







一、MyBatis查询语句专题
模块名:mybatis-008-select
打包方式:jar 引入依赖:mysql驱动依赖、mybatis依赖、logback依赖、junit依赖。
引入配置文件:jdbc.properties、mybatis-config.xml、logback.xml
创建pojo类:Car
创建Mapper接口:CarMapper
创建Mapper接口对应的映射文件:CarMapper.xml
创建单元测试:CarMapperTest
拷贝工具类:SqlSessionUtil
1.返回Car
当查询的结果,有对应的实体类,并且查询结果只有一条时:
/**
* Car SQL映射器
*/
public interface CarMapper {
/**
* 根据id主键查询:结果最多只有一条
* @param id
* @return
*/
Car selectById(Long id);
}
<select id="selectById" resultType="Car">
select id, car_num as carNum, brand, guide_price as guidePrice, produce_time as produceTime, car_type as carType
from t_car
where id = #{id}
</select>public class CarMapperTest {
@Test
public void testSelectById(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
Car car = mapper.selectById(35L);
System.out.println(car);
}
}执行结果:

查询结果是一条的话可以使用List集合接收吗?当然可以。
@Test
public void testSelectByIdToList(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
List<Car> cars = mapper.selectByIdToList(35L);
System.out.println(cars);
}执行结果:

2.返回List<Car>
当查询的记录条数是多条的时候,必须使用集合接收。如果使用单个实体类接收会出现异常。
/**
* 查询所有的Car
* @return
*/
List<Car> selectAll();<select id="selectAll" resultType="Car">
select id,car_num carNum,brand,guide_price guidePrice,produce_time produceTime,car_type carType from t_car
</select>@Test
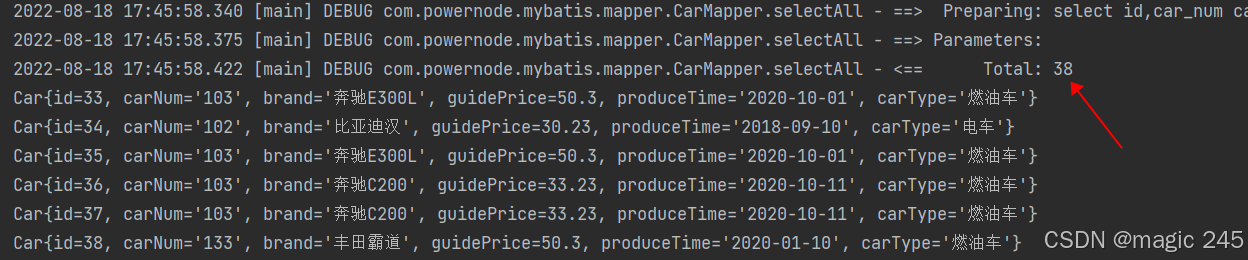
public void testSelectAll(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
List<Car> cars = mapper.selectAll();
cars.forEach(car -> System.out.println(car));
}
如果返回多条记录,采用单个实体类接收会怎样?
/**
* 查询多条记录,采用单个实体类接收会怎样?
* @return
*/
Car selectAll2();<select id="selectAll2" resultType="Car">
select id,car_num carNum,brand,guide_price guidePrice,produce_time produceTime,car_type carType from t_car
</select>@Test
public void testSelectAll2(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
Car car = mapper.selectAll2();
System.out.println(car);
}3.返回Map
当返回的数据,没有合适的实体类对应(比如返回的应该对应User类,里面的pojo只有Car类)的话,可以采用Map集合接收。字段名做key,字段值做value。 查询如果可以保证只有一条数据,则返回一个Map集合即可。

/**
* 通过id查询一条记录,返回Map集合
* @param id
* @return
*/
Map<String, Object> selectByIdRetMap(Long id);<select id="selectByIdRetMap" resultType="map">
select id,car_num carNum,brand,guide_price guidePrice,produce_time produceTime,car_type carType from t_car where id = #{id}
</select>resultMap="map",这是因为mybatis内置了很多别名。【参见mybatis开发手册】
@Test
public void testSelectByIdRetMap(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
Map<String,Object> car = mapper.selectByIdRetMap(35L);
System.out.println(car);
}执行结果:

当然,如果返回一个Map集合,可以将Map集合放到List集合中吗?当然可以,这里就不再测试了。 反过来,如果返回的不是一条记录,是多条记录的话,只采用单个Map集合接收,这样同样会出现之前的异常:TooManyResultsException
4.返回List<Map>
查询结果条数大于等于1条数据,则可以返回一个存储Map集合的List集合。List<Map>等同于List<Car>

