






简介:
本博客归属于第15届中国大学生服务外包创新创业大赛A29赛道中南铁道游击队
文字识别技术,亦称为光学字符识别(Optical Character Recognition, OCR),是一种将不同类型的文档(如扫描的纸张文档、PDF文件或图像)中的文字转化为机器编码文字的技术。这项技术的发展和应用在当今信息化社会中扮演着至关重要的角色。
我最近参加的一个服创的项目就需要识别题目图片里的题目信息。我才用的解决办法时调用合合信息的TextIn产品的api进行相应的识别。合合TextIn是上海合合信息科技股份有限公司旗下智能文字识别产品,专注文字识别领域16年,对企业、开发者、个人用户提供智能文字识别引擎、产品、云端服务。
如果你也想尝试以下并且应用文本识别技术到你的项目中的话可以参考以下我的使用过程。
注册合合信息账号
首先我们需要注册一个账号,登录合合TextIn官网进行注册就可以
选择想要使用的服务
然后我们要选择我们需要的服务,首先在首页点击工作台
然后为进入以下页面,在侧边栏中点击“我的机器人”,由于我使用的时api服务,这里就选择的时公有api。可以看到我已经选择好了一个服务:通用文字识别

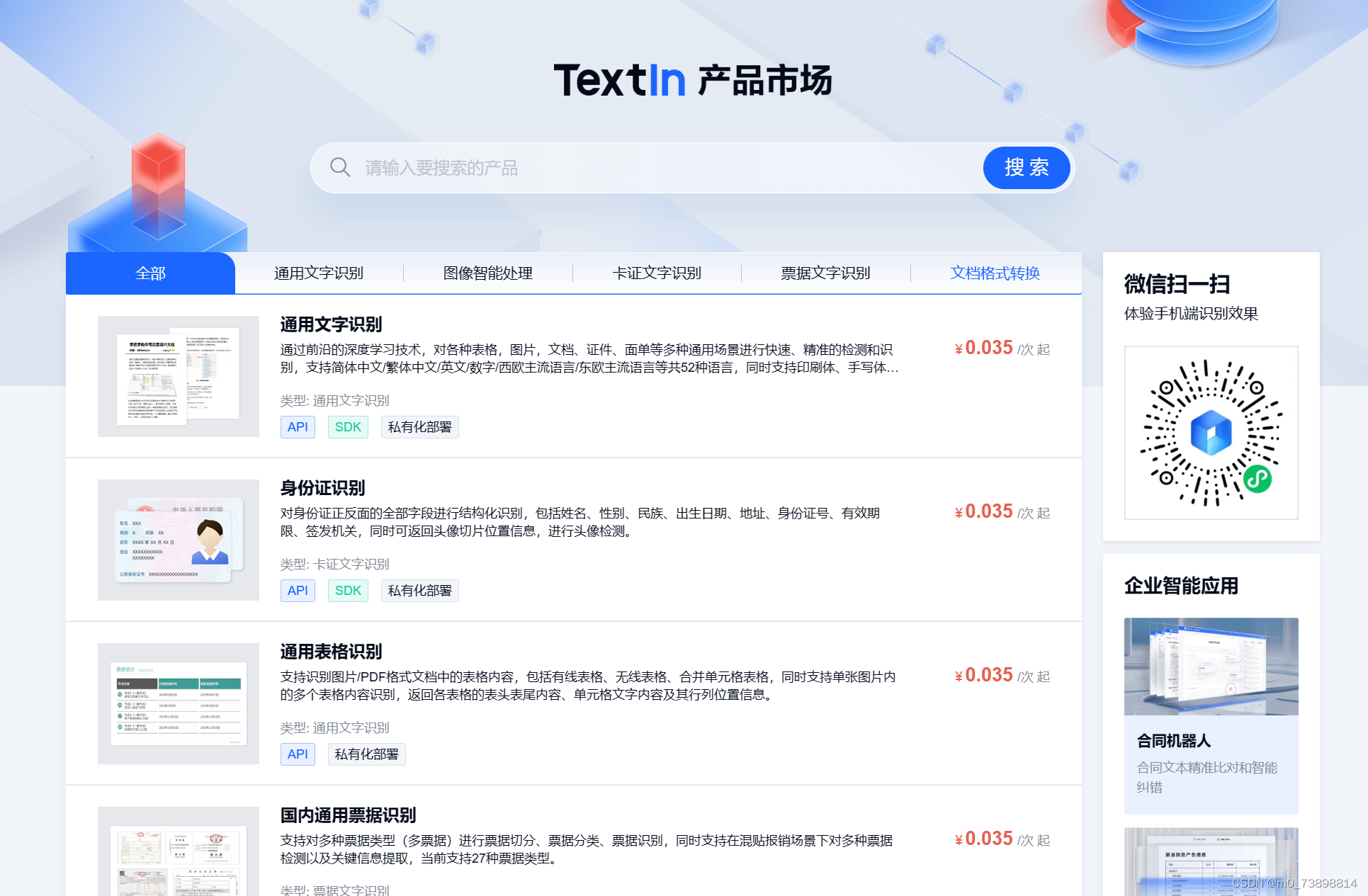
你可以添加其他的服务(机器人),点击添加机器人之后页面如下,可以看到有很多机器人可供选择,根据自己的需求选择购买即可。TextIn会对新用户提供一定的免费限额,所以一开始尝试的时候不需要担心价格,我还是以我选择的通用文字识别来进行说明
开始使用服务
添加好了自己的机器人之后就回到了以上的这个图片的界面,点击其中的api集成就可到如下页面查看详细的文档了。也可以点击左边的查看详细看你的api的使用情况和右边的在线使用快速的体验其效果。
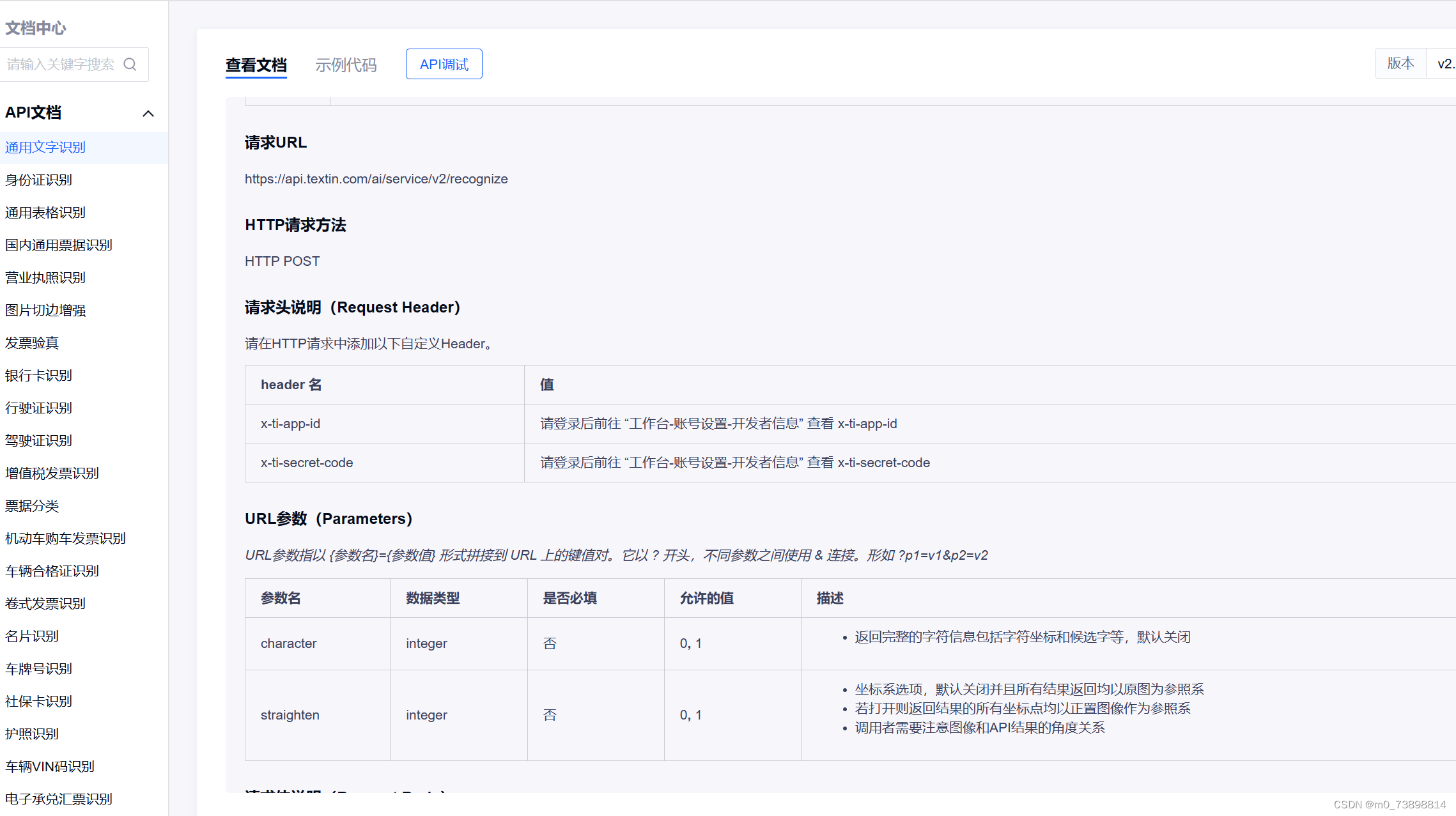
其api写的还是比较详细和通俗的,如果懒得看就想大致使用的话可以看我使用的一个范例。之后想有进一步的需求的话可以再去查看文档。
使用范例
我这里演示的是我的项目中使用到的把一个包含了一道题目的图片的文字提取出来,
我选择的图片如下:

