







本人大二下学期报了中国大学生计算机设计大赛、珠澳计算机设计大赛、区块链软件设计大赛、蓝桥杯......然后一直准备着设计大赛的比赛,根本没空管蓝桥杯,就省考前准备了一星期,感觉是没有希望了,但是很莫名其妙的就拿了蓝桥杯JavaB组省一......然后接着国赛准备期间还是再搞别的,现在是2024/05/19日,我今天第一天开始重新学算法,将记录一下我的做题笔记,看看能不能记录到6月1号国赛。
然后我也是真的捞,算法也忘得差不多了,这里重新跟着一些简单的题开始,各位看官别喷......真忘光了,重头开始吧......
一、剑指 Offer II 088. 爬楼梯的最少成本(小儿智障题)
来自力扣的一道经典题目:
一个数组cost的所有数字都是正数,它的第i个数字表示在一个楼梯的第i级台阶往上爬的成本
在支付了成本cost[i]之后可以从第i级台阶往上爬1级或2级。
假设台阶至少有2级,既可以从第0级台阶出发,也可以从第1级台阶出发,请计算爬上该楼梯的最少成本。
示例 1:
输入:[10, 15, 20]
输出:15
解释:最低花费是从 cost[1] 开始,然后爬2级即可到阶梯顶,一共花费 15 。
示例 2:
输入:[1, 100, 1, 1, 1, 100, 1, 1, 100, 1]
输出:6
解释:最低花费方式是从 cost[0] 开始,爬2级跳过cost[1],然后逐个经过那些 1 ,跳过 cost[3] 跟cost[5]跟cost[8],一共花费 6 。
那么我们的思路是要有两个数组:
f[i]:f[i]数组用来记录到达【当前这个阶梯之前所要花费的最少的钱】(也就是不包含当前这层阶梯的费用的最少费用)
cost[i]:cost[i]数组用来记录【每一层阶梯需要交多少钱】
每一层阶梯都要带着一个 f[i] 跟 cost[i],一个是在这之前最少花多少,一个是当前这一层该交多少
(不过我实际代码喜欢用集合,到时代码里我会用集合代替数组)
然后怎么获得【f[i]:所要花费最少的钱】呢?
我们到达每一层阶梯之后,比较【前1层阶梯总共所花费的最少费用】和【前2层所花费的最少的费用】
每一层阶梯总共要花费的最少费用 = 【当前这个阶梯之前所要花费的最少的钱】+【每一层阶梯需要交多少钱】= f[i] + cost[i]
所以:
【前1层阶梯总共所花费的最少费用】= f[i-1] + cost[i-1]
【前2层所花费的最少的费用】= f[i-2] + cost[i-2]
然后我们来看一些初始值,因为我们从第0层往阶梯上走,第1步可以选择第一层阶梯(数组第0位)或者第二层阶梯(数组第1位),这是可以确定的;然后再走这一步到达第1或第2层阶梯之前,我们并不需要花一分钱,所以f[0]、f[1]都是0元
我写的比较抽象,可能比较难以理解,这里我再用手画图来带各位理解(¥是表示钱)
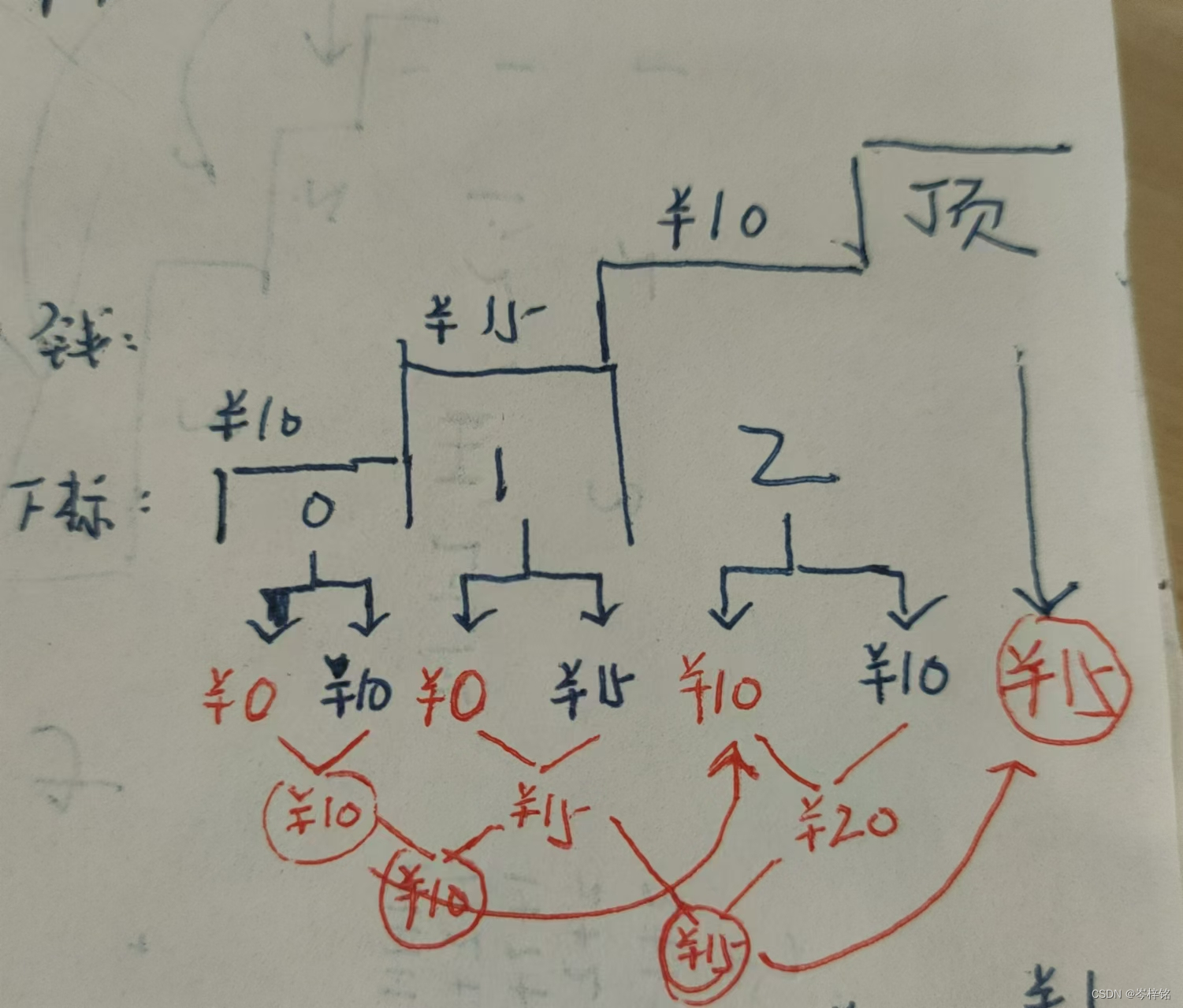
示例一:
输入:[10, 15, 20]
输出:15
示例二:
输入:[1, 100, 1, 1, 1, 100, 1, 1, 100, 1]
输出:6
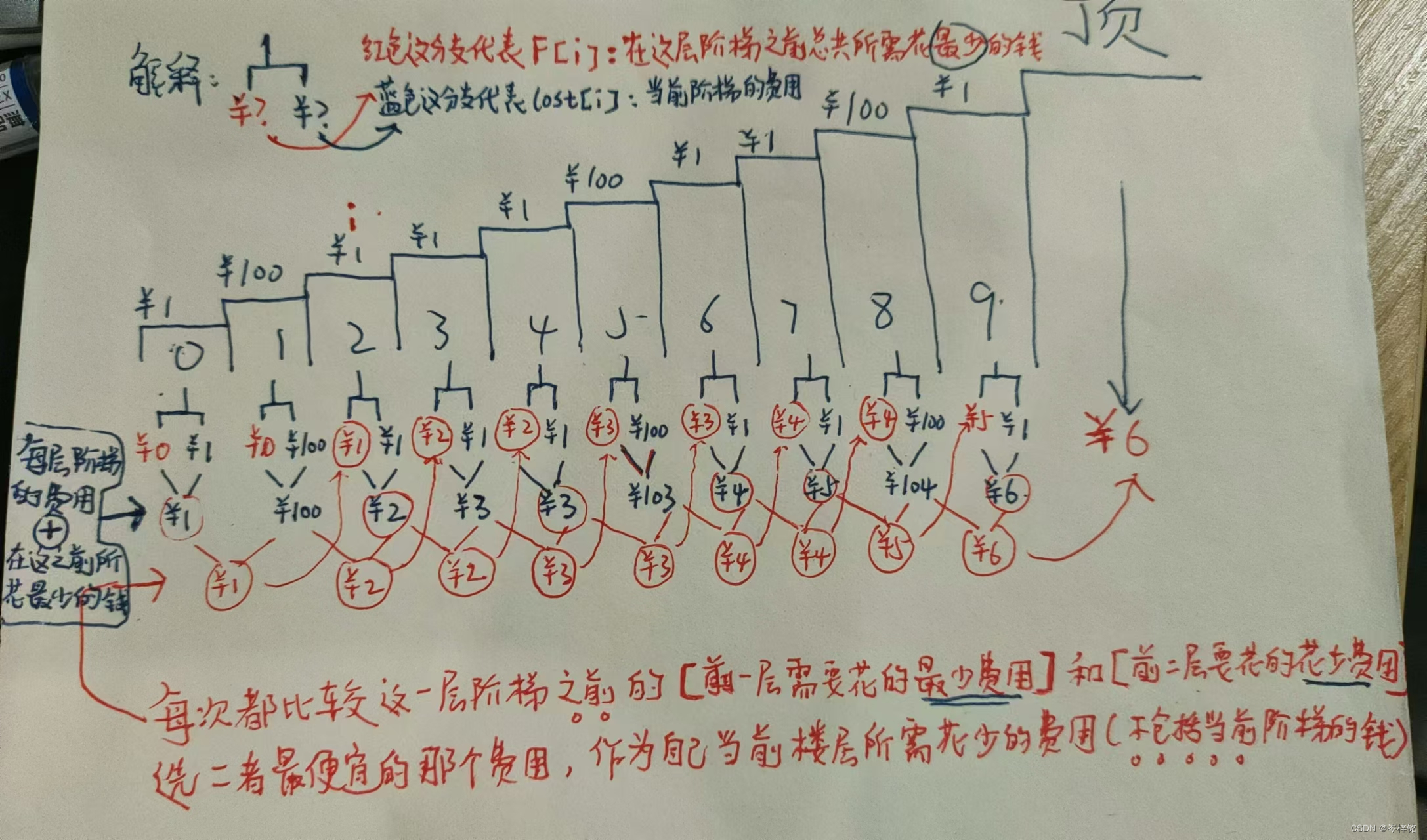
注意一点:在循环cost结束后,当遍历完最后一层阶梯之后,只会求得到达这一层阶梯【之前】的所需花最少的钱
所以还要再进行一次判断,再比较一次,在到顶之前,倒数第一层跟倒数第二层的费用谁最便宜,取最便宜的作为最后总共要花的钱
完整代码:(包括了输入,注释的那几块是输入部分,可以省略不看)
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class 爬楼梯最少花费 {
public static void main(String[] args){
//------------这一块不用管,这里是为了输入[1,2,3...]提取出数字用的-----------
Scanner in = new Scanner(System.in);
String s = in.nextLine();
Pattern pattern = Pattern.compile("\\d+"); // 匹配一个或多个数字
Matcher matcher = pattern.matcher(s);
//-----------------------------------------------------------------------
//我喜欢用集合来代替数组,因为我不知道总共要设这个数组多大
List<Integer> cost = new ArrayList<>(); //cost是当前阶梯的费用
List<Integer> f = new ArrayList<>(); //f是到当前阶梯之前最少要花多少(既不包含当前阶梯的费用)
//----------这也不用管,这就是把[1,2,3...]这里的数字装入cost集合----------
int n = 0;
while (matcher.find()) {
String number = matcher.group();
cost.add(Integer.parseInt(number));
n++;
}
//-----------------------------------------------------------------------
//开始逻辑运算
//注意判断大于两层阶梯、只有两层阶梯、小于两层阶梯的情况
if(n > 2){
f.add(0); //就等于f[0] = 0
f.add(0); //就等于f[1] = 0
for (int i = 2; i < cost.size(); i++) {
//因为我们要根据f[i-1]+cost[i-1]和f[i-2]+cost[i-2]来决定f[i]是多少
//而且f[0]、f[1]又是已经确定的,所以就直接从第2位开始遍历
Integer minF = Math.min( (f.get(i-1) + cost.get(i-1)) , (f.get(i-2) + cost.get(i-2)) );
//这里我检查发现,当遍历完最后一层阶梯之后,只会求得到达这一层阶梯【之前】的所需花最少的钱
//System.out.print(f.get(i-1)+" + "+cost.get(i-1)+" , "+f.get(i-2)+" + "+cost.get(i-2)+" ");
f.add(minF);
}
//所以这里结束循环之后我要再比较一次,在到顶之前,倒数第一层跟倒数第二层的费用谁最便宜,取最便宜的作为最后总共要花的钱
int index = f.size();
Integer minF = Math.min( (f.get(index-1) + cost.get(index-1)) , (f.get(index-2) + cost.get(index-2)) );