/**
* 查询所有的Car,返回一个List集合。List集合中存储的是Map集合。
* @return
*/
List<Map<String,Object>> selectAllRetListMap();<select id="selectAllRetListMap" resultType="map">
select id,car_num carNum,brand,guide_price guidePrice,produce_time produceTime,car_type carType from t_car
</select>@Test
public void testSelectAllRetListMap(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
List<Map<String,Object>> cars = mapper.selectAllRetListMap();
System.out.println(cars);
}执行结果:
[
{carType=燃油车, carNum=103, guidePrice=50.30, produceTime=2020-10-01, id=33, brand=奔驰E300L},
{carType=电车, carNum=102, guidePrice=30.23, produceTime=2018-09-10, id=34, brand=比亚迪汉},
{carType=燃油车, carNum=103, guidePrice=50.30, produceTime=2020-10-01, id=35, brand=奔驰E300L},
{carType=燃油车, carNum=103, guidePrice=33.23, produceTime=2020-10-11, id=36, brand=奔驰C200},
......
]5.返回Map<String,Map>
拿Car的id做key,以后取出对应的Map集合时更方便。
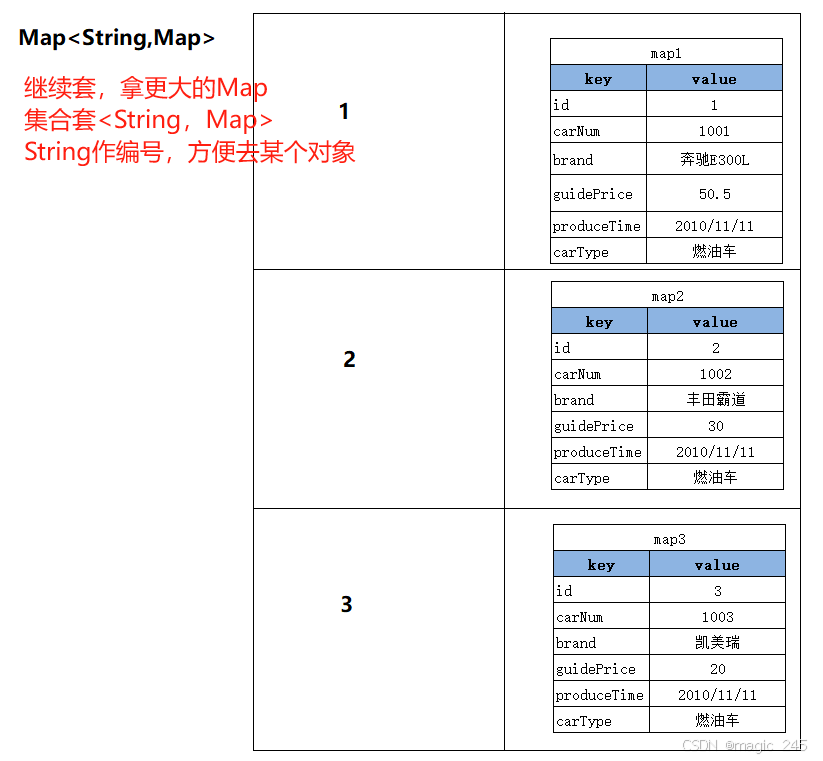
/**
* 查询所有的Car,返回一个大Map集合。
* Map集合的key是每条记录的主键值。
* Map集合的value是每条记录。
* {
* 160={car_num=3333, id=160, guide_price=32.00, produce_time=2000-10-10, brand=奔驰E300L, car_type=新能源},
* 161={car_num=4444, id=161, guide_price=32.00, produce_time=2000-10-10, brand=奔驰C200, car_type=新能源},
* 162={car_num=9999, id=162, guide_price=30.00, produce_time=2020-10-11, brand=帕萨特, car_type=燃油车},
* 163={car_num=9991, id=163, guide_price=30.00, produce_time=2020-11-11, brand=凯美瑞, car_type=燃油车},
* 158={car_num=1111, id=158, guide_price=3.00, produce_time=2000-10-10, brand=比亚迪汉, car_type=新能源},
* 159={car_num=2222, id=159, guide_price=32.00, produce_time=2000-10-10, brand=比亚迪秦, car_type=新能源}
* }
* @return
*/
@MapKey("id") // 将查询结果的id值作为整个大Map集合的key。
Map<Long, Map<String,Object>> selectAllRetMap();<select id="selectAllRetMap" resultType="map">
select id,car_num carNum,brand,guide_price guidePrice,produce_time produceTime,car_type carType from t_car
</select>@Test
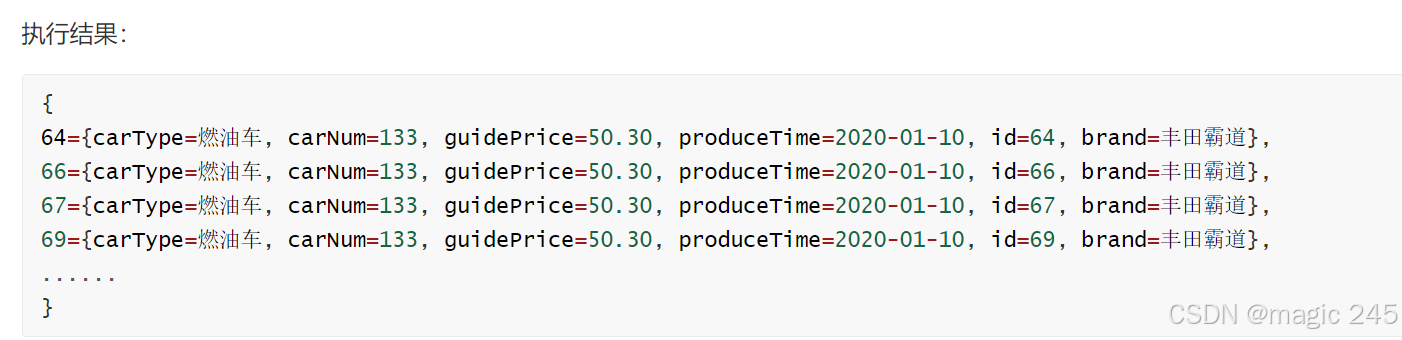
public void testSelectAllRetMap(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
Map<Long,Map<String,Object>> cars = mapper.selectAllRetMap();
System.out.println(cars);
}
6.resultMap结果映射
查询结果的列名和java对象的属性名对应不上怎么办?
-
第一种方式:as 给列起别名
-
第二种方式:使用resultMap进行结果映射
-
第三种方式:是否开启驼峰命名自动映射(配置settings)
⑴.使用resultMap进行结果映射
/**
* 查询所有Car,使用resultMap进行结果映射
* @return
*/
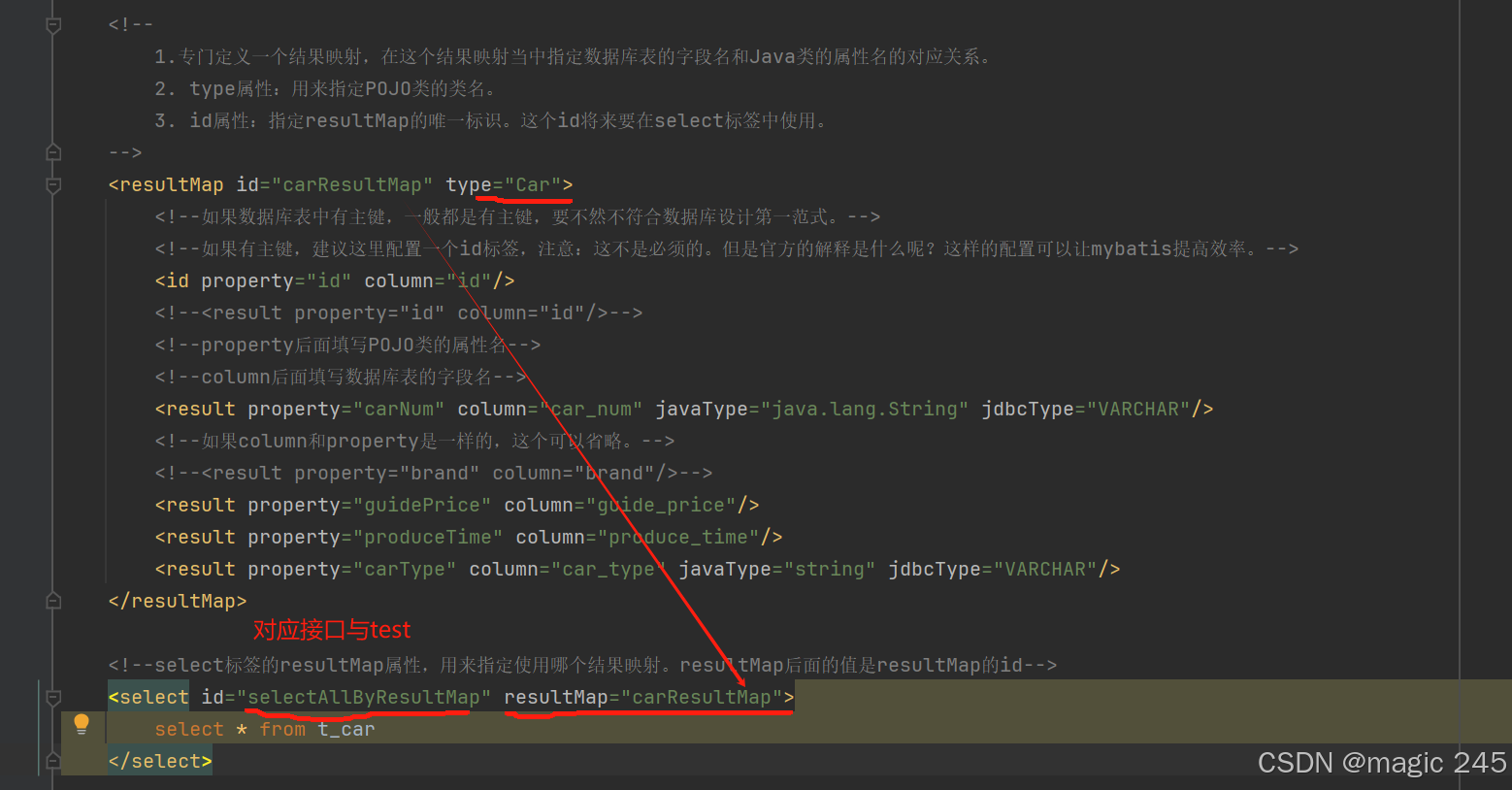
List<Car> selectAllByResultMap(); <!--
1.专门定义一个结果映射,在这个结果映射当中指定数据库表的字段名和Java类的属性名的对应关系。
2. type属性:用来指定POJO类的类名。
3. id属性:指定resultMap的唯一标识。这个id将来要在select标签中使用。
-->
<resultMap id="carResultMap" type="Car">
<!--如果数据库表中有主键,一般都是有主键,要不然不符合数据库设计第一范式。-->
<!--如果有主键,建议这里配置一个id标签,注意:这不是必须的。但是官方的解释是什么呢?这样的配置可以让mybatis提高效率。-->
<id property="id" column="id"/>
<!--<result property="id" column="id"/>-->
<!--property后面填写POJO类的属性名-->
<!--column后面填写数据库表的字段名-->
<result property="carNum" column="car_num" javaType="java.lang.String" jdbcType="VARCHAR"/>
<!--如果column和property是一样的,这个可以省略。-->
<!--<result property="brand" column="brand"/>-->
<result property="guidePrice" column="guide_price"/>
<result property="produceTime" column="produce_time"/>
<result property="carType" column="car_type" javaType="string" jdbcType="VARCHAR"/>
</resultMap>
<!--select标签的resultMap属性,用来指定使用哪个结果映射。resultMap后面的值是resultMap的id-->
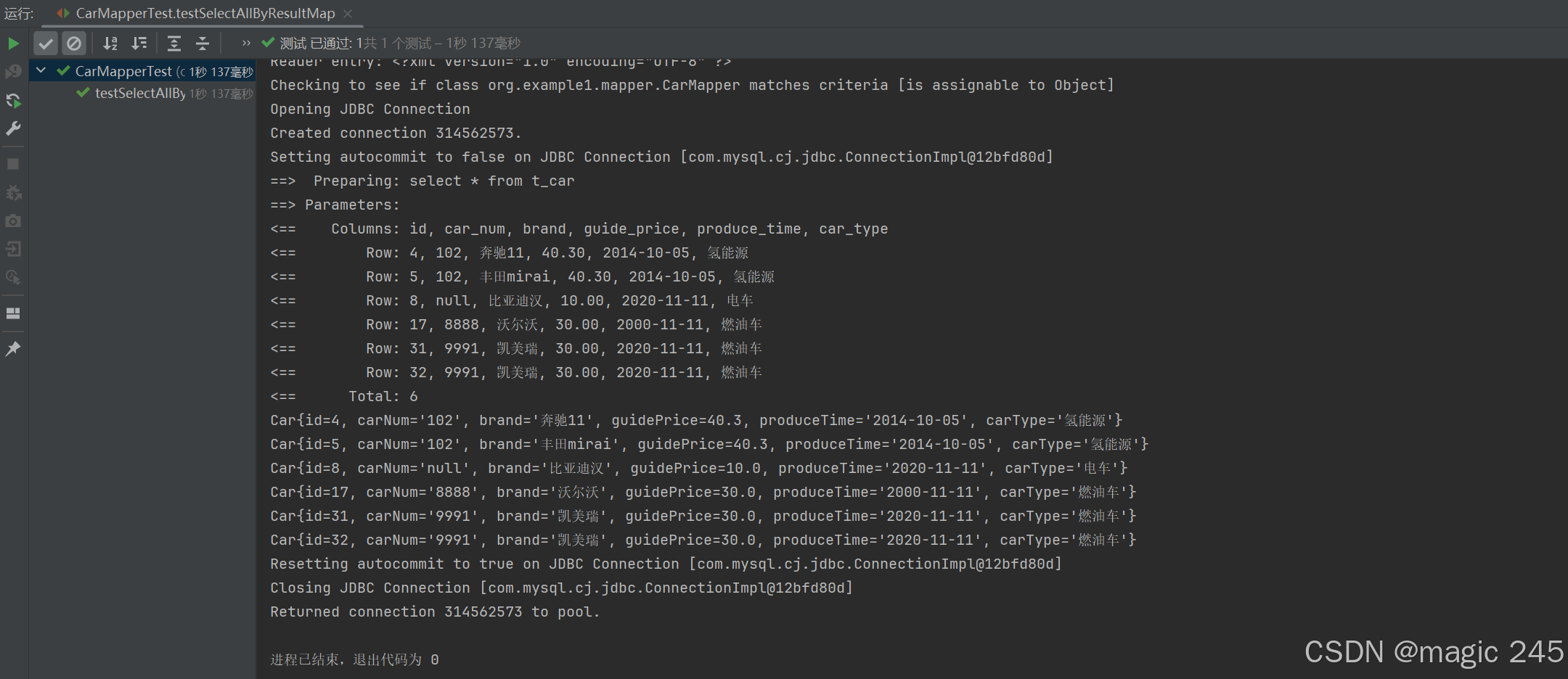
<select id="selectAllByResultMap" resultMap="carResultMap">
select * from t_car
</select> @Test
public void testSelectAllByResultMap(){
SqlSession sqlSession = SqlSessionUtil.openSession();
CarMapper mapper = sqlSession.getMapper(CarMapper.class);
List<Car> cars = mapper.selectAllByResultMap();
cars.forEach(car -> System.out.println(car));
sqlSession.close();
}
⑵是否开启驼峰命名自动映射
使用这种方式的前提是:属性名遵循Java的命名规范,数据库表的列名遵循SQL的命名规范。 Java命名规范:首字母小写,后面每个单词首字母大写,遵循驼峰命名方式。
SQL命名规范:全部小写,单词之间采用下划线分割。
比如以下的对应关系:

如何启用该功能,在mybatis-config.xml文件中进行配置:
<!--放在properties标签后面-->
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>/**
* 查询所有Car,启用驼峰命名自动映射
* @return
*/
List<Car> selectAllByMapUnderscoreToCamelCase();<select id="selectAllByMapUnderscoreToCamelCase" resultType="Car">
select * from t_car
</select>@Test
public void testSelectAllByMapUnderscoreToCamelCase(){
CarMapper carMapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
List<Car> cars = carMapper.selectAllByMapUnderscoreToCamelCase();
System.out.println(cars);
}7.返回总记录条数
需求:查询总记录条数
/**
* 获取总记录条数
* @return
*/
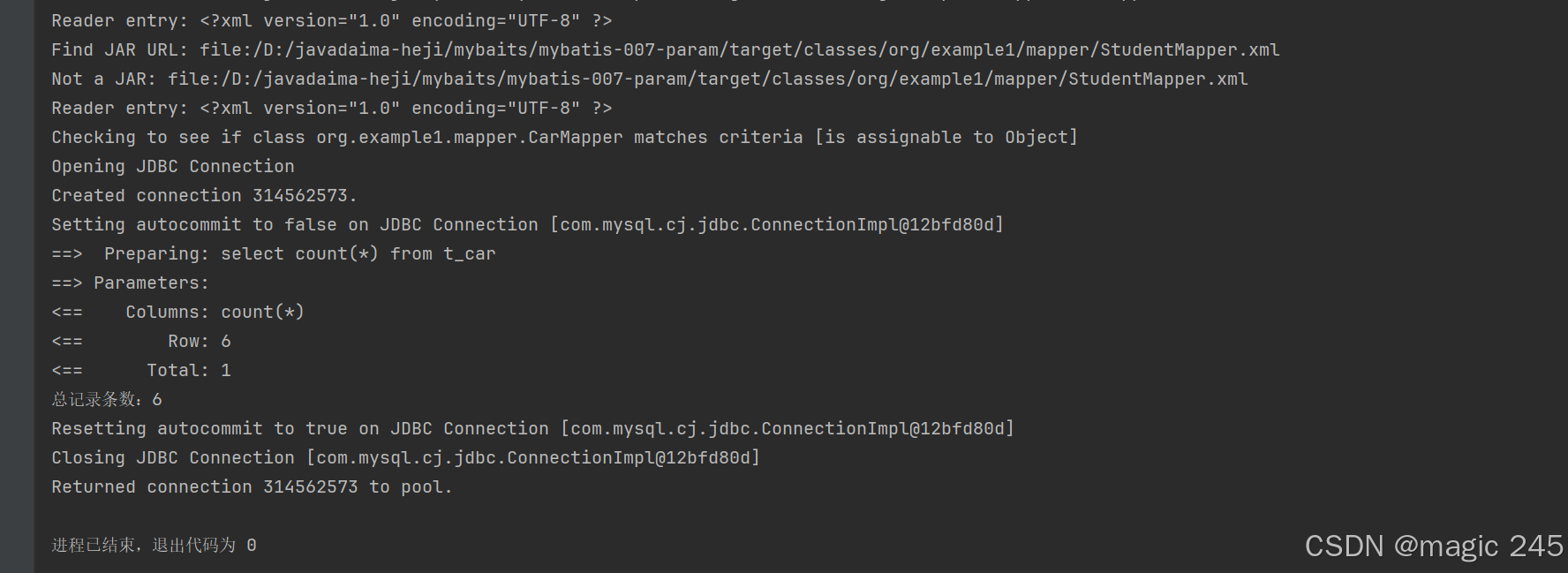
Long selectTotal();<!--long是别名,可参考mybatis开发手册。-->
<select id="selectTotal" resultType="long">
select count(*) from t_car
</select>@Test
public void testSelectTotal(){
CarMapper carMapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
Long total = carMapper.selectTotal();
System.out.println(total);
}
二、动态SQL
有的业务场景,也需要SQL语句进行动态拼接,例如:
-
批量删除

