






目录
二. 数据准备(coco格式全流程都可以//voc格式推理和个别时延测试时会报错,暂时未解决)
1.3 yolo格式标签转换coco格式标签(保存在annotations文件中)
2.2 yolo格式标签转换voc格式标签(保存在annotations文件中)
3.2 准备配置文件(以voc格式416*416大小为例,coco类似)
3.2.2 修改主配置文件 configs/picodet/picodet_xs_416_voc_lcnet.yml
3.2.5 修改训练优化参数optimizer_300e.yml
3.5 模型推理预测(使用voc格式训练无法预测,coco可以正常推理)
4.1 模型导出 (numpy==1.26.4 scipy==1.13.1)
4.2 模型转换onnx(numpy==1.26.4 scipy==1.13.1)
4.3 简化onnx模型(numpy==1.19.5 scipy==1.13.1)
4.4 使用OpenVINO测试CPU运行速度(voc格式中间的测试会报错,coco 不会)
4.4.1 Benchmark测试(numpy==1.19.5 scipy==1.5.4)
4.4.2 真实图片测试(网络不包含后处理)(numpy==1.19.5 scipy==1.5.4)
4.4.3 真实图片测试(网络包含后处理,但不包含NMS)(numpy==1.19.5 scipy==1.5.4)
一. 环境配置(cpu/gpu)
官方安装教程:https://github.com/PaddlePaddle/PaddleDetection/blob/develop/docs/tutorials/INSTALL_cn.md
1. 安装paddlepaddle
1.1 安装 CPU版本,没有任何报错
1.2 安装GPU版本,安装哪一个版本都会报错(我自己的电脑是这样)
# CUDA10.2
python -m pip install paddlepaddle-gpu==2.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# CPU
python -m pip install paddlepaddle==2.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple更多CUDA版本或环境快速安装,请参考:
https://www.paddlepaddle.org.cn/install/quick?docurl=undefined
请确保您的PaddlePaddle安装成功并且版本不低于需求版本。使用以下命令进行验证
# 在您的Python解释器中确认PaddlePaddle安装成功
python
>>> import paddle
>>> paddle.utils.run_check()
# 确认PaddlePaddle版本
python -c "import paddle; print(paddle.__version__)"2. 安装PaddleDetection
2.1 建议直接下载,解压,链接如下:
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.8.1
2.2 安装依赖
# 安装其他依赖
cd PaddleDetection
pip install -r requirements.txt
# 编译安装paddledet
python setup.py install
#安装后确认测试通过:
python ppdet/modeling/tests/test_architectures.py
#测试通过后会提示如下信息:
.......
----------------------------------------------------------------------
Ran 7 tests in 12.816s
OK注意:
1.在安装后确认测试通过这一步骤可能会报错:ModuleNotFoundError: No module named 'paddle.base'
解决方案:重新安装 paddledet 包,之后重新运行上述测试命令,就会成功运行
pip uninstall paddledet
pip install paddledet
3. 快速体验
# 在GPU上预测一张图片
export CUDA_VISIBLE_DEVICES=0
python tools/infer.py -c configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml -o use_gpu=true weights=https://paddledet.bj.bcebos.com/models/ppyolo_r50vd_dcn_1x_coco.pdparams --infer_img=demo/000000014439.jpg会在output文件夹下生成一个画有预测结果的同名图像。
如图:

注意:
1 这里可能会报与上述相同的错误:ModuleNotFoundError: No module named 'paddle.base'
解决方案:清理缓存后重新安装,就能成功运行
pip cache purge
pip install paddlepaddle
二. 数据准备(coco格式全流程都可以//voc格式推理和个别时延测试时会报错,暂时未解决)
1. coco格式数据准备
1.1 coco数据集完整格式如下:
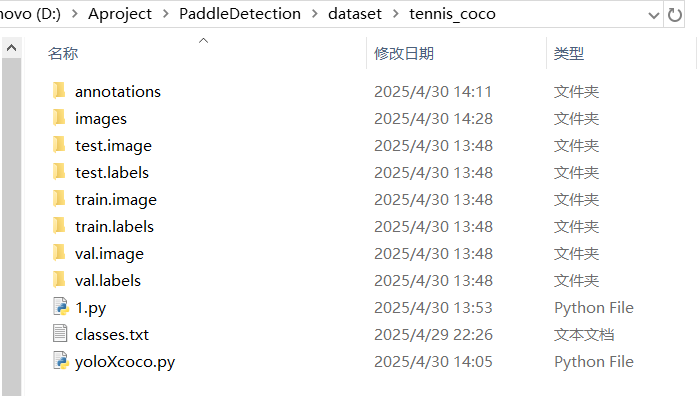
首先需要有images(即图片数据集)labels(yolo格式标签文件,这里后面划分好,我删除了)
classes.txt中为我们训练的类别,一行写一个类别
1.2 对图片和标签同步划分训练集,验证集,测试集
#请按照8:1:1的比例随机划分生成训练集,验证集,测试集
import os
import shutil
import random
# 设置图片和标注文件夹路径
image_dir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/images'
label_dir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/labels'
# 设置目标文件夹路径
train_image_dir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/train.image'
val_image_dir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/val.image'
test_image_dir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/test.image'
train_label_dir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/train.labels'
val_label_dir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/val.labels'
test_label_dir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/test.labels'
# 创建目标文件夹,如果文件夹不存在
os.makedirs(train_image_dir, exist_ok=True)
os.makedirs(val_image_dir, exist_ok=True)
os.makedirs(test_image_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
os.makedirs(test_label_dir, exist_ok=True)
# 获取所有图片文件和标注文件
image_files = [f for f in os.listdir(image_dir) if f.endswith(('.jpg', '.jpeg', '.png'))]
label_files = [f for f in os.listdir(label_dir) if f.endswith('.txt')] # 假设标注文件为 .txt 格式
# 确保图片和标注文件一一对应
assert len(image_files) == len(label_files), "图片和标注文件数量不匹配!"