System.out.println(minF);
}else if(n == 2){
System.out.println( Math.min(cost.get(0), cost.get(1)) );
}else{
System.out.println(0);
}
}
}
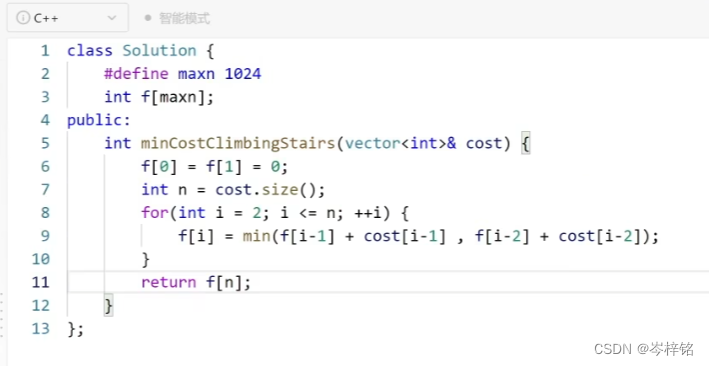
【力扣里C++的代码】
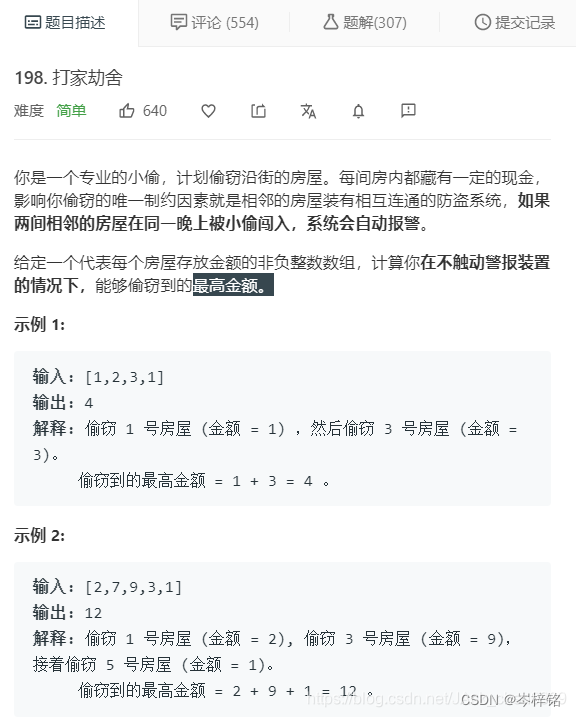
二、打家劫舍(小儿智障题)
完整代码:(包括了输入,注释的那几块是输入部分,可以省略不看)
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class 打家劫舍 {
public static void main(String[] args){
//------------这一块不用管,这里是为了输入[1,2,3...]提取出数字用的-----------
Scanner in = new Scanner(System.in);
String s = in.nextLine();
Pattern pattern = Pattern.compile("\\d+"); // 匹配一个或多个数字
Matcher matcher = pattern.matcher(s);
//-----------------------------------------------------------------------
//我喜欢用集合来代替数组,因为我不知道总共要设这个数组多大
List<Integer> money = new ArrayList<>(); //money是这个街区的每一个房子的钱
//因为不可以紧挨着两家偷钱,那就是说只能跳着偷,那就只有两种方法:跳着奇数房子偷、跳着偶数房子偷,那就用两个集合来装
List<Integer> getMony1 = new ArrayList<>(); //getMoney1是从第1家开始打劫所获得的钱
List<Integer> getMony2 = new ArrayList<>(); //getMoney2是从第2家开始打劫所获得的钱
//因为我想让这三个集合第0位是空的,也就是:
//money = [ 0 , ......]
//getMony1 = [ 0 , ......]
//getMony2 = [ 0 , ......]
//而且因为【getMony1[i]】【getMony2[i]】要根据前一位来获得,所以要确保【getMony1】【getMony2】这两个集合第0位要有数
//所以这里要先添加集合第0位为0
money.add(0);
getMony1.add(0);
getMony2.add(0);
//----------这也不用管,这就是把[1,2,3...]这里的数字装入money集合----------
while (matcher.find()) {
String number = matcher.group();
money.add(Integer.parseInt(number));
}
//--------------------------------------------------------------------
int index1 = 1; //遍历getMoney1的下标
int index2 = 1; //遍历getMoney2的下标
for (int i = 1; i < money.size(); i++) {
//奇数的房子
if(i % 2 != 0){
int m1 = getMony1.get(index1-1) + money.get(i); //这是前缀和,每次累加偷到的钱
index1++;
getMony1.add(m1);
//偶数的房子
}else{
int m2 = getMony2.get(index2-1) + money.get(i); //这是前缀和,每次累加偷到的钱
index2++;
getMony2.add(m2);
}
}
//最后比较【奇数房子的钱】和【偶数房子的钱】,谁多取谁
System.out.println(Math.max( getMony1.get(getMony1.size()-1) , getMony2.get(getMony2.size()-1) ));
}
}【力扣里C++的代码】
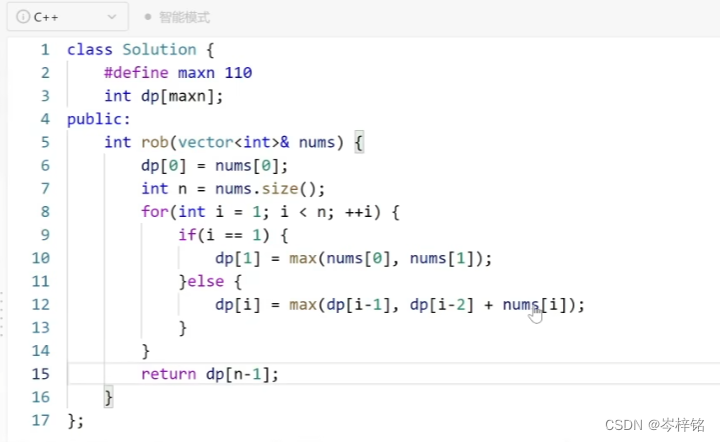
三、打家劫舍2.0
(没什么区别,也很简单,小儿智障题)

就是在原基础是,把房屋围起来,最后一间房子会跟第一间连起来,只要判断在最后打劫的房屋会不会跟第一间打劫的房屋是紧挨着就行了。
那么我翻译一下就是:总共有奇数个数的房屋,从第一间房屋打劫,最后到最后一间房子必然是跟第一间紧挨着的,只能从第二间房子开始打劫偶数房子;总共有偶数个数的房子,从第一间和从第二间开始都没问题,复制上一题的的代码就行。
也就是判断一下总有奇数个还是偶数个房子就行了
完整代码:(输入我就不复制了,只复制最后的判断跟循环,前面都一样的)
int index1 = 1; //遍历getMoney1的下标
int index2 = 1; //遍历getMoney2的下标
if ((money.size() - 1) % 2 == 0) {
for (int i = 1; i < money.size(); i++) {
//奇数的房子
if(i % 2 != 0){
int m1 = getMony1.get(index1-1) + money.get(i); //这是前缀和,每次累加偷到的钱
index1++;
getMony1.add(m1);
//偶数的房子
}else{
int m2 = getMony2.get(index2-1) + money.get(i); //这是前缀和,每次累加偷到的钱
index2++;
getMony2.add(m2);
}
}
//最后比较【奇数房子的钱】和【偶数房子的钱】,谁多取谁
System.out.println(Math.max( getMony1.get(getMony1.size()-1) , getMony2.get(getMony2.size()-1) ));
} else {
for (int i = 1; i < money.size(); i++) {
if(i % 2 == 0){
int m2 = getMony2.get(index2-1) + money.get(i); //这是前缀和,每次累加偷到的钱
index2++;
getMony2.add(m2);
}
}
System.out.println(getMony2.get(getMony2.size()-1));
}
四、分隔数组已得到最大和(中等难度)

思路:dp动态规划来解!
