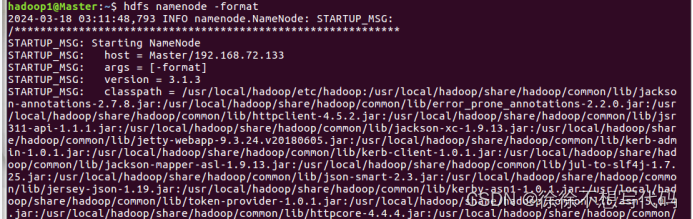
(7)启动Hadoop,需要在Master上执行

(8)验证是否成功
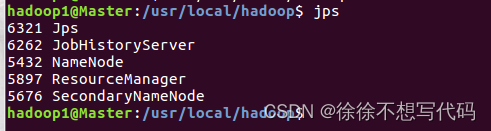

(9)通过命令“hdfs dfsadmin -report”查看数据节点是否正常启动
















 2618
2618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