# 打乱文件列表
random.shuffle(image_files)
# 计算划分的数量
total_files = len(image_files)
train_count = int(0.8 * total_files)
val_count = int(0.1 * total_files)
test_count = total_files - train_count - val_count # 剩余部分作为测试集
# 按比例划分
train_images = image_files[:train_count]
val_images = image_files[train_count:train_count + val_count]
test_images = image_files[train_count + val_count:]
# 获取对应的标注文件
def get_label_file(image_name):
label_name = os.path.splitext(image_name)[0] + '.txt'
return label_name
# 移动文件到目标文件夹
def move_files(image_list, image_dir, label_dir, image_dest, label_dest):
for image_name in image_list:
# 图片文件路径
image_path = os.path.join(image_dir, image_name)
label_name = get_label_file(image_name)
label_path = os.path.join(label_dir, label_name)
# 目标文件路径
image_dest_path = os.path.join(image_dest, image_name)
label_dest_path = os.path.join(label_dest, label_name)
# 移动图片和标注文件
shutil.move(image_path, image_dest_path)
shutil.move(label_path, label_dest_path)
# 移动到训练集、验证集和测试集文件夹
move_files(train_images, image_dir, label_dir, train_image_dir, train_label_dir)
move_files(val_images, image_dir, label_dir, val_image_dir, val_label_dir)
move_files(test_images, image_dir, label_dir, test_image_dir, test_label_dir)
print(f"划分完成!共 {total_files} 张图片和标注文件,训练集 {len(train_images)} 张,验证集 {len(val_images)} 张,测试集 {len(test_images)} 张。")
1.3 yolo格式标签转换coco格式标签(保存在annotations文件中)
import os
import json
import cv2
import random
import time
from PIL import Image
# 修改为要生成的annotations文件夹位置
coco_format_save_path = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/annotations' # 要生成的标准coco格式标签所在文件夹
# 类别文件:原来COCO Json格式中的类别名称,将其写到classes.txt文件中,每行一个
yolo_format_classes_path = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/classes.txt' # 类别文件,一行一个类
# 注意区分训练集和测试集文件位置
yolo_format_annotation_path = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/train.labels' # yolo格式标签所在文件夹
img_pathDir = 'D:/Aproject/PaddleDetection/dataset/tennis_coco/train.image' # 图片所在文件夹
if not os.path.exists(coco_format_save_path):
os.makedirs(coco_format_save_path)
# 打开并读取类别文件
with open(yolo_format_classes_path, 'r') as fr:
lines1 = fr.readlines()
# print(lines1)
# 存储类别的列表
categories = []
for j, label in enumerate(lines1):
label = label.strip()
# 将类别信息添加到categories中
categories.append({'id': j + 1, 'name': label, 'supercategory': 'None'})
# print(categories)
# 写入.json文件的大字典
write_json_context = dict()
write_json_context['info'] = {'description': '', 'url': '', 'version': '', 'year': 2024, 'contributor': 'kak',
'date_created': '2024-06-28'}