delete from t_car where id
in(1,2,3,4,5,6,......这里的值是动态的,根据用户选择的id不同,值是不同的);-
多条件查询

select * from t_car where brand like '丰田%' and guide_price > 30 and .....;创建模块:mybatis-009-dynamic-sql
打包方式:jar 引入依赖:mysql驱动依赖、mybatis依赖、logback依赖、junit依赖。
引入配置文件:jdbc.properties、mybatis-config.xml、logback.xml
创建pojo类:Car
创建Mapper接口:CarMapper
创建Mapper接口对应的映射文件:CarMapper.xml
创建单元测试:CarMapperTest
拷贝工具类:SqlSessionUtil
1.if标签
需求:多条件查询。 可能的条件包括:品牌(brand)、指导价格(guide_price)、汽车类型(car_type)
CarMapper接口
package com.powernode.mybatis.mapper;
import com.powernode.mybatis.pojo.Car;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface CarMapper {
/**
* 多条件查询
* @param brand 品牌
* @param guidePrice 指导价
* @param carType 汽车类型
* @return
*/
List<Car> selectByMultiCondition(@Param("brand") String brand, @Param("guidePrice") Double guidePrice, @Param("carType") String carType);
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.example1.mapper.CarMapper">
<select id="selectByMultiCondition" resultType="car">
<!--
1. if标签中test属性是必须的。
2. if标签中test属性的值是false或者true。
3. 如果test是true,则if标签中的sql语句就会拼接。反之,则不会拼接。
4. test属性中可以使用的是:
当使用了@Param注解,那么test中要出现的是@Param注解指定的参数名。@Param("brand"),那么这里只能使用brand
当没有使用@Param注解,那么test中要出现的是:param1 param2 param3 arg0 arg1 arg2....
当使用了POJO,那么test中出现的是POJO类的属性名。
5. 在mybatis的动态SQL当中,不能使用&&,只能使用and。
-->
select * from t_car where
<if test="brand != null and brand != ''">
brand like #{brand}"%"
</if>
<if test="guidePrice != null and guidePrice != ''">
and guide_price >= #{guidePrice}
</if>
<if test="carType != null and carType != ''">
and car_type = #{carType}
</if>
</select>
</mapper>
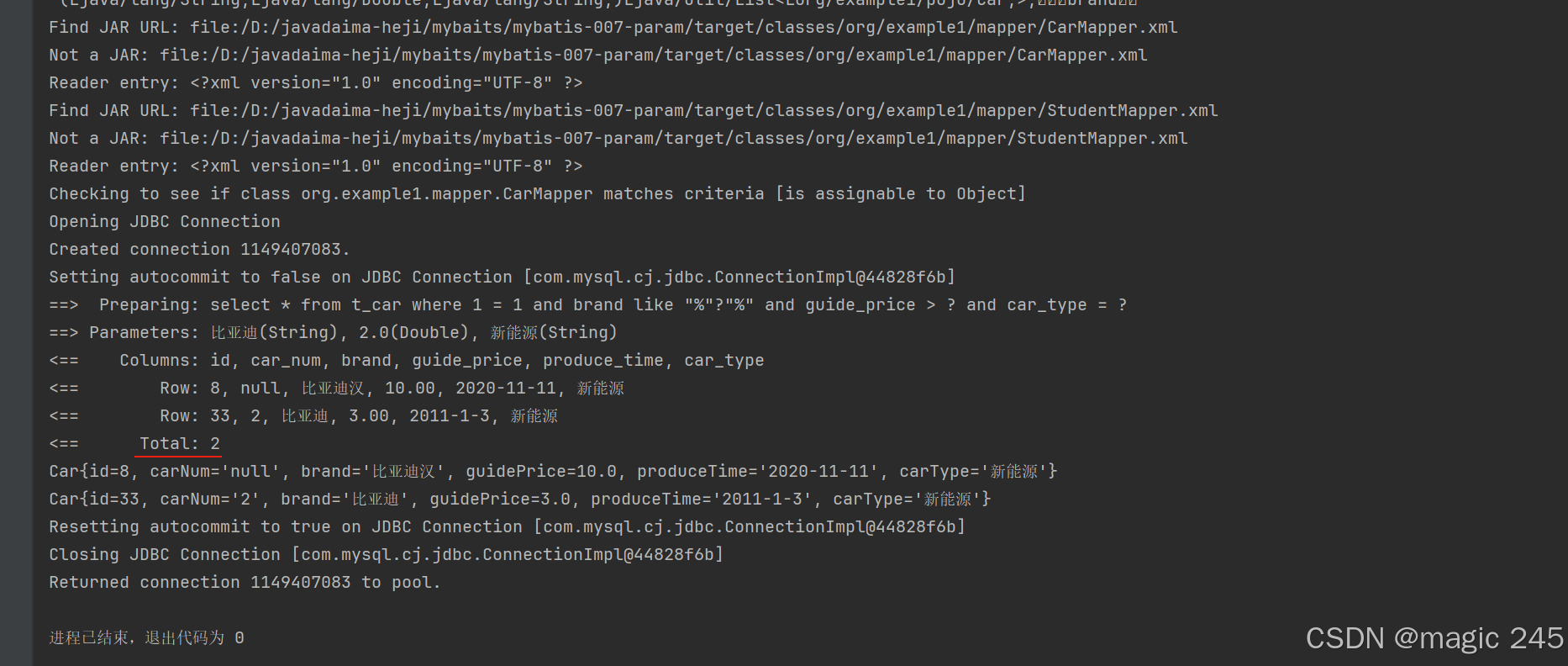
// 假设三个条件都不是空
@Test
public void testSelectByMultiCondition(){
SqlSession sqlSession = SqlSessionUtil.openSession();
CarMapper mapper = sqlSession.getMapper(CarMapper.class);
// 假设三个条件都不是空
List<Car> cars = mapper.selectByMultiCondition("比亚迪", 2.00, "新能源");
// 假设三个条件都是空
//List<Car> cars = mapper.selectByMultiCondition("", null, "");
// 假设后两个条件不为空,第一个条件为空
//List<Car> cars = mapper.selectByMultiCondition("", 2.0, "新能源");
// 假设第一个条件不是空,后两个条件是空
//List<Car> cars = mapper.selectByMultiCondition("比亚迪", null, "");
cars.forEach(car -> System.out.println(car));
sqlSession.close();
}
// 假设三个条件都是空
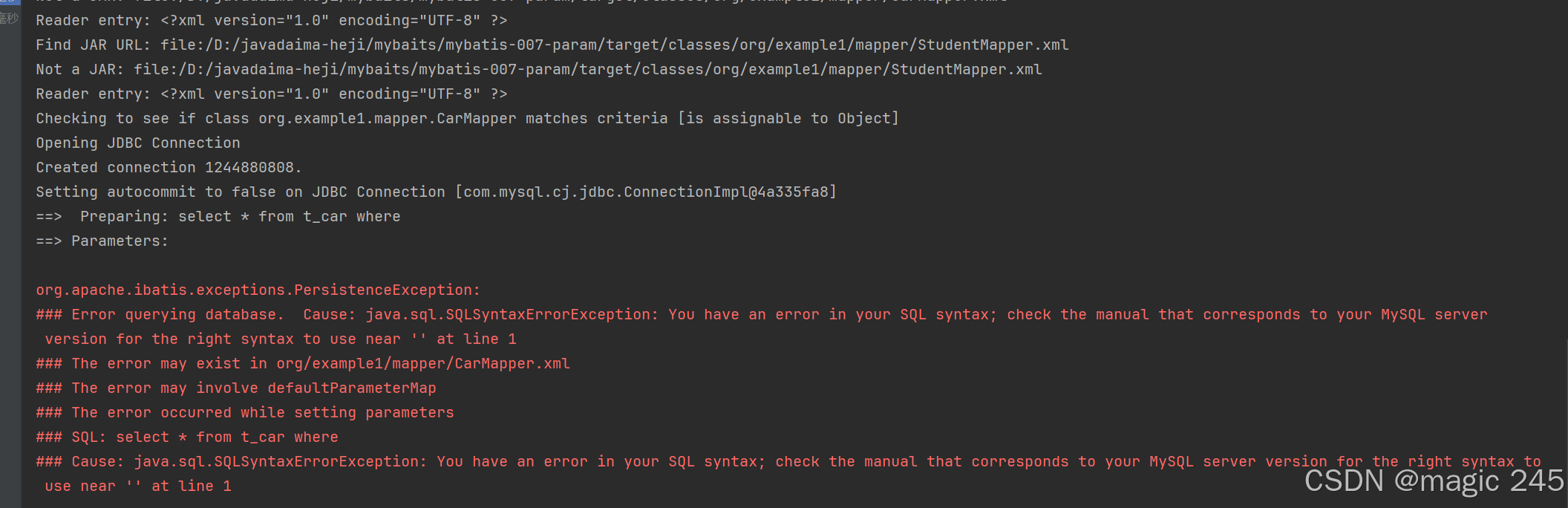
解决方法:
运行结果:
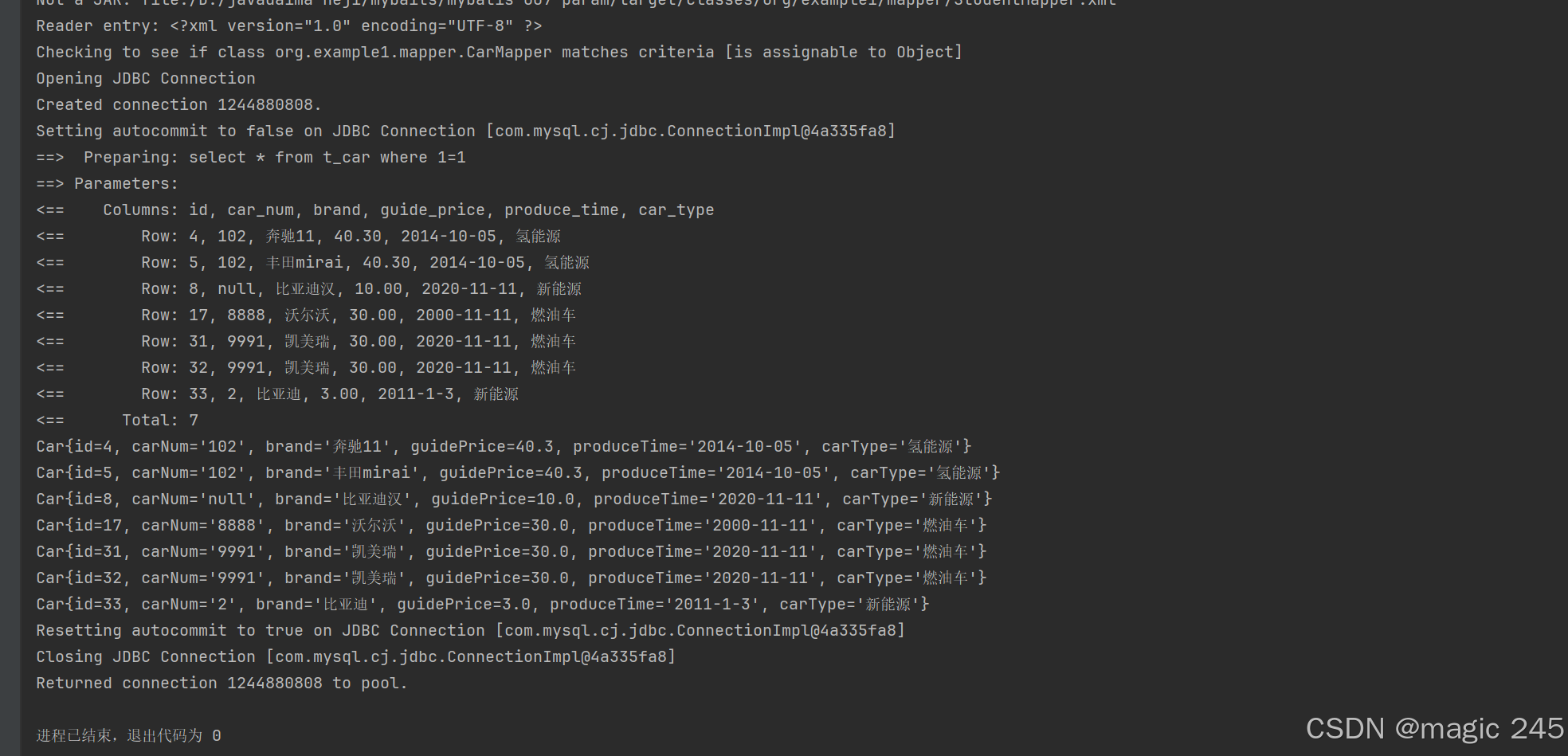
// 假设第一个条件不是空,后两个条件是空

