







目录
前言
本文主要从元素的定位、测试对象操作、窗口、弹窗、等待、浏览器导航、文件上传、浏览器参数设置这几个方面介绍一下selenium自动化测试工具。
一、什么是自动化?
自动化简单理解一下就是使用工具代替人力劳动,将人从劳动中解放出来。具体到我们的测试工作中就是:我们使用一些工具来代替我们完成一些重复的“点点点”的工作。Selenium就是一款自动化工具,我们可以使用它来解放我们的生产力!
二、元素的定位
假设我们想在相对一款浏览器的首页进行测试,我们首先就必须要能够“找到”对应的元素而后执行相应的操作。

比方说,我们现在想测试搜索功能是否正常,我们就需要将想要搜索的文本设置进搜索框中并且点击搜索按钮进行搜索,如果浏览器能够返回和我们输入文本相关性比较强的响应页,那么我们就可以这次测试的结果是正常的。
那么问题来了,在上述的问题中我们如何定位“搜索框”和“按钮”呢?
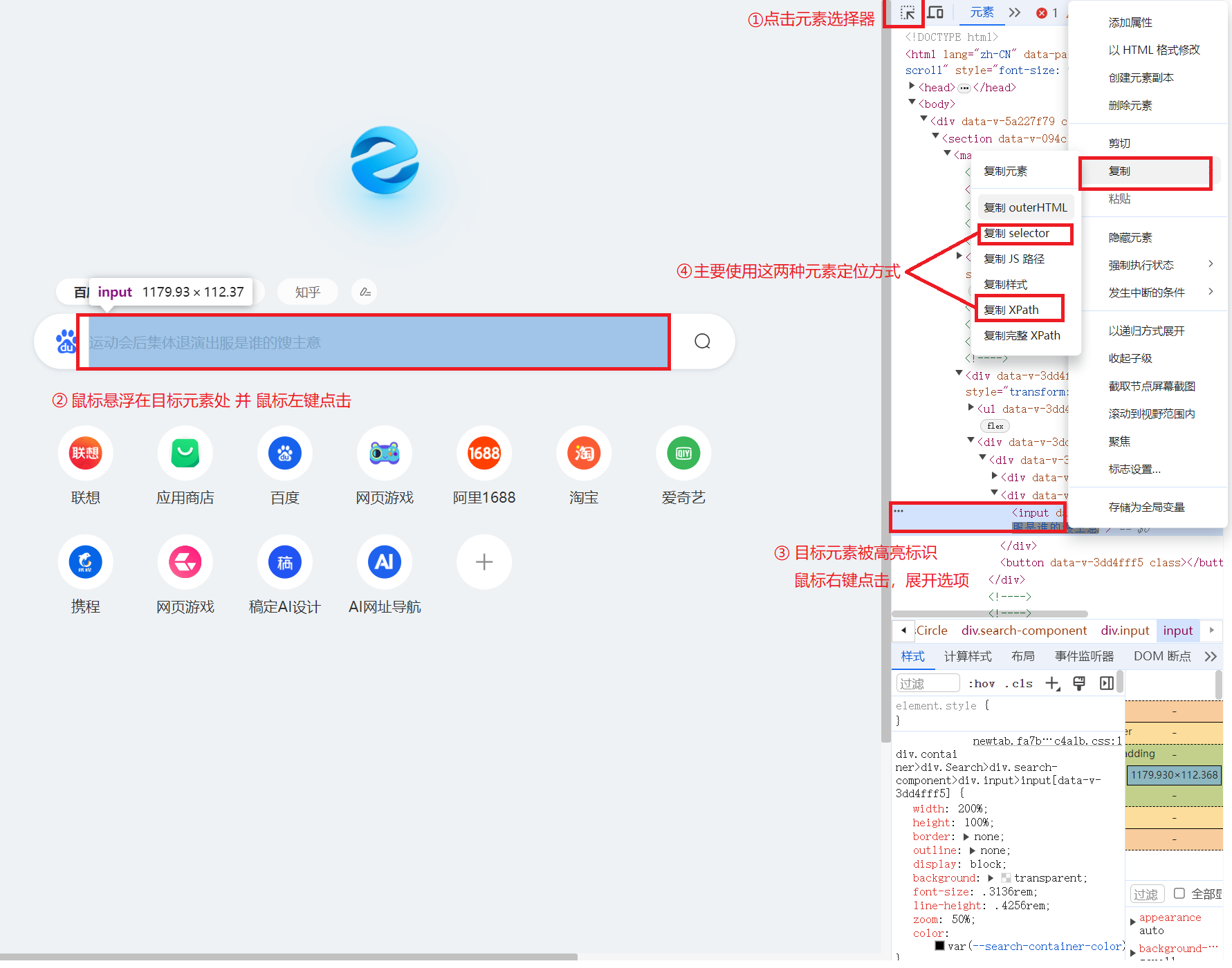
我们可以按下F12唤出开发者模式或者右键浏览器页面按下鼠标右键然后选择“检查”都可以进入到开发者模式,而后根据图2所示获取元素的位置信息即可。
三、测试对象的操作
3.1输入文本send_keys()
在元素定位的例子中,我们提到了向输入框中输入文本并且点击搜索按钮。这里的文本输入和按钮的点击操作就是我们对象操作的一部分,我们使用selenium工具来实现一下这两个动作。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
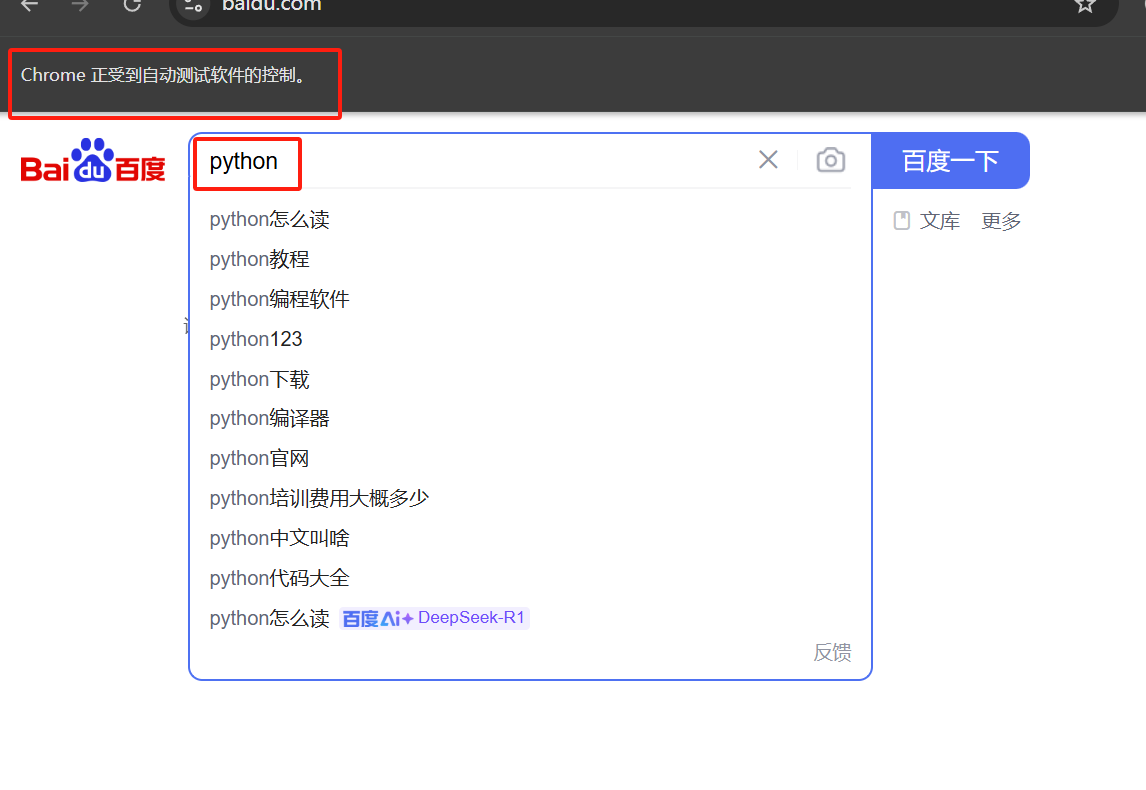
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到输入框并输入文本
time.sleep(2) #休眠两秒观察现象
driver.quit() #关闭浏览器这里简单解释一下上面给出的代码。因为我们的selenium工具主要面向的是Web页面的自动化测试工具,所以你需要先指定使用你电脑上的哪个浏览器来执行测试任务,而后你需要确定你要执行测试的网页,这两部都确定好了之后我们就可以先定位元素,然后执行对象操作即可。
由于运行过程是一个动态的过程,这里使用图片贴出来则比较麻烦,所以这里希望读者自己尝试一下。
这段代码运行起来整体的效果就是:打开谷歌浏览器-》向搜索框中输入“python”。等待两秒后浏览器退出。
3.2按钮点击click()
当我们向搜索框中输入文本后我们需要点击“百度一下”按钮来进行搜索操作,还是一样想要执行点击操作,就必须要找到指定的按钮元素。找到按钮元素之后触发点击操作即可。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到输入框并输入文本
time.sleep(2) #休眠两秒观察现象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按钮元素并执行点击操作
driver.maximize_window()
time.sleep(4) #休眠观察现象
driver.quit() #关闭浏览器
3.3清除文本clear()
上面的例子中,我们只执行一次搜索测试时,似乎并没有什么问题,但是如果我们需要进行多次关键词搜索的时候应该如何编写代码呢?是下面这种方式吗?