write_json_context['licenses'] = [{'id': 1, 'name': None, 'url': None}]
write_json_context['categories'] = categories
write_json_context['images'] = []
write_json_context['annotations'] = []
# 接下来的代码主要添加'images'和'annotations'的key值
# 遍历该文件夹下的所有文件,并将所有文件名添加到列表中
imageFileList = os.listdir(img_pathDir)
for i, imageFile in enumerate(imageFileList):
# 获取图片的绝对路径
imagePath = os.path.join(img_pathDir, imageFile)
image = Image.open(imagePath)
# 读取图片,然后获取图片的宽和高
W, H = image.size
# 使用一个字典存储该图片信息
img_context = {}
# 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值
# img_name=os.path.basename(imagePath)
img_context['file_name'] = imageFile
img_context['height'] = H
img_context['width'] = W
img_context['date_captured'] = '2022-07-8'
# 该图片的id
img_context['id'] = i
img_context['license'] = 1
img_context['color_url'] = ''
img_context['flickr_url'] = ''
# 将该图片信息添加到'image'列表中
write_json_context['images'].append(img_context)
txtFile = imageFile.replace('.jpg', '.txt')
# 获取该图片获取的txt文件
# txtFile=imageFile[:5]+'.txt'
with open(os.path.join(yolo_format_annotation_path, txtFile), 'r') as fr:
# 读取txt文件的每一行数据,lines2是一个列表,包含了一个图片的所有标注信息
lines = fr.readlines()
for j, line in enumerate(lines):
# 将每一个bounding box信息存储在该字典中
bbox_dict = {}
# line = line.strip().split()
# print(line.strip().split(' '))
# 获取每一个标注框的详细信息
class_id, x, y, w, h = line.strip().split(' ')
# 将字符串类型转为可计算的int和float类型
class_id, x, y, w, h = int(class_id), float(x), float(y), float(w), float(h)
# 坐标转换
xmin = (x - w / 2) * W
ymin = (y - h / 2) * H
xmax = (x + w / 2) * W
ymax = (y + h / 2) * H
w = w * W
h = h * H
# bounding box的坐标信息
bbox_dict['id'] = i * 10000 + j
bbox_dict['image_id'] = i
# 注意目标类别要加一
bbox_dict['category_id'] = class_id + 1
bbox_dict['iscrowd'] = 0
height, width = abs(ymax - ymin), abs(xmax - xmin)
bbox_dict['area'] = height * width
bbox_dict['bbox'] = [xmin, ymin, w, h]
bbox_dict['segmentation'] = [[xmin, ymin, xmax, ymin, xmax, ymax, xmin, ymax]]
# 将每一个由字典存储的bounding box信息添加到'annotations'列表中
write_json_context['annotations'].append(bbox_dict)
name = os.path.join(coco_format_save_path, "train" + '.json') #这里要改你要生成标注文件的名字
if not os.path.exists(name):
with open(name, 'w') as fw:
# 将字典信息写入.json文件中
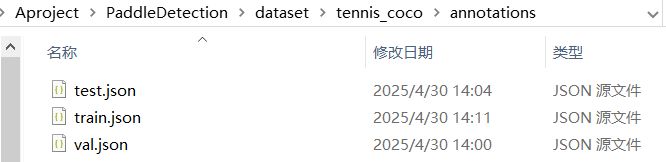
json.dump(write_json_context, fw, indent=2)注意:上述代码需要运行3次,分别是转换训练集,验证集,测试集的标签
转换后的标签存放在annotations文件,如下图:
2. voc格式数据准备
2.1 voc数据集完整格式如下:

首先需要有images(即图片数据集)labels(yolo格式标签文件)
label_list.txt 中为我们训练的类别,且这个名字不能更改
2.2 yolo格式标签转换voc格式标签(保存在annotations文件中)
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
dic = {'0': "Person", # 创建字典用来对类型进行转换
'1': "Racket",
'2': "sky_moving_ball",
