









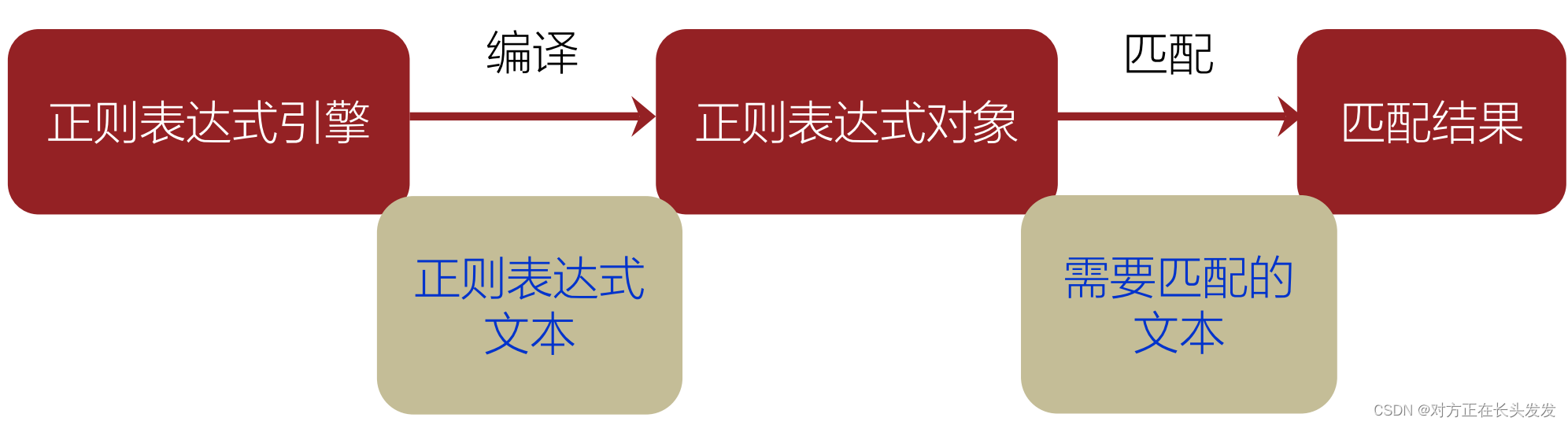
 本文详细介绍了正则表达式的概念、匹配过程,涵盖字符组、重复运算符(包括贪婪与非贪婪)、括号的作用、首尾匹配以及如何在Python中处理中文正则。还提供了几个实战案例和在线测试网址供读者练习。
本文详细介绍了正则表达式的概念、匹配过程,涵盖字符组、重复运算符(包括贪婪与非贪婪)、括号的作用、首尾匹配以及如何在Python中处理中文正则。还提供了几个实战案例和在线测试网址供读者练习。
目录
1.什么是正则表达式?
正则表达式(regular expression),又记作re或regex。是用来简洁表达一组字符串的表达式。
2.正则表达式匹配过程
• 依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功。
• 一旦有匹配不成功的字符则匹配失败。
3.匹配集合与补集
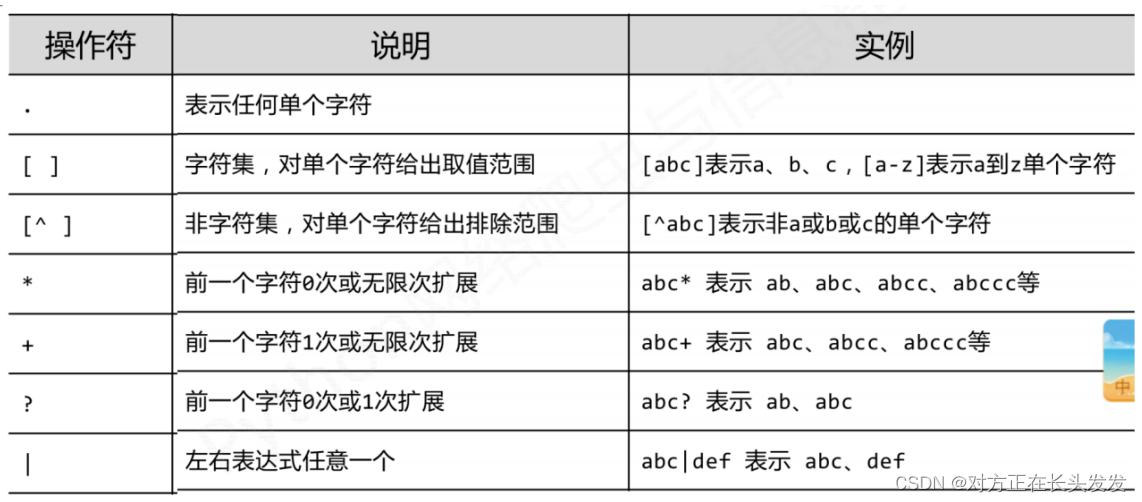
①字符组表达式 [ ] 匹配括号中列出的任一个字符
如:[abc] 可以匹配字符 a 或 b 或 c
区间形式 [0-9] 匹配所有十进制数字
字符 [0-9a-zA-Z] 匹配所有字母(英文字母)和数字
② [^...] 中的 ^ 表示求补,这种模式匹配所有未在括号里列出的字符
如:[^0-9] 匹配所有非十进制数字的字符
[^ \t\v\n\f\r] 匹配所有非空白字符(非空格/制表符/换行符)
注意:如果需要在字符组里包括 ^,就不能放在第一个位置,以免混淆含义。可以写\^恢复其本来含义;如果需要在字符组包括 - 或者 ],也必须写 \- 或 \]
4.常用字符组
1)为了方便,re 用换意串形式定义了几个常用字符组,包括:
①\d:与十进制数字匹配,等价于 [0-9]
②\D:与非十进制数字的所有字符匹配,等价于 [^0-9]
③\s:与所有空白字符匹配,等价于 [ \t\v\n\f\r]