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
#第一次搜索测试
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到输入框并输入文本
time.sleep(2) #休眠两秒观察现象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按钮元素并执行点击操作
time.sleep(2)
#第二次搜索测试
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("C++好学吗?") #找到输入框并输入文本
time.sleep(2) #休眠两秒观察现象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按钮元素并执行点击操作
time.sleep(2)
driver.maximize_window()
time.sleep(4) #休眠观察现象
driver.quit() #关闭浏览器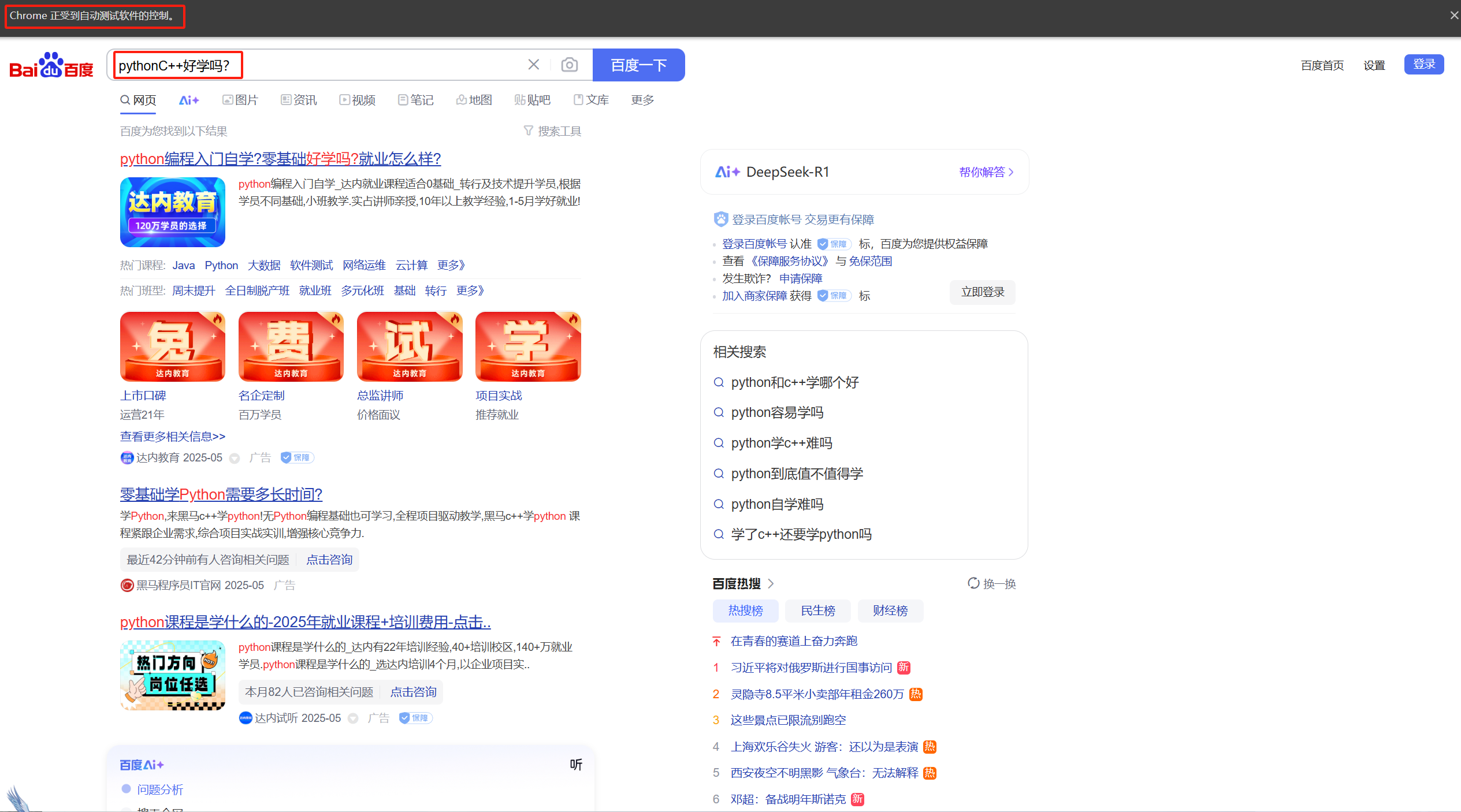
我们可以发现上面代码的写法,会导致我们的搜索文本发生混叠进而导致搜索不准确的问题,为了解决这种问题,我们应该在每一次搜索文本之后将搜索框中的文本进行清空而后在输入新的文本,就像这样。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
#第一次搜索测试
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到输入框并输入文本
time.sleep(2) #休眠两秒观察现象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按钮元素并执行点击操作
time.sleep(2)
#第二次搜索测试
driver.find_element(By.CSS_SELECTOR,"#kw").clear() #输入新的文本前,先对文本进行清空
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("C++好学吗?") #找到输入框并输入文本