'3': "machine_box",# 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "D:/Aproject/PaddleDetection/dataset/tennis_voc/images/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "D:/Aproject/PaddleDetection/dataset/tennis_voc/labels/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "D:/Aproject/PaddleDetection/dataset/tennis_voc/annotations/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)2.3 划分训练集,验证集,测试集图片和标签路径
train.txt,val.txt,test.txt文件中格式为:前面为图片路径,然后空格,然后对应标签路径
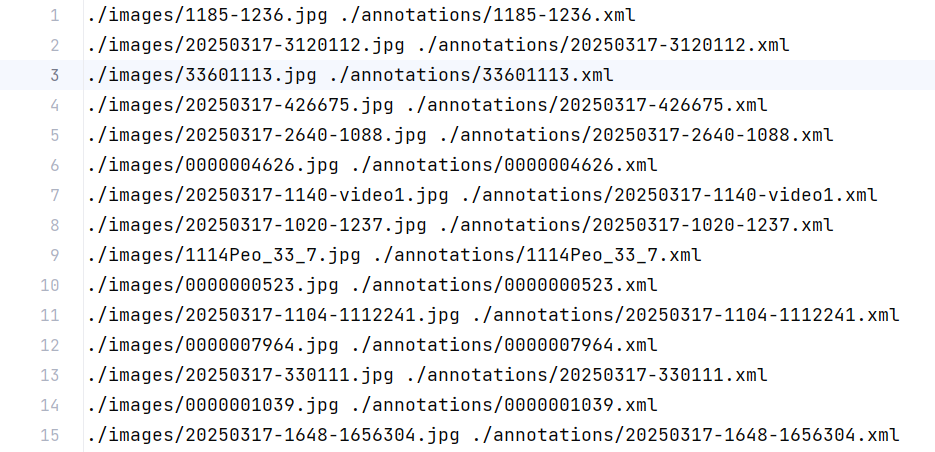
所以我选择先生成图片路径(懒得将两个代码合一了)
#按照8:1:1的比例随机生成训练集,验证集,测试集图片路径,格式为:./images/xxx3.jpg
import os
import random
# 定义文件夹路径
image_folder = "D:/Aproject/PaddleDetection/dataset/tennis_voc/images"
output_folder = "D:/Aproject/PaddleDetection/dataset/tennis_voc" # 输出的txt文件将保存到这个文件夹
# 获取所有图片文件名
image_files = [f for f in os.listdir(image_folder) if f.endswith('.jpg')]
# 输出总共的图片数量
total_images = len(image_files)
print(f"共有图片 {total_images} 张")
# 打乱文件列表
random.shuffle(image_files)
# 计算训练集、验证集和测试集的大小
train_size = int(0.8 * total_images)
val_size = int(0.1 * total_images)
test_size = total_images - train_size - val_size
# 按照比例划分文件列表
train_files = image_files[:train_size]
val_files = image_files[train_size:train_size + val_size]
test_files = image_files[train_size + val_size:]
# 输出各个数据集的数量
print(f"训练集包含 {len(train_files)} 张图片")
print(f"验证集包含 {len(val_files)} 张图片")
print(f"测试集包含 {len(test_files)} 张图片")
# 定义文件路径
train_txt = os.path.join(output_folder, 'train.txt')
val_txt = os.path.join(output_folder, 'val.txt')
test_txt = os.path.join(output_folder, 'test.txt')
# 写入train.txt
with open(train_txt, 'w') as f:
for image in train_files:
f.write(f'./images/{image}\n')
# 写入val.txt
with open(val_txt, 'w') as f:
for image in val_files:
f.write(f'./images/{image}\n')
# 写入test.txt
with open(test_txt, 'w') as f:
for image in test_files:
f.write(f'./images/{image}\n')
print(f"数据集已成功划分并保存为 {train_txt}, {val_txt}, {test_txt}")
然后在生成对应标签路径
#该脚本会生成一个新的文件 train_updated.txt,原始的 train.txt 文件保持不变。如果你希望直接修改原始文件,
# 可以直接将 train_txt_path 和 new_train_txt_path 设置为同一文件路径,并用 'w' 模式覆盖原文件。
#在每一行图片路径后面 首先空一格,再添加该图片对应的xml标注文件路径,格式如下 ./images/20250317-1112-1120126.jpg ./annotations/20250317-1112-1120126.jpg
# 定义文件路径
train_txt_path = "D:/Aproject/PaddleDetection/dataset/tennis_voc/test.txt"
new_train_txt_path = "D:/Aproject/PaddleDetection/dataset/tennis_voc/test.txt"
# 打开原始的train.txt文件读取内容
with open(train_txt_path, 'r') as f:
lines = f.readlines()
# 打开新的文件保存修改后的内容
with open(new_train_txt_path, 'w') as f:
for line in lines:
# 去除行末的换行符并获取图片路径
image_path = line.strip()
