







Prometheus基本了解
-
介绍
- Prometheus 是一个开源的系统监控和报警系统,现在已经加入到 CNCF 基金会,成为继 k8s 之后第二个在 CNCF 托管的项目,在 kubernetes 容器管理系统中,通常会搭配 prometheus 进行监控,同时也支持多种 exporter 采集数据,还支持 pushgateway 进行数据上报,Prometheus 性能足够支撑上万台规模的集群。
-
特点
1.多维度数据模型
- 每一个时间序列数据都由 metric 度量指标名称和它的标签 labels 键值对集合唯一确定:2.灵活的查询语言(PromQL)
-
通过基于 HTTP 的 pull 方式采集时序数据;
-
有多种可视化图像界面,如 Grafana 等。
-
做高可用,可以对数据做异地备份,联邦集群,部署多套 prometheus,pushgateway 上报数据
-
-
样本
-
单个时间序列中的一个数据点,在prometheus数据模型的基本单位
-
指标名称,http请求数量
-
时间戳和值
-
标签,对样本的描述或者分组
-
-
组件
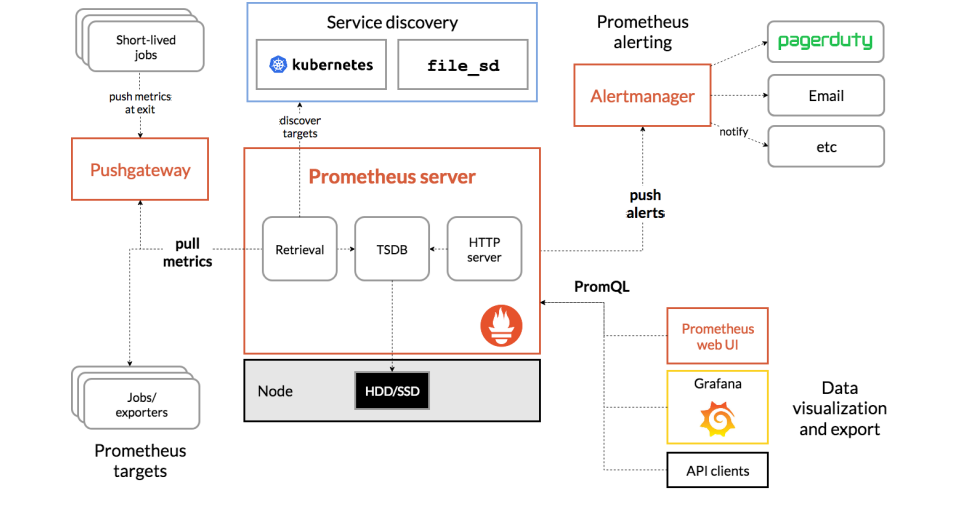
-
组件的功能:
-
Retrieval是负责定时去暴露的目标页面上去抓取采样指标数据。
-
Storage 是负责将采样数据写入指定的时序数据库存储
-
PromQL 是Prometheus提供的查询语言模块。可以和一些webui比如grfana集成。
-
Jobs / Exporters:Prometheus 可以从 Jobs 或 Exporters 中拉取监控数据。Exporter 以 Web API 的形式对外暴露数据采集接口。
-
Prometheus Server:Prometheus 还可以从其他的 Prometheus Server 中拉取数据。
-
Pushgateway:对于一些以临时性 Job 运行的组件,Prometheus 可能还没有来得及从中 pull 监控数据的情况下,这些 Job 已经结束了,Job 运行时可以在运行时将监控数据推送到 Pushgateway 中,Prometheus 从 Pushgateway 中拉取数据,防止监控数据丢失。
-
Service discovery:是指 Prometheus 可以动态的发现一些服务,拉取数据进行监控,如从DNS,Kubernetes,Consul 中发现, file_sd 是静态配置的文件。
-
AlertManager:是一个独立于 Prometheus 的外部组件,用于监控系统的告警,通过配置文件可以配置一些告警规则,Prometheus 会把告警推送到 AlertManager。
-
-
组件工作流程
-
Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
-
Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
-
Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
-
在图形界面中,可视化采集数据。
-
-
Prometheus server
-
通过http请求定期从目标(应用,服务,exporters)拉取指标数据,Retrieval组件在活跃的主机上抓取监控数据
-
通过服务发现或者直接进行拉取监控的数据
-
拉取的数据可以是静态的或者是动态的
-
将拉取的数据进行存储
-
-
Exporters(数据采集器)
-
Exporters是应用程序或者服务的代理,负责从不同来源收集指标,并将其暴露为http接口
-
收集到系统指标在http端点上以Prometheus格式公开
-
Retrieval定期从这些http端点拉取数据,形成了数据序列
-
所有向Prometheus server提供监控数据的程序都可以被称为exporter
-
-
ALettmanager
-
从Prometheus server端接收到了alerts后,会进行去重,分组,并路由到相应的接收方,发出报警
-
常见的接收方式为微信,电子邮件等
-
-
Grafana
-
监控仪表盘,可视化监控数据
-
pushgateway
-
各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据
-
-
Prometheus web ui
-
交互式查询
-
提供webui 查看实时数据
-
用图形化界面方便快速的查询
-
-
服务发现
-
prometheus支持多种服务发现机制,k8s的api,consul,ec2等,自动识别新加入的服务或者实例
-
在微服务架构中,不需要手动更新监控配置,prometheus会自动更新调整
-
-
流程
-
Prometheus server 可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态 job 或者服务发现的方式被 prometheus server 采集到,这种方式默认的 pull方式拉取指标;也可通过 pushgateway 把采集的数据上报到 prometheus server中;还可通过一些组件自带的 exporter 采集相应组件的数据;