time.sleep(2) #休眠两秒观察现象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按钮元素并执行点击操作
time.sleep(2)
driver.maximize_window()
time.sleep(4) #休眠观察现象
driver.quit() #关闭浏览器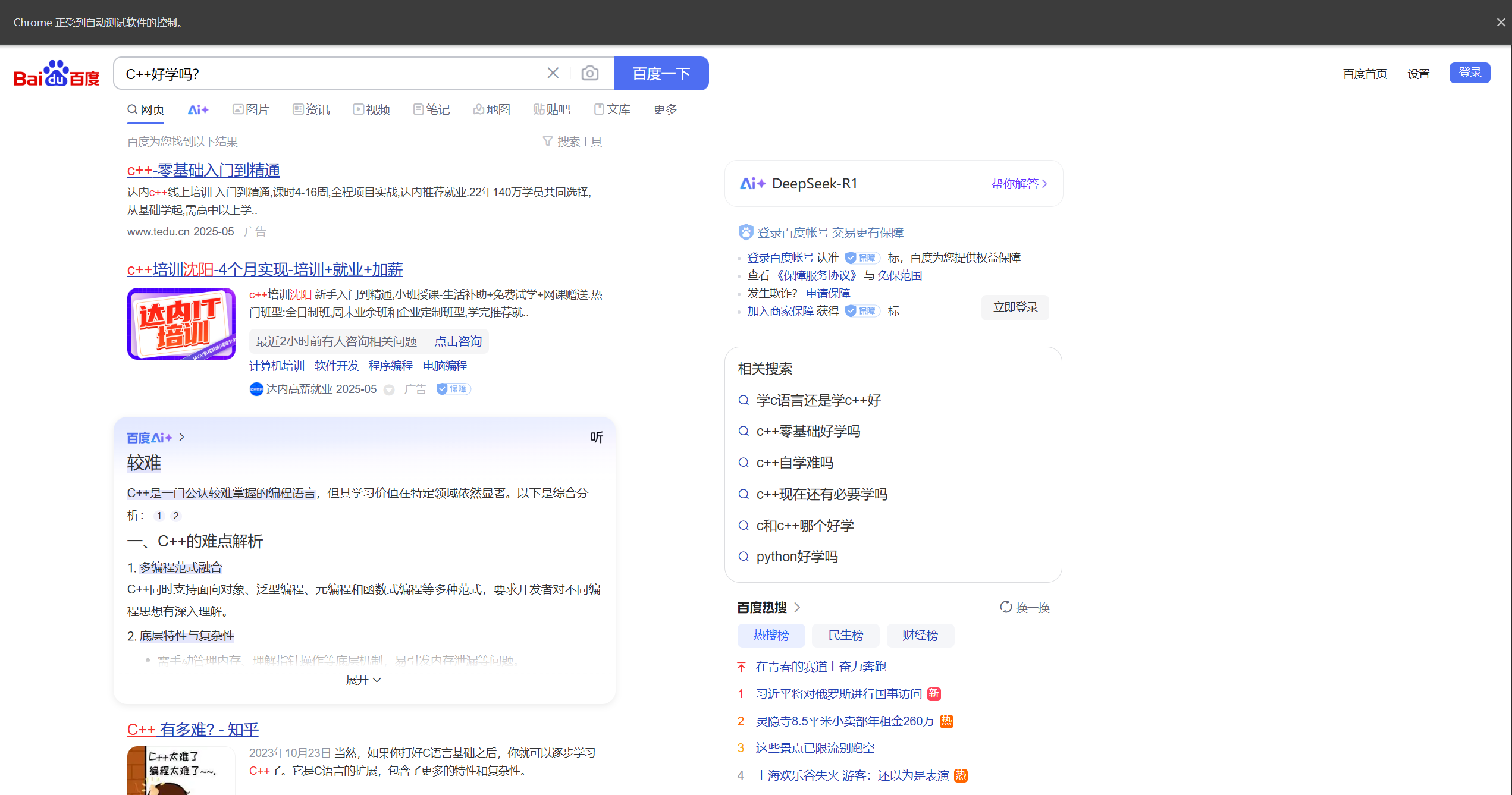
3.4获取文本信息text
如果你在测试工作过程中需要获取元素所包含的文本可以按照如下的方式来获取元素的文本信息。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
text=driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(2) > a > span.title-content-title").text
print(text)
driver.quit()
如果我们现在想获取“百度一下”按钮的文本呢信息,我们应该怎么获取呢?是下面这种写法吗?
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
text=driver.find_element(By.CSS_SELECTOR,"#su").text
print(text)
driver.quit()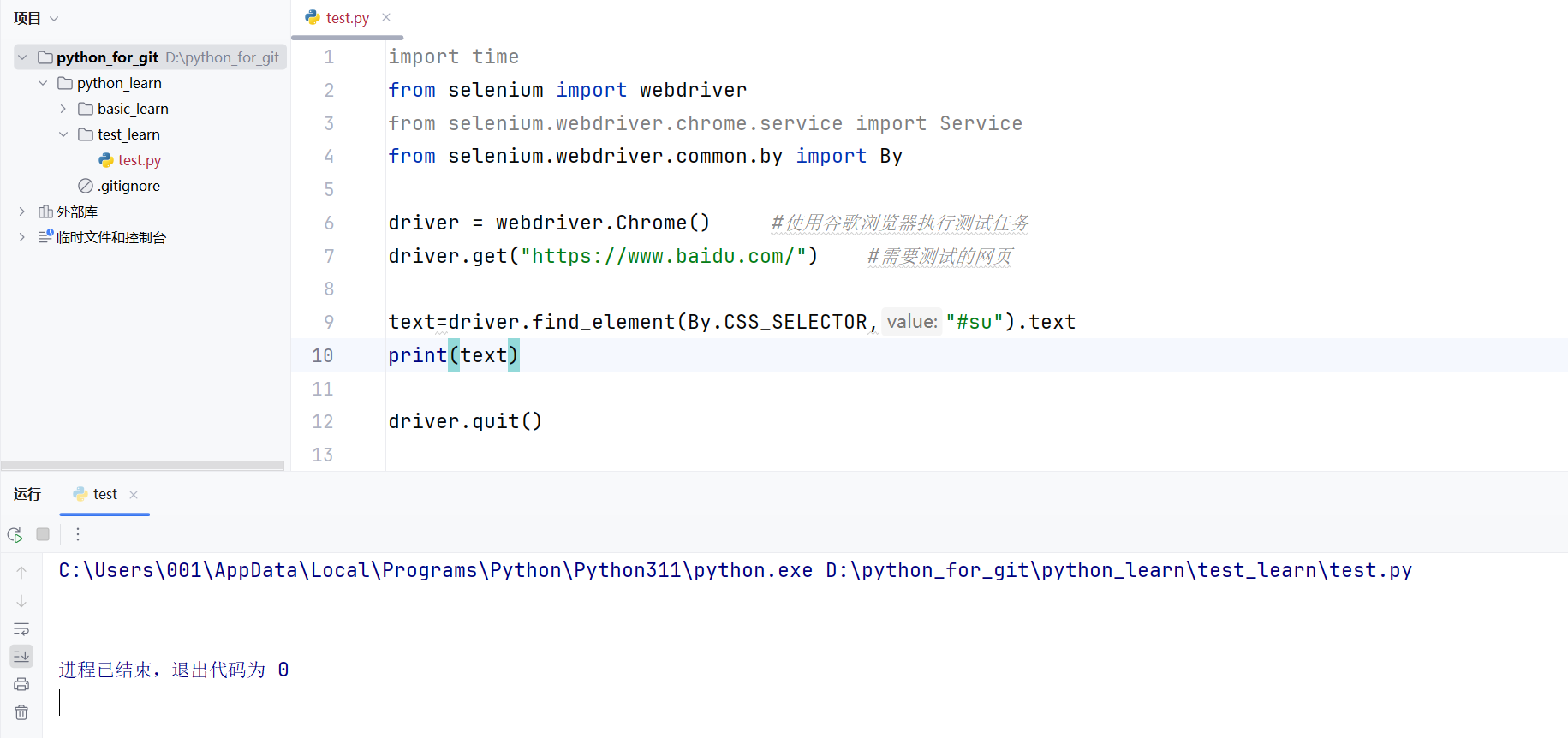
从图8的结果中我们不难看出,最后程序的输出中并没有对应的文本信息,这是因为“百度一下”按钮的文本信息存储在属性值value中,我们也可以html标签初见端倪。
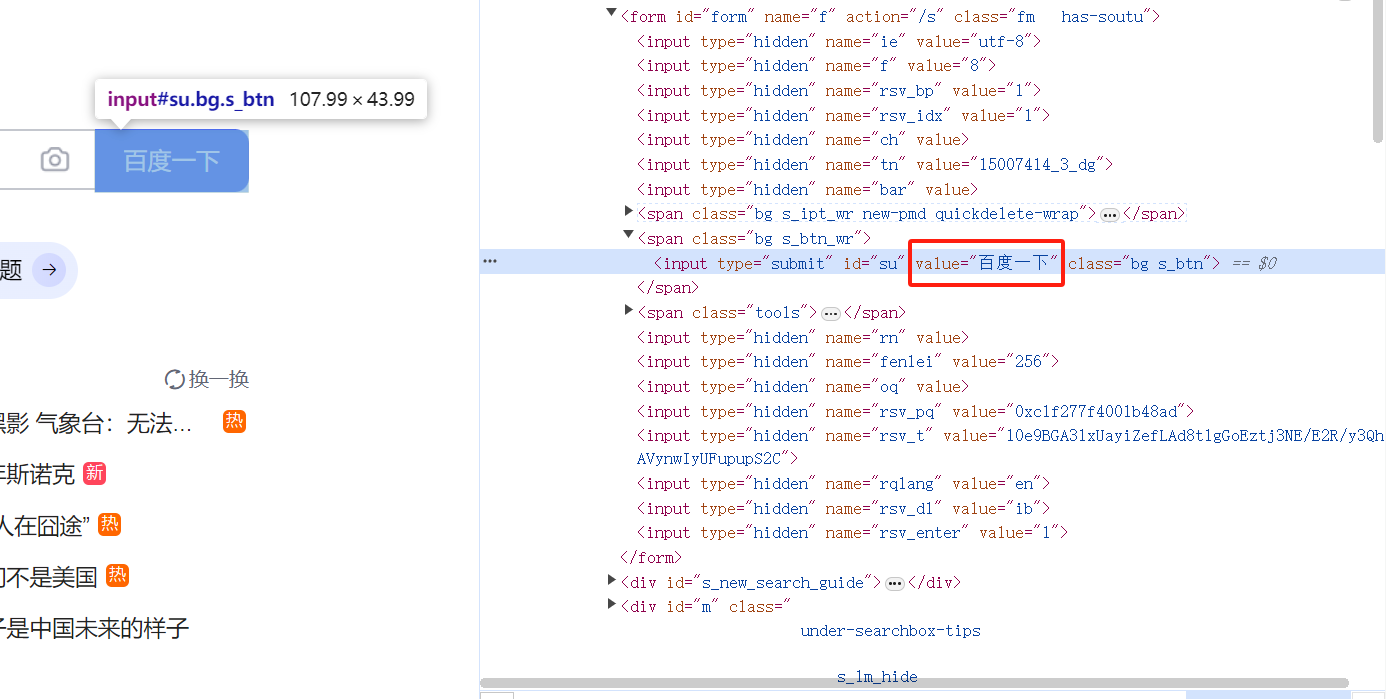
所以要获取这类元素的“文本”,我们就需要使用get_attribute()方法来进行获取。
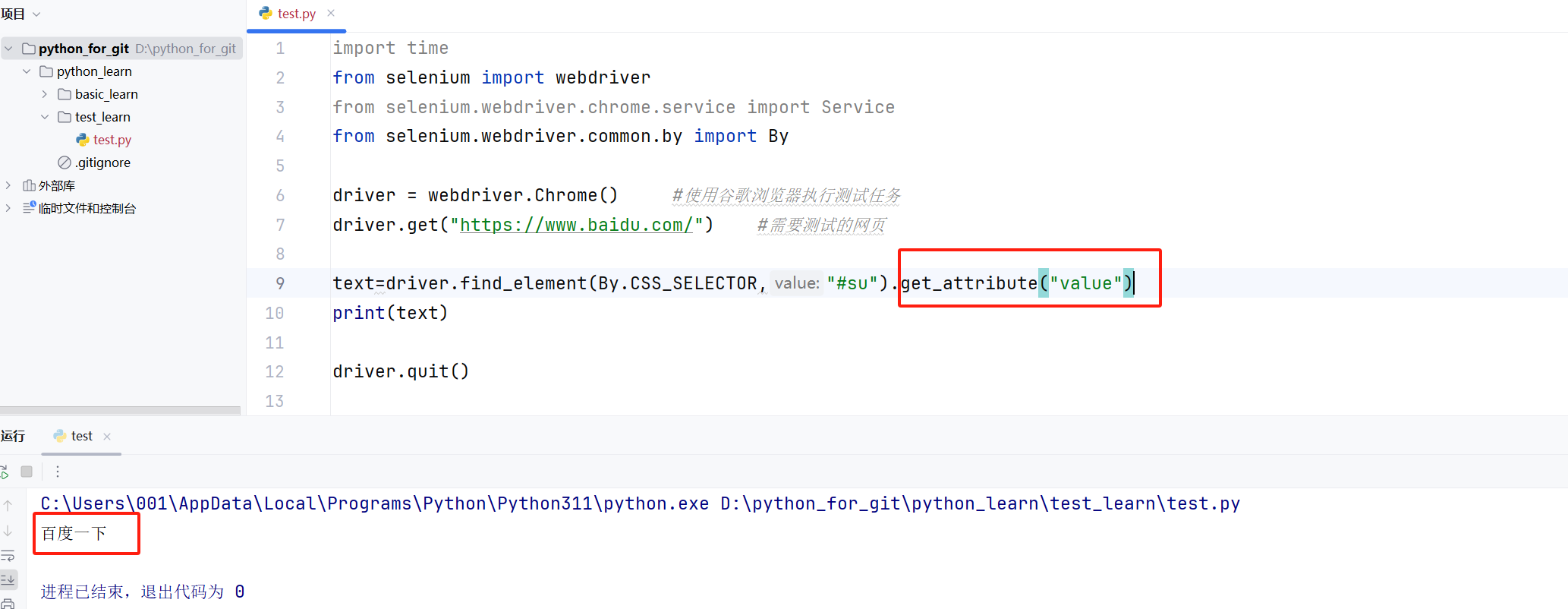
3.5获取页面的title与URL