# 构建对应的xml标注文件路径
xml_path = image_path.replace('./images', './annotations').replace('.jpg', '.xml')
# 将原图片路径和xml路径写入新的文件
f.write(f"{image_path} {xml_path}\n")
print(f"已成功创建新的文件:{new_train_txt_path}")
三. 开始模型训练
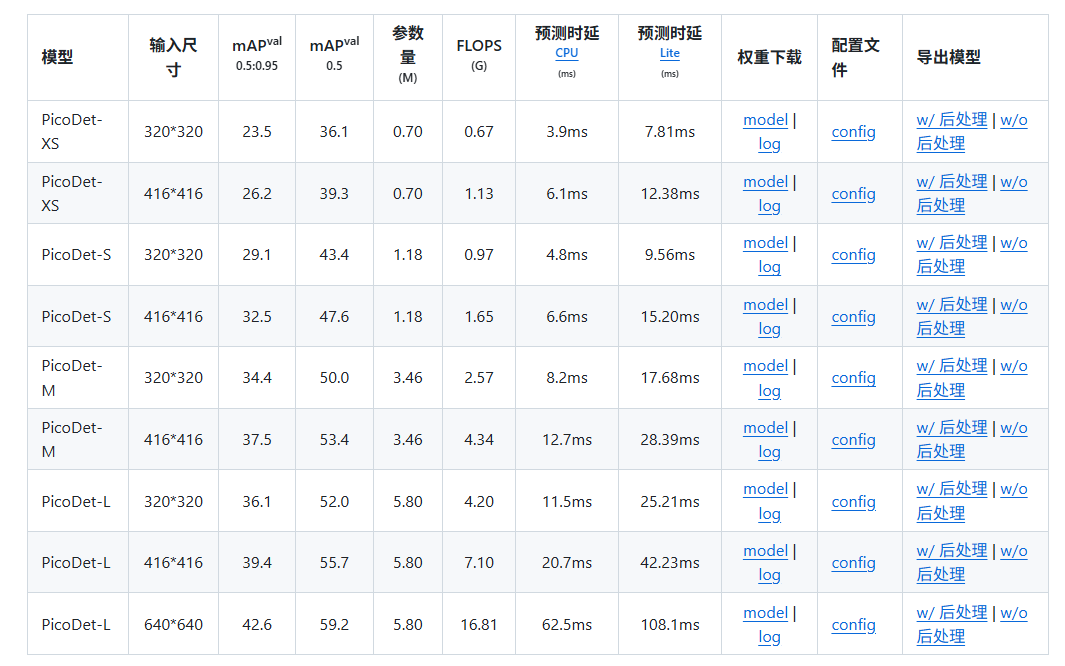
3.1 下载预训练模型
在PaddleDetection目录下新建文件夹:pretrained_model
在该链接下,下载你需要的预训练模型,并放到pretrained_model文件中:如图所示
3.2 准备配置文件(以voc格式416*416大小为例,coco类似)
复制 configs/picodet/picodet_xs_416_coco_lcnet.yml 在原路径下重命名为
configs/picodet/picodet_xs_416_voc_lcnet.yml这个是主配置文件,
复制configs/datasets/voc.yml 在原路径下重命名为(根据自己需要改)
configs/datasets/voc_tennis.yml,这个是数据相关配置文件。
3.2.1 修改voc_tennis.yml
如何自定义数据集,官方参考链接:https://aistudio.baidu.com/projectdetail/1917140?login_type=weixin&login_type=weixin&login_type=weixin
根据其中说明修改
dataset_dir: 表示数据集的路径(该路径下保存数据集、标注文件、标签以及训练验证数据集说明txt文件)
anno_path: 表示训练/验证数据集的说明txt文件路径 (该处填写相对于dataset_dir的相对路径)
label_list: 表示label的txt文件路径(该处填写相对于dataset_dir的相对路径)
在TestDataset的配置中,对于的主要是label_list的路径,确保在测试过程中,有正确的标签
如图:
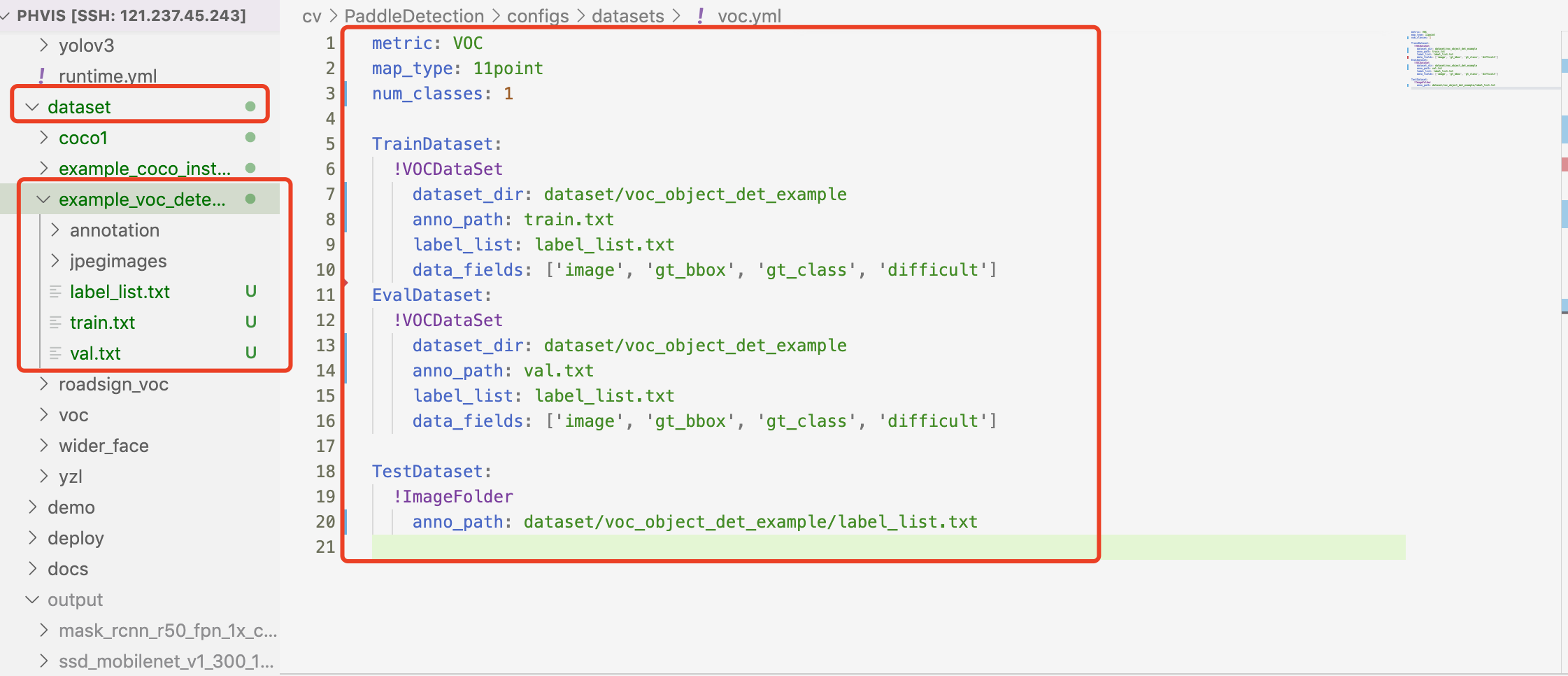
修改后我的voc_tennis.yml
metric: VOC
map_type: 11point
num_classes: 4
TrainDataset:
name: VOCDataSet
dataset_dir: D:/Aproject/PaddleDetection/dataset/tennis_voc
anno_path: train.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
name: VOCDataSet
dataset_dir: D:/Aproject/PaddleDetection/dataset/tennis_voc
anno_path: val.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
name: ImageFolder
anno_path: D:/Aproject/PaddleDetection/dataset/tennis_voc/label_list.txt
coco格式自定义数据集
当用户使用COOC数据集进行目标检测的时候,只需要对cooc_detection.yml进行修改即可实现正常训练。
我们提供了一个自定义的COCO数据集,并整理成如图如下图所示的形式。用户在cooc_detection.yml文件中修改路径即可。
image_dir: 表示训练/验证图片的路径
anno_path: 表示训练/验证图片的标注文件的路径
dataset_dir: 表示数据集的路径(该路径下保存数据集、标签)
在TestDataset的配置中,对于的主要是引入标签,这里会抽取val.json文件中标签,确保在测试过程中,有正确的标签
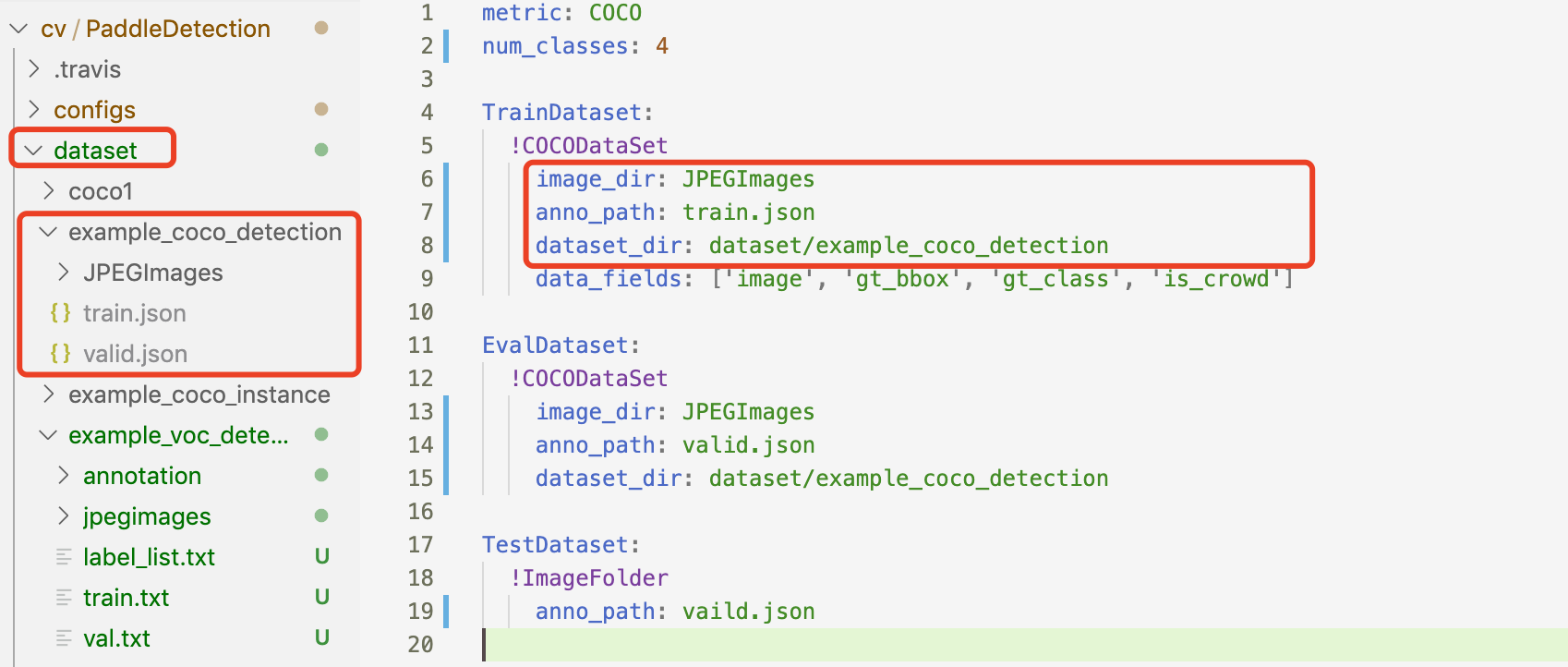
修改后我的coco_tennis.yml
metric: COCO
num_classes: 4
TrainDataset:
name: COCODataSet
image_dir: D:/Aproject/PaddleDetection/dataset/tennis_coco/train.image
anno_path: D:/Aproject/PaddleDetection/dataset/tennis_coco/annotations/train.json
dataset_dir: D:/Aproject/PaddleDetection/dataset/tennis_coco
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
EvalDataset:
name: COCODataSet
image_dir: D:/Aproject/PaddleDetection/dataset/tennis_coco/val.image
anno_path: D:/Aproject/PaddleDetection/dataset/tennis_coco/annotations/val.json
dataset_dir: D:/Aproject/PaddleDetection/dataset/tennis_coco
allow_empty: true
TestDataset:
name: ImageFolder
anno_path: D:/Aproject/PaddleDetection/dataset/tennis_coco/annotations/test.json # also support txt (like VOC's label_list.txt)