我们用 i 遍历数组,然后用这么两个思维理解:
1、这个【以0开头 ~ 到以i为结尾的数组】是原数组的【子数组】,然后再以这个【子数组】为基础, 再去进行多个“更小的、长度不超过k”的【子数组】的分割
(比如【1,2,3,4】是原数组,现在i遍历到第2位,【1,2,3】就是【子数组】,在这个基础是分割出【1】、【2】、【3】这三个“更小的、长度不超过k”的【子数组】)
2、或者你理解为【以0开头 ~ 到以i为结尾的数组】这就是“暂时的”一整个数组,以它为原数组再进行多个“长度不超过k”的小数组的分割;
(比如【1,2,3,4】是原数组,现在i遍历到第2位,直接当【1,2,3】就是一整个【新数组】,在这个基础是分割出【1】、【2】、【3】这三个【子数组】)
那么dp[ i ]就是代表:每一个【以0开头 ~ 到以i为结尾的数组】的最大和
注意:这个 “最大和” 是根据题意,假设以当前这个数组为整个数组,然后是分割多个小数组后可获得的最大数组和,而不是单单是此数组所有数之和
然后当 i 每次往后遍历的时候,就要以当前 i 为结尾,用 j 把这个【以0开头 ~ 到以i为结尾的数组】从后往前遍历,【以j开头 到 以i为结尾 的范围为分割出】的一个【子数组】,j 前面则是【之前已经分割好的各个可以凑成最大和】的【子数组】,也就是dp[ j-1 ]
比如:原数组【1,2,3,4】
当 i=3(Arrays[3] = 4) , j=2(Arrays[2] = 3)
那么【1,2】就是 dp[ j-1 ],也就是【 j 前面则是之前已经分割好的各个可以凑成最大和】的【子数组】
那么【3,4】就是 【以j开头 到 以i为结尾 的范围为分割出】的一个【子数组】
在这个遍历循环里,dp[ j ]的任务就是不断通过比较、更新,去分割这个【以0开头 ~ 到以i为结尾的数组】,最终获得当前dp[ i ]这个最大数组和
我们也可以得出一个公式:
设【以j开头 到 以i为结尾 的范围为分割出的一个】的【子数组】长度为length
设【以j开头 到 以i为结尾 的范围为分割出的一个】的【子数组】的最大值为max
当 j > 0时(length不超出k范围),dp[ i ] = dp[ j-i ] + length * max
当 j == 0时(length不超出k范围),dp[ i ] = length * max
然后因为不确定【0 ~ i】这个数组里怎么分才能凑出最大数组和,那就要不断比较、更新dp[ i ]
比如:
假设i=4时
j=4:dp[ 4 ] = [【dp[3]】+ 【max1】]
j=3:dp[ 4 ] = [【dp[2]】+ 【max2 + max2】]
j=2:dp[ 4 ] = [【dp[1]】+ 【max3 + max3 + max3】]
j=1:dp[ 4 ] = [【dp[0]】+ 【max4 + max4 + max4 + max4】]
j=0:dp[ 4 ] = 【max5 + max5 + max5 + max5 + max5】
然后还要实时根据 j 往后遍历,比较到底哪个dp[ 4 ]才是最大的,
因为我们不确定是什么情况dp[ 4 ]才是最大,
我们每一次 j 往前遍历的时候,都取上一次的dp[ i ]跟这一次的dp[ j-1 ] + length*max比较一下,谁大就取谁作为这次循环的dp[ i ],
然后这个dp[ i ]再拿去跟下一次循环的dp[ j-1 ] + length*max比较,直到最后更新出最大的dp[ i ]
配上哥的手绘图
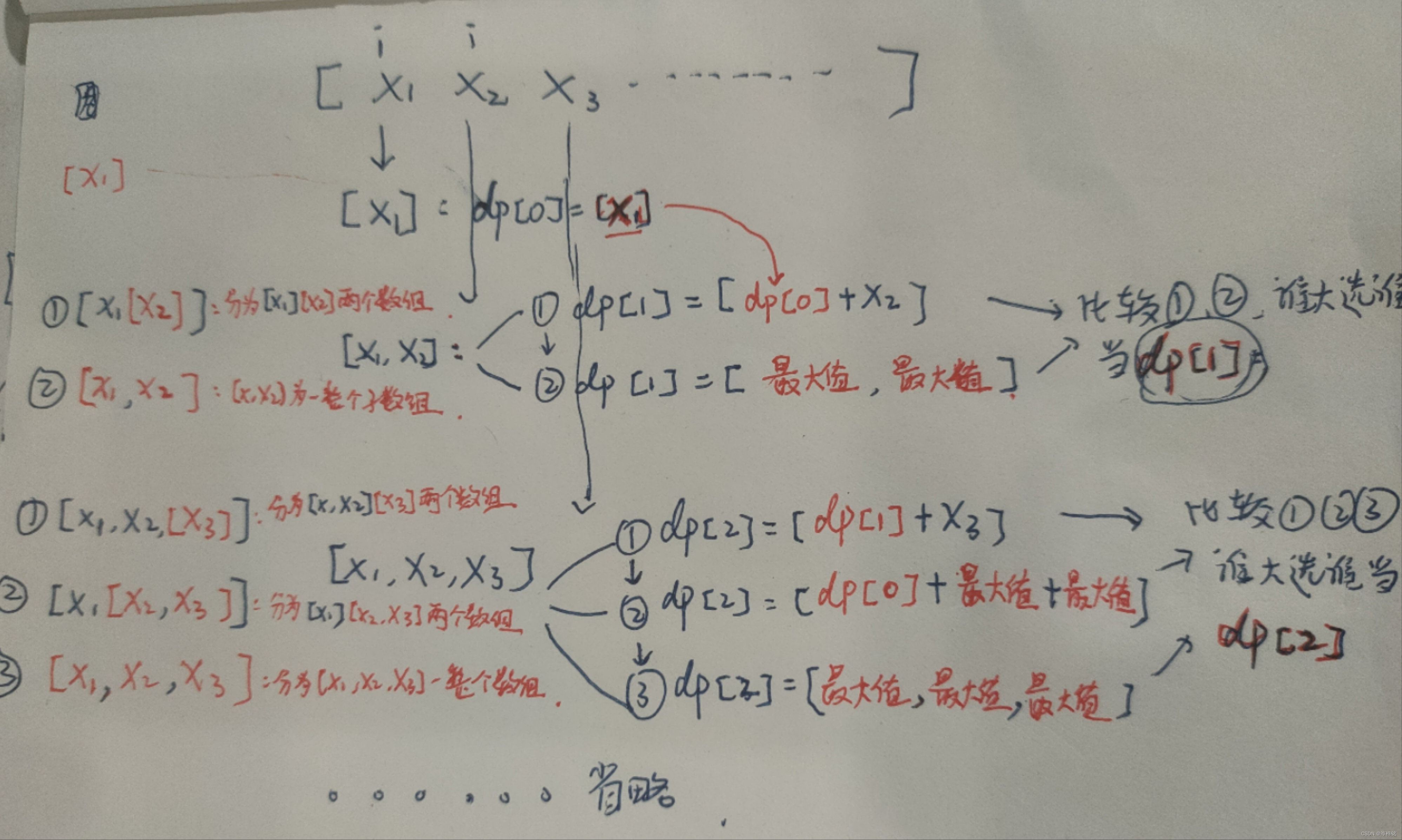

完整代码(省略了输入):
public static void main(String[] args){
//省略了输入部分,k就是规定的子数组长度,Arrays就是原数组,这里我用【集合】来存
List<Integer> dp = new ArrayList<>();
//依次往后遍历,直到遍历完整个数组
for (int i = 0; i < Arrays.size(); i++) {
//每次都更新、初始化max、length、“dp[i]”为0
int max = 0;
int length = 0;
dp.add(0); //等于dp[i] = 0;
//然后以当前i为结尾的这个数组,开始往后分割多个【长度不超过k】的小数组
for (int j = i; j >= 0; j--) {
//max要立刻更新,这样才能找到每个【被分割出来的子数组】的最大成员数
if( max < Arrays.get(j) ){
max = Arrays.get(j);
}
//实时统计可以被……分割理解为当前被分割数组有几个成员)
length++;
//记得控制每个【被分割子数组】的长度不能超过k
if(length > k){
break;
}
//然后最重要的部分
//简单来说就这么一个公式:dp[j] = dp[j-1] + length * max ——> [【dp[j-1]】,max,max......]
//但是随着i往后遍历,要考虑到一些特殊情况,会导致“加了后面的dp[i]”还不如“前面的dp[i-1]”大
//所以要一直随着i往后遍历,用j往前遍历,不停按照这个公式找“最大和”的情况
//当j > 0的时候,说明没有遍历完整个集合(数组)到头,也就是说那么此时j还没有遍历完数组
//就应该用这个公式:dp[j] = dp[j-1] + length * max ——> [【dp[j-1]】,max,max......]
if( j > 0 ){
//这里因为我用的是集合,集合不能像数组那样dp[i] = ...;所以只能这样,是一个意思的
int num = Math.max(dp.get(i) , dp.get(j-1)+length*max );
dp.set(i,num);
}else{
//而当j == 0的时候,说明j遍历完了整个数组,也既是从i到0这个范围的长度没有超过k
//那就说明:
//1、这整个数组就可以凑一整个【分割子数组】
// 那么一整个【分割子数组】最大的情况就是全都是最大值 ——> [max,max,max,max......]
//2、要么就是i刚到第0位
// j这时就在第0位,那么没有dp[-1],只能length * max (max就是第0位)
int num = Math.max(dp.get(i) , length*max );
dp.set(i,num);
}
}
}
System.out.println(dp.get(dp.size()-1));
}五、单词拆分拼接(说复杂也不复杂,简单了解)
说它简单是因为,逻辑原理让智障小儿来做都会,但是你要记得java里这些Api方法,以及怎么用
样例:String s = "123kkk%%"
1、s.indexOf("子字符串"):返回字符串s里包含第一个这个"子字符串"的第一个字符串的下标(没有这个"子字符串"就返回-1)
示例:s.indexOf("kkk") ——> 返回【3】,k在下标3
s.indexOf("fuck") ——> 返回【-1】,s里没有"fuck"这个子字符串
2、s.subString( 首下标 , 末下标 ):返回[ 首下标 ~ 末下标 ]范围的子字符串,并且要一个新的字符串变量接收,不能直接改变自己
3、想获得这个“子字符串”在整个字符串s里的首末位置,只需要先用【s.indexOf("字符串")】先求到【首位】,然后用这个【首位】+【这个“子字符串”长度】即可获得【末位】
4、然后整个字符串里,截取【头 ~ 这个"子字符串"首位"】和【这个"子字符串"末位 ~ 尾】,然后拼接起来,就是整个字符串s去掉这个"子字符串"
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class 单词拆分 {
public static void main(String[] args){
Scanner in = new Scanner(System.in);
//输入一整个字符串s
String s = in.nextLine();
//输入“单词字典”,格式是:[单词1,单词2,单词3......]
String str = in.nextLine();
//整个输入样例大概就是:
//xxx123Apple
//[xxx,123,Apple]
// 去除两端的方括号
str = str.substring(1, str.length() - 1);
// 使用逗号分割字符串,获取只包含单词的字符串数组,也就是【单词字典】
String[] wordDict = str.split(",");
while(true){
//如果字符串被更新为空字符串,就说明wordDict里的word能够拼出这个s,那就退出
if(s.isEmpty()){
break;
}
//用一个计数器统计,如果遍历完了wordDict都没有发现计数器变化,就说明wordDict没有符合单词,退出
int count = 0;
// 遍历分割后的数组
for (String word : wordDict) {
// 去除可能存在的空白字符
word = word.trim();
//首先找到这个【单词】在字符串s的第一个单词位置的第一个字符的下标、最后一个字符的下标
//比如"xxx123xxx",这里【xxx】这个单词在这个字符串第一个位置就是123前面,第一个字符的下标就是0、最后一个是2
int wordHead = s.indexOf(word);
//如果字符串s没有这个单词,那么indexOf就会返回-1
if(wordHead != -1){
int wordEnd = wordHead + word.length();
//然后截取字符串s里,开头到这个单词的第一个字符的部分,还有这个单词尾到字符串s结尾的部分
String head = s.substring( 0 , wordHead );
String tail = s.substring( wordEnd , s.length());
//最后更新这个字符串s,把除了这个单词以外的两部分拼接,也就相当于字符串s去掉了这个单词
s = head + tail;
//这个是用来检测去掉【word】部分之后的字符串s是否改变了
//System.out.println(s);
count++;
}
}
//当计数器统计完发现是0,说明wordDict里已经没有可以拼字符串s的单词了,那就退出
if(count == 0){
break;
}
}
//最后看这个字符串s是否是空字符串,如果是就说明wordDict的单词可以拼成字符串s;否则就不行
if(s.isEmpty()){
System.out.println("true");
}else{
System.out.println("false");
}
}
}
【力扣c++解法,有点麻烦我懒得研究了,反正java方便哈哈】
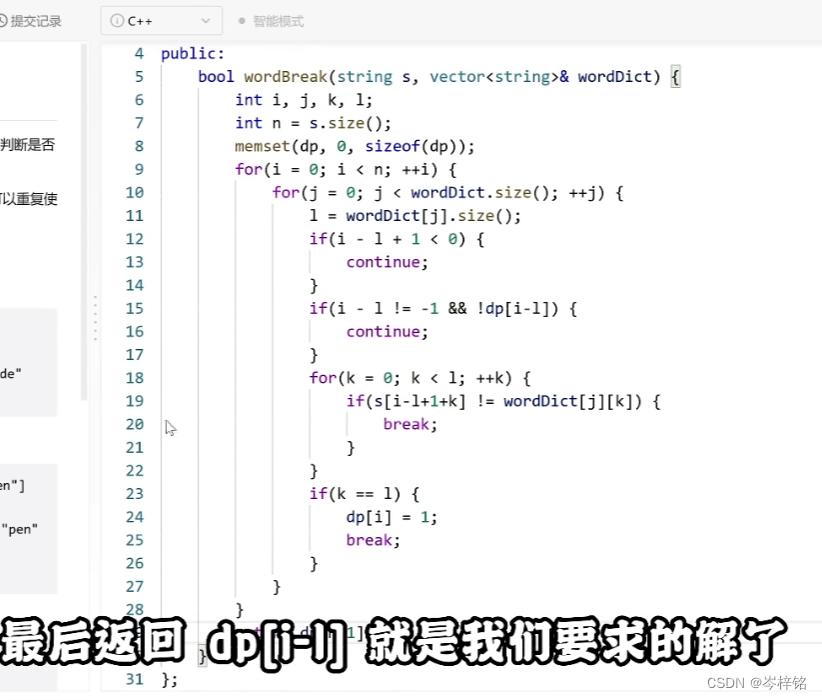
六、第14届蓝桥杯国赛——互质(中等偏上一点的难度)

【互质就是指这两个数之间除了1没有别的公约数,比如“3跟7”、“2跟13”,“6跟8”就不是,因为有公约数2】
一共三个方法,第一个是傻逼方法,第二个是稍微不那么傻逼但是也不对的方法,第三个方法是正确的。想学逻辑思路的看前两个方法,想看正确做法的看第三个方法。
第一个方法思路:(傻逼的方法)
原始第一版,直接无脑,暴力搜索
首先分解【2023】的约数(除了1),得到一共5个:【7、17、119、289、2023(它自己)】
然后遍历【2 ~ 2023的20233次方】(1没用,就不参与遍历了)
每遍历一个数,就分解它的约数,然后在分解一个约数的时候马上去【2023的约数】里找
有相同的,就说明这个数跟2023存在除了1以外的公约数;没有就说明这个数跟2023只有1这个公约数,那就是互质。
注意:
1、因为数据量很大很大,long也装不下,所以要用到【BigInteger】,这是一个用来装超大数的对象。
2、然后尽量用集合而不是数组,集合的成员也换成BigInteger类型
3、然后其实这个方法正确,但是数据量庞大的情况根本循环不了,时间消耗太久,自己可以拿我代码试一下,可以试着循环【1~10000】以内跟2023的互质数,再多一点就要卡死了(所以建议看我第二版)
另外,提一下BigInteger用法
1、创建
第一种:BigInteger n = BigInteger.valueOf( 数字值 );
第二种:BigInteger n = new BigInteger( "字符串类型数字" );
2、加、减、乘、除、取余运算
BigInteger a = sc.nextBigInteger();
BigInteger b = sc.nextBigInteger();
(1)加:a.add(b) ——> a + b
(2)减:a.subtract(b) ——> a - b
(3)乘:a.multiply(b) ——> a * b
(4)除:a.divide(b) ——> a / b
(5)取余:a.remainder(b) ——> a % b
3、逻辑运算
(1)比较:a.compareTo(b) ——> a>b返回正数、a==b返回0、a<b返回负数
(2)等于:a.equals(b) ——> a==b返回true、a!=b返回false
4、自增自减等变化
a = a.add(...)、 a = a.subtract(...)、 a = a.mutiply(...) ......