页面的title信息和URL信息更多的时候是帮助我们判断页面的跳转是否正确,比如我在搜索页面点击了一个今天的热搜,这个热搜的地址与我们设置好的地址是不是相对应的,这个时候就可以通过这两个接口加断言就可以实现。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
#先获取一下按钮点击之前的URL和title信息
title = driver.title
url = driver.current_url
print("切换前:")
print("title: "+title+' ')
print("URL: "+url+'\n')
#查找对应的热搜并点击
driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(2) > a > span.title-content-title").click()
#因为我们的driver定位的是一个页面,页面切换了,driver也得切换
cur_page = driver.current_window_handle #获取当前页
all_pages = driver.window_handles #获取所有页
for handle in all_pages:
if(handle != cur_page): #因为一共两个页面,不是当前页就是新开页
driver.switch_to.window(handle)
title = driver.title #获取一下切换后的title
url = driver.current_url #获取一下切换后的URL
print("切换后:")
print("title: "+title+' ')
print("URL: "+url+'\n')
driver.quit()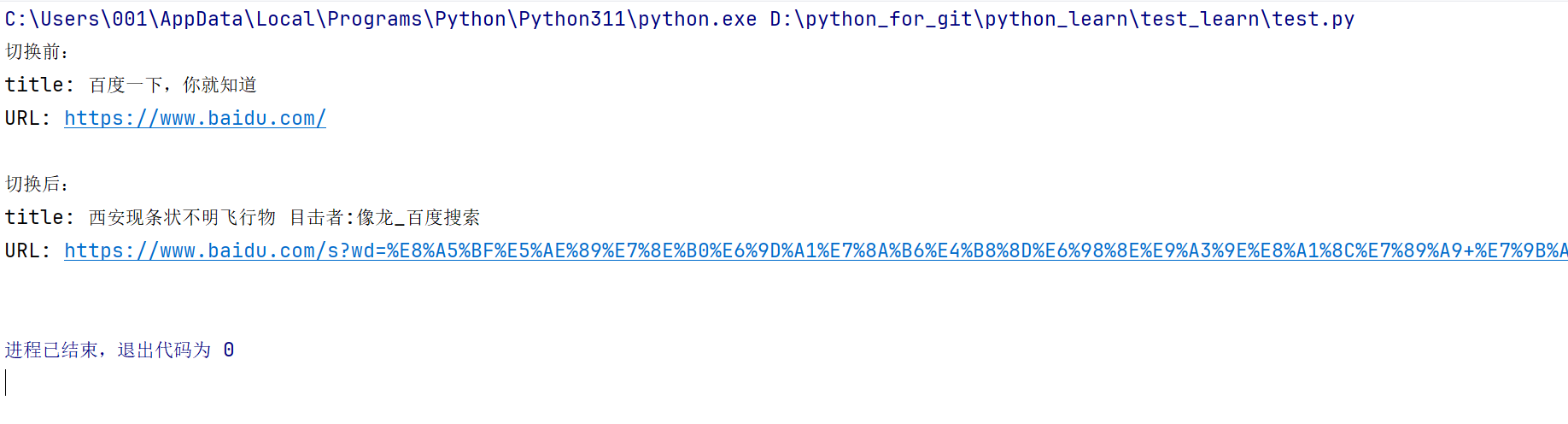
至于当有多个窗口的时候,怎么才能确定我要切换到哪个窗口的问题,我想大家暂时不用担心,一来在实际测试工作中很少会出现多个页面同时存在的情况,二来,即使真出现了这种情况我们只需要在新开页之前,就获取一下现有的页面记存储页面的数组为A,在新开页之后获取一下现有的页面记存储页面的数组为B,对比A、B两个数组的差异不就可以确定新开页是哪个页了吗?
