






 本文详细介绍了Python中的线程与进程的区别,包括使用`threading`和`multiprocessing`模块创建线程和进程的方法,进程池的使用,以及共享内存和Lock锁的应用。着重展示了进程特有的功能,如进程池的返回值和进程间通信的机制。
本文详细介绍了Python中的线程与进程的区别,包括使用`threading`和`multiprocessing`模块创建线程和进程的方法,进程池的使用,以及共享内存和Lock锁的应用。着重展示了进程特有的功能,如进程池的返回值和进程间通信的机制。
在操作系统中,一个进程有多个线程,每个进程可以在一个CPU的一个核(core)上运行
先来看一下线程与进程在代码上的区别:
import multiprocessing as mp
import threading as td
def job(a, b):
print('Hello World')
if __name__ == '__main__':
t1 = td.Thread(target = job, args = (1, 2))
p1 = mp.Process(target = job, args = (1, 2))
t1.start()
p1.start()
t1.join()
p1.join()在创建进程的时候,也就是调用的库不太一样,其他大差不差
创建并运行一个进程:
import multiprocessing as mp
def job(a, b):
print('Hello World')
if __name__ == '__main__':
p1 = mp.Process(target = job, args = (1, 2))
p1.start()
p1.join()在进程的运行这块儿,需要到terminal(终端)来运行,其他运行代码方式会没有输出,但是cmd终端好像无法捕捉其他进程,需要到pycharm终端来执行,在此之前,莫烦老师一直用的python的IDLE来敲的代码,所以我也是一直用IDLE来学习的代码,知道碰到这个进程的代码无法执行,才知道要下载PyCharm才能运行出来,也希望大家在之后的学习中可以多使用PyCharm,就跟Java的IDEA一样,非常方便
运行结果:
Hello World
多线程:
import multiprocessing as mp
def job(q):
res = 0
for i in range(100):
res += i + i**2 + i**3
q.put(res)
if __name__ == '__main__':
q = mp.Queue()
p1 = mp.Process(target=job, args=(q,))
#在Process里面传入arg=(q,)的时候一定要加, 不然会报错
p2 = mp.Process(target=job, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
for _ in range(q.qsize()):
print(q.get())进程池pool:
共享池可以让池子对应某一个函数,我们向池子里丢数据,池子就会返回函数返回的值。Pool和之前的Process的不同点是丢向Pool的函数有返回值,而Process的没有返回值。
最基本的进程池的使用:
import multiprocessing as mp
def fun(x):
return x*x
def multicore():
pool = mp.Pool()
res = pool.map(fun, range(10))
print(res)
if __name__ == '__main__':
multicore()运行结果:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
指定用一定数量CPU内核来计算:
也就是把上面代码的第7行改为:pool = mp.pool(processes = 3)
将任务仅放在一个进程中:
import multiprocessing as mp
def fun(x):
return x*x
def multicore():
pool = mp.Pool(processes=2)#指定两个核来计算
res = pool.map(fun, range(10))
print(res)
res = pool.apply_async(fun, (2,))
print(res.get())
#mutil_res = [pool.apply_async(fun, (i,))for i in range(10)]
#print([res.get() for res in mutil_res])
if __name__ == '__main__':
multicore()用到pool.apply_async()函数,第二个参数只能写一个数据,不能写range(10)之类的多个数据
如果想要依次输出多个计算结果,那么就可以把加注释的两行代码去掉注释:
import multiprocessing as mp
def fun(x):
return x*x
def multicore():
pool = mp.Pool(processes=2)#指定两个核来计算
res = pool.map(fun, range(10))
print(res)
res = pool.apply_async(fun, (2,))
print(res.get())
mutil_res = [pool.apply_async(fun, (i,))for i in range(10)]
print([res.get() for res in mutil_res])
if __name__ == '__main__':
multicore()共享内存:
只有用共享内存才能让CPU之间有交流。
这是python常用的简写数据类型对应的表格
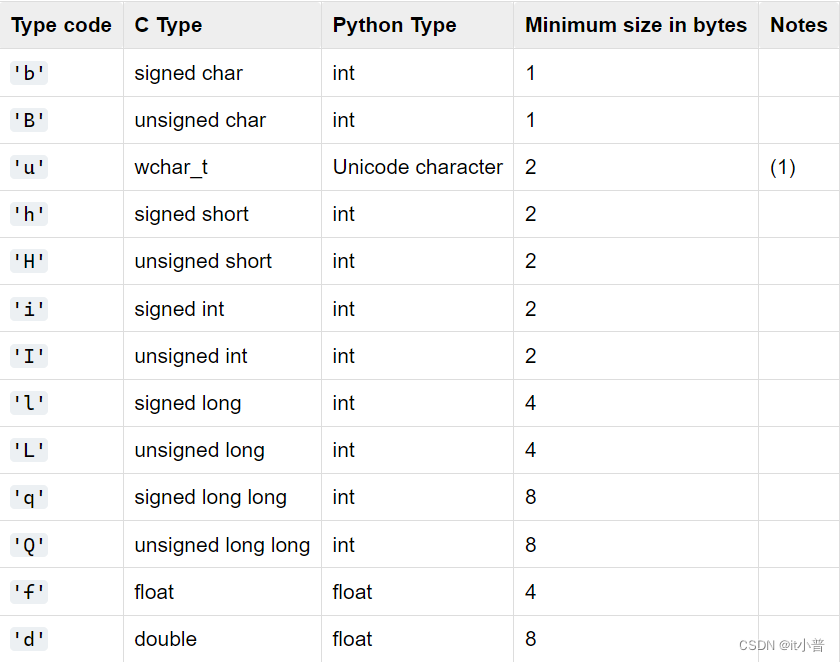
import multiprocessing as mp
value = mp.Value('d', 1)
array = mp.Array('i', [1, 2, 3])#它只能是一维的,不能是多维的有两种共享内存的种类,一个是Value,只能共享一个数据;一个是Array,可以共享一维数组
下面展示一下多线程、lock锁和共享内存的结合使用:
import multiprocessing as mp
import time
def fun(v, num, l):
l.acquire()
for _ in range(10):
time.sleep(0.1)
v.value += num
print(v.value)
l.release()
def multicore():
l = mp.Lock()
v = mp.Value('i', 0)#定义数据类型为signed int
p1 = mp.Process(target = fun, args=(v, 1, l))
p2 = mp.Process(target = fun, args=(v, 3, l))
p1.start()
p2.start()
p1.join()
p2.join()
if __name__ == '__main__':
multicore()
也就是,先让p1进程运行完(也就是+1),然后p2基于共享内存再对v.value +3
运行结果:
1
2
3
4
5
6
7
8
9
10
13
16
19
22
25
28
31
34
37
40
总结
进程这里也是面向对象语言的一大特点,当然肯定也有许多的知识亟待去学习,这里只是列举了基本的函数用法,在创建进程上与创建线程相似,在多进程上也与多线程相似。进程特有的功能就是进程池pool,这样就可以让调用的函数能够return了。















 2038
2038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









