



在 Python 爬虫中,XPath 是一种强大的工具,用于在 HTML 或 XML 文档中定位元素。
1. 安装必要的库
首先需要安装requests和lxml库:pip install requests lxml
2. 基本 XPath 语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。以下是一些常用的 XPath 表达式:
//tagname:选取所有tagname元素,无论它们在文档中的位置/tagname:从根节点选取tagname元素tagname[@attribute='value']:选取具有指定属性值的元素tagname[position()]:选取指定位置的元素.:选取当前节点..:选取当前节点的父节点@attribute:选取属性
3. 注意事项
- 处理动态内容:如果页面内容是通过 JavaScript 动态加载的,
requests无法获取完整内容,需要使用 Selenium 等工具 - 避免频繁请求:爬虫可能会对目标网站造成压力,应合理设置请求间隔
- 遵守 robots.txt:爬取前应查看网站的 robots.txt 文件,了解爬取规则
- 异常处理:网络请求可能失败,需要适当的异常处理机制
4.进阶技巧
- 处理相对路径:使用
.作为上下文节点 - 使用谓语:如
//div[@id="content"][last()]选择最后一个具有特定 id 的 div - 处理命名空间:XML 文档中可能存在命名空间,需要特殊处理
-
下面给大家演示一下Python 中使用 XPath 的示例:
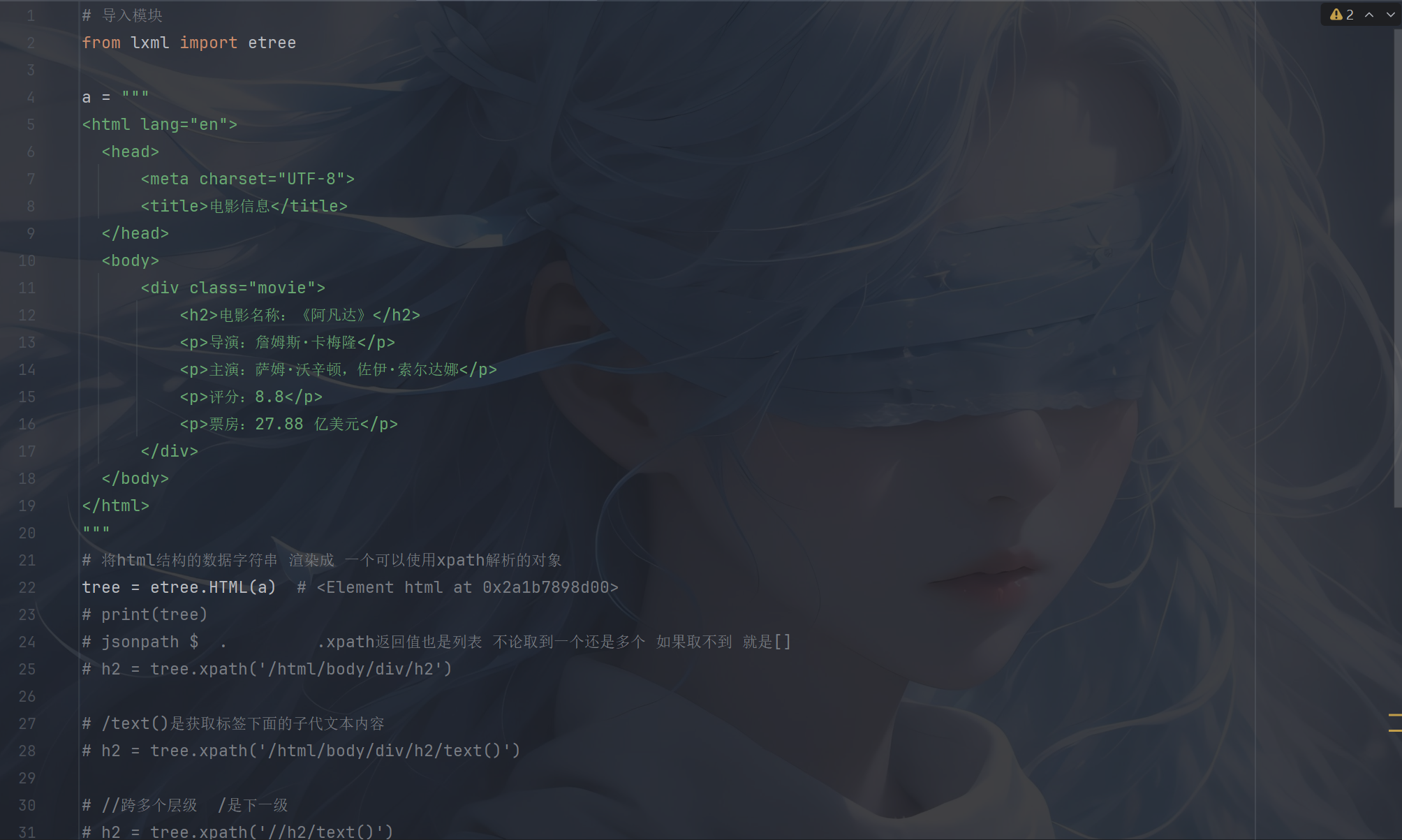

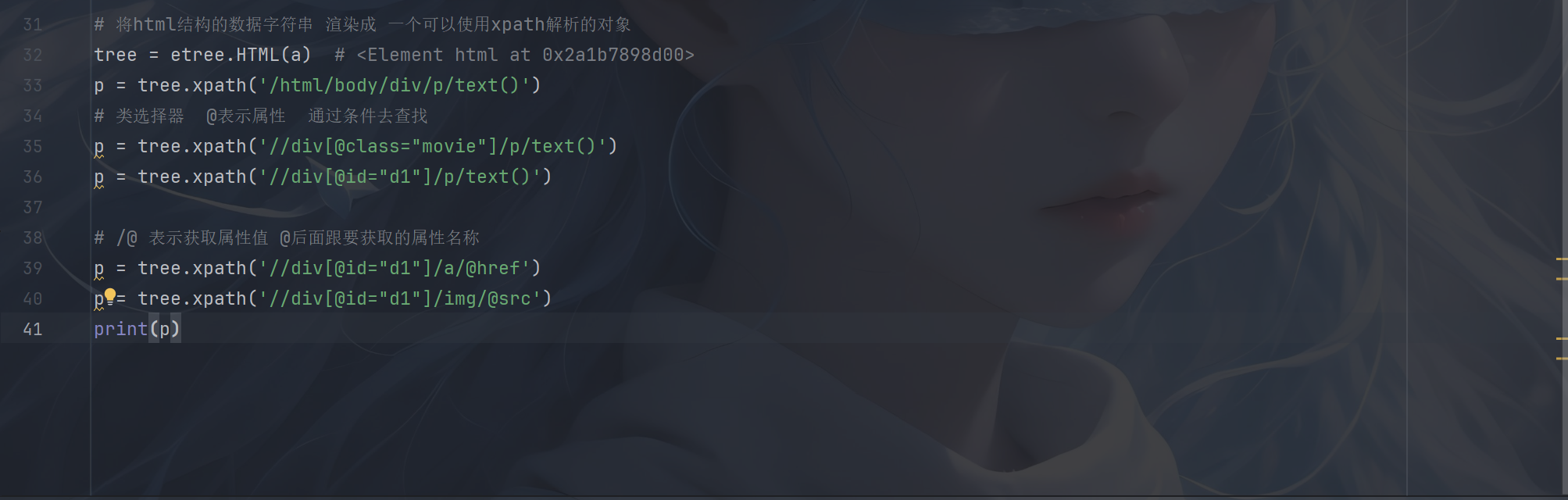
接下来是实战案例:
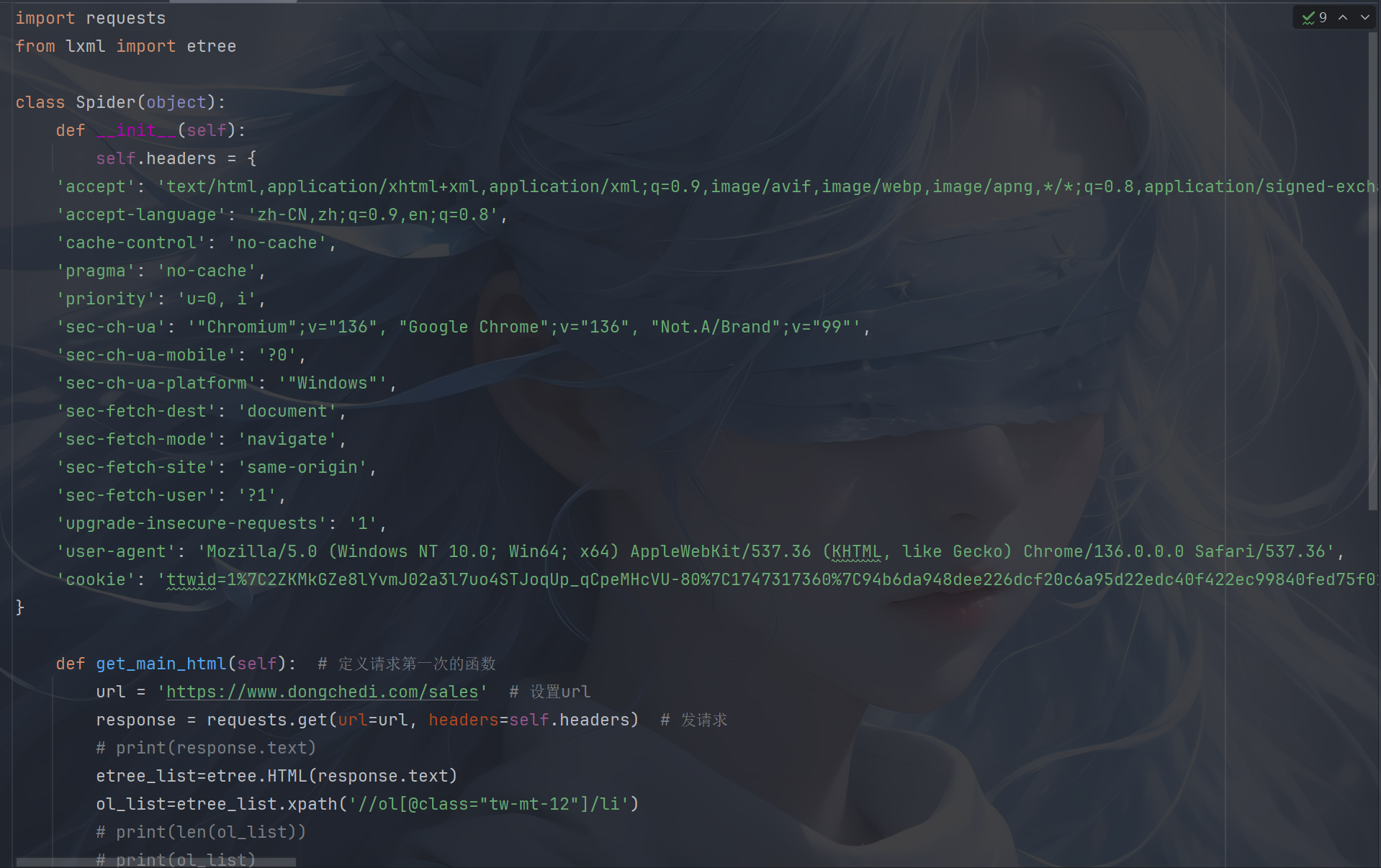