dataset_dir: D:/Aproject/PaddleDetection/dataset/tennis_coco # if set, anno_path will be 'dataset_dir/anno_path'
3.2.2 修改主配置文件 configs/picodet/picodet_xs_416_voc_lcnet.yml
主配置文件中设置的参数会覆盖掉子配置文件相关参数,所以子配置文件可以保留不变,想要修改直接在主配置文件中修改,这样避免要修改的地方太分散。
改前configs/picodet/picodet_xs_416_coco_lcnet.yml
_BASE_: [
'../datasets/coco_detection.yml',
'../runtime.yml',
'_base_/picodet_v2.yml',
'_base_/optimizer_300e.yml',
'_base_/picodet_640_reader.yml',
]
pretrain_weights: https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/legendary_models/PPLCNet_x2_0_pretrained.pdparams
weights: output/picodet_l_320_coco/best_model
find_unused_parameters: True
use_ema: true
epoch: 200
snapshot_epoch: 10
LCNet:
scale: 2.0
feature_maps: [3, 4, 5]
LCPAN:
out_channels: 160
PicoHeadV2:
conv_feat:
name: PicoFeat
feat_in: 160
feat_out: 160
num_convs: 4
num_fpn_stride: 4
norm_type: bn
share_cls_reg: True
use_se: True
feat_in_chan: 160
LearningRate:
base_lr: 0.06
schedulers:
- !CosineDecay
max_epochs: 300
- !LinearWarmup
start_factor: 0.1
steps: 300
TrainReader:
batch_size: 12
改后:configs/picodet/picodet_xs_416_voc_lcnet.yml
_BASE_: [
'../datasets/voc_tennis.yml', #改成VOC读取方式
'../runtime.yml',
'_base_/picodet_v2.yml',
'_base_/optimizer_300e.yml',
'_base_/picodet_416_reader.yml',
]
pretrain_weights: D:/Aproject/PaddleDetection/pretrained_model/picodet_xs_416_coco_lcnet.pdparams #训练时不加载就注注释掉
weights: output/picodet_xs_416_voc/model_final.pdparams #训练时注释掉,模型评估和推理时使用的训练后保存的最佳模型
find_unused_parameters: True
use_ema: true
epoch: 1 #改总共要训300个epoch
snapshot_epoch: 1 #可改可不改,表示几个epoch保存一个模型
LCNet:
scale: 0.35
feature_maps: [3, 4, 5]
LCPAN:
out_channels: 96
PicoHeadV2:
conv_feat:
name: PicoFeat
feat_in: 96
feat_out: 96
num_convs: 2
num_fpn_stride: 4
norm_type: bn
share_cls_reg: True
use_se: True
feat_in_chan: 96
TrainReader:
batch_size: 64 #可改可不改,根据gpu显存大小来设置即可,表示一次推理所用的图片数,如果是多卡,会分散到各个卡上,所以batch_size要能被GPU整除
LearningRate:
base_lr: 0.07 #改,官方用四个显卡,我们用1个,学习率改为1/4
schedulers:
- name: CosineDecay
max_epochs: 300
- name: LinearWarmup
start_factor: 0.1
steps: 300
3.2.3 修改runtime.yml
原runtime.yml,基本不需要修改(不放心就和主配置文件修改对应的数据)
use_gpu: true #是否使用GPU训练
use_xpu: false #是否使用XPU训练
log_iter: 20 #显示训练信息的迭代间隔
save_dir: output #模型保存位置
snapshot_epoch: 1 #模型保存间隔
print_flops: false
# Exporting the model #这个是与导出模型有关
export:
post_process: True # Whether post-processing is included in the network when export model.
nms: True # Whether NMS is included in the network when export model.
benchmark: False # It is used to testing model performance, if set `True`, post-process and NMS will not be exported.