因为这些加减乘除之后只会返回一个新的值,而不是修改a原本的值,要让a重写接收赋值,来获得对自己加减乘除之后的新值
最后,因为BigInteger类型的数据只跟BigInteger类型数据运算、比较,像【a.add(1)】这样是【错】的,要把1换成BigInteger类型才行【a.add(BigInteger.valueOf(1))】这样才是对的
为了减少转换的麻烦,我们一开始就把这些0、1、最大值啥的频繁要用的数,定义成常量:
static BigInteger TZTT = BigInteger.valueOf(2023); //TZTT代表2023
static BigInteger MAX = TZTT.pow(2023); //MAX代表2023的2023次方
static BigInteger ZERO = BigInteger.valueOf(0); //ZERO代表0
static BigInteger ONE = BigInteger.valueOf(1); //ONE代表1
static BigInteger TWO = BigInteger.valueOf(2); //TWO代表2
完整代码:(不适用于2023的2023次方,只适合小范围循环)
import java.util.ArrayList;
import java.util.List;
import java.math.BigInteger;
public class 国赛01_互质数 {
static BigInteger TZTT = BigInteger.valueOf(2023); //TZTT代表2023
static BigInteger MAX = TZTT.pow(2023); //MAX代表2023的2023次方
static BigInteger ZERO = BigInteger.valueOf(0); //ZERO代表0
static BigInteger ONE = BigInteger.valueOf(1); //ONE代表1
static BigInteger TWO = BigInteger.valueOf(2); //TWO代表2
public static void main(String[] args){
//既然规定了是跟2023找互质数,那么就先拆分2023的所有约数
List<BigInteger> Yueshu = new ArrayList<>();
//yueshu是用来遍历2023(包括后面2~2023的2023次方的每一个数)的【约数】,因为1没用就从2开始遍历
BigInteger yueshu = BigInteger.valueOf(2);
//翻译:【yueshu.compareTo( TZTT ) <= 0】————>【yueshu <= TZTT(2023)】
while(yueshu.compareTo( TZTT ) <= 0){
//翻译:if(2023 % yueshu == 0)
if(TZTT.remainder( yueshu ).equals(ZERO)){
Yueshu.add(yueshu);
}
//虽然BigInteger的加法是.add(),但是这只会返回一个加后的结果,并不会让yueshu自身变化
//必须得让yueshu去接收“yushu + 1”的这个结果才行
yueshu = yueshu.add( ONE );
}
//经过确定2023的约数只有5个,那么只要遍历2~2023的2023次方,然后分解他们的约数
//但是!并不分解完!每次分解获得约束的时候就去比较Yueshu这个集合(也就是2023的约束)里有没有一样的,有就退出、下一个
//而且我发现2023是奇数,偶数不可能分解出偶数约数,奇数也不会分解出奇数约数,那么【偶数就必然会跟2023互质】的
boolean flag = false; //flag判断这个数有无跟2023之间除了1以外得约数,有就true
BigInteger count = ONE; //count统计有几个互质数,并且直接定义为1,因为1跟任何书互质
//翻译:for(int i = 0; i<=MAX; i++),遍历2~2023(因为1没用)的2023次方,并且不要偶数
//这里我发现这样根本不能循环2023的2023次方,计算机会卡死,所以我这就判断【1~2023】跟2023的互质数了(不符题意,这个解法不行)
for (BigInteger i = TWO; i.compareTo( BigInteger.valueOf(2023) )<=0; i=i.add(ONE)) {
//并且判断是偶数就直接是互质数,因为偶数不可能和2023有除了1以外的公约数
if( i.remainder(TWO).equals(ZERO) ){
count = count.add(ONE);
continue;
}
//每次都要更新初始值:约数 = 2 / flag为假
yueshu = BigInteger.valueOf(2);
flag = false;
//分解1~2023的2023的每一个数的约数,yueshu从2遍历到i
//【yueshu.compareTo( i ) <= 0】 ————> 【yueshu <= i】
while(yueshu.compareTo( i ) <= 0){
//如果是约数
//【i.remainder( yueshu ).equals(ZERO)】————>【i % yueshu == 0】
if( i.remainder( yueshu ).equals(ZERO) ) {
//那么遍历2023的所有约数,然后如果当前这个约数如果等于2023的其中一个约数,就判断不是互质数并退出遍历
for (BigInteger item : Yueshu) {
//【yueshu.equals(item)】————>【yueshu == item】
if (yueshu.equals(item)) {
flag = true;
break;
}
}
//如果flag从false变true了
//就说明当前这个约数如果等于2023的其中一个约数,就判断为不是互质数
//当前i就没必要分解yueshu了,退出遍历
if (flag) {
break;
}
}
yueshu = yueshu.add( ONE );
}
//那么只要flag没变过,就说明这个i跟2023除了1没有公约数,那就是互质数
if (!flag){
count = count.add(ONE);
}
}
//题目要求把结果对【10的9次方+7】取余
BigInteger yu = BigInteger.valueOf(10).pow(9).add(BigInteger.valueOf(7));
System.out.println(count.remainder(yu));
}
}
第二个方法思路:(傻逼的方法)
我发现第一个不行,于是我想到【欧几里得】求最大公约数法,也就是求a和b这两个数的最大公约数,只需要:
b % a = c1(余数1)
a % c1 = c2(余数2)
c1 % c2 = c3(余数3)
......
不停把【除数】当成下一次计算的【被除数】,【余数】当成下一次计算的【除数】,直到【余数】为0的时候,那个【除数】就是就 a 和 b 的最大公约数
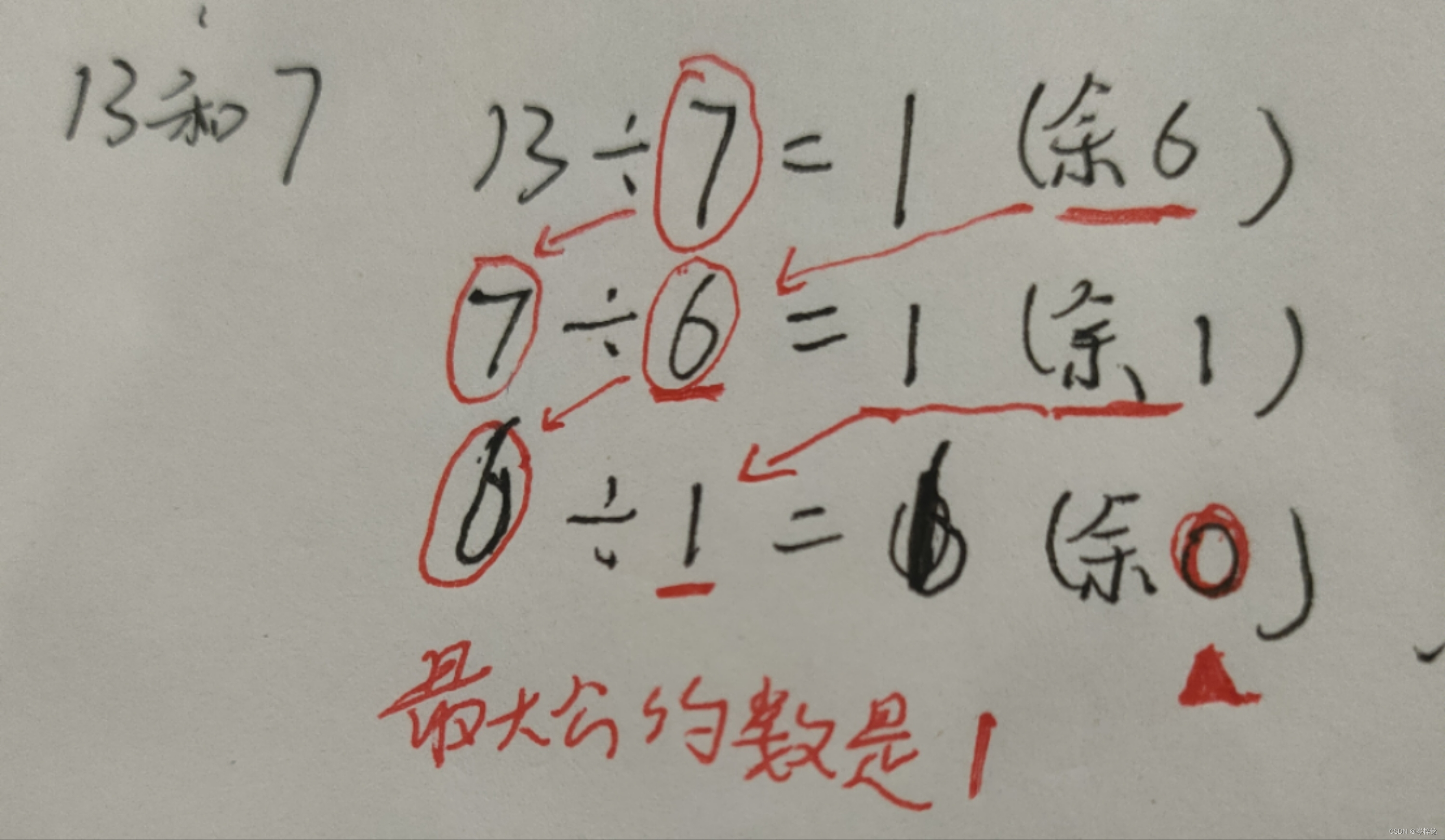


这样一来只要判断最后这两个数的【最大公约数】是不是1就知道它两是不是互质了
完整代码:
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
public class 国赛01_互质数第二版 {
static BigInteger TZTT = BigInteger.valueOf(2023); //TZTT代表2023
static BigInteger MAX = TZTT.pow(2023); //MAX代表2023的2023次方
static BigInteger ZERO = BigInteger.valueOf(0); //ZERO代表0
static BigInteger ONE = BigInteger.valueOf(1); //ONE代表1
static BigInteger TWO = BigInteger.valueOf(2); //TWO代表2
public static void main(String[] args) {
BigInteger count = ONE;//count计数器记录有几个互质数,初始值为1,因为下面我从2~2023的2023次方遍历,而1与任何非0数都互质
for (BigInteger i = TWO; i.compareTo(BigInteger.valueOf(20)) <= 0; i = i.add(ONE)) {
boolean isHuZhi = gcd( i );
if( isHuZhi ){
count = count.add(ONE);
}
}
// 行不通,还是根本循环不了
// for (BigInteger i = TWO; i.compareTo(MAX) <= 0; i = i.add(ONE)) {
// boolean isHuZhi = getHowManyHuZhi( i );
// if( isHuZhi ){
// count = count.add(ONE);
// }
// }
System.out.println(count);
}
//欧几里得求最大公约数法
public static boolean gcd( BigInteger i ){
BigInteger beichushu = TZTT;
BigInteger chushu = i;
BigInteger yushu = beichushu.remainder( chushu );
while( !yushu.equals(ZERO) ){
beichushu = chushu;
chushu = yushu;
yushu = beichushu.remainder( chushu );
}
if (chushu.equals(ONE)) {
return true;
} else {
return false;
}
}
}最后发现......塔玛得还是只能循环小范围,根本不能循环2023的2023次方
第三个方法:(正确的)
后面借鉴网上,发现......塔玛得根本不是算法的问题,是根本不可能循环2023的2023次方,哪怕你跳着循环、循环一半、一次循环啥也不做,都根本不可能跑完这么大的数
那么只能是跟数学的计算公式有关,应该用个公式直接算出来
那么就要引入一个新知识点(原谅我是文科转理工科,这对于我来说就是新知识点):质因子
【质因子】就是每个数里由【这些数】以及【包含它们为约数的数】相乘得的数
打比方:
1没有质因子。
5只有1个质因子,5本身。(5是质数。)
6的质因子是2和3。(6 = 2×3)
2、4、8、16等只有1个质因子:2(2是质数,4 = 22,8 = 23,如此类推。)
100有2个质因子:2和5。(100 = “2的二次方” × “5的二次方”)
360有3个质因子:2、3、5。(360 = “2的三次方” × “3的二次方” × “5的一次方”)
那么我们要质因子干什么?因为如果两个数共同含有质因子的话,那么这两个数必然有除了1以外的公约数,那么这两个数百分之一百不互质!!!