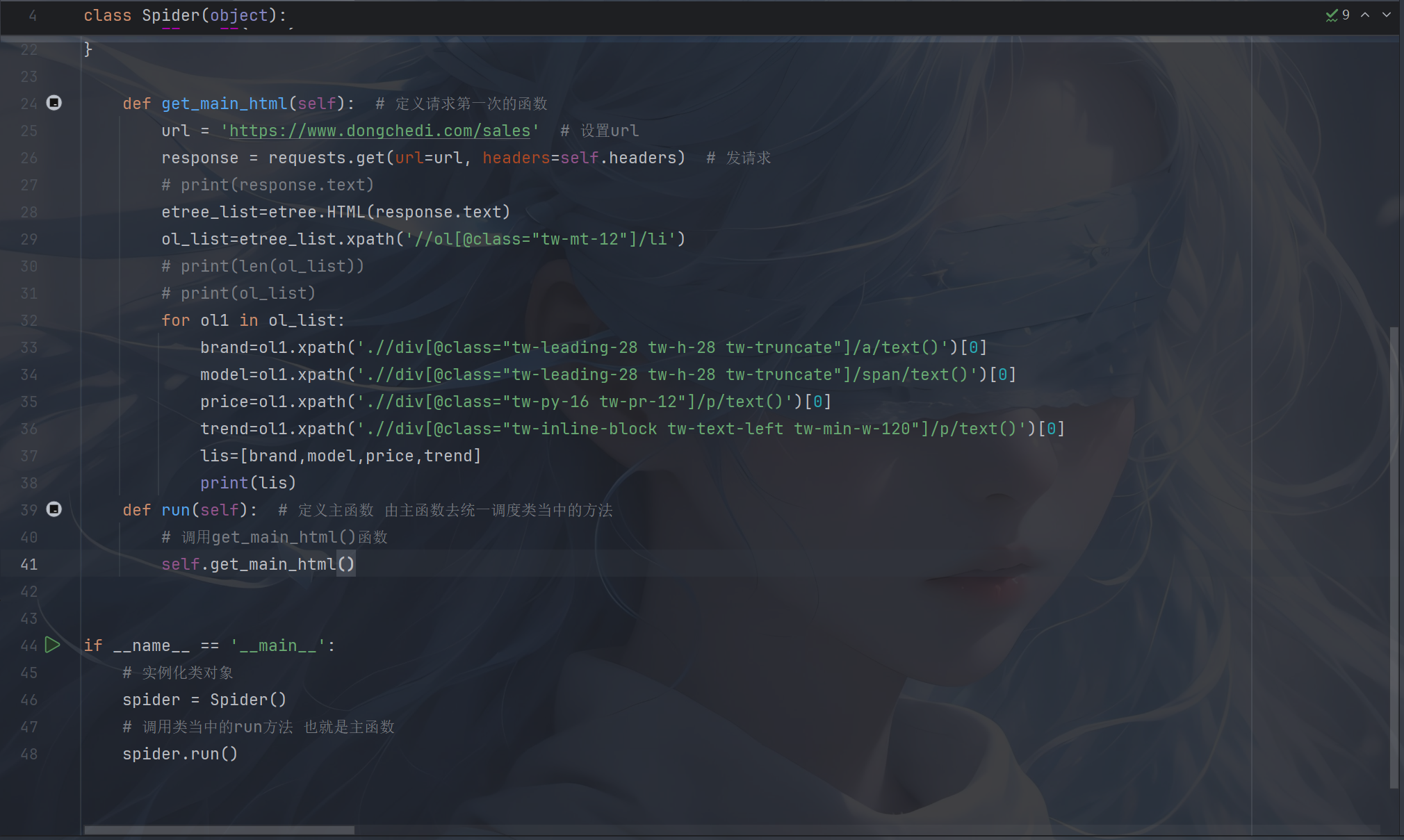
我这里运用了面向对象的基本结构,并且使用了在线curl命令转代码来写入的headers和获取到的url
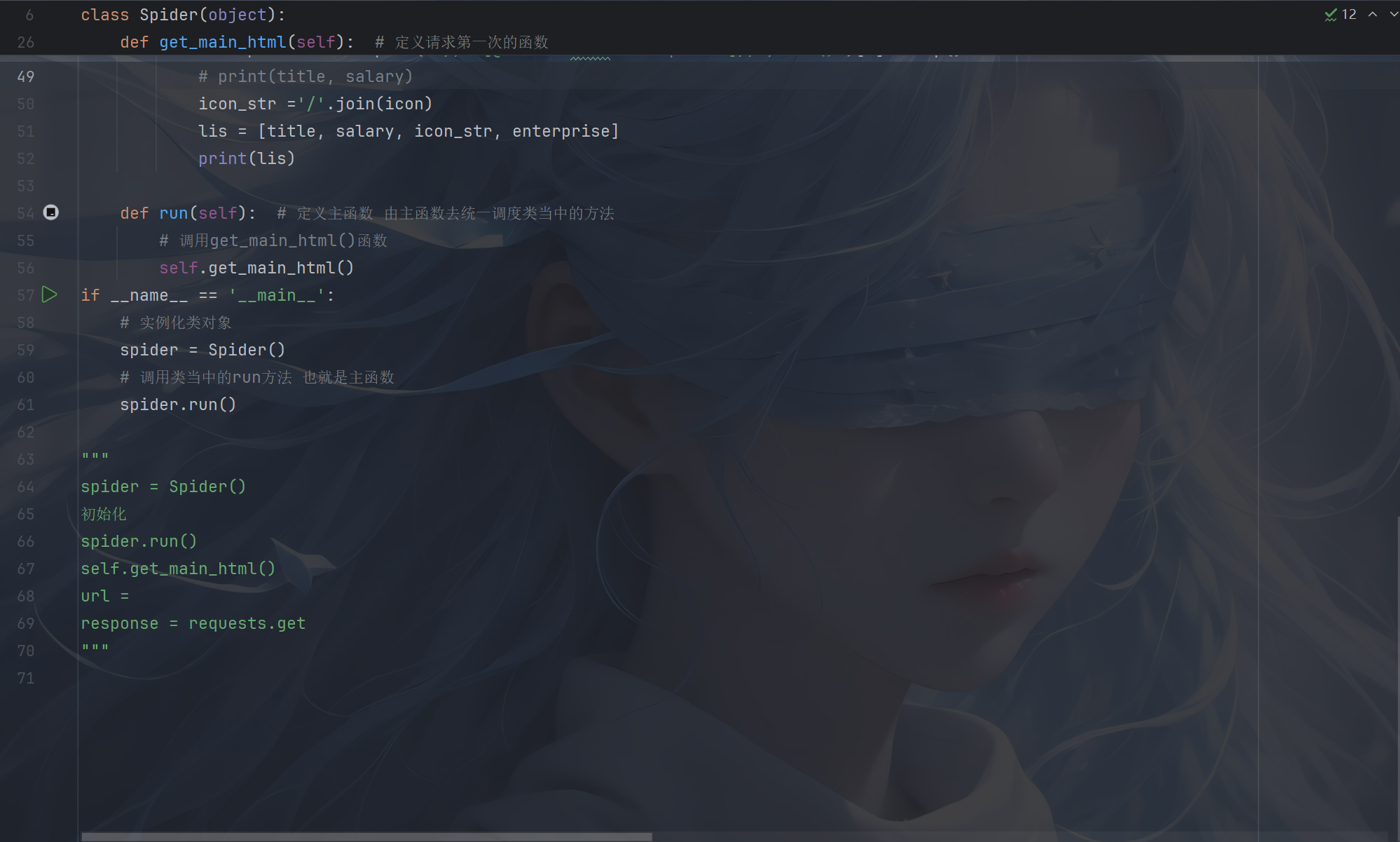
1.爬取赶集网数据