-
Prometheus server 把采集到的监控指标数据保存到本地磁盘或者数据库;
-
Prometheus 采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager
-
Alertmanager 通过配置报警接收方,发送报警到邮件,微信或者钉钉等
-
Prometheus 自带的 web ui 界面提供 PromQL 查询语言,可查询监控数据
2、部署模式
-
基本高可用模式
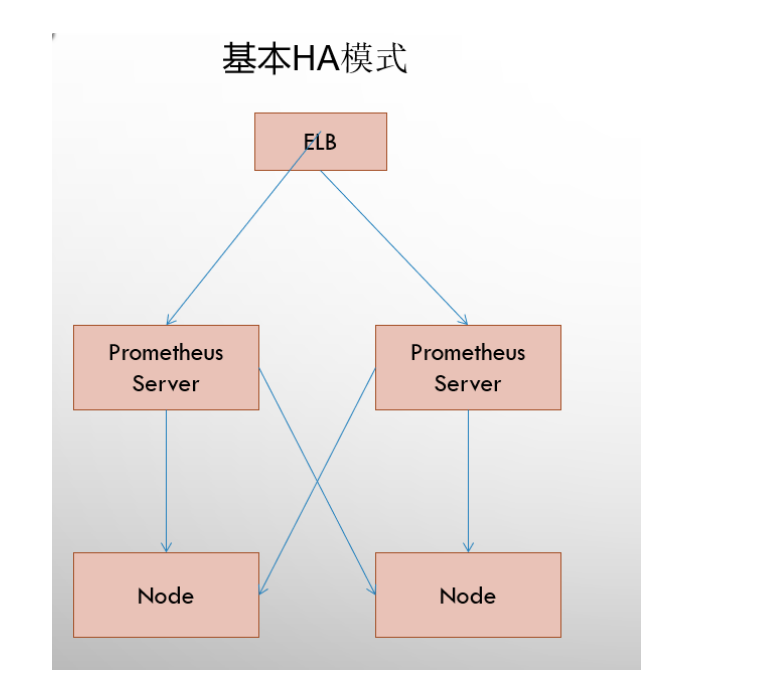
-
基本高可用+远程存储
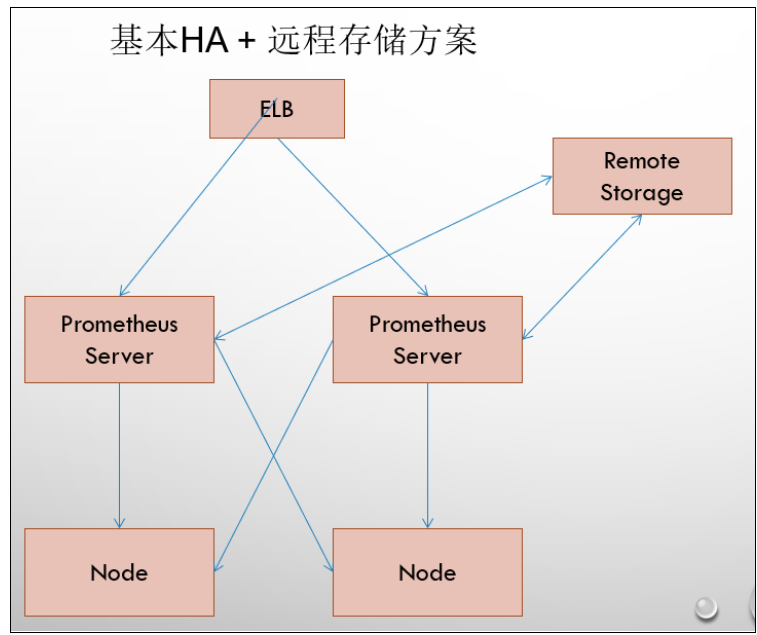
-
基本ha+远程存储+联邦集群方案
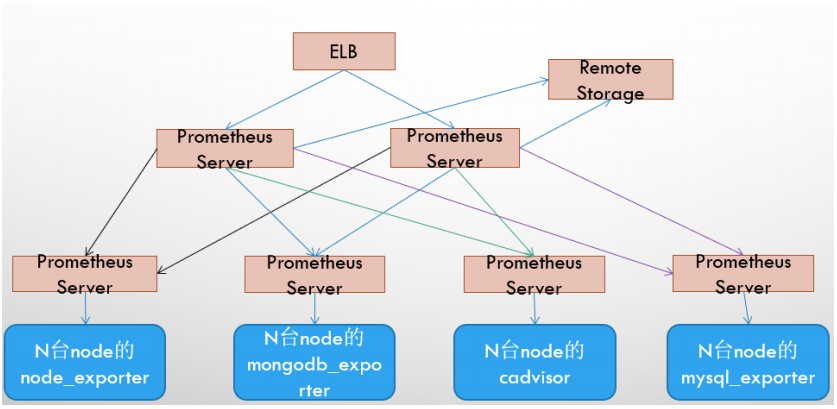
1、四种数据类型
1、count计数器类型
-
用于累计值,记录请求次数,任务完成数,错误发生错误数
-
一直增加,不会减少
-
重启进程后,会被重置
2、Gauge 测量器类型
-
可增加可减小
-
温度变化,或者内存变化
-
重启进城后,会被重置
3、histogram(重要)
-
一个区间
-
是一个树状图
-
提供三个
-
basename_bucket{le=“上边界”} 这个值小于等于上边界的所有采样点数量
-
basename_sun 对每个采样点值累计和
-
basename_count 对每个采样点累计和
-
如果定义了histogram的话,会自动的生成这三个指标
-
4、summary
-
表示一段时间内的数据采样的结果,不是通过区间来进行计算的
-
也有三个作用
-
对每个采样点进行计算,形成分位图,跟正态分布一样
-
统计所有值的总和
-
统计观察到的事件数量
-
2、安装
1、安装node–exporter
-
采集机器(物理机,虚拟机,云主机等)监控指标数据,指标包括cpu,内存,磁盘,网络,文件数据等
-
负责数据指标采集的,可以向prometheus提供监控数据的程序都可以被称为exporter
# 上传镜像
node-exporter.tar.gz
# 配置文件,ds控制器,每一个节点上面有pod
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor-sa
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
# pod里面的容器会直接使用宿主机的网络,直接与宿主机进行进程间的通信,看到宿主机里面的所有的进程,hostnetwork会直接将我们宿主机的9100端口映射出来,不需要svc创建宿主机上面就会有这个端口,直接访问即可
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true # 开启特权模式
args:
- --path.procfs # 配置挂载宿主机的路径
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc # 将这些目录挂载到容器中,这样很多节点的数据都是通过这些文件来获取的系统信息
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
[root@master ~]# kubectl get pod -n monitor-sa
NAME READY STATUS RESTARTS AGE
node-exporter-6ncqv 1/1 Running 0 13m
node-exporter-ggp8m 1/1 Running 0 13m
[root@master ~]# kubectl get ds -n monitor-sa
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
node-exporter 2 2 2 2 2 <none> 13m
# 就能访问到master节点,采集到数据了
[root@master ~]# curl 10.104.43.174:9100/metrics
2、prometheus server安装和配置
-
创建sa账号,因为这些都是封装在pod里面的,所以的话,要获取系统中的信息的话,需要授权才行,k8s的apiserver,scheduler这些组件的信息
-
可以查询这些监控的数据
1、创建sa账号和对sa进行rbac授权
# 创建一个sa和secret
[root@master prometheus]# cat sa-se.yaml
apiVersion: v1
kind: Secret
metadata:
name: monitor-secret
namespace: monitor-sa
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: monitor