那么,我们先拆分2023的质因子,2023 = 【7 * 17 * 17】,那么质因子就是【7】跟【17】,然后还是找【1 ~ 2023的2023】究竟有几个跟2023一样含有【7】、【17】为质因子的数,除了这些数以外的数就跟2023互质了。
然后分别求除【1 ~ 2023的2023】范围里有几个含【7】跟【17】为质因子的数,怎么求?
因为含有这个【质因子】的这个数,就是这个【质因子的倍数】,而(从1到某个数范围内)有几个含有这个质因子的【个数】 就等于这个【质因子的倍数】
打比方:
【1 ~ 7】范围,含有质因子为3的有2个:3、6,而3的2倍就是6
【1~15】范围,含有质因子为4的有3个:4、8、12,而4的3倍就是12
所以可得:
【1 ~ 2023的2023次方】含【7】质因子的个数 = 【2023的2023次方】 / 【7】
【1 ~ 2023的2023次方】含【17】质因子的个数 = 【2023的2023次方】 / 【17】


然后这还没结束,并不是“含【7】质因子的个数” + “含【17】质因子的个数” 就是 【1 ~ 2023的2023次方】里与2023互质的数,因为我们假设:
A集合作为“含【7】质因子的个数”
B集合作为“含【17】质因子的个数”
那么 A + B 其实还涵盖了 共同 “含【7】和【17】都是【质因子】的数” ,比如:119的质因子有7跟17,那这么一来就重复统计了
当我们有两个集合A和B,并且我们想要找出同时属于A和B的元素数量时,可以使用公式:
∣A∪B∣=∣A∣+∣B∣−∣A∩B∣
其中,∣A∪B∣ 表示集合A和B的并集的大小,∣A∣ 和 ∣B∣ 分别表示集合A和B的大小,∣A∩B∣ 表示集合A和B的交集的大小。
SO,回到题目,那么【A∩B】就是【7 * 17】=【119】
然后【∣A∩B∣】就是:【1 ~ 2023的2023次方】含【119】质因子的个数 = 【2023的2023次方】 / 【119】
所以【1 ~ 2023的2023】里与2023不互质的数一共有:【1 ~ 2023的2023】- ( ∣A∪B∣ ) = 【1 ~ 2023的2023】- ( ∣A∣+∣B∣−∣A∩B∣ )
结合代码,就这么几句 [ / 捂脸 ]
import java.math.BigInteger;
public class 国赛01_互质数第三版 {
public static void main(String[] args) {
BigInteger SEVEN = BigInteger.valueOf(7), SEVENTEEN = BigInteger.valueOf(17), ONEONENINE = BigInteger.valueOf(119);
BigInteger MAX = BigInteger.valueOf(2023).pow(2023);
BigInteger A = target.divide(SEVEN), B = target.divide(SEVENTEEN), C = target.divide(ONEONENINE);
System.out.println(MAX.subtract(A).subtract(B).add(C).mod(BigInteger.valueOf((int)1e9 + 7)));
//翻译简单就是
//【A = 2023的2023次方 / 7】 、【B = 2023的2023次方 / 17】 、【C = 2023的2023次方 / 119】
//【1 ~ 2023的2023次方】跟2023互质的数 = 2023的2023次方 - A - B + C (取模就不解释了)
//也就是【1 ~ 2023的2023次方】跟2023互质的数 = 2023的2023次方 - ( A + B - C )
}
}七 、统计全由1组成的正方形矩阵(中等偏上难度)

一开始我的错误思路:
先用一个变量MaxLength获取原矩阵的最小边长,作为【正方形矩形】的【最大边长】
打比方:
1111111111
1111111111
这么一个矩阵,最短的一边是2,
那么这里面最大只能分出2 * 2的正方形矩形
1111111111
1111111111 (对)
然后用一个大循环从1遍历到MaxLength,每次循环代表当前可分的正方形边长,不超出MaxLength就行
然后里面再套两层循环,用来遍历“原矩阵”这个二维数组,每遍历到一个坐标,只要这个坐标的(自己、右上角、右下角、左下角)都是1就当成一个正方形
但是错!!!大错特错!!!!
我这既不能确认边全都是1,更不能确认除了四边、里面全都是1组成!!!!
傻逼的错误代码展示:
import java.util.Scanner;
public class 统计全由1组成的正方形矩阵 {
public static void main(String[] args){
Scanner in = new Scanner(System.in);
//给一个矩阵大小:m * n
int m = in.nextInt(); //m是列,(但是是x轴坐标)
int n = in.nextInt(); //n是行,(但是是y轴坐标)
int[][] matrix = new int[n][m];
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
matrix[i][j] = in.nextInt();
//样例:
//0 1 1 1
//1 1 1 1
//0 1 1 1
}
}
//首先要限制正方形矩形的边长,不能大于 m * n 这个长方形的短的那个边长
int MaxLength = Math.max(m,n);
//计数器
int count = 0;
//就是老容易看错坐标,写个注释就方便了
// j(m) j(m) j(m) j(m)
// 0 1 1 1 i(n)
// 1 1 1 1 i(n)
// 0 1 1 1 i(n)
for (int l = 1; l <= MaxLength; l++) {
for (int i = 0; i+l-1 < n; i++) {
for (int j = 0; j+l-1 < m; j++) {
if( l == 1 ){
if( matrix[i][j] == 1 )
count ++;
}else{
if( matrix[i][j]==1 && matrix[i][j+l-1]==1 && matrix[i+l-1][j+l-1]==1 && matrix[i+l-1][j]==1){
count++;
}
}
}
}
}
System.out.println(count);
}
}
正确的思路:
还是得用dp动态规划
(1)第一个规律
首先判断得到一个边长为1的正方形,以这个坐标的小正方形为【状态1】:dp1
那么在【dp1】的基础上,以它为边长为2的正方形的右下角,那么只要dp1的外围都是1,就可得到一个边长为2的正方形,再以这个正方形为【状态3】:dp2
再以这个【dp2】为基准,又可以推出【dp3】;然后【dp3】推出【dp4】......