甚至,如果你愿意,你也可以将这些页与特定的标识相绑定,然后在你想操作特定页的时候遍历你的映射表去除你想操作的页后直接切换即可。当然还是那句话,这样的场景很少见,这里只是提出一些解决问题的方案。
四、窗口
其实有关窗口的知识,我们已经在前面有所铺垫:比如我们之前所说的页面切换,实际上就是窗口的切换,页面是一个窗口,也是一个可以切换的对象。这里我们在说一下有关窗口的知识与操作。
4.1窗口的切换switch_to.window()
如3.5所讲解的例子,在进行窗口的切换时,需要使用switch类,如果你想要切换到窗口就需要使用switch下的window方法。需要注意的是传递给该方法的参数必须是一个handle句柄对象就类似于我们的窗口对象。
driver.switch_to.window(handle)我们也可以通过一些方法获取当前浏览器下已经存在的窗口和当前处于哪个窗口下。
cur_page = driver.current_window_handle #获取当前窗口
all_pages = driver.window_handles #获取所有窗口另外,建议当存在多个页面的时候,如果你不使用当前页,在关闭这个页之后,你最好切换到一个不会被关闭的页保证操作页的可预见性。即便是只有两个页面,如果你想操控那个未被关闭的页面也需要进行窗口的切换。
4.2窗口大小设置
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
driver.minimize_window() #将窗口最小化
time.sleep(2)
driver.maximize_window() #将窗口最大化
time.sleep(2)
driver.fullscreen_window() #将窗口全屏
time.sleep(2)
driver.set_window_size(1024, 768) #手动设置窗口大小
time.sleep(2)
driver.close()有关窗口的大小变换这里就不过多介绍了,读者可以将这段运行这段代码,看看实际的演示效果。
4.3屏幕截图save_screenshot()
这个功能主要是给我测试的人来看的,一种使用场景是在容易出错的或已经出错的地方加上这样的屏幕截图供测试人员介入后快速的定位问题,有点像调试功能或者说是测试工作中的“红黑表笔”。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
driver.save_screenshot("./screenshots/baidu.png")
time.sleep(2)
driver.close()屏幕截图的方式还是比较简单的,只需要指定保存截图文件的路径即可。但是实际测试工作中必然有大量的截图到来,这个时候我们就不能将图片的名字设置为一个固定值,所以我们可以在这个图片名字的前面或后面加上一个唯一的前缀或后缀,这里我就演示一下增加一个前缀。
import time
import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #使用谷歌浏览器执行测试任务
driver.get("https://www.baidu.com/") #需要测试的网页
dirctory = "./screenshots/"
filename = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S_")
picture_name = "baidu"
farmat = ".png"
driver.save_screenshot(dirctory+filename+picture_name+farmat)
time.sleep(2)
driver.close()当然,这不是严格意义上的唯一,因为在同一秒中截图就会出现覆盖的情况导致先生成的图片被覆盖,所以你也可以使用uuid生成器生成一个uuid,uuid在正常情况下可以说是一个绝对唯一的值了,你当然也可以使用uuid。
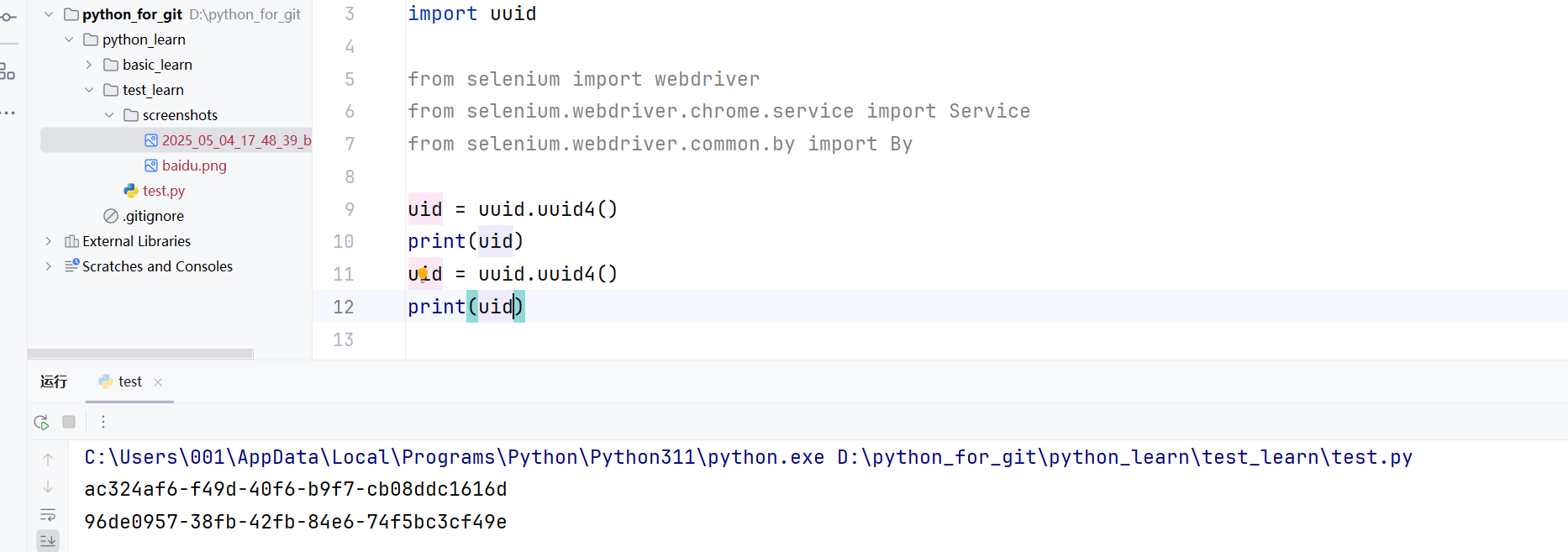
当然,这种方式有点杀鸡用牛刀的感觉~
4.4 关闭窗口close()
当你使用完窗口之后应该将其关闭,就像你在C语言中malloc空间后需要将其free掉是一个道理。这里就不进行代码演示了,因为在本文的例子中或多或少都有所体现,但是这里要说明一下close()与quit()的区别
driver.close()
driver.quit()close是关闭窗口,当存在多个页面的时候,其只会关闭一个页面,如果还有其它页面浏览器不会退出,但是quit是指关闭浏览器,也就是说无论有多少个页面都会立即被关闭并且浏览器会直接退出。
五、弹窗
如图13所示的就是一个弹窗,如果你不消除这个弹窗就无法进行下一步操作,所以我们如何定位这个弹窗,并且将其关闭呢?