我使用的CPU训练,所以 use_gpu: false
模型保存位置可以修改为自己想要保存的位置
3.2.4 修改模型网络参数picodet_v2.yml
这部分也是不用改的,需要改的部分己经在主配置文件中做了覆盖。
3.2.5 修改训练优化参数optimizer_300e.yml
修改前的optimizer_300e.yml
epoch: 300
LearningRate:
base_lr: 0.32
schedulers:
- !CosineDecay
max_epochs: 300
- !LinearWarmup
start_factor: 0.1
steps: 300
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.00004
type: L2
主要是关于学习率和优化器的配置,其中学习率已经在主配置文件做了修改。学习率这个可以尝试的设。(不放心设置为和主配置文件相同)
3.2.6 修改数据读取器配置picodet_640_reader.yml
修改前的picodet_640_reader.yml
worker_num: 6
eval_height: &eval_height 640
eval_width: &eval_width 640
eval_size: &eval_size [*eval_height, *eval_width]
TrainReader:
sample_transforms:
- Decode: {}
- RandomCrop: {}
- RandomFlip: {prob: 0.5}
- RandomDistort: {}
batch_transforms:
- BatchRandomResize: {target_size: [576, 608, 640, 672, 704], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
- PadGT: {}
batch_size: 32
shuffle: true
drop_last: true
EvalReader:
sample_transforms:
- Decode: {}
- Resize: {interp: 2, target_size: *eval_size, keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_transforms:
- PadBatch: {pad_to_stride: 32}
batch_size: 8
shuffle: false
TestReader:
inputs_def:
image_shape: [1, 3, *eval_height, *eval_width]
sample_transforms:
- Decode: {}
- Resize: {interp: 2, target_size: *eval_size, keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_size: 1
修改下和主配置文件一样的batch_size即可
3.3 模型训练
GPU单卡训练(如果想边训练边评估,在结尾添加 --eval)
export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
python tools/train.py -c configs/picodet/picodet_xs_416_voc_lcnet.yml训练可视化
在训练命令后面添加 --use_vdl=true --vdl_log_dir=vdl_dir/scalar 如下
python tools/train.py -c configs/picodet/picodet_xs_416_voc_lcnet.yml --use_vdl=true --vdl_log_dir=vdl_dir/scalar然后,新打开一个终端输入:
visualdl --logdir vdl_dir/scalar/
然后根据浏览器输入提示的网址,效果如下:
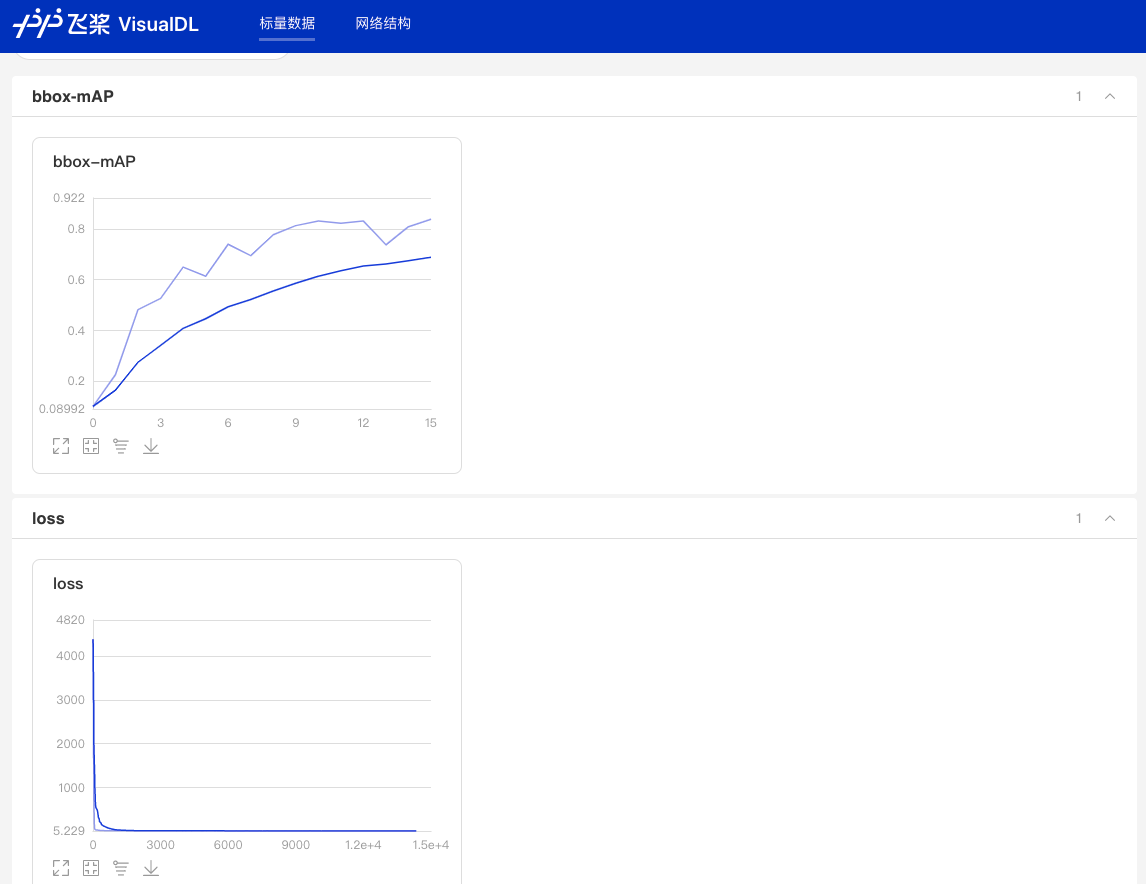
GPU多卡训练
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 #windows和Mac下不需要执行该命令
python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml在日常训练过程中,有的用户由于一些原因导致训练中断,用户可以使用-r的命令恢复训练
export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
python tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml -r output/faster_rcnn_r50_1x_coco/100003.4 模型评估
默认将训练生成的模型保存在当前output文件夹下,在runtime.yml中可以修改训练生成的模型保存路径
export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
python tools/eval.py -c configs/picodet/picodet_xs_416_voc_lcnet.yml -o weights=output/picodet_xs_416_coco/model_final.pdparams 注意:边训练边评估时,如果验证集很大,测试将会比较耗时,建议调整configs/runtime.yml 文件中的 snapshot_epoch配置以减少评估次数,或训练完成后再进行评估。
输出的结果类似是这样(使用voc格式的话):
[07/06 10:08:52] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 71.69%
[07/06 10:08:52] ppdet.engine INFO: Total sample number: 5237, averge FPS: 51.81244804206111
要获复每个类别的结果:后面添加 --classwise
python tools/eval.py -c configs/picodet/picodet_l_640_voc_lcnet_my.yml -o weights=output/picodet_l_640_voc_lcnet_my/best_model.pdparams --classwise
会列出每个分类的AP值,样子大概是这样:
[07/06 10:22:12] ppdet.metrics.map_utils INFO: Per-category of VOC AP:
+----------+-------+
| category | AP |
+----------+-------+
| screen | 0.717 |
+----------+-------+
[07/06 10:22:12] ppdet.metrics.map_utils INFO: per-category PR curve has output to voc_pr_curve folder.