那么可知,反推:要想得到一个边长为3的正方形(【dp3】),右下角必须得先有边长为2的正方形(【dp2】);而要有边长为2的正方形(【dp2】),右下角必须得先有边长为1的正方形(【dp1】)
(2)第二个规律
因为1个边长为2的小正方形包含了【4个边长为1的小正方形】和【1个边长为2 的大正方形】
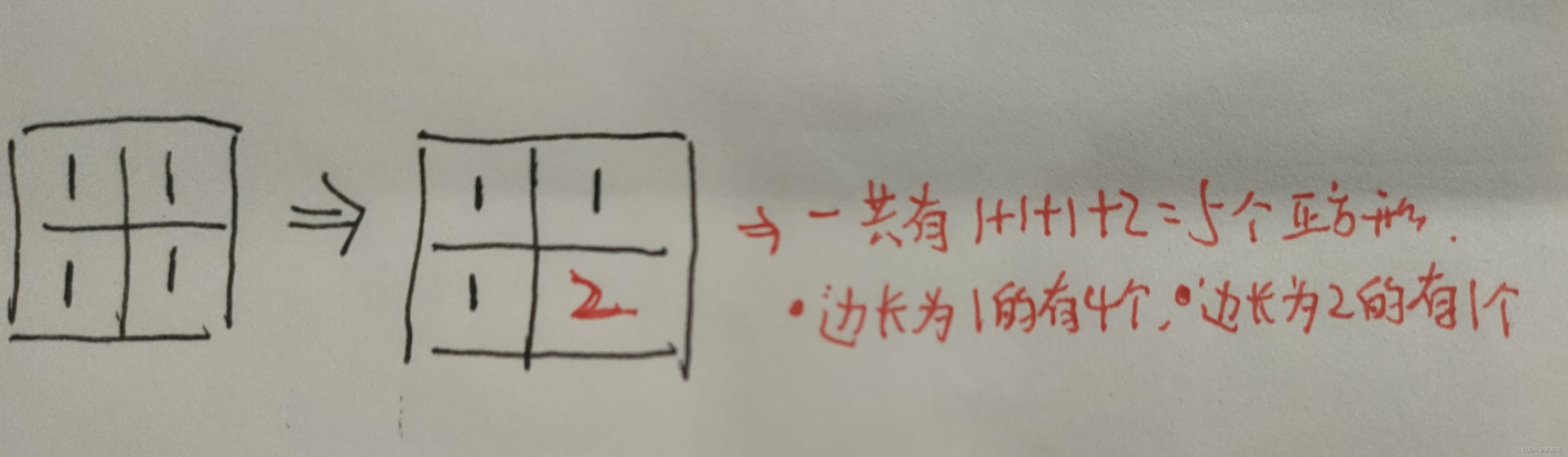
那么我们在最右下角那里给那个 “ 1 ” 【加1】,写上个 “ 2 ” 代表:【这整个正方形可以组成1个边长为2的大正方形】,把所有数字加起来就是最多可以组成的正方形:1+1+1+2 = 5个
(注意:另外2 > 1,“ 2 ”即表示【这整个正方形可以组成1个边长为2的大正方形】,也包含了【这个位置是1个边长为1的小正方形】的含义)
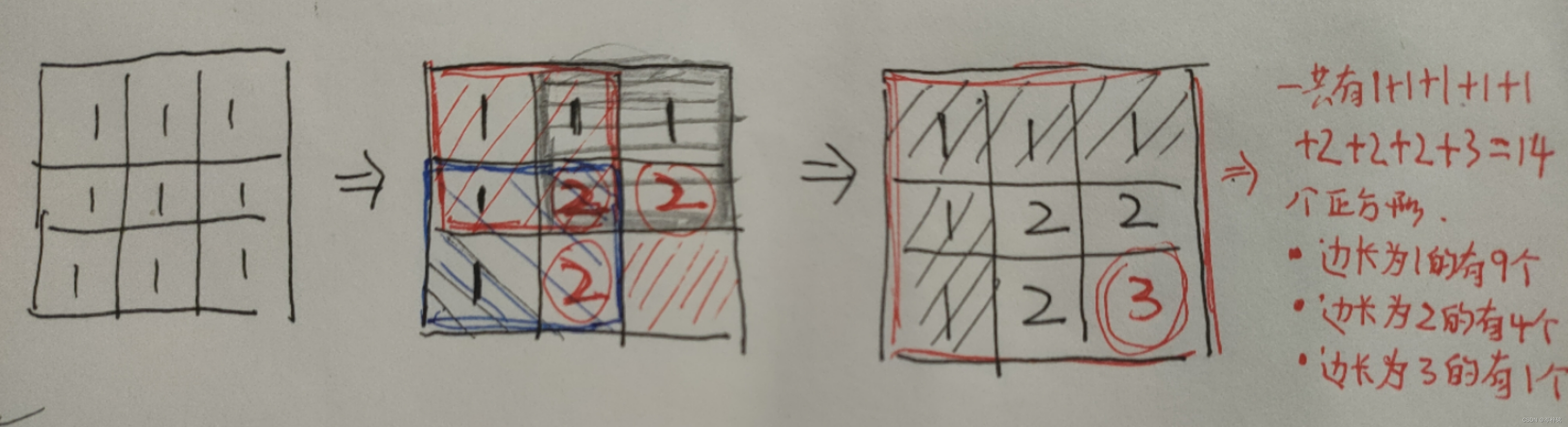
那么以这个边长为2的正方形为基础,在一个边长为3的正方形里,从外围往里面右下角看,让每一个边长为2的正方形的右下角都【加1】,然后右下角就应该是一个【边长为2】的并且【都是由 “ 2 ” 组成】的正方形
但是,这里我们先保留最右下角的那一块边长为1的正方形不写 “ 2 ” ,因为这里应该是在外围的 “ 2 ” 的基础上再【加1】:2+1=3
因为 3>2>1 ,“ 3 ”就表示:这整个大正方形可以组成1个边长为3的大正方形、然后包含了【右下角还可以组成1个边长为2的中正方形】、【最后最右下角是1个边长为1的小正方形】的含义,所以这里要用“ 3 ”表示
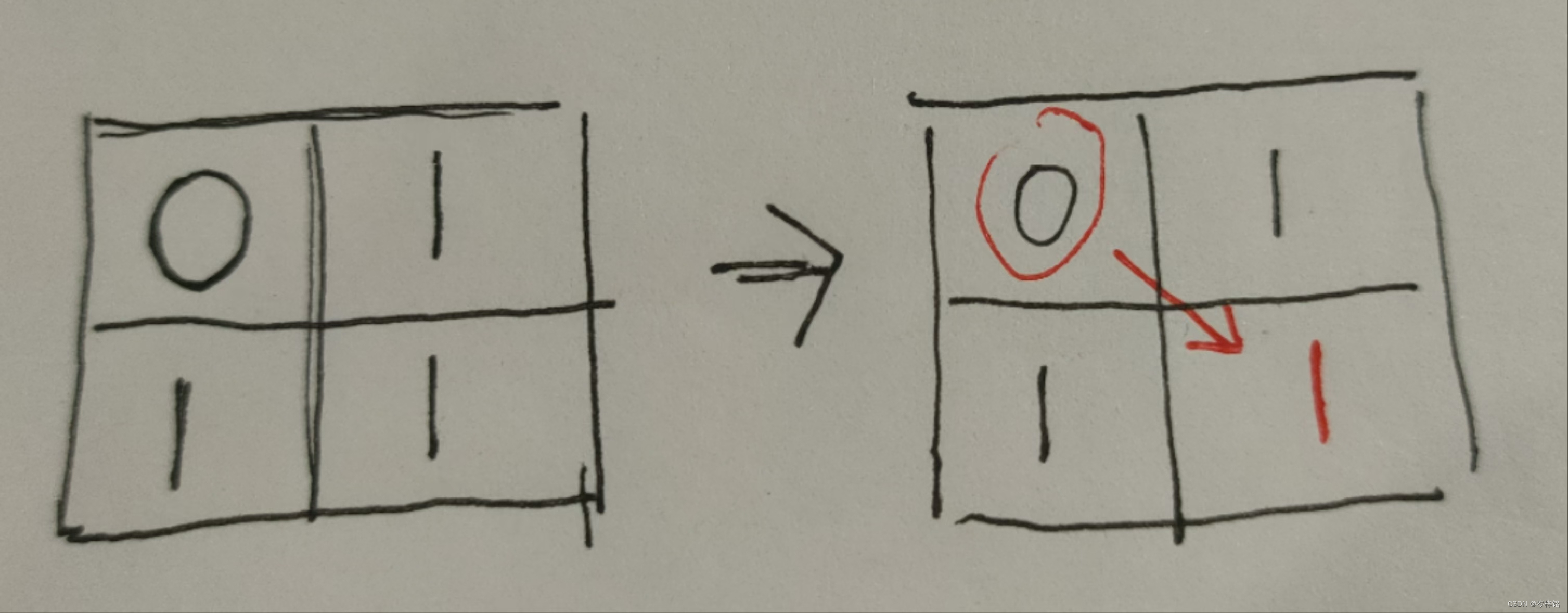
那么现在规律已经很明显了:
1、以一个边长为2的正方形(也即是由4个边长为1的小正方形组成的)为基准正方形
2、在这个基准正方形的右下角的数值 = 外围数值的最小值 + 1 = (左上角、左边、上边的最小值) + 1
为什么要外围的最小值呢?
因为会出现中间有0没办法组成正方形的情况,那么右下角的数值就应该根据外围数值的最小值情况+1,然后组成新的外围供下一个右下角生成新的数值
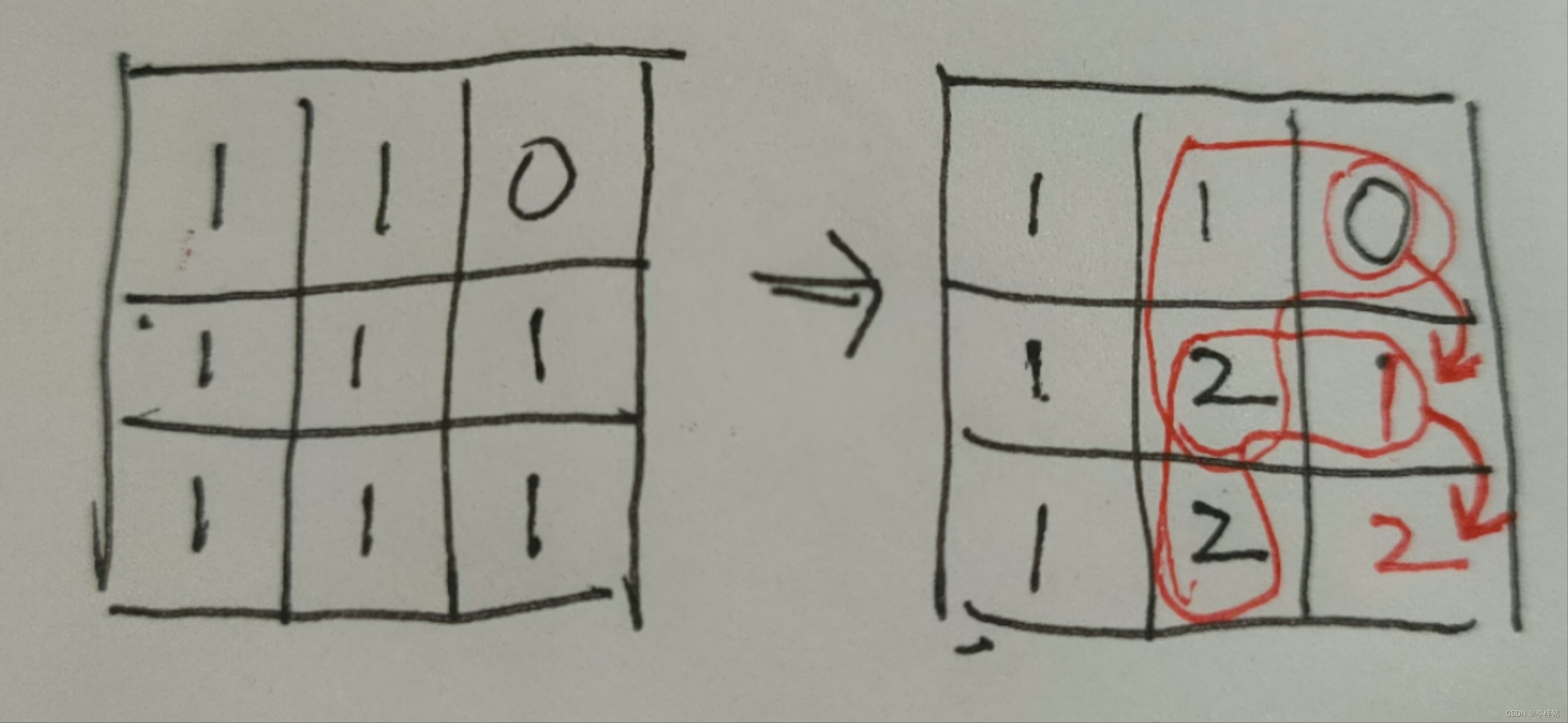
(3)最后一个难点
那接下来到底该怎么遍历呢?