需要说明的是,弹窗也是一个窗口,这就意味着我们需要先切换到该窗口上,才能够对该窗口上的元素进行操作,此外,我们使用开发者模式是没有办法定位到这个弹窗的,这是因为弹窗和我们的页面是两个窗口,开发者模式只能定位到页面这个窗口上的元素,弹窗不在页面上,所以自然也就无法使用元素选择器选中。
但是,无论你是什么窗口,总归还是会被浏览器的驱动所管理的,所以我们使用驱动可以管理这个弹窗的。
import time
import datetime
import uuid
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
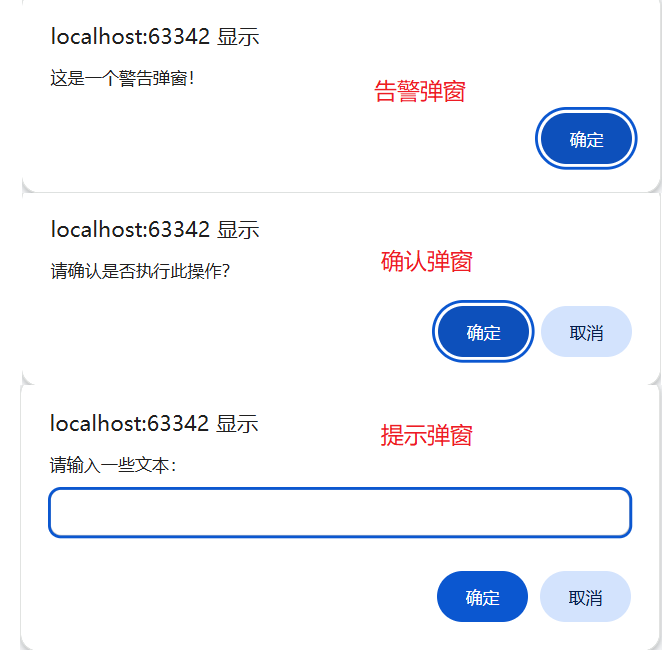
driver = webdriver.Chrome()
#这是警告弹窗
driver.get("http://localhost:63342/python_for_git/test_learn/alert.html?_ijt=7392b4jk49m4e4vre8ngsni9rr")
driver.find_element(By.CSS_SELECTOR,"body > button").click()
time.sleep(2)
alert = driver.switch_to.alert
time.sleep(2)
alert.accept()
time.sleep(2)
driver.close()
# #这是文本弹窗
# driver.get("http://localhost:63342/python_for_git/test_learn/text.html?_ijt=7392b4jk49m4e4vre8ngsni9rr")
# alert = driver.switch_to.alert
# alert.send_keys("你是一个文本弹窗")
# #确认/取消二选一
# alert.accept()
# alert.dismiss()
#
# #这是确认/取消选择弹窗
# driver.get("http://localhost:63342/python_for_git/test_learn/query.html?_ijt=7392b4jk49m4e4vre8ngsni9rr")
# #确认/取消二选一
# alert.accept()
# alert.dismiss()(这里由于弹窗并不是在每个页面都会存在,所以这里作者让AI生成了几个生成弹窗的html网页,如果感兴趣,可以查看本文绑定的资源。在使用时先将html网页运行在本地,然后将网址的地址拷贝到get()方法中,而后像获取网页元素一样定位我给出的网页中的按钮,定位后点击就会出现弹窗)
六、等待
讲解等待等待之前要清楚为什么要进行等待,关于这一点我相信你一定深有体会,当你在刷网站的时候,是不是有时会遇到一直卡在加载这一步,自己想要浏览的页面迟迟刷新不出来的场景。对于浏览器selenium来说也是如此,当我们使用selenium进行网页自动化测试的时候也是需要发送请求/接收响应的,这就意味着我们的网页也是需要渲染时间的,如果网页没有渲染完成就进行元素的查找,很有可能就会导致本应该存在的元素却没有被找到的问题,进而导致自动化程池执行失败的问题。而等待就是为了解决检测先于渲染之前的问题。
6.1强制等待
强制等待就是我们一直在用的等待。
time.sleep(2)这种等待,只有等待的时间到了才会继续向下执行,否则保持等待行为。
6.2隐式等待
隐式等待是一种“智能等待”,智能等待就是如果你请求查找的元素们在规定时间之内能找到就继续程序的执行,如果你请求查找的元素们在规定时间之内没有被找到,那么将会报错退出(不使用异常机制捕获)。
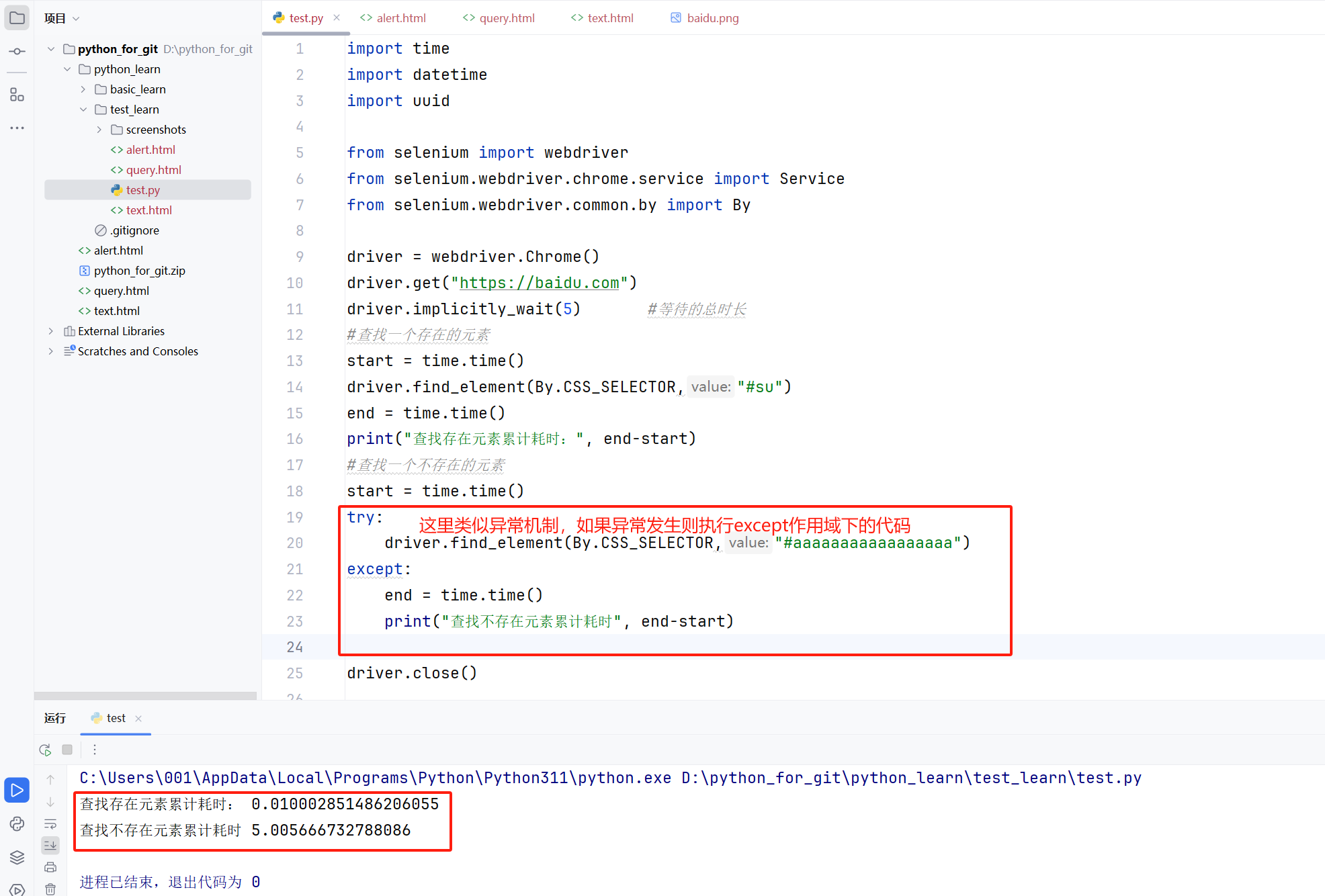
可以看到,智能等待不同于强制等待,智能等待作用于全局,这也就意味这你可以在程序的开始就定义等待的总时长且不会造成阻塞,这个时长是所有需要等待元素等待的时间之和。
import time
import datetime
import uuid
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://baidu.com")
driver.implicitly_wait(5) #等待的总时长
#查找一个存在的元素
start = time.time()
driver.find_element(By.CSS_SELECTOR,"#su")
end = time.time()
print("查找存在元素累计耗时:", end-start)
#查找一个不存在的元素
start = time.time()
try:
driver.find_element(By.CSS_SELECTOR,"#aaaaaaaaaaaaaaaaa")