④\S:与所有非空白字符匹配,等价于 [^ \t\v\n\f\r]
⑤\w:与所有字母数字字符匹配,等价于 [0-9a-zA-Z]
⑥\W:与所有非字母数字字符匹配,等价于 [^0-9a-zA-Z]
2)圆点字符 . 可以匹配任意一个字符
①a..b 匹配所有以 a 开头 b 结束的四字符串。
例如:模式: \w[^\w]\w,字符串:fsfjaksajkbkks^gctkjku 结果:s^g
5.重复
①基本重复运算符是 *,α*为α的 0 次或任意多次出现匹配。
例:[1-9][0-9]*或者[1-9]\d*代表任意大的正整数
②与 * 略微不同的重复运算符 + 表示 1 次或多次重复。
例:允许以0开头时,描述正整数的一种简单写法'\d+'。其中'α +',等价于 'αα* '。
③用 ? 运算符表示 0 次或 1 次重复。
例:描述整数(表示整数的字符串)的一种简单模式 '-?\d+'前面的'-?'部分表示可以以负号开头。
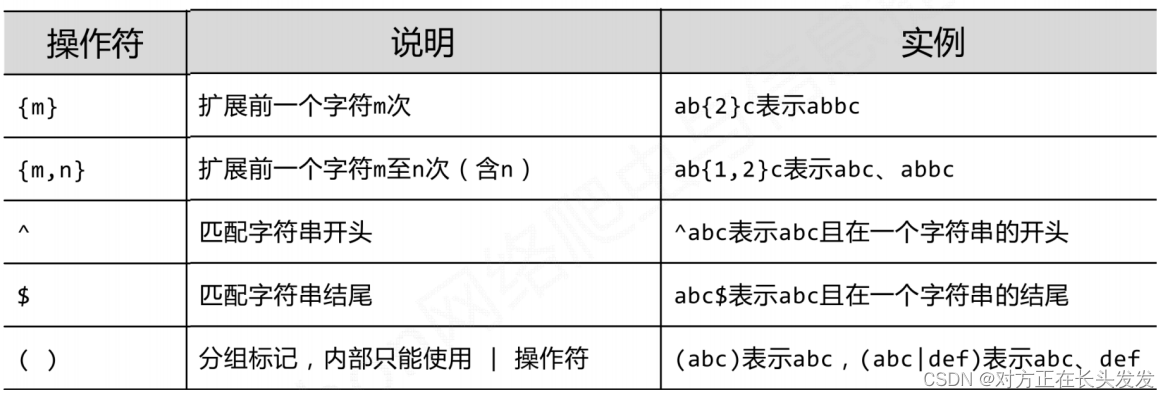
④确定次数的重复用{n}表示,如:α{n}表示α串的 n 次重复匹配。
例:描述北京常规的固话号码:'(010-)?[2-9][0-9]{7}'表示可选010前缀,2-9开头,后面的任意数字加起来一共可以有七位。
⑤重复范围用 {m,n} 表示,如:α{m,n}表示α匹配的串的 m 到 n 次重复匹配。
例,a{3,7} 与 3 到 7 个 a 构成的串匹配;go{2,10}gle 与 google, gooogle, ..., goooooooooogle 匹配。
重复范围中的 m 和 n 均可以省略,α{,n} 表示 α{0,n},而 α{m,} 表示 α{m, infinity}。注意: α{n} 等价于 α{n,n},α? 等价于 α{0,1} ,α* 等价于 α{0,infinity},α+等价于 α{1,infinity}。
(infinity表示无穷)
注意:*与+等重复要与前一个字符结合使用,表示对前一个字符的重复。
重复-总结:

6.重复-贪婪匹配模式:
特别注意,涉及重复的地方都会涉及一个概念叫做'贪婪匹配'。
如测试:字符串为abcdddddddd,正则表达式为abcd{3,5},正常理解的话,我们会认为正则表达式可匹配abcddd、abcdddd、abcddddd,但是实际匹配为abcddddd。
一般程序设计语言中,大多会默认正则表达式进行贪婪匹配,即可匹配的多个互相
有包含关系的时候,只匹配最大的那一个。
取消贪婪匹配模式:在产生贪婪匹配的正则表达式后加?符号
7.括号:
正则表达式中括号()将其内部的内容形成一个整体,再进行外部运算。
例如:ab*代表一个a与许多个b连在一起,而(ab)*代表任意多个(ab)连在一起:模式为"((ab)*) " 。测试:字符串为abbbbabababcdddddddd。
在正则表达式较大、较复杂的时候,要特别注意运算的规则,以及运用括号达到自己真正需要表达的意思结果为abcddd);abcd*(贪婪匹配),abcd+? (非贪婪,结果为abcd)。
8.首尾匹配---匹配行首用^,匹配行尾用$。
①行首匹配:以 ^ 符号开头的模式,只能与一行的前缀子串匹配。
例如'^for'只能匹配以'for'为前缀的一行。如果将其与一行'books for children'匹配,将得到 None。
②行尾匹配:以 $ 符号结尾的模式,只与一行的后缀匹配。
例如'fish$'只匹配以'fish'为后缀的一行。如果将其与一行'cats like to eat fishes'匹配,将得到 None。
注意:^与$代表的一行的开头与结束,而不是整个字符串的开头与结束。如果一个字符串中出现了多个换行符号,则模式或许可能与多个行首、行尾形成匹配。
总结:
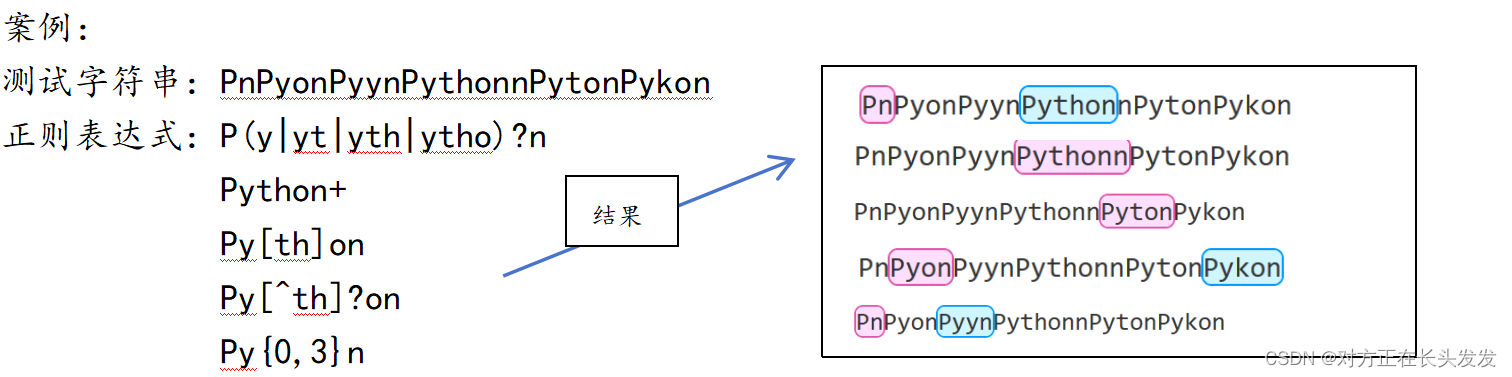
案例1:

案例2:

提示:Python re正则匹配中文,把中文的unicode字符串转换成utf-8格式就可以了,然后可以在re中随意调用unicode中中文的编码为/u4e00-/u9fa5,因此正则表达式u”[\u4e00-\u9fa5]+”可以表示一个或者多个中文字符。
案例3:
正则表达式测试网址:
大家了解了正则表达式,想看下自己结果是否正确,可以去测试网址练手。大家网上直接搜正则表达式测试,也可以找到。找不到的可以用下面的两个:















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