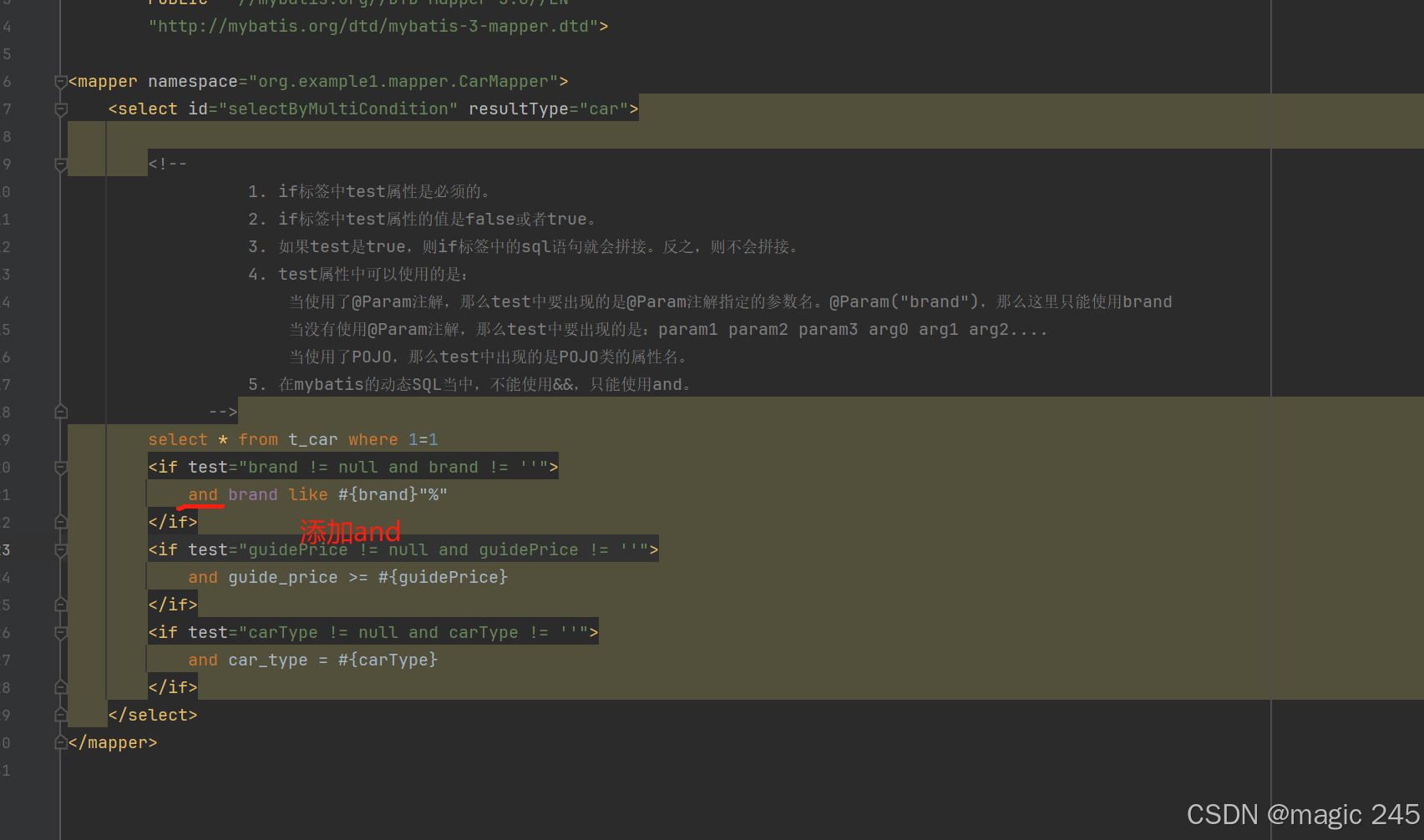
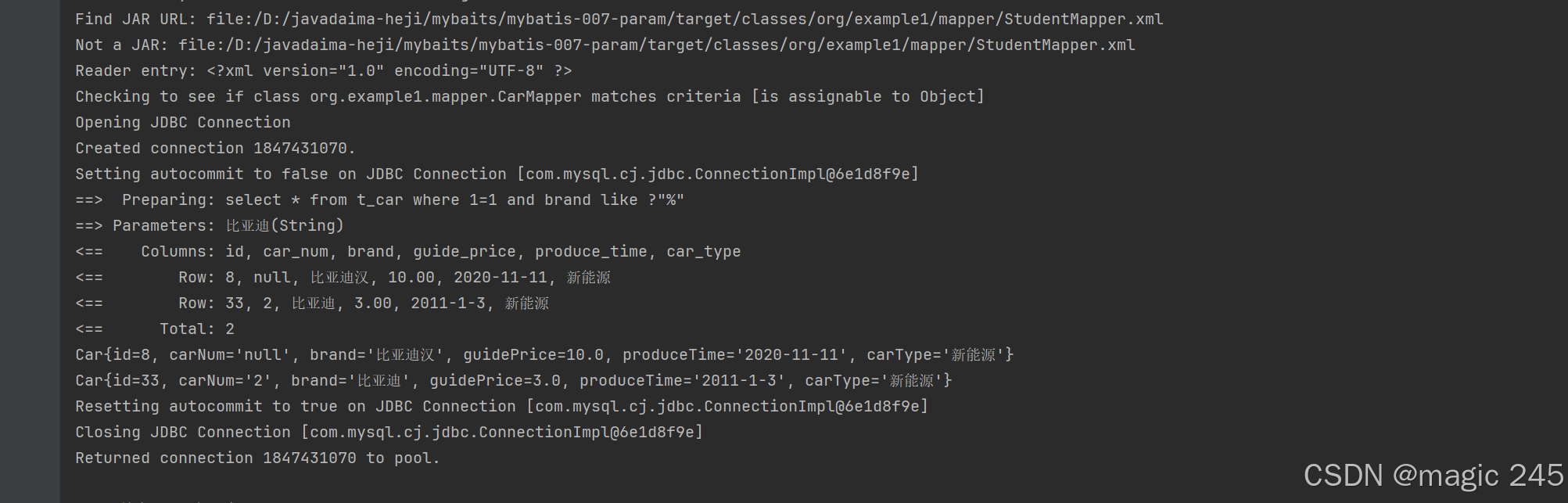
2.where标签
where标签的作用:让where子句更加动态智能。
-
所有条件都为空时,where标签保证不会生成where子句。
-
自动去除某些条件前面多余的and或or。
-
后面的and或or则无法去除
继续使用if标签中的需求。
package org.example1.mapper;
import org.apache.ibatis.annotations.Param;
import org.example1.pojo.Car;
import java.util.List;
public interface CarMapper {
/**
* 使用where标签,让where子句更加的智能。
* @param brand
* @param guidePrice
* @param carType
* @return
*/
List<Car> selectByMultiConditionWithWhere(@Param("brand") String brand, @Param("guidePrice") Double guidePrice, @Param("carType") String carType);
}
<select id="selectByMultiConditionWithWhere" resultType="Car">
select * from t_car
<!--where标签是专门负责where子句动态生成的。-->
<where>
<if test="brand != null and brand != ''">
and brand like "%"#{brand}"%"
</if>
<if test="guidePrice != null and guidePrice != ''">
and guide_price > #{guidePrice}
</if>
<if test="carType != null and carType != ''">
and car_type = #{carType}
</if>
</where>
</select> @Test
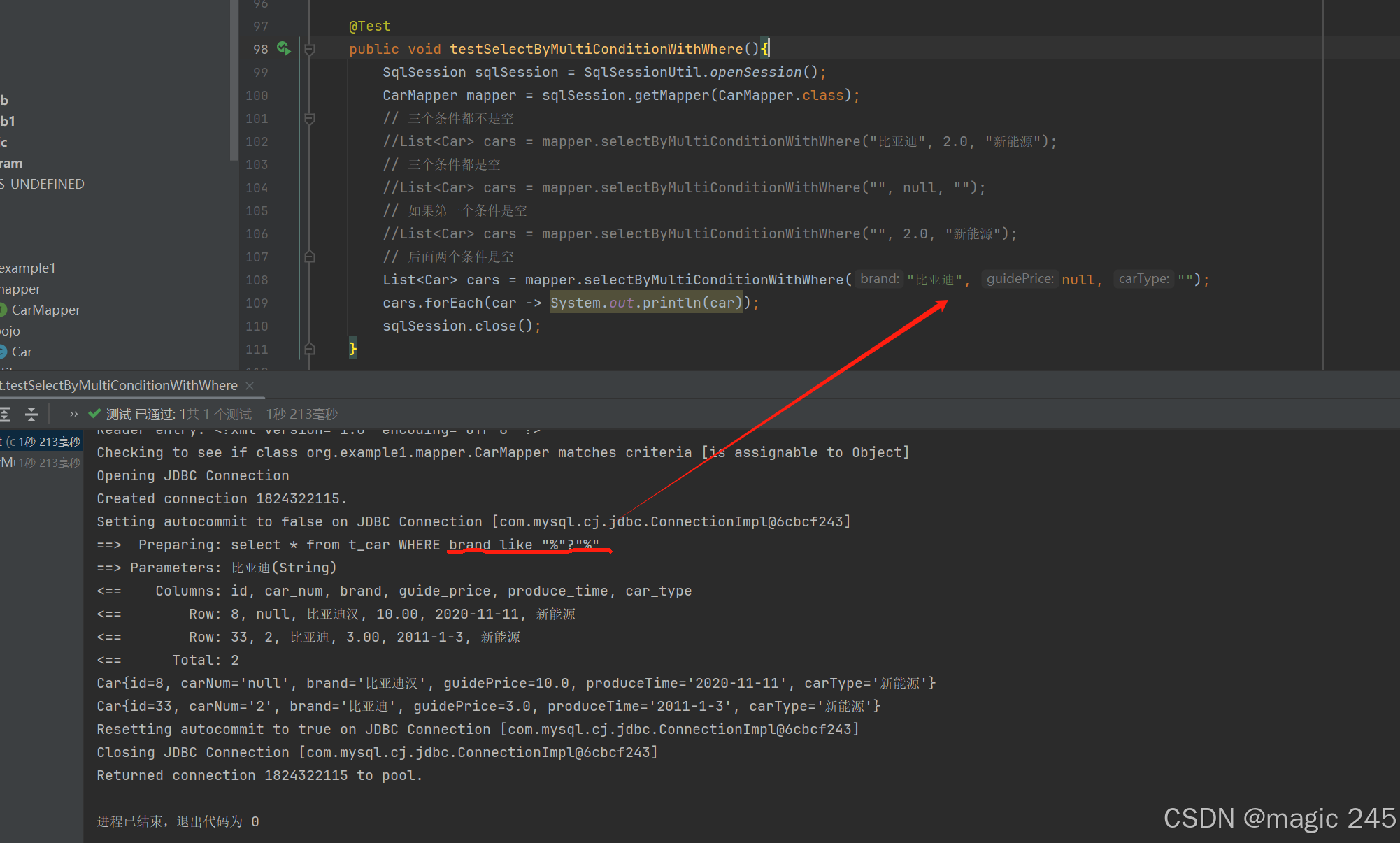
public void testSelectByMultiConditionWithWhere(){
SqlSession sqlSession = SqlSessionUtil.openSession();
CarMapper mapper = sqlSession.getMapper(CarMapper.class);
// 三个条件都不是空
//List<Car> cars = mapper.selectByMultiConditionWithWhere("比亚迪", 2.0, "新能源");
// 三个条件都是空
//List<Car> cars = mapper.selectByMultiConditionWithWhere("", null, "");
// 如果第一个条件是空
//List<Car> cars = mapper.selectByMultiConditionWithWhere("", 2.0, "新能源");
// 后面两个条件是空
List<Car> cars = mapper.selectByMultiConditionWithWhere("比亚迪", null, "");
cars.forEach(car -> System.out.println(car));
sqlSession.close();
}
它可以自动去掉前面多余的and,那可以自动去掉后面多余的and吗?
<select id="selectByMultiConditionWithWhere" resultType="car">
select * from t_car
<where>
<if test="brand != null and brand != ''">
brand like #{brand}"%" and
</if>
<if test="guidePrice != null and guidePrice != ''">
guide_price >= #{guidePrice} and
</if>
<if test="carType != null and carType != ''">
car_type = #{carType}
</if>
</where>
</select>// 让最后一个条件为空
List<Car> cars = mapper.selectByMultiConditionWithWhere("丰田", 20.0, "");运行结果:
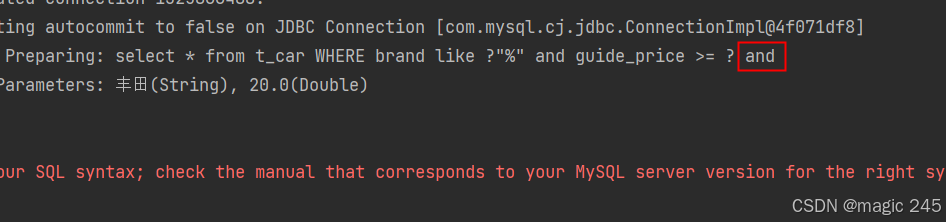
很显然,后面多余的and是不会被去除的。
3.trim标签
trim标签的属性:
-
prefix:在trim标签中的语句前添加内容
-
suffix:在trim标签中的语句后添加内容
-
prefixOverrides:前缀覆盖掉(前缀去掉)
-
suffixOverrides:后缀覆盖掉(后缀去掉)
/**
* 根据多条件查询Car,使用trim标签
* @param brand
* @param guidePrice
* @param carType
* @return
*/
List<Car> selectByMultiConditionWithTrim(@Param("brand") String brand, @Param("guidePrice") Double guidePrice, @Param("carType") String carType);<select id="selectByMultiConditionWithTrim" resultType="car">
select * from t_car
<trim prefix="where" suffixOverrides="and|or">
<if test="brand != null and brand != ''">
brand like #{brand}"%" and
</if>
<if test="guidePrice != null and guidePrice != ''">
guide_price >= #{guidePrice} and
</if>
<if test="carType != null and carType != ''">
car_type = #{carType}
</if>
</trim>
</select>@Test
public void testSelectByMultiConditionWithTrim(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
List<Car> cars = mapper.selectByMultiConditionWithTrim("丰田", 20.0, "");
System.out.println(cars);
}
如果所有条件为空,where会被加上吗?
List<Car> cars = mapper.selectByMultiConditionWithTrim("", null, "");执行结果:
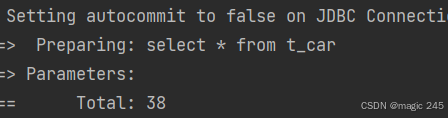
4.set标签
主要使用在update语句当中,用来生成set关键字,同时去掉最后多余的“,” 比如我们只更新提交的不为空的字段,如果提交的数据是空或者"",那么这个字段我们将不更新。
/**
* 更新信息,使用set标签
* @param car
* @return
*/
int updateWithSet(Car car);@Test
public void testUpdateWithSet(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
Car car = new Car(38L,"1001","丰田霸道2",10.0,"",null);
int count = mapper.updateWithSet(car);
System.out.println(count);
SqlSessionUtil.openSession().commit();
}执行结果:

5.choose when otherwise
这三个标签是在一起使用的:
<choose>
<when></when>
<when></when>
<when></when>
<otherwise></otherwise>
</choose>等同于:
if(){
}else if(){
}else if(){
}else if(){
}else{
}只有一个分支会被选择!!!!
需求:先根据品牌查询,如果没有提供品牌,再根据指导价格查询,如果没有提供指导价格,就根据生产日期查询。
/**
* 使用choose when otherwise标签查询
* @param brand
* @param guidePrice
* @param produceTime
* @return
*/
List<Car> selectWithChoose(@Param("brand") String brand, @Param("guidePrice") Double guidePrice, @Param("produceTime") String produceTime);<select id="selectWithChoose" resultType="car">
select * from t_car
<where>
<choose>
<when test="brand != null and brand != ''">
brand like #{brand}"%"
</when>
<when test="guidePrice != null and guidePrice != ''">
guide_price >= #{guidePrice}
</when>
<otherwise>
produce_time >= #{produceTime}
</otherwise>
</choose>
</where>
</select>@Test
public void testSelectWithChoose(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
//List<Car> cars = mapper.selectWithChoose("丰田霸道", 20.0, "2000-10-10");
//List<Car> cars = mapper.selectWithChoose("", 20.0, "2000-10-10");
//List<Car> cars = mapper.selectWithChoose("", null, "2000-10-10");
List<Car> cars = mapper.selectWithChoose("", null, "");
System.out.println(cars);
}
6.foreach标签
循环数组或集合,动态生成sql,比如这样的SQL:
delete from t_car where id in(1,2,3);
delete from t_car where id = 1 or id = 2 or id = 3;insert into t_car values
(null,'1001','凯美瑞',35.0,'2010-10-11','燃油车'),
(null,'1002','比亚迪唐',31.0,'2020-11-11','新能源'),
(null,'1003','比亚迪宋',32.0,'2020-10-11','新能源')⑴.批量删除
-
用in来删除
/**
* 通过foreach完成批量删除
* @param ids
* @return
*/
int deleteBatchByForeach(@Param("ids") Long[] ids);<!--
collection:集合或数组
item:集合或数组中的元素(名字随便取)
separator:分隔符
open:foreach标签中所有内容的开始
close:foreach标签中所有内容的结束
-->
<delete id="deleteBatchByForeach">
delete from t_car where id in
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>@Test
public void testDeleteBatchByForeach(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
int count = mapper.deleteBatchByForeach(new Long[]{40L, 41L, 42L});
System.out.println("删除了几条记录:" + count);
SqlSessionUtil.openSession().commit();
}执行结果:

-
用or来删除
/**
* 通过foreach完成批量删除
* @param ids
* @return
*/
int deleteBatchByForeach2(@Param("ids") Long[] ids);<delete id="deleteBatchByForeach2">
delete from t_car where
<foreach collection="ids" item="id" separator="or">
id = #{id}
</foreach>
</delete>@Test
public void testDeleteBatchByForeach2(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
int count = mapper.deleteBatchByForeach2(new Long[]{40L, 41L, 42L});
System.out.println("删除了几条记录:" + count);
SqlSessionUtil.openSession().commit();
}执行结果:

⑵.批量添加
/**
* 批量添加,使用foreach标签
* @param cars
* @return
*/
int insertBatchByForeach(@Param("cars") List<Car> cars);<insert id="insertBatchByForeach">
insert into t_car values
<foreach collection="cars" item="car" separator=",">
(null,#{car.carNum},#{car.brand},#{car.guidePrice},#{car.produceTime},#{car.carType})
</foreach>
</insert>@Test
public void testInsertBatchByForeach(){
CarMapper mapper = SqlSessionUtil.openSession().getMapper(CarMapper.class);
Car car1 = new Car(null, "2001", "兰博基尼", 100.0, "1998-10-11", "燃油车");
Car car2 = new Car(null, "2001", "兰博基尼", 100.0, "1998-10-11", "燃油车");
Car car3 = new Car(null, "2001", "兰博基尼", 100.0, "1998-10-11", "燃油车");
List<Car> cars = Arrays.asList(car1, car2, car3);
int count = mapper.insertBatchByForeach(cars);
System.out.println("插入了几条记录" + count);
SqlSessionUtil.openSession().commit();
}执行结果:

7.sql标签与include标签
sql标签用来声明sql片段
include标签用来将声明的sql片段包含到某个sql语句当中
作用:代码复用。易维护。
<sql id="carCols">id,car_num carNum,brand,guide_price guidePrice,produce_time produceTime,car_type carType</sql>
<select id="selectAllRetMap" resultType="map">
select <include refid="carCols"/> from t_car
</select>
<select id="selectAllRetListMap" resultType="map">
select <include refid="carCols"/> carType from t_car
</select>
<select id="selectByIdRetMap" resultType="map">
select <include refid="carCols"/> from t_car where id = #{id}
</select>三、MyBatis的高级映射及延迟加载
模块名:mybatis-0010-advanced-mapping
打包方式:jar
依赖:mybatis依赖、mysql驱动依赖、junit依赖、logback依赖
配置文件:mybatis-config.xml、logback.xml、jdbc.properties
拷贝工具类:SqlSessionUtil
准备数据库表:一个班级对应多个学生。班级表:t_clazz。学生表:t_student
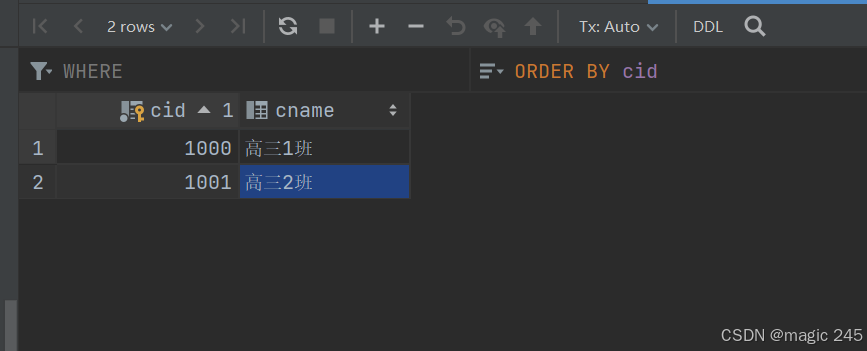
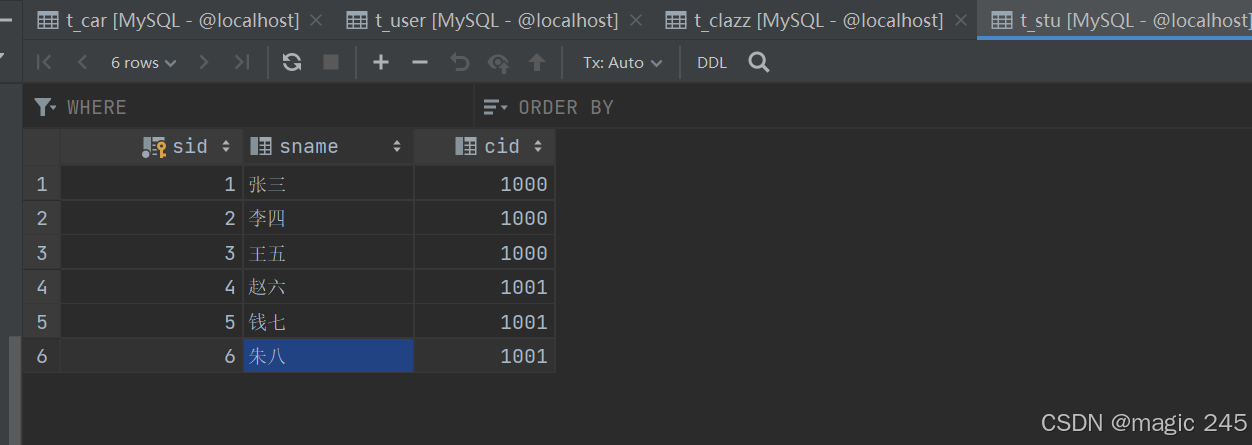
创建pojo:Student、Clazz
/**
* 学生类
*/
public class Student {
private Integer sid;
private String sname;
//......
}
/**
* 班级类
*/
public class Clazz {
private Integer cid;
private String cname;
//......
}1.多对一