except:
end = time.time()
print("查找不存在元素累计耗时", end-start)
driver.close()6.3显示等待
显示等待与隐式等待都属于智能等待,这意味着显示等待也是“设置一个等待总时长,如果成功等待继续执行,否则报错退出(不使用异常机制捕获)”。但是显示等待与隐式等待不同的是:显示等待增加了更多与校验有关的函数。
| 方法 | 说明 |
|---|---|
| title_is(title) | 检查标题是否是期望值 |
| title_contains(title) | 检查标题是否包含期望值 |
| visibility_of_element_located(locator,str]) | 检查目标元素的可见性与期望值 |
| presence_of_element_located(locator,str]) | 检查目标元素的可见性与期望值 |
| visibility_of(element) | 检查已知存在于页面DOM上的元素是否可见的期望 |
| alert_is_present() | 检查是否出现弹窗 |
关于visibility_of_element_located()与presence_of_element_located()的额外说明:
presence_of_element_located:该方法用于等待指定元素在 DOM(文档对象模型)中出现。也就是说,只要元素存在于 HTML 结构里,即便它在页面上不可见(比如被隐藏、未加载完全等),这个方法也会判定元素已找到。
当你只需要确认元素已经被加载到 DOM 中,而不关心它是否可见时,就可以使用这个方法。例如,在等待一个动态加载的元素开始加载时。
visibility_of_element_located:此方法用于等待指定元素在页面上可见。元素不仅要存在于 DOM 中,还得满足一定的可见性条件,例如元素的宽度和高度大于 0、不被隐藏(
display属性不为none,visibility属性不为hidden)等。当你需要确保元素不仅存在于 DOM 中,还能在页面上被用户看到时,就应该使用这个方法。例如,在进行页面交互之前,需要确保按钮、输入框等元素是可见的。
DOM (Document Object Model)将文档解析为一个由节点和对象(包含属性和方法)组成的结构集合。简单来说,它把网页文档转换为一个树形结构,其中每个部分(如元素、属性、文本等)都可以被看作是树中的一个节点,开发者可以通过编程的方式对这些节点进行访问、修改、删除或添加等操作。
这里就不对显示等待做演示了,智能等待的场景性比较强,读者遇到了需要根据情况自行定夺。此外,需要说明的是:显示等待与隐式等待不能混合使用!这样做会导致意料之外的问题。
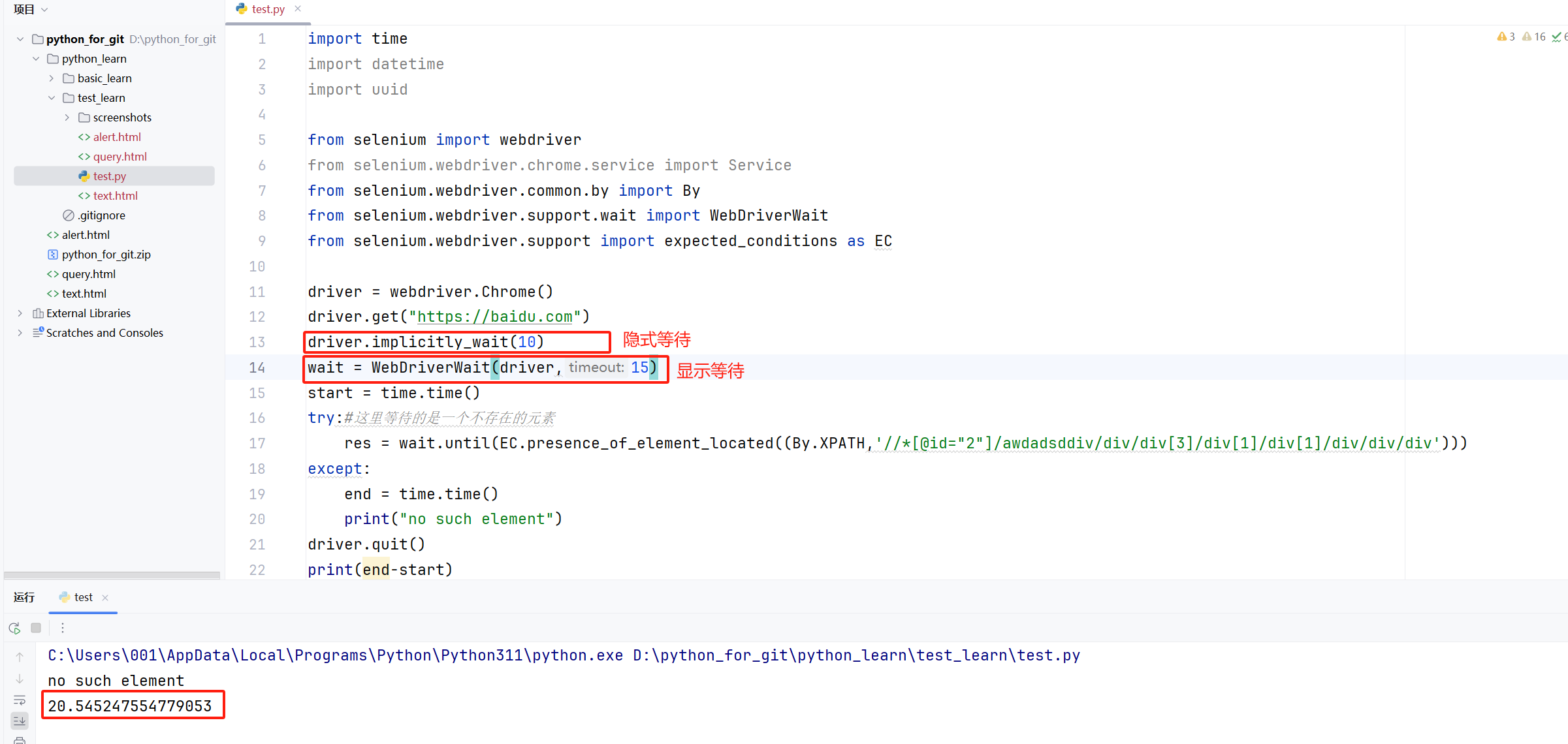
import time
import datetime
import uuid
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://baidu.com")
driver.implicitly_wait(10)
wait = WebDriverWait(driver,15)
start = time.time()
try:#这里等待的是一个不存在的元素
res = wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="2"]/awdadsddiv/div/div[3]/div[1]/div[1]/div/div/div')))
except:
end = time.time()
print("no such element")
driver.quit()
print(end-start)七、浏览器导航
这部分操作就比较常规了,主要是对浏览器导航栏中的内容进行操作,比如浏览器的刷新、前进、后退操作。这里就不粘贴结果了,感兴趣的读者可以自行运行查看结果。
import time
import datetime
import uuid
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://baidu.com")
driver.find_element(By.CSS_SELECTOR,"#su").click()
driver.refresh() #刷新操作
time.sleep(2)
driver.back() #后退操作
time.sleep(2)
driver.forward() #前进操作
time.sleep(2)八、文件上传
当我们需要上传一个文件到网页的时候,我们点击上传,就会弹出我们Windows的文件管理器让我们选择上传文件,文件管理器又不是浏览器的一部分,我们的selenium怎么测试呢?