[07/06 10:22:12] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 71.69%
[07/06 10:22:12] ppdet.engine INFO: Total sample number: 5237, averge FPS: 52.107162396101515
输出以上结果,同时会在voc_pr_curve下生成每个分类的PR曲线。由于数据格式是VOC所以无法输出COCO的格式。
3.5 模型推理预测(使用voc格式训练无法预测,coco可以正常推理)
python tools/infer.py -c configs/picodet/picodet_xs_416_coco_lcnet.yml -o use_gpu=false weights=output/picodet_xs_416_coco/model_final.pdparams --infer_img=dataset/tennis_voc/images/6120117.jpg有几个可以加的参数:
--draw_threshold=0.5 # 结果画框只画大于该阈值的框
--output_dir='output' # 指定画框后结果保存位置
四. 部署
4.1 模型导出 (numpy==1.26.4 scipy==1.13.1)
注意:在导出时预训练模型,和实际训练的权重都不能缺少,否则会报错weights路径错误

cd PaddleDetection
python tools/export_model.py -c configs/picodet/picodet_xs_416_coco_lcnet.yml -o weights=output/picodet_xs_416_coco/model_final.pdparams --output_dir=output_inference如无需导出后处理,请指定:-o export.post_process=False(如果-o已出现过,此处删掉-o)或者手动修改runtime.yml 中相应字段。
如无需导出NMS,请指定:-o export.nms=False或者手动修改runtime.yml 中相应字段。 许多导出至ONNX场景只支持单输入及固定shape输出,所以如果导出至ONNX,推荐不导出NMS。
4.2 模型转换onnx(numpy==1.26.4 scipy==1.13.1)
安装Paddle2ONNX >= 0.7 并且 ONNX > 1.10.1
pip install onnx
pip install paddle2onnx==0.9.2转换模型
paddle2onnx --model_dir output_inference/picodet_xs_416_coco_lcnet --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file picodet_xs_416_coco.onnx4.3 简化onnx模型(numpy==1.19.5 scipy==1.13.1)
简化onnx模型时会报错,因为numpy不兼容问题,此时要重新安装numpy==1.19.5
pip install numpy==1.19.5 -i https://pypi.tuna.tsinghua.edu.cn/simple/安装 onnxsim >= 0.4.1:
pip install onnxsim简化ONNX模型: 后面那个是简化后模型的名称,可以自己更改
onnxsim picodet_xs_416_coco.onnx picodet_s_processed_coco.onnx4.4 使用OpenVINO测试CPU运行速度(voc格式中间的测试会报错,coco 不会)
本demo安装的是 OpenVINO 2022.1.0,可直接运行如下指令安装:
pip install openvino==2022.1.04.4.1 Benchmark测试(numpy==1.19.5 scipy==1.5.4)
Benchmark测试会报错,因为scipy不兼容问题,此时要重新安装scipy==1.5.4
pip install scipyy==1.5.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/准备测试模型:根据PicoDet中【导出及转换模型】步骤,采用不包含后处理的方式导出模型(-o export.benchmark=True ),并生成待测试模型简化后的onnx模型(可在下文链接中直接下载)。同时在本目录下新建out_onnxsim文件夹,将导出的onnx模型放在该目录下。
导出时:后面要加 -o export.benchmark=True -o export.post_process=False
准备测试所用图片:本demo默认利用PaddleDetection/demo/000000014439.jpg
在本目录下直接运行:该目录为D:\Aproject\PaddleDetection\deploy\third_engine\demo_openvino\python\openvino_benchmark.py
也就是说,测试时要先进入该目录下,然后再运行测试命令
# Linux
python openvino_benchmark.py --img_path ../../../../demo/000000014439.jpg --onnx_path out_onnxsim/picodet_s_320_coco_lcnet.onnx --in_shape 320
# Windows
python openvino_benchmark.py --img_path ..\..\..\..\demo\000000014439.jpg --onnx_path out_onnxsim\picodet_s_320_coco_lcnet.onnx --in_shape 320我自己训练的命令为
python openvino_benchmark.py --img_path ..\..\..\..\dataset\tennis_voc\images\1185-1236.jpg --onnx_path D:\Aproject\PaddleDetection\out_onnxsim\picodet_xs_416_coco_Benchmark.onnx --in_shape 416
注意:--in_shape为对应模型输入size,默认为320
4.4.2 真实图片测试(网络不包含后处理)(numpy==1.19.5 scipy==1.5.4)
导出时:后面要加 -o export.post_process=False
测试命令
# Linux
python openvino_benchmark.py --benchmark 0 --img_path ../../../../demo/000000014439.jpg --onnx_path out_onnxsim/picodet_s_320_coco_lcnet.onnx --in_shape 320
# Windows
python openvino_benchmark.py --benchmark 0 --img_path ..\..\..\..\demo\000000014439.jpg --onnx_path out_onnxsim\picodet_s_320_coco_lcnet.onnx --in_shape 320我的测试命令
python openvino_benchmark.py --benchmark 0 --img_path ..\..\..\..\dataset\tennis_voc\images\1185-1236.jpg --onnx_path D:\Aproject\PaddleDetection\out_onnxsim\picodet_xs_416_coco_no_post_process.onnx --in_shape 4164.4.3 真实图片测试(网络包含后处理,但不包含NMS)(numpy==1.19.5 scipy==1.5.4)
准备测试模型:根据PicoDet中【导出及转换模型】步骤,采用包含后处理但不包含NMS的方式导出模型(-o export.benchmark=False export.nms=False ),并生成待测试模型简化后的onnx模型(可在下文链接中直接下载)。同时在本目录下新建out_onnxsim_infer文件夹,将导出的onnx模型放在该目录下。
所以,导出时,后面要加:-o export.benchmark=False -o export.nms=False
# Linux
python openvino_infer.py --img_path ../../demo_onnxruntime/imgs/bus.jpg --onnx_path out_onnxsim_infer/picodet_s_320_postproccesed_woNMS.onnx --in_shape 320
# Windows
python openvino_infer.py --img_path ..\..\demo_onnxruntime\imgs\bus.jpg --onnx_path out_onnxsim_infer\picodet_s_320_postproccesed_woNMS.onnx --in_shape 320我的命令:
python openvino_infer.py --img_path ..\..\..\..\demo\5.jpg --onnx_path D:\Aproject\PaddleDetection\out_onnxsim_infer\picodet_s_processed_coco_no_NMS.onnx --in_shape 416

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