首先我们不能把【把基准正方形的右下角数值加1】这种操作放在原矩阵(二维数组)里操作,因为这样会破坏原二维数组的各数值正常情况,要另起一个二维数组——dp状态数组,来记录根据我们上面【右下角的数值 = 外围数值的最小值 + 1 = (左上角、左边、上边的最小值) + 1】这个公式获得新矩阵。
然后我们只需要每遍历到一个【坐标】,就以这个坐标为一个【基准正方形】的 【左上角】,直接通过【外围】(该坐标、坐标右边、坐标下边)的【最小值+1】获得【右下角】坐标那里的数字值
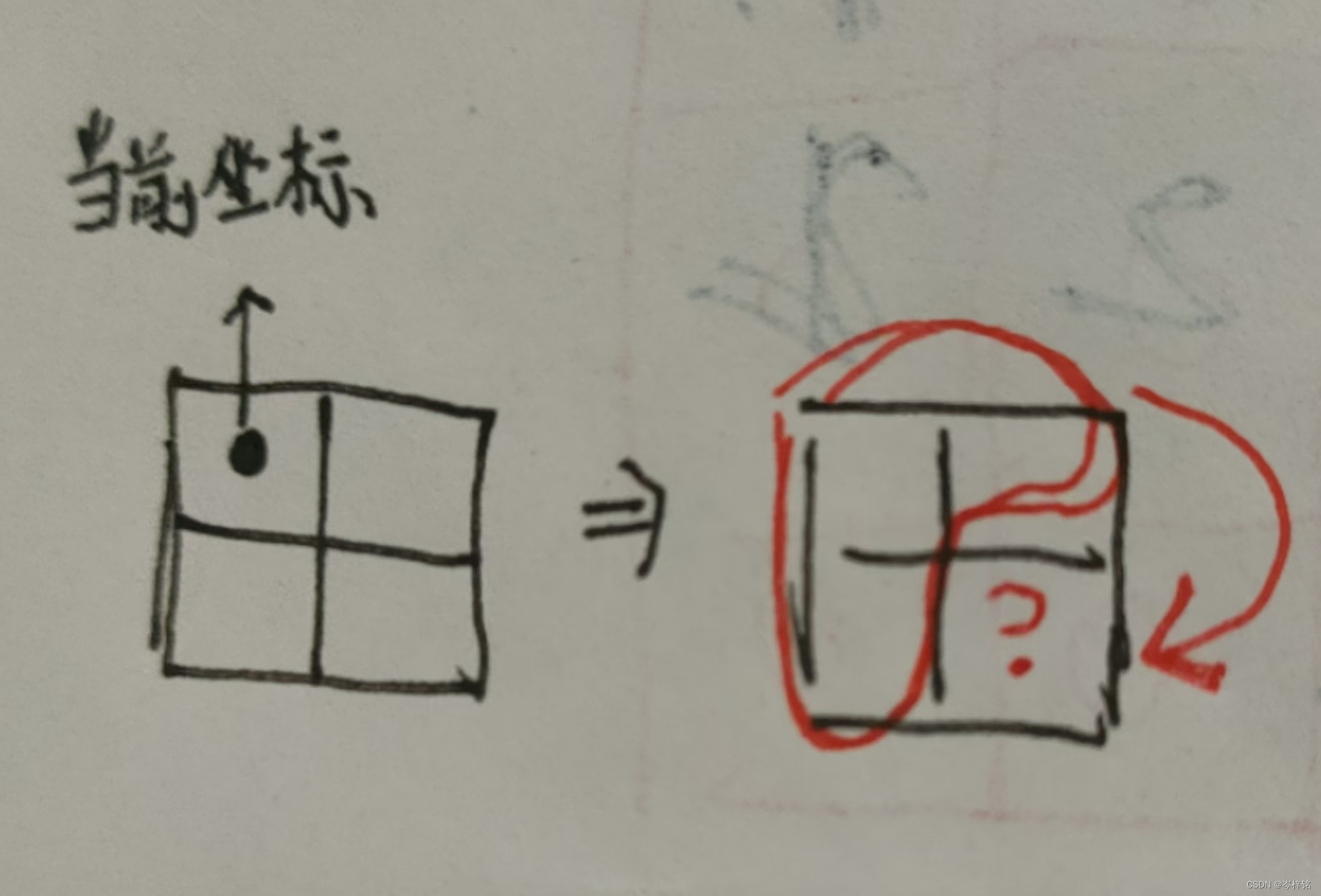
最后,因为遍历到的坐标是[ i ][ j ],而右下角的坐标是[ i+1 ][ j+1 ],当遍历到原二维数组的【最右边】或【最下边】的坐标时,[ i+1 ][ j+1 ]就会数组越界了!
那么注意!!这是重点!
1、首先dp数组是一个初始值全是0的二维数组,然后我们要让dp数组比原二维数组多一行、多一列,以【第1行】和【第1列】为不记录数值的【初始值】,除了这一行和这一列的右下角整个矩阵,才代表原二维数组矩阵。
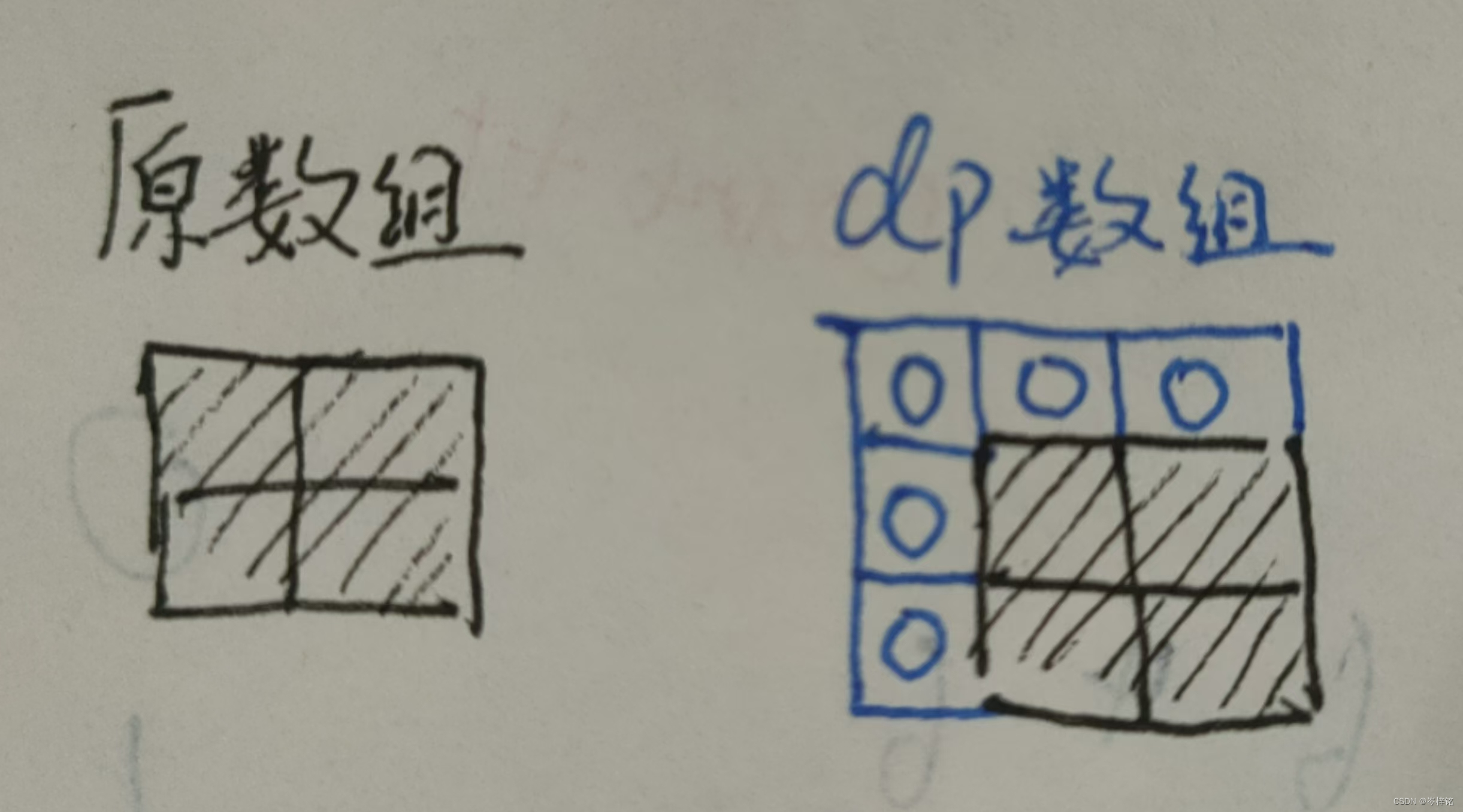
2、第二步,我们遍历原数组的范围
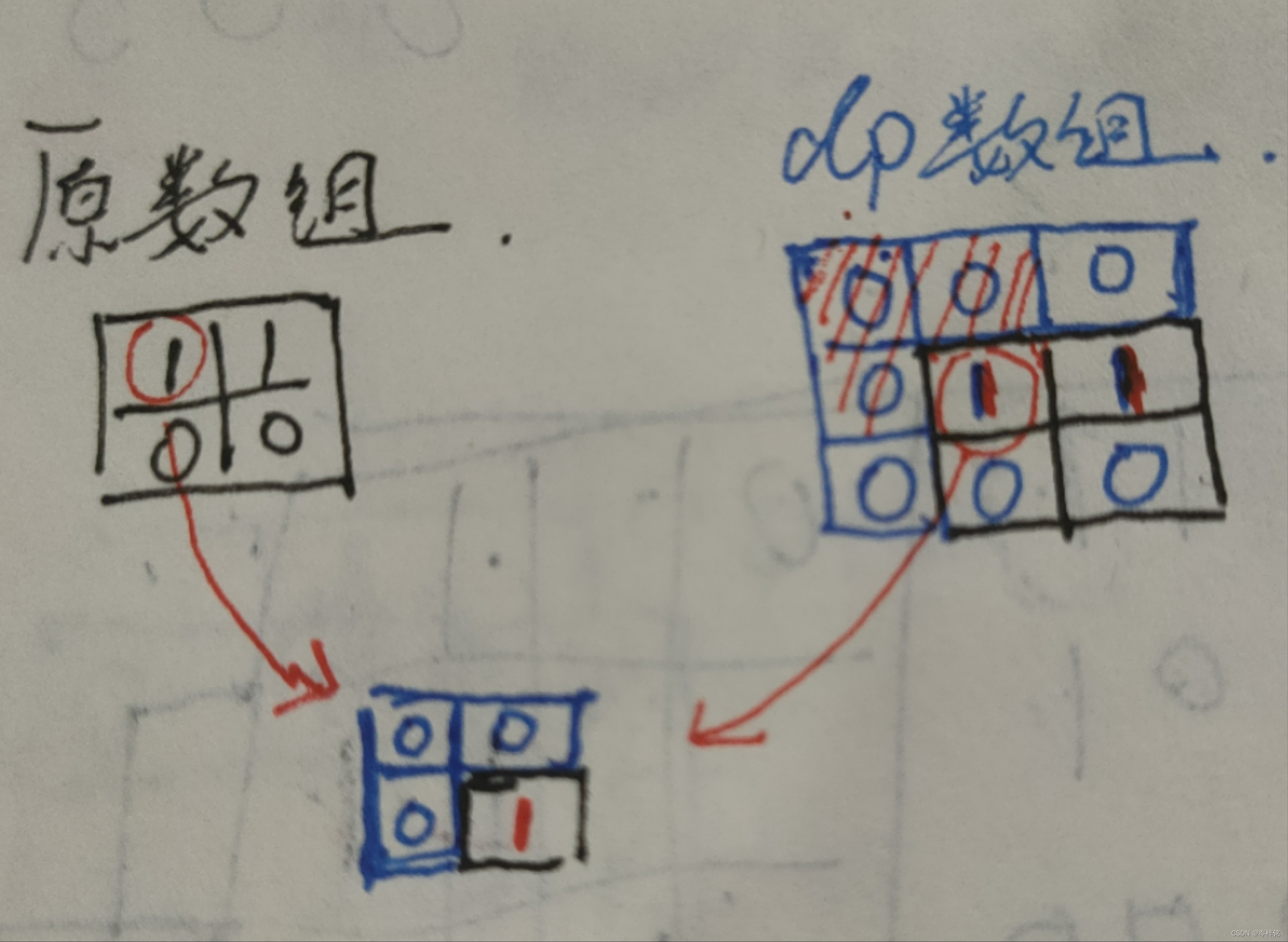
当遇到数值是0的坐标,就跳过不管
遇到数值1的坐标,就到dp数组里对应的坐标,【注意注意!!!!】把这个【原数组里的坐标】作为【dp数组里的一个基准正方形的最右下角】!!!