namespace: monitor-sa
secrets:
- name: monitor-secret
# 对sa进行授权,绑定集群角色为cluster-admin,集群绑定,sa这个账户,对于k8s中的所有名称空间下面都有最大的权限
[root@master prometheus]# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
2、创建prometheus数据存储目录
-
prometheus需要存储这些监控的数据
-
pod调度在node1上面执行,因此创建一个目录用来存储监控数据
-
这个目录挂载到prometheus里面
[root@node1 ~]# mkdir /data
[root@node1 ~]# chmod 777 /data/
3、创建一个configmap存储卷
-
用来存放prometheus配置信息
-
获取的信息, 通过服务发现等
[root@master prometheus]# cat prometheus-cfg.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
kubectl apply -f prometheus-cfg.yaml
[root@master prometheus]# kubectl get cm -n monitor-sa
NAME DATA AGE
kube-root-ca.crt 1 55m
prometheus-config 1 38s
4、通过deployment安装prometheus
[root@master prometheus]# cat prometheus-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
#matchExpressions:
#- {key: app, operator: In, values: [prometheus]}
#- {key: component, operator: In, values: [server]}
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: node1
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
imagePullPolicy: IfNotPresent
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention=720h
- --web.enable-lifecycle # 热加载
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/prometheus.yml # configmap配置文件已经编写好了,直接进行configmap挂载了
name: prometheus-config
subPath: prometheus.yml
- mountPath: /prometheus/
name: prometheus-storage-volume
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
items:
- key: prometheus.yml
path: prometheus.yml
mode: 0644
- name: prometheus-storage-volume
hostPath:
path: /data
type: Directory
[root@master prometheus]# kubectl get deployments.apps -n monitor-sa
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus-server 1/1 1 1 51s
[root@master prometheus]# kubectl get pod -n monitor-sa
NAME READY STATUS RESTARTS AGE
node-exporter-6ncqv 1/1 Running 0 60m
node-exporter-ggp8m 1/1 Running 0 60m
prometheus-server-746949b4b9-mg7pf 1/1 Running 0 55s
5、为deployment创建一个svc
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor-sa
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
protocol: TCP
selector:
app: prometheus
component: server
[root@master prometheus]# kubectl apply -f prometheus-svc.yaml
service/prometheus created
