






一、主成分分析(PCA)概述
主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维方法。它通过线性变换将原始数据变换到一个新的坐标系中,使得第一个坐标(第一主成分)具有最大的方差,第二个坐标(第二主成分)具有次大的方差,以此类推。PCA的目的是从高维数据中提取出最重要的特征,通过保留最重要的主成分来实现数据的降维,同时尽可能保留原始数据的结构。
二、PCA算法
2.1 PCA算法步骤
-
数据标准化:为了消除不同特征之间的量纲影响,通常需要对数据进行标准化处理,使得每个特征的均值为0,标准差为1。
-
计算协方差矩阵:协方差矩阵描述了数据特征之间的相关性。对于标准化后的数据,协方差矩阵可以通过计算特征之间的协方差得到。
-
计算特征值和特征向量:求解协方差矩阵的特征值和对应的特征向量。特征值和特征向量给出了数据的主要方向,即主成分。
-
选择主成分:根据特征值的大小,选择前k个最大的特征值对应的特征向量,这些特征向量构成了新的特征空间。
-
变换数据:将原始数据投影到新的特征空间中,得到降维后的数据。
2.2 PCA算法代码
首先,先获取要进行PCA操作的数据集;
from numpy import *
# 获取数据集
def loadDataSet(fileName, delim = '\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [map(float,line) for line in stringArr]
return mat(datArr)以上述获取的数据集为例,描述PCA算法的实现步骤:
- 首先计算并减去原始数据集的平均值;
- 然后,计算协方差矩阵及其特征值,接着利用argsort( )函数对特征值进行从小到大的排序。根据特征值排序结果的逆序就可以得到topNfeat个最大的特征向量;
- 这些特征向量将构成后面对数据进行转换的矩阵,该矩阵则利用N个特征将原始数据转换到新空间中。
- 最后,原始数据被重构后,返回用于调试,同时降维之后的数据集也被返回了。
# PCA算法
def pca(dataMat, topNfeat = 99999999):
#计算并减去原始数据集的平均值
meanVals = mean(dataMat, axis = 0)
meanRemoved = dataMat - meanVals
#计算协方差矩阵和特征值
covMat = cov(meanRemoved, rowvar = 0)
eigVals, eigVects = linalg.eig(mat(covMat))
#对特征值从小到大排序,并由其逆序得到特征向量
eigValInd = argsort(eigVals)
eigValInd = eigValInd[:-(topNfeat+1):-1]
redEigVects = eigVects[:, eigValInd]
#将数据转换到新空间
lowDDataMat= meanRemoved * redEigVects
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat2.3 PCA算法的优缺点
优点
- 降低数据维度:PCA可以有效地降低数据的维度,去除噪声和冗余特征,提高计算效率。
- 保留重要信息:通过保留最大的主成分,PCA可以保留数据中的大部分重要信息。
- 无需监督学习:PCA是一种无监督学习方法,不需要类别标签,适用于无法获取标签的数据。
缺点
- 线性假设:PCA假设数据的主要结构是线性的,对于非线性结构的数据可能不够有效。
- 解释性较差:降维后的主成分可能不容易解释,它们是原始特征的线性组合。
- 敏感度高:PCA对数据中的异常值比较敏感,异常值可能会对主成分的计算产生较大影响。
三、PCA算法的简单案例应用
以Python库中自带的鸢尾花数据集iris为样本数据集实现PCA算法的简单应用;
3.1 获取数据集
首先,先从Python库中下载数据集并赋值给储存数据集的变量X;
from sklearn import datasets
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data3.2 数据预处理
对获取的数据集中的数据进行标准化处理,以便后续能够更好地应用PCA算法;
# 标准化数据
X_std = (X - X.mean(axis=0)) / X.std(axis=0)3.3 PCA降维处理
为了方便,我在这里直接调用Python库中自带的PCA算法的函数;
from sklearn.decomposition import PCA
# 设置PCA参数,这里我们选择保留90%的方差
pca = PCA(n_components=0.9)
X_pca = pca.fit_transform(X_std)3.4 可视化降维前后的数据集
3.4.1 导入库包
先导入Python中用于可视化的库包 matplotlib.pyplot;
# 可视化原始数据和降维后的数据
import matplotlib.pyplot as plt
3.4.2 可视化降维前的数据集
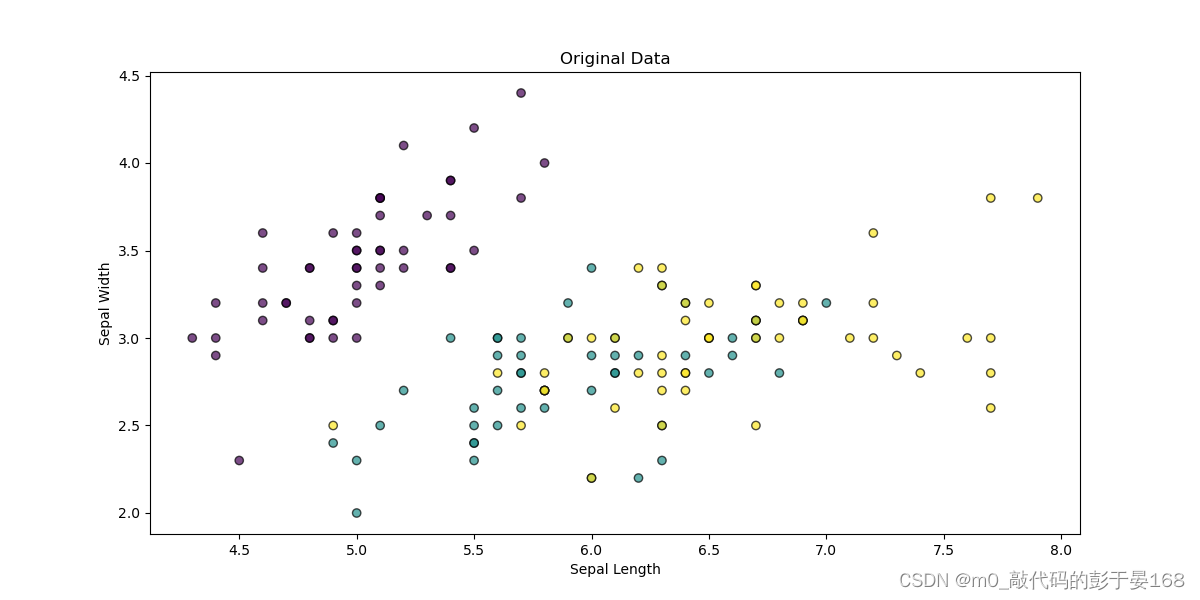
- 下面的图表显示了降维前的数据分布。这里我们只展示了前两个特征,但鸢尾花数据集实际上有四个特征维度。
可视化代码
# 原始数据
#plt.subplot(1, 2, 1)
plt.figure(figsize=(12, 6))
plt.scatter(X[:, 0], X[:, 1], c=iris.target, edgecolor='k', alpha=0.7)
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Original Data')
plt.show()降维前的数据集可视化结果展示
3.4.3 可视化降维后的数据集
可视化代码
# 降维后的数据
#plt.subplot(1, 2, 2)
plt.figure(figsize=(12, 6));
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=iris.target, edgecolor='k', alpha=0.7)
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.title('Data after PCA')
plt.show()- 下面的图表显示了应用PCA并将数据降至两个主成分后的分布。可以看到,尽管数据被压缩到二维,但主要的聚类结构仍然被保留,不同类别的数据点仍然可以被清晰地区分开来。
降维后的数据集可视化结果展示