使用前要提前知道你的x-ti-app-id和x-ti-secret-code的值,这个值可以在工作台-账号管理-开发者信息中查看。
然后我的代码如下,我这里使用的是python语言
import requests
import io
# API端点
url = 'https://api.textin.com/ai/service/v2/recognize'
# 替换这里的值为您从API提供方获取的实际值
x_ti_app_id = '你的id'
x_ti_secret_code = '你的secret code'
# 请求头部
headers = {
'x-ti-app-id': x_ti_app_id,
'x-ti-secret-code': x_ti_secret_code
}
# URL参数
# 根据API要求,这里可以设置为0或1,修改为所需的值
params = {
'character': 0, # 是否返回完整的字符信息
'straighten': 0, # 是否返回以正置图像作为参照系的坐标点
}
def get_text_from_picture_rb(img_file):
# 将图片文件转换为字节对象
img_byte_array = io.BytesIO()
img_file.save(img_byte_array, format='PNG')
img_byte_array = img_byte_array.getvalue()
# 发送HTTP POST请求
response = requests.post(url, headers=headers, params=params, data=img_byte_array)
if response.status_code == 200:
# 解析响应体为JSON
data = response.json()
return data
else:
print(response)
raise Exception(f'exception from get_text_from_picture_rb')
# 然后调用这个方法
from PIL import Image
# 调用函数
image = Image.open('img.png')
data = get_text_from_picture_rb(image)
print(data)
我们可以得到如下的结果,这里的结果很长,包含了许多信息。如果你尝试成功的话就可以看到合合的服务的功能还是很强大的,不只是提供文字的信息而且置信度,以及每个字识别的其他可能的文字,甚至还有字符的方向,是不是手写体的信息都进行提供。

这时候我们可以自取所需比如将以上代码小改一下得到其中的文本信息
def get_text_from_picture_rb(img_file):
# 将图片文件转换为字节对象
img_byte_array = io.BytesIO()
img_file.save(img_byte_array, format='PNG')
img_byte_array = img_byte_array.getvalue()
# 发送HTTP POST请求
response = requests.post(url, headers=headers, params=params, data=img_byte_array)
if response.status_code == 200:
# 解析响应体为JSON
data = response.json()
# 改动的部分,只取结果中的text对象,这里的json的格式可以去之前提到的官方文档进行查看
text = ''
for item in data['result']['lines']:
text += item['text'] + '\n'
return text
else:
print(response)
raise Exception(f'exception from get_text_from_picture_rb')
然后我们就可以得到以下结果

总结
到这里你就已经快速上手了textIn的api的基本使用方法了。我也是刚使用其没多久,不得不说体验还是很好的。识别率高,响应速度快,而且内容齐全,各种信息都有。从上面的例子可以看到,我给出的图片右下角几乎不可见的水印都被准确的识别了。不得不赞叹这个服务做的真的很好。
那么以上就是我以我的使用textIn的api的经历带给大家的textIn的api的快速上手指南,希望对大家有所帮助。















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