[root@master prometheus]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.110.199.30 <none> 9090:30084/TCP 5s
# 浏览器进行访问即可
[root@master bao]# curl 10.104.43.174:30084
6、prometheus热加载
#修改了配置文件,为了不停止prometheus,就可以使配置文件生效
# 热加载命令
# pod的ip地址和svc的服务端口
[root@master prometheus]# curl -X POST http://10.244.166.134:9090/-/reload
[root@master ~]# kubectl logs -n monitor-sa prometheus-server-746949b4b9-mg7pf -f
# 可以查看日志,说明成功了
level=info ts=2024-09-25T08:37:31.191341253Z caller=main.go:588 msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml
level=info ts=2024-09-25T08:37:31.195301569Z caller=kubernetes.go:191 component="discovery manager scrape" discovery=k8s msg="Using pod service account via in-cluster config"
level=info ts=2024-09-25T08:37:31.196746822Z caller=kubernetes.go:191 component="discovery manager scrape" discovery=k8s msg="Using pod service account via in-cluster config"
level=info ts=2024-09-25T08:37:31.198121614Z caller=kubernetes.go:191 component="discovery manager scrape" discovery=k8s msg="Using pod service account via in-cluster config"
level=info ts=2024-09-25T08:37:31.199442235Z caller=kubernetes.go:191 component="discovery manager scrape" discovery=k8s msg="Using pod service account via in-cluster config"
# 热加载的速度比较慢
[root@master bao]# kubectl exec -ti -n monitor-sa prometheus-server-746949b4b9-mg7pf -- sh
/prometheus $ cd /etc/
/etc $ ls
group hosts passwd resolv.conf shadow
hostname localtime prometheus services ssl
/etc $ cd prometheus/
/etc/prometheus $ ls
console_libraries consoles prometheus.yml
3、安装和配置Grafana
- 可以将prometheus采集的数据可视化的展示
-
特点
-
展示仪式,快速的灵活的客户端图表,,面板插件有不同的方式可视化指标和日志
-
注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记
-
数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch 和KairosDB 等;
-
通知提醒:以可视方式定义最重要指标的警报规则,Grafana 将不断计算并发送通知,在数据达到阈值时通过 Slack、PagerDuty 等获得通知;
-
[root@master prometheus]# cat grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort
# 安装在kube-system名称空间下面
[root@master prometheus]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-d886b8fff-54nqt 1/1 Running 0 16m
calico-node-p747x 1/1 Running 0 16m
calico-node-t6g48 1/1 Running 0 16m
coredns-567c556887-f4kz7 1/1 Running 0 15m
coredns-567c556887-tmtp7 1/1 Running 0 15m