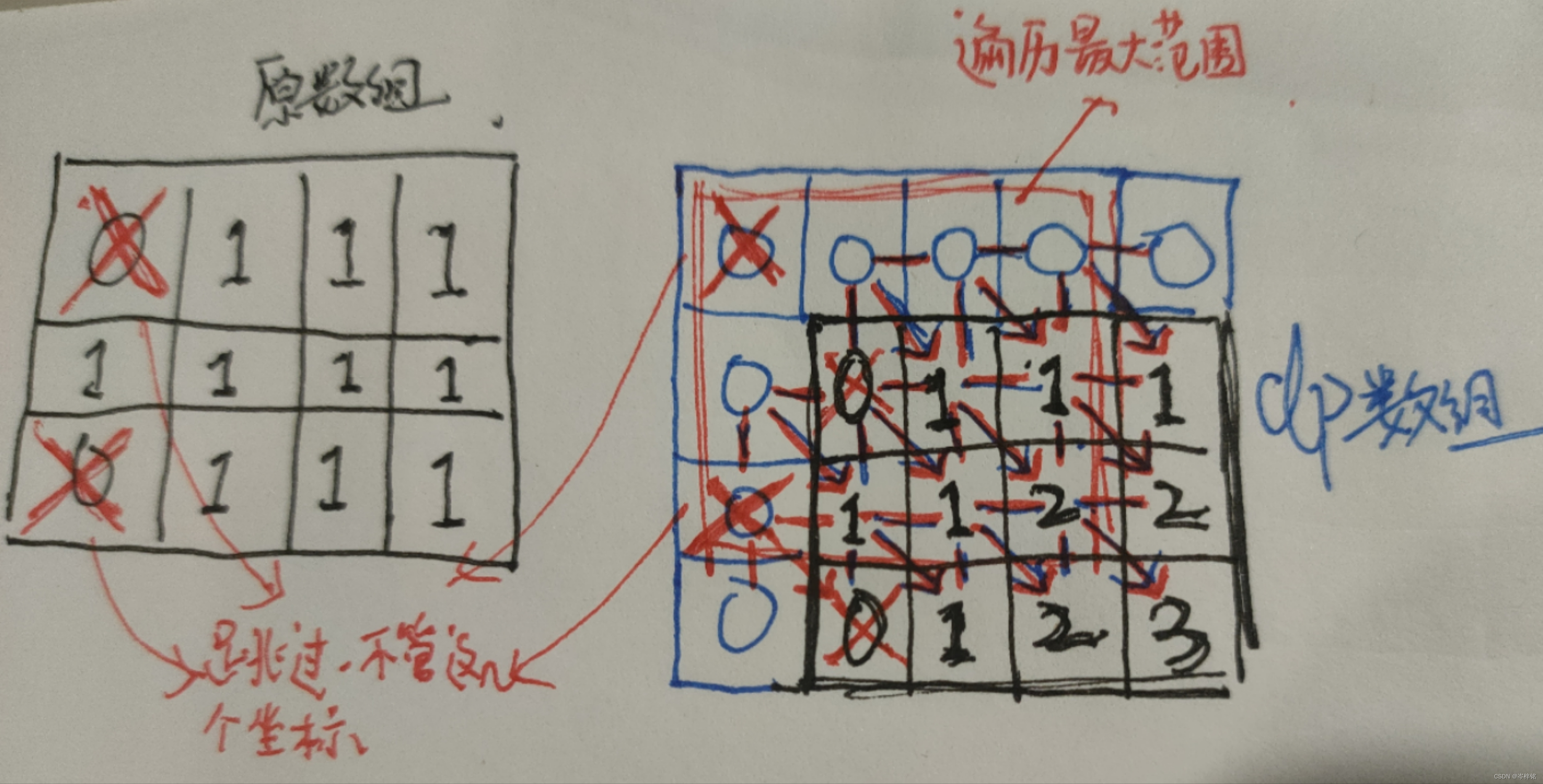
这样一来,我们就将dp数组里当前这个坐标的右下角作为原数组的当前坐标,根据dp这个右下角坐标的【外围】来确定这个坐标的数值,如此循环下来就能得到记录【能组成多少个正方形的矩阵】了
完整代码:(这里输入没按题意,我直接按数字把原数组直接输入了)
import java.util.Scanner;
//输入样例
//4 3
//0 1 1 1
//1 1 1 1
//0 1 1 1
public class 统计全由1组成的正方形矩阵 {
public static void main(String[] args){
Scanner in = new Scanner(System.in);
//给一个矩阵大小:m * n
int m = in.nextInt(); //m是列,(但是是x轴坐标)
int n = in.nextInt(); //n是行,(但是是y轴坐标)
int[][] matrix = new int[n][m];
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
matrix[i][j] = in.nextInt();
}
}
int count = 0;//正方形的个数
int[][] dp = new int[matrix.length + 1][matrix[0].length + 1];
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[0].length; j++) {
//如果当前坐标是0,就不可能构成正方形,直接跳过
if (matrix[i][j] == 0)
continue;
//递推公式
dp[i + 1][j + 1] = Math.min(Math.min(dp[i + 1][j], dp[i][j + 1]), dp[i][j]) + 1;
//累加所有的dp值
count += dp[i + 1][j + 1];
}
}
System.out.println(count);
}
}八、粉刷房子(中等偏下难度)

当你认真把前面的题目搞明白了,那么这道题你会发现跟前面的逻辑有些地方有点相似:
1、跟 “ 四、分隔数组已得到最大和 ” 这题逻辑有点近似,用动态规划dp数组记录每一个位置的最理想状态,然后后面位置的dp状态根据比较前面的dp状态,从前面选出最理想的状态结合自己,作为自己位置最理想的dp状态
2、跟上一题 也相似,因为这里要用到二维数组形态的dp数组
然后我们根据房子顺序去遍历,先不要考虑每个房子哪个颜色最便宜,要遍历每一个颜色的情况
dp数组则要按房子顺序记录:每一个房子选取某个颜色后,结合它之前粉刷过的房子【最理想】的花费,所要花费最少的钱(当然两间房子一定不能同色)
打比方:
已知第3间房子选红色至少要花100,选蓝色至少花200,选绿色至少花300;
然后第4间房子(不包括前面房子要花的钱)刷红色漆要花50,刷蓝色30,刷绿色40
那么此时第4间房子选红色至少花【50+200】,选蓝色至少【30+100】,选绿色至少【40+100】
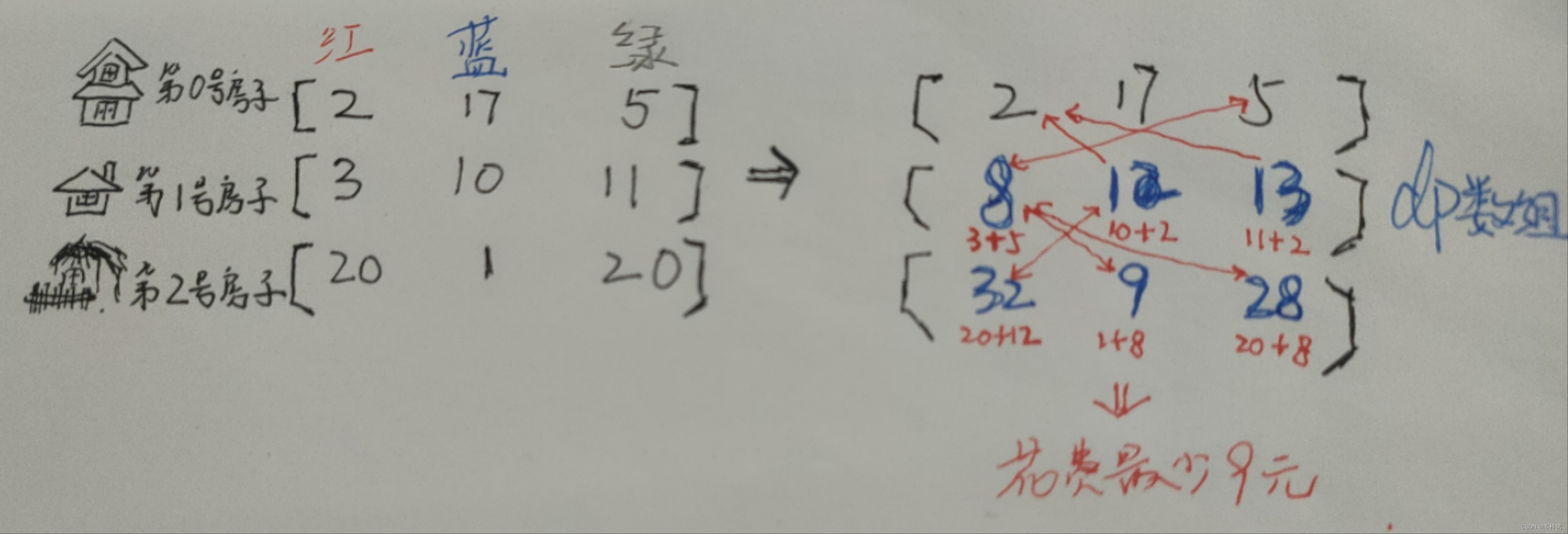
那么代码就出来了:
import java.util.Scanner;
public class 粉刷房子 {
//输入样例
//3
//2 17 5
//3 10 11
//20 1 20
public static void main(String[] args){
Scanner in = new Scanner(System.in);
//这里输入格式我改一下,因为我懒得花时间在输入部分,只要知道算法逻辑就行了
//先输入要粉刷几个房子: n
int n = in.nextInt();
//然后输入各个房子粉刷[ 红\蓝\绿 ]分别要花的钱,二维数组
int[][] house = new int[n][3];
for (int i = 0; i < house.length; i++) {
for (int j = 0; j < house[0].length; j++) {
house[i][j] = in.nextInt();
}
}
//然后有一个dp二维数组来记录每一个房子选择的每一个颜色所需花费的最少钱(包括了前面的房子所花费最少的钱)
int[][] dp = new int[n][3];
int min = Integer.MAX_VALUE;
for (int i = 0; i < house.length; i++) {
for (int j = 0; j < house[0].length; j++) {
//当刷第一个房子的时候,因为前面没有刷过的房子
//那么每一种颜色都是当前这个房子[ 对应的这个颜色 ]要花最少的钱
//(不是要花最少的钱,最少的钱肯定是哪个颜色便宜选哪个)
if( i == 0 ){
dp[i][j] = house[i][j]; //那就直接赋值给dp数组里的第一间房子
continue;//并且跳过下面的操作
}
//初始化dp[i][j]的值为最大
dp[i][j] = Integer.MAX_VALUE;
//当开始刷第2间房子的时候
for (int k = 0; k < house[0].length; k++) {
//只要不是跟上一间房子同颜色
if( k != j ){
//那么就根据上一间房子的各个颜色所花费最少的钱,来比较当前这个房子怎么选颜色最省钱
dp[i][j] = Math.min( dp[i][j] , house[i][j] + dp[i-1][k] );
}
}
//当遍历到最后一间房子的时候,再比较一下最一间房子[哪一个颜色的方案]最便宜
//一定要在最后一间房子的时候才比较,不然最小值就是前面房子的钱了,忽略了后面房子要花的钱
if( i == house.length - 1){
min = Math.min( dp[i][j] , min );
}
}
}
//当然还要判断一下如果只有一个房子的情况
if(house.length == 1){
for (int j = 0; j < house[0].length; j++) {
min = Math.min( house[0][j] , min );
}
}
//最后输出最小值
System.out.println(min);
// 测试输出,可以看到dp二维数组已经把选择每个房子的每种颜色所要花费最少的钱获得了
// for (int i = 0; i < dp.length; i++) {
// for (int j = 0; j < dp[0].length; j++) {
// System.out.print(dp[i][j] + " ");
// }
// System.out.println();
// }
}
}
累了,现在5月23号,距离国赛还有7天,还有一堆逼作业还有逼课,过两天再更新吧



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