这就其实也有办法,我们只需要将文件的路径作为参数传递给send_keys方法就可以将本地的文件上传。不过这也需要前端设计要进行配合否则也无法完成这个工作。(页面在绑定资源里)
import time
import datetime
import uuid
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("http://localhost:63342/python_for_git/test_learn/fileupload.html?_ijt=7mc670vp975dm5a1jdasgc0co2")
driver.find_element(By.CSS_SELECTOR,"#filePath").send_keys("C:/Users/001/Desktop/20241108191217.png")
time.sleep(2)
driver.find_element(By.CSS_SELECTOR,"body > button:nth-child(2)").click()
time.sleep(5)
driver.find_element(By.CSS_SELECTOR,"body > button:nth-child(3)").click()
time.sleep(5)
driver.close()九、浏览器参数设置
9.1无头模式
无头模式的主要目的是,想让我们的检测程序不发生将浏览器唤出的动作,即程序仍然正常执行,但是无需向我展示过程时,可以使用这个选项。这个选项开启后,你将不会看到浏览器被换出并执行你提前定义好的行为,但是这些行为确实被执行了,只不过你很难进行感知了。
你可以尝试“注释无头模式选项”和“不注释无头模式选项”对比差异。
import time
import datetime
import uuid
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
options = webdriver.ChromeOptions()
options.add_argument('--headless') #设置无头模式
driver = webdriver.Chrome(options=options)
driver.get("http://baidu.com")
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到输入框并输入文本
time.sleep(2) #休眠两秒观察现象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按钮元素并执行点击操作
time.sleep(2)9.2浏览器加载策略
这里主要讲解三种浏览器加载内容的模式,实际上与等待也有着一定的影响~~
| 策略 | 说明 |
|---|---|
| normal | 默认选项,表示等待每一个资源加载 |
| eager | 省略加载,开始检测的时,DOM加载完毕,但可能存在较大的资源未加载完毕。 |
| none | 不对任何资源进行等待,不会被任何事务阻塞 |
下面主要说一下这几种策略对等待时间的影响:
1. normal 加载策略
- 原理:
normal是默认的加载策略,它会等待页面上的所有资源(包括 HTML、CSS、JavaScript、图片等)都加载完成后,才会认为页面加载完毕。这意味着浏览器会等待每一个资源加载,直到onload事件触发。 - 对等待时间的影响:这种策略会消耗隐式等待和显示等待的时间。因为在页面资源加载过程中,Selenium 会持续等待,直到页面完全加载。如果页面上有大量的资源需要加载,等待时间可能会很长,从而导致隐式等待或显示等待超时。例如,若页面上有一个大尺寸的图片加载缓慢,在
normal策略下,Selenium 会一直等待该图片加载完成,期间可能会消耗掉隐式等待或显示等待设置的时间。
2. eager 加载策略
- 原理:
eager策略会省略一些资源的加载等待,当 DOM 加载完毕(即DOMContentLoaded事件触发)时,就认为页面加载完成,而不等待所有的资源(如图片等大资源)加载完成。 - 对等待时间的影响:相比
normal策略,eager策略通常会减少等待时间。因为它不需要等待所有资源加载,只要 DOM 准备好就可以开始后续操作。不过,它仍然可能消耗隐式等待和显示等待的时间。例如,如果在 DOM 加载完成后,某些元素的动态内容还需要通过 JavaScript 进一步加载,而你使用了显示等待来等待这些元素满足特定条件,那么在这个过程中就会消耗等待时间。
3. none 加载策略
- 原理:
none策略不对任何资源进行等待,浏览器不会被任何事务阻塞,在开始执行后续操作时,页面可能还在加载中。 - 对等待时间的影响:
none策略一般不会消耗隐式等待和显示等待的时间用于页面加载。因为它不会等待页面资源加载完成,而是立即开始执行后续的代码。但是,如果你在后续代码中使用了隐式等待或显示等待来等待特定元素或条件,那么等待时间将取决于这些元素或条件的实际情况,而不是页面加载的情况。例如,你使用显示等待来等待一个元素可见,即使页面还在加载中,Selenium 也会在指定的时间内尝试查找该元素,直到满足条件或超时。
我们之前讲到在某些情况下不建议混用 “显式等待” 与 “隐式等待”,原因在于可能会出现等待时间不确定的问题。当隐式等待和显式等待都在等待同一个内容的加载时,即出现 “交叉” 情况,两者都会对等待时间产生影响,但其具体的时间消耗并非简单的相加,可能会因多种因素而变得复杂,从而导致最终等待时间难以准确预估。而当隐式等待和显式等待的内容相互独立,也就是 “无关” 的情况时,它们各自按照自己的规则消耗等待时间,这也会使得整个等待过程的总时间变得不确定,增加了测试用例执行时间的不可控性。
这里我们在展示一下如何对加载策略进行设置。
import uuid
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
options = webdriver.ChromeOptions()
options.page_load_strategy = 'eager'
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(4)
begin = time.time()
driver.get("https://www.bilibili.com/")
driver.find_element(By.CSS_SELECTOR,"#nav-searchform > div.nav-search-content > input").send_keys("python") #找到输入框并输入文本
time.sleep(2) #休眠两秒观察现象
driver.find_element(By.CSS_SELECTOR,"#nav-searchform > div.nav-search-btn").click() #找到按钮元素并执行点击操作
time.sleep(2)
end_time = time.time()
print(end_time - begin)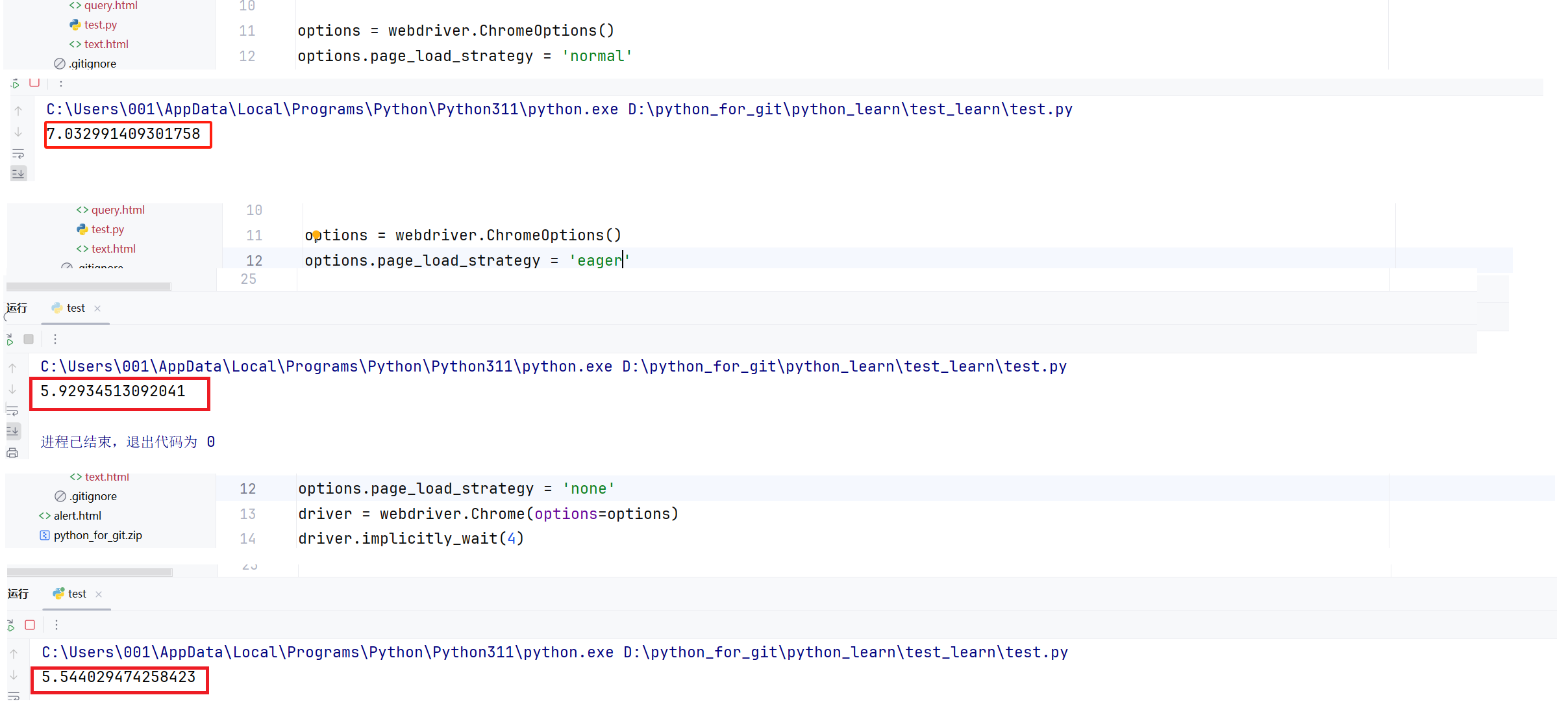
这里的有关时间的测试,实际上相当不严谨,一方面受限于网络状况与网络波动,另一方面受限于本地内存资源等,这里正常应该多次实验取平均值,来进行验证,但是这里作者就不这么严谨了,如果你自己去进行数学统计来得出一个更严谨的结论。
这里作者测试的时间是,打开B站,在搜索框中搜素“python”并进行搜索的整体时间。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