etcd-master 1/1 Running 1 (11m ago) 146m
kube-apiserver-master 1/1 Running 1 (11m ago) 146m
kube-controller-manager-master 1/1 Running 1 (11m ago) 146m
kube-proxy-6p8p4 1/1 Running 1 (21m ago) 146m
kube-proxy-p7nw5 1/1 Running 1 (21m ago) 144m
kube-scheduler-master 1/1 Running 1 (11m ago) 146m
monitoring-grafana-5c6bb4b6-5j28f 1/1 Running 0 12s
[root@master prometheus]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 147m
monitoring-grafana NodePort 10.97.126.161 <none> 80:31130/TCP 52s
# 浏览器进行访问,就能获取到监控数据的图形化的页面了
10.104.43.174:31130
1、grafana与prometheus连接
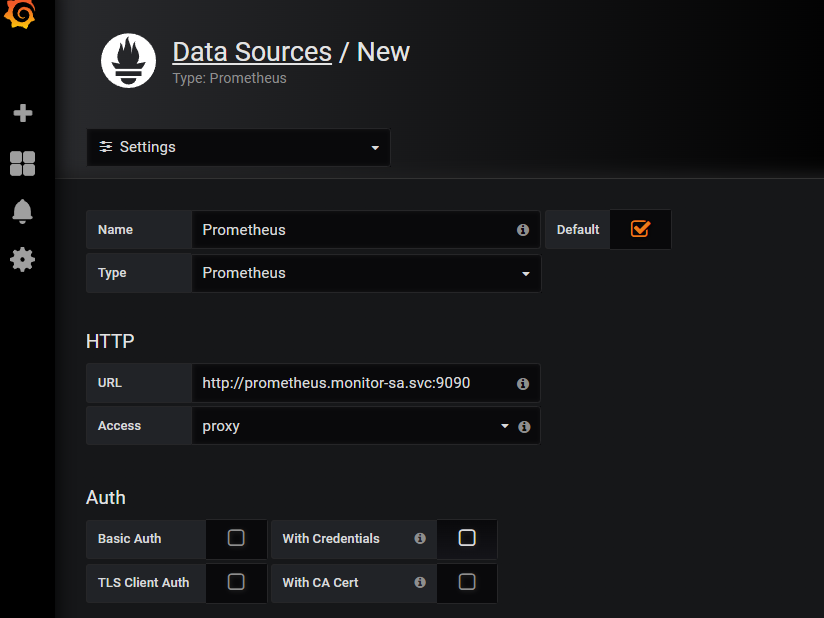
- 导入监控模版
# import 里面进行导入即可
node_exporter.json
-
能够在promtheus里面查询到的数据的话,也能在grafana里面获取到,grafana的数据也是通过prometheus里面获得的
-
查看容器数据,导入 docker_rev1.json
4、安装kube-state-metrics组件
-
通过监听api server生成有关资源对象的状态指标,deployment,node,pod等
-
kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些数据,prometheus抓取这些数据然后存储
-
主要是关注,调度了多少个rs,可用的,重启了多少次等
# 创建sa,并对sa进行授权
[root@master prometheus]# cat kube-state-metrics-rbac.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
# 安装kube-stat-metrics组件
[root@master prometheus]# cat kube-state-metrics-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: quay.io/coreos/kube-state-metrics:v1.9.0
ports:
- containerPort: 8080
# 创建一个svc关联deployment
[root@master prometheus]# cat kube-state-metrics-svc.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true' # 普罗米修斯可以获取这个svc的值,因为prometheus-cfg.yaml定义了获取这些参数的
name: kube-state-metrics
namespace: kube-system
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
- 安装成功后,prometheus查看这些数据
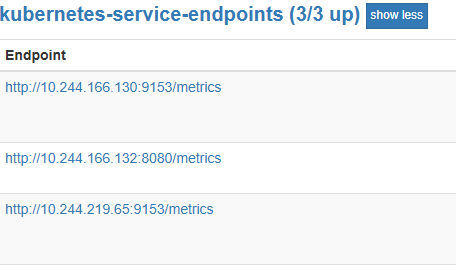
5、安装alertmanager组件
-
报警流程
-
prometheuss监控主机上暴露http接口(a接口),prometheus配置的scrape_interval定义的时间间隔,定期采集目标主机的上的数据
-
当接口a不可用的时候,server端会持续尝试从接口中抓取数据,超过了超时的时间,为变成down
-
altermanager发现接口为down的话,激活alert,进入pending状态,记录当前active时间
-
当下一个alert rule 的评估周期到来的时候,发现 UP=0 继续为真,然后判断警报 Active 的时间是否已经超出 rule 里的‘for’ 持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则 alert 的状态变为“FIRING”;同时调用 Alertmanager 接口,发送相关报警数据。
-
AlertManager 收到报警数据后,会将警报信息进行分组,然后根据 alertmanager 配置的“group_wait”时间先进行等待。等 wait 时间过后再发送报警信息。
-
属于同一个 Alert Group 的警报,在等待的过程中可能进入新的 alert,如果之前的报警已经成功发出,那么间隔“group_interval”的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个 group 的报警信息会汇总在一个邮件里进行发送。