3.5 完整代码
from sklearn import datasets
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
# 标准化数据
X_std = (X - X.mean(axis=0)) / X.std(axis=0)
from sklearn.decomposition import PCA
# 设置PCA参数,这里我们选择保留90%的方差
pca = PCA(n_components=0.9)
X_pca = pca.fit_transform(X_std)
# 可视化原始数据和降维后的数据
import matplotlib.pyplot as plt
# 原始数据
#plt.subplot(1, 2, 1)
plt.figure(figsize=(12, 6))
plt.scatter(X[:, 0], X[:, 1], c=iris.target, edgecolor='k', alpha=0.7)
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Original Data')
plt.show()
# 降维后的数据
#plt.subplot(1, 2, 2)
plt.figure(figsize=(12, 6));
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=iris.target, edgecolor='k', alpha=0.7)
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.title('Data after PCA')
plt.show()
# 输出主成分的方差贡献率
explained_variance_ratio = pca.explained_variance_ratio_
print("主成分的方差贡献率:", explained_variance_ratio)四、实验小结
降维技术使得数据变得更易使用,并且它们往往能够去除数据中的噪声,使得其他机器学习任务更加精确。降维往往作为预处理步骤,在数据应用到其他算法之前清洗数据。有很多技术可以用于数据降维,如独立成分分析、因子分析和主成分分析比较流行,其中又以主成分分析应用最为广泛。
PCA可以从数据中识别其主要特征,它是通过沿着数据最大方差方向旋转坐标轴来实现的。选择方差最大的方向作为第一条坐标轴,后续坐标轴则与前面的坐标轴正交。而其协方差矩阵上的特征值分析可以用一系列的正交坐标轴来获取。
到这里,本篇博文的PCA算法的阐述与实现也告一段落了,希望大家都能在自己所喜欢的领域努力实现自己的小目标!!!
















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