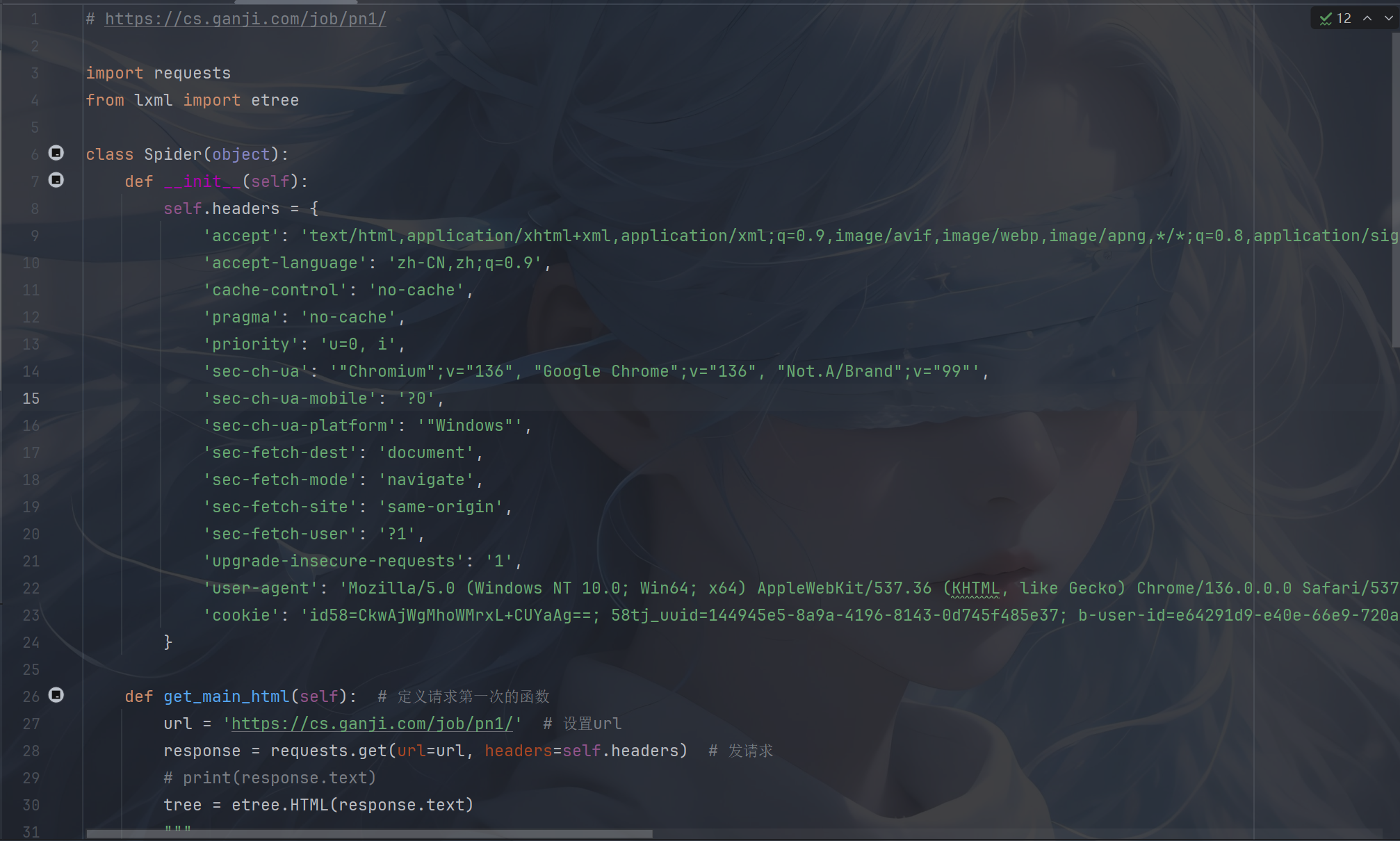
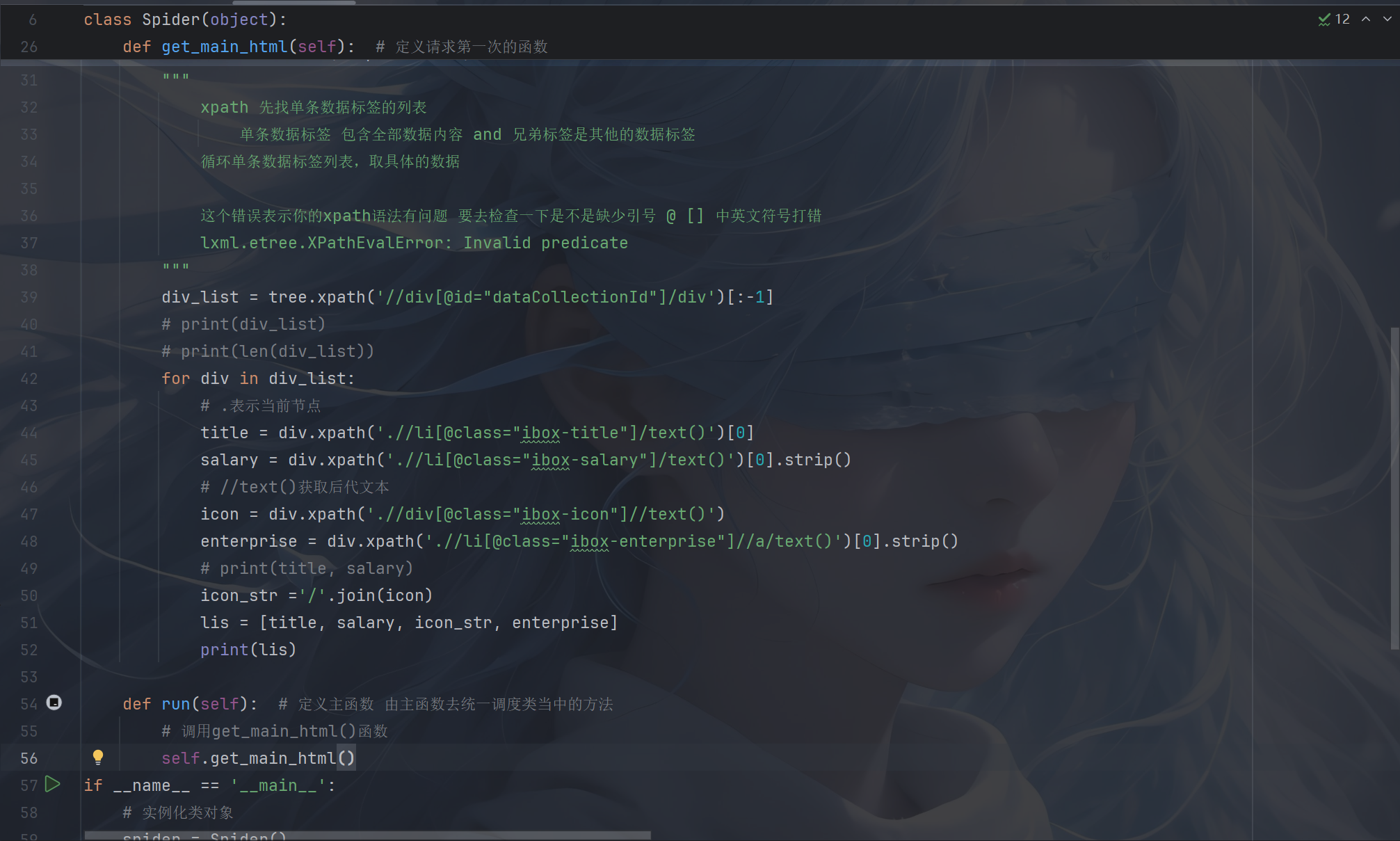
2.爬取懂车帝:

















 58万+
58万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