多种方式,常见的包括三种:
-
第一种方式:一条SQL语句,级联属性映射。
-
第二种方式:一条SQL语句,association。
-
第三种方式:两条SQL语句,分步查询。(这种方式常用:优点一是可复用。优点二是支持懒加载。)
⑴.第一种方式:级联属性映射
pojo类Student中添加一个属性:Clazz clazz; 表示学生关联的班级对象。
package org.example1.pojo;
/**
* 学生信息
*/
public class Student { // Student是多的一方
private Integer sid;
private String sname;
private Clazz clazz; // Clazz是一的一方。
@Override
public String toString() {
return "Student{" +
"sid=" + sid +
", sname='" + sname + '\'' +
", clazz=" + clazz +
'}';
}
public Clazz getClazz() {
return clazz;
}
public void setClazz(Clazz clazz) {
this.clazz = clazz;
}
public Integer getSid() {
return sid;
}
public void setSid(Integer sid) {
this.sid = sid;
}
public String getSname() {
return sname;
}
public void setSname(String sname) {
this.sname = sname;
}
public Student(Integer sid, String sname) {
this.sid = sid;
this.sname = sname;
}
public Student() {
}
}
<!--多对一映射的第一种方式:一条SQL语句,级联属性映射。-->
<resultMap id="studentResultMap" type="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname"/>
<result property="clazz.cid" column="cid"/>
<result property="clazz.cname" column="cname"/>
</resultMap>
<select id="selectById" resultMap="studentResultMap">
select
s.sid,s.sname,c.cid,c.cname
from
t_stu s left join t_clazz c on s.cid = c.cid
where
s.sid = #{sid}
</select>StudentMapper接口
package org.example1.mapper;
import org.example1.pojo.Student;
import java.util.List;
public interface StudentMapper {
/**
* 根据id获取学生信息。同时获取学生关联的班级信息。
* @param id 学生的id
* @return 学生对象,但是学生对象当中含有班级对象。
*/
Student selectById(Integer id);
}test
@Test
public void testSelectById(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
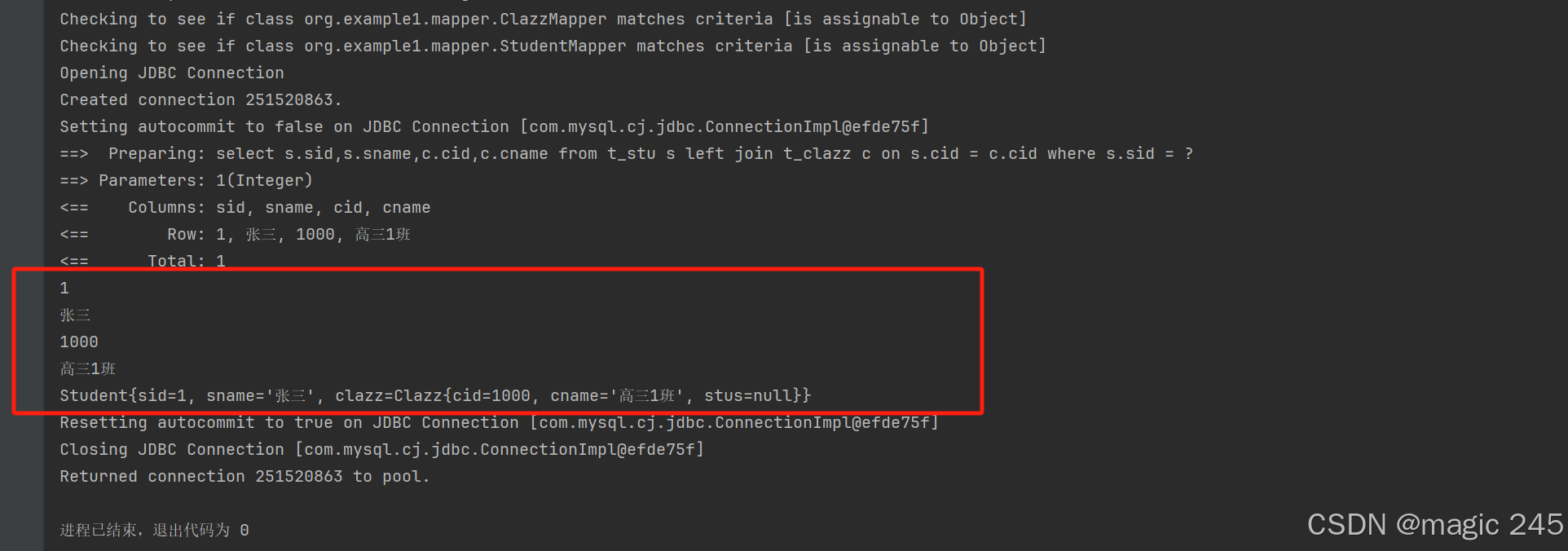
Student student = mapper.selectById(1);
System.out.println(student.getSid());
System.out.println(student.getSname());
System.out.println(student.getClazz().getCid());
System.out.println(student.getClazz().getCname());
System.out.println(student);
sqlSession.close();
}运行结果:
⑵.第二种方式:association
其他位置都不需要修改,只需要修改resultMap中的配置:association即可。
StudentMapper接口
package org.example1.mapper;
import org.example1.pojo.Student;
import java.util.List;
public interface StudentMapper {
/**
* 一条SQL语句,association
* @param id
* @return
*/
Student selectByIdAssociation(Integer id);
}association翻译为:关联。 学生对象关联一个班级对象。
<!--
association:翻译为关联。一个Student对象关联一个Clazz对象
property:提供要映射的POJO类的属性名。
javaType:用来指定要映射的java类型。
-->
<association property="clazz" javaType="Clazz">
<id property="cid" column="cid"/>
<result property="cname" column="cname"/>
</association>
</resultMap>
<select id="selectByIdAssociation" resultMap="studentResultMapAssociation">
select
s.sid,s.sname,c.cid,c.cname
from
t_stu s left join t_clazz c on s.cid = c.cid
where
s.sid = #{sid}
</select>Test
@Test
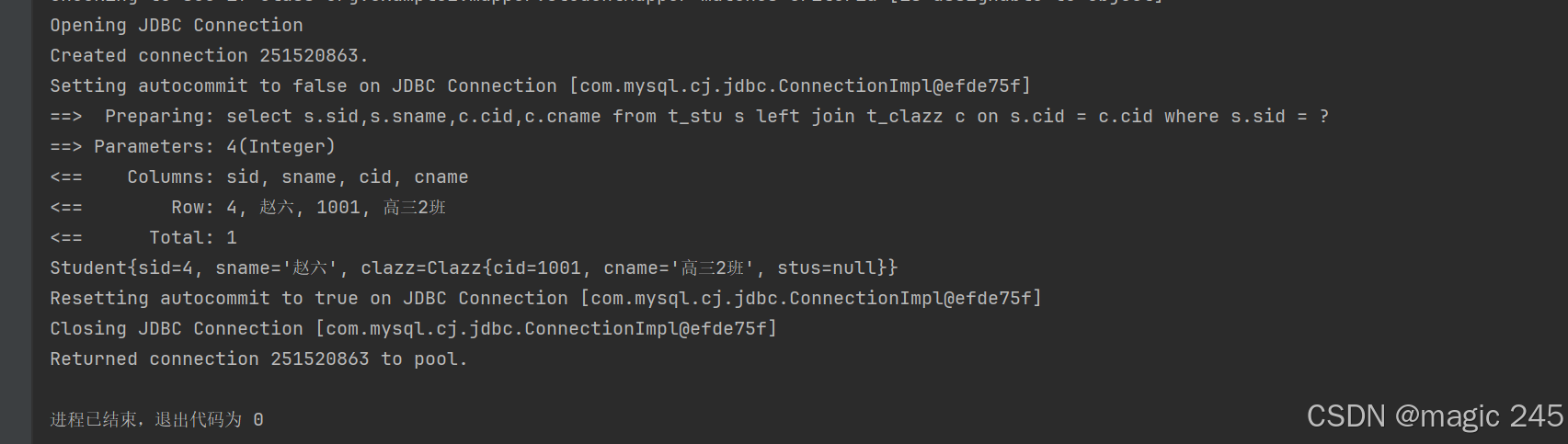
public void testSelectByIdAssociation(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student student = mapper.selectByIdAssociation(4);
System.out.println(student);
sqlSession.close();
}
⑶.第三种方式:分步查询
其他位置不需要修改,只需要修改以及添加以下三处:
第一处:association中select位置填写sqlId。sqlId=namespace+id。其中column属性作为这条子sql语句的条件。
第一步:现在Student根据Id查询学生信息
StudentMapper接口
package org.example1.mapper;
import org.example1.pojo.Student;
import java.util.List;
public interface StudentMapper {
/**
* 分部查询第一步:先根据学生的sid查询学生的信息。
* @param sid
* @return
*/
Student selectByIdStep1(Integer sid);
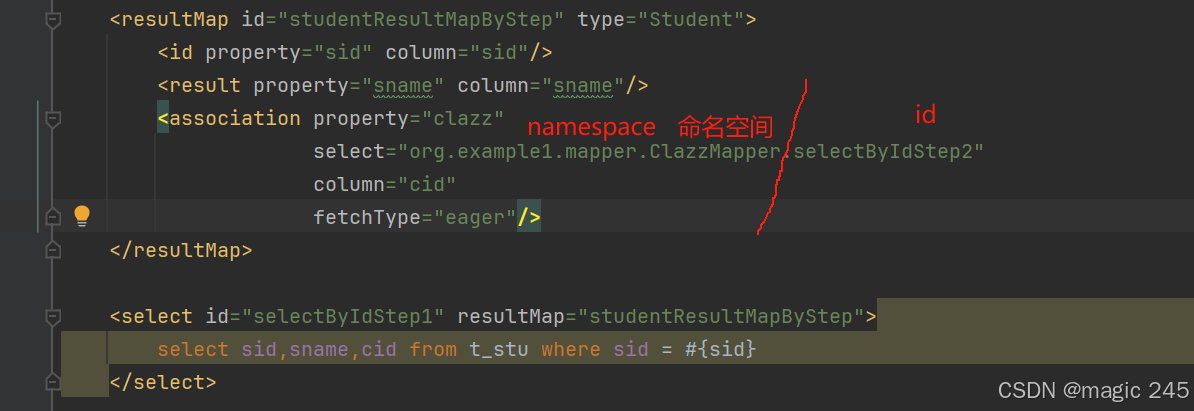
} <!--两条SQL语句,完成多对一的分步查询。-->
<!--这里是第一步:根据学生的id查询学生的所有信息。这些信息当中含有班级id(cid)-->
<resultMap id="studentResultMapByStep" type="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname"/>
<association property="clazz"
select=""
column="cid"
/>
</resultMap>
<select id="selectByIdStep1" resultMap="studentResultMapByStep">
select sid,sname,cid from t_stu where sid = #{sid}
</select>分步查询第二步:根据cid获取班级信息。
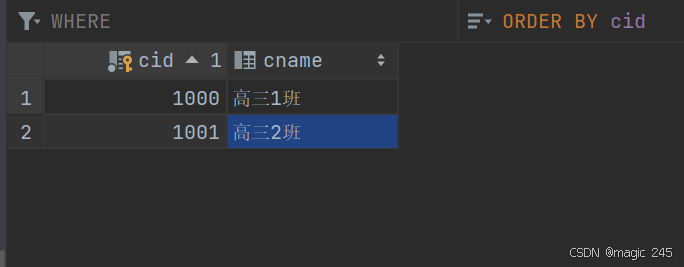
ClazzMapper接口
package org.example1.mapper;
import org.example1.pojo.Clazz;
public interface ClazzMapper {
/**
* 分步查询第二步:根据cid获取班级信息。
* @param cid
* @return
*/
Clazz selectByIdStep2(Integer cid);
} <!--分步查询第二步:根据cid获取班级信息。-->
<select id="selectByIdStep2" resultType="Clazz">
select cid,cname from t_clazz where cid = #{cid}
</select>把第一查出来的cid传给第二步(根据cid获取班级信息)的写法
test
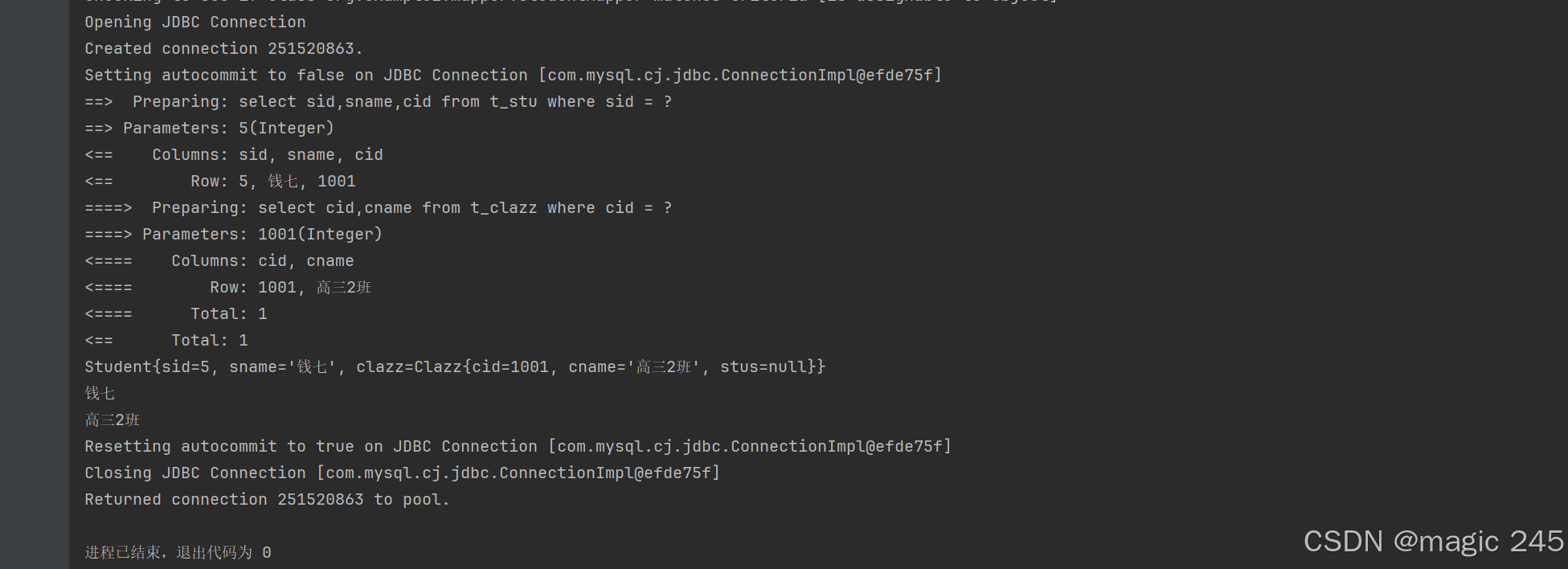
@Test
public void testSelectByIdStep1(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student student = mapper.selectByIdStep1(5);
System.out.println(student);
// 只需要看学生的名字
System.out.println(student.getSname());
// 程序执行到这里了,我想看看班级的名字
System.out.println(student.getClazz().getCname());
sqlSession.close();
}
分步优点:
-
第一个优点:代码复用性增强。
-
第二个优点:支持延迟加载。【暂时访问不到的数据可以先不查询。提高程序的执行效率。】
2.多对一延迟加载
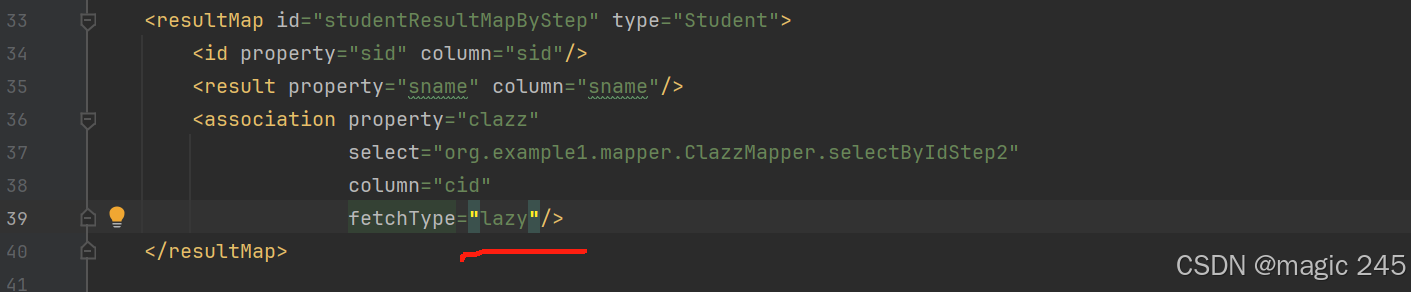
要想支持延迟加载,非常简单,只需要在association标签中添加fetchType="lazy"即可。 修改StudentMapper.xml文件:
@Test
public void testSelectByIdStep1(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
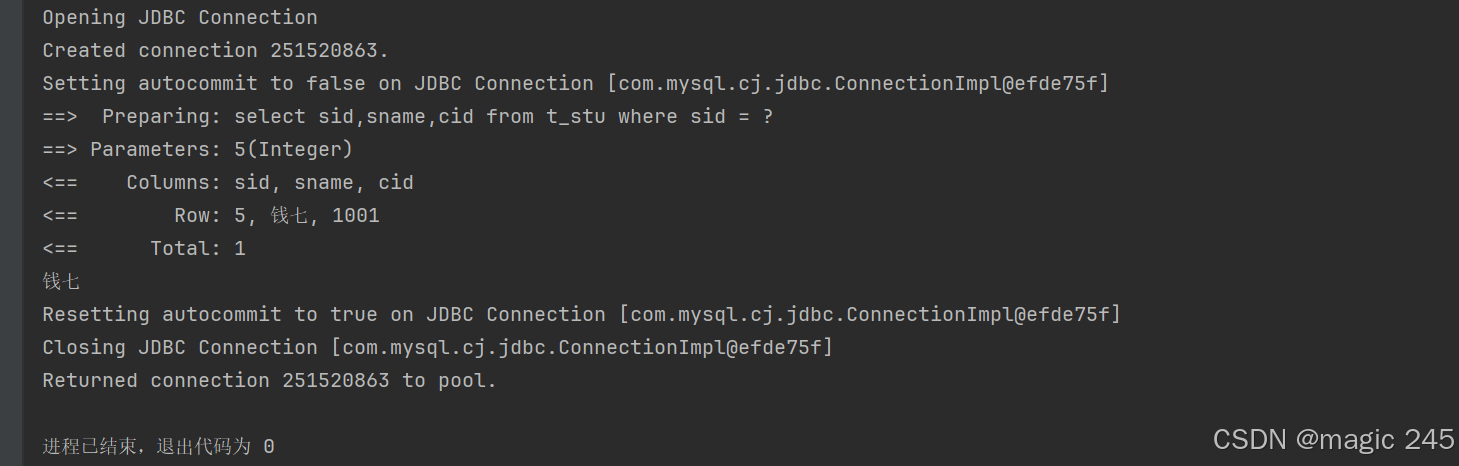
Student student = mapper.selectByIdStep1(5);
// 只需要看学生的名字
System.out.println(student.getSname());
// 程序执行到这里了,我想看看班级的名字
//System.out.println(student.getClazz().getCname());
sqlSession.close();
}只需要看学生的名字
看班级的名字