-
如果 Alert Group 里的警报一直没发生变化并且已经成功发送,等待‘repeat_interval’时间间隔之后再重复发送相同的报警邮件;如果之前的警报没有成功发送,则相当于触发第 6 条条件,则需要等待 group_interval 时间间隔后重复发送。
-
同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,
-
# 生成一个配置文件altermanager
[root@master prometheus]# cat alertmanager-cm.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor-sa
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '@163.com'
smtp_auth_username: ''
smtp_auth_password: '授权码'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
- to: '@qq.com'
send_resolved: true
# 创建一个prometheus和altermanage关联的配置文件
[root@master prometheus]# ls prometheus-alertmanager-cfg.yaml
# 上传镜像altermanager.tar.gz
# 创建一个altermanager的deploy文件
[root@master prometheus]# cat prometheus-alertmanager-deploy.yaml
# 生成一个etcd-certs 就是创建一个secret
kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
# 注意需要把之前的prometheus删除掉
# 创建一个服务
[root@master prometheus]# cat alertmanager-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
name: prometheus
kubernetes.io/cluster-service: 'true'
name: alertmanager
namespace: monitor-sa
spec:
ports:
- name: alertmanager
nodePort: 30066
port: 9093
protocol: TCP
targetPort: 9093
selector:
app: prometheus
sessionAffinity: None
type: NodePort
[root@master prometheus]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager NodePort 10.106.71.70 <none> 9093:30066/TCP 14s
prometheus NodePort 10.110.199.30 <none> 9090:30084/TCP 5h6m
# 浏览器访问
http://10.104.43.174:30066/
# 这个时候qq邮箱就会有消息发送过来
3、prometheus语法
-
计算出来得到的值类型
-
瞬时向量,一组时序,每个时序只有一个采样值
-
区间向量,一组时序,每个时序有多个采样值
-
标量数据,一个浮点数
-
字符串
-
4、总结
-
还是非常的难的
-
字段的介绍
-
工作原理
1、prometheus.yml编写
global: # 全局部分
scrape_interval: 15s # 全局抓取的时间,每隔15秒抓取一次数据
scrape_configs: # 配置prometueus抓取数据的目标
- job_name: 'prometheus' # 抓取任务的目标
static_configs: # 定义静态配置
- targets: ['10.104.43.47:49185'] # 抓取数据的目标地址
- job_name: 'node'
static_configs:
- targets: ['10.104.43.47:49154'] # 替换为实际的节点导出器地址
- job_name: 'alertmanager'
static_configs:
- targets: ['10.104.43.47:49168'] # 替换为实际的告警管理器地址
# 添加规则文件
rule_files: # 定义了规则的配置文件
- '/data/prometheus/alert-rules.yml' # 指向你的警报规则文件

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