<!--
分步查询的优点:
第一:复用性增强。可以重复利用。(大步拆成N多个小碎步。每一个小碎步更加可以重复利用。)
第二:采用这种分步查询,可以充分利用他们的延迟加载/懒加载机制。
什么是延迟加载(懒加载),有什么用?
延迟加载的核心原理是:用的时候再执行查询语句。不用的时候不查询。
作用:提高性能。尽可能的不查,或者说尽可能的少查。来提高效率。
在mybatis当中怎么开启延迟加载呢?
association标签中添加fetchType="lazy"
注意:默认情况下是没有开启延迟加载的。需要设置:fetchType="lazy"
这种在association标签中配置fetchType="lazy",是局部的设置,只对当前的association关联的sql语句起作用。
在实际的开发中,大部分都是需要使用延迟加载的,所以建议开启全部的延迟加载机制:
在mybatis核心配置文件中添加全局配置:lazyLoadingEnabled=true
实际开发中的模式:
把全局的延迟加载打开。
如果某一步不需要使用延迟加载,请设置:fetchType="eager"
-->

开启全局延迟加载之后,所有的sql都会支持延迟加载,如果某个sql你不希望它支持延迟加载怎么办呢?将fetchType设置为eager:
<resultMap id="studentResultMap" type="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname"/>
<association property="clazz"
select="org.example1.mapper.ClazzMapper.selectByCid"
column="cid"
fetchType="eager"/>
</resultMap>3.一对多
一对多的实现,通常是在一的一方中有List集合属性。 在Clazz类中添加List<Student> stus; 属性。
package org.example1.pojo;
import java.util.List;
/**
* 班级信息
*/
public class Clazz {
private Integer cid;
private String cname;
private List<Student> stus;
@Override
public String toString() {
return "Clazz{" +
"cid=" + cid +
", cname='" + cname + '\'' +
", stus=" + stus +
'}';
}
public List<Student> getStus() {
return stus;
}
public void setStus(List<Student> stus) {
this.stus = stus;
}
public Integer getCid() {
return cid;
}
public void setCid(Integer cid) {
this.cid = cid;
}
public String getCname() {
return cname;
}
public void setCname(String cname) {
this.cname = cname;
}
public Clazz() {
}
public Clazz(Integer cid, String cname) {
this.cid = cid;
this.cname = cname;
}
}
一对多的实现通常包括两种实现方式:
-
第一种方式:collection
-
第二种方式:分步查询
⑴.第一种方式:collection
package org.example1.mapper;
import org.example1.pojo.Clazz;
public interface ClazzMapper {
/**
* 根据班级编号查询班级信息。
* @param cid
* @return
*/
Clazz selectByCollection(Integer cid);
} <resultMap id="clazzResultMap" type="Clazz">
<id property="cid" column="cid"/>
<result property="cname" column="cname"/>
<!--一对多,这里是collection。collection是集合的意思。-->
<!--ofType 属性用来指定集合当中的元素类型。-->
<collection property="stus" ofType="Student">
<id property="sid" column="sid"/>
<result property="sname" column="sname"/>
</collection>
</resultMap>
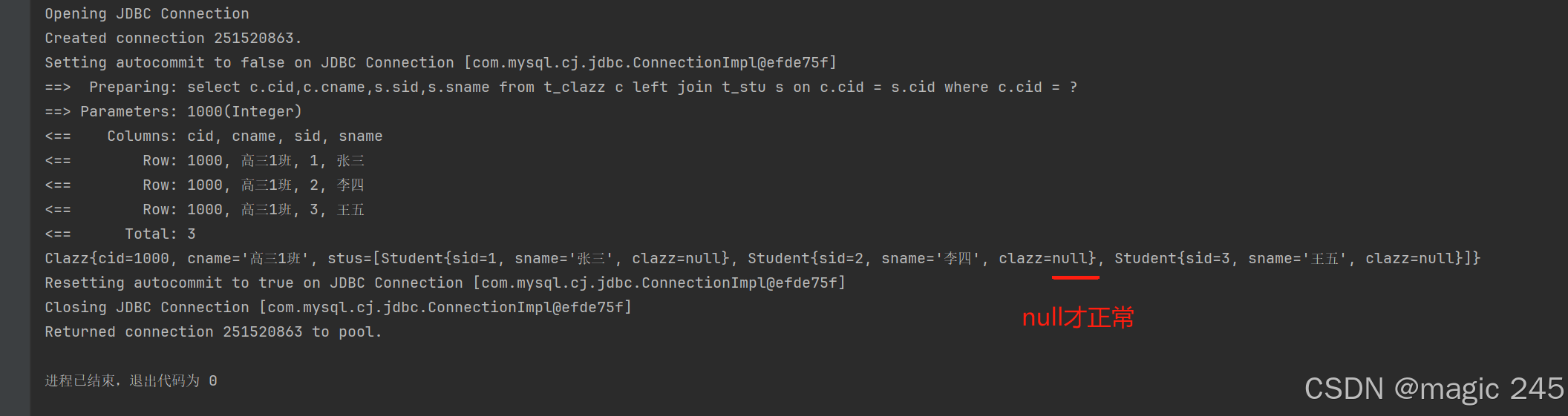
<select id="selectByCollection" resultMap="clazzResultMap">
select c.cid,c.cname,s.sid,s.sname from t_clazz c left join t_stu s on c.cid = s.cid where c.cid = #{cid}
</select>注意是ofType,表示“集合中的类型”。
Test
@Test
public void testSelectByCollection(){
SqlSession sqlSession = SqlSessionUtil.openSession();
ClazzMapper mapper = sqlSession.getMapper(ClazzMapper.class);
Clazz clazz = mapper.selectByCollection(1000);
System.out.println(clazz);
sqlSession.close();
}
⑵.第二种方式:分步查询
分步查询。第一步:根据班级编号获取班级信息。
ClazzMapper接口
package org.example1.mapper;
import org.example1.pojo.Clazz;
public interface ClazzMapper {
/**
* 分步查询。第一步:根据班级编号获取班级信息。
* @param cid 班级编号
* @return
*/
Clazz selectByStep1(Integer cid);
}
<!--分步查询第一步:根据班级的cid获取班级信息。-->
<resultMap id="clazzResultMapStep" type="Clazz">
<id property="cid" column="cid"/>
<result property="cname" column="cname"/>
<collection property="stus"
select="org.example1.mapper.StudentMapper.selectByCidStep2"
column="cid" fetchType="eager" />
</resultMap>
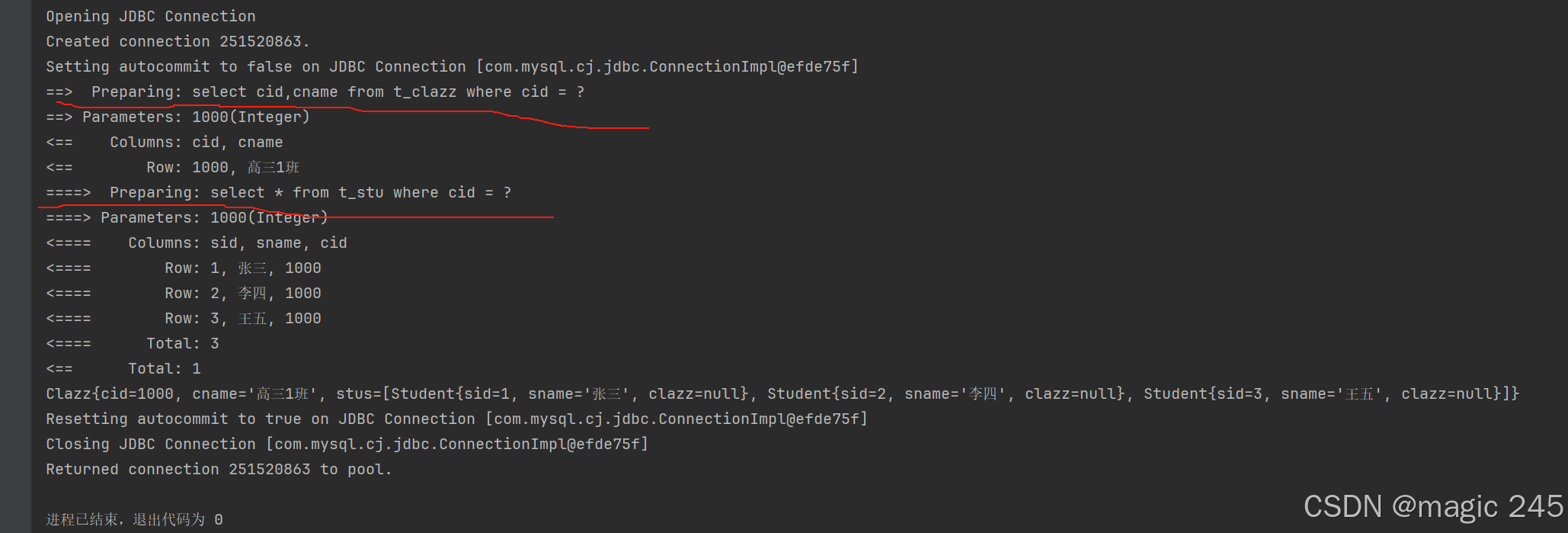
<select id="selectByStep1" resultMap="clazzResultMapStep">
select cid,cname from t_clazz where cid = #{cid}
</select>第二步:根据班级编号查询学生信息。
package org.example1.mapper;
import org.example1.pojo.Student;
import java.util.List;
public interface StudentMapper {
/**
* 根据班级编号查询学生信息。
* @param cid
* @return
*/
List<Student> selectByCidStep2(Integer cid);
}
<select id="selectByCidStep2" resultType="Student">
select * from t_stu where cid = #{cid}
</select>Test
@Test
public void testSelectByStep1(){
SqlSession sqlSession = SqlSessionUtil.openSession();
ClazzMapper mapper = sqlSession.getMapper(ClazzMapper.class);
Clazz clazz = mapper.selectByStep1(1000);
System.out.println(clazz);
sqlSession.close();
}
4.一对多延迟加载
一对多延迟加载机制和多对一是一样的。同样是通过两种方式:
-
第一种:fetchType="lazy"
-
第二种:修改全局的配置setting,lazyLoadingEnabled=true,如果开启全局延迟加载,想让某个sql不使用延迟加载:fetchType="eager"


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









