







爬取中国知网网站的内容(底下附源码和运行结果)
项目需求:
爬取中国知网网站的内容(网址https://www.cnki.net/),获取搜索到的文章的信息,包括文章的序号、题名、作者、发表时间和数据库,输出爬取到的信息并将其保存到MongoDB数据库中。
项目分析:
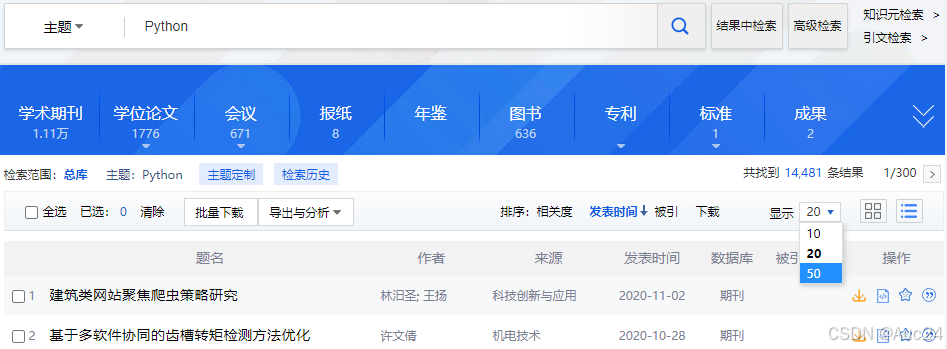 |
使用Selenium模拟浏览器在中国知网中搜索文章的过程为:最先,使用Google Chrome浏览器打开中国知网首页(网址https://www.cnki.net/),搜索“Python”;然后,在“显示”的下拉列表中选择“50”选项;最后,通过单击“下一页”按钮来实现翻页,如图所示。
通过在开发者工具中查找需要操作的节点,判断节点是否加载出来,然后进行操作。例如,搜索时,需要根据“搜索”的输入文本框和按钮节点是否加载完成判断是否进行下一步;选择每页显示文章数时,需要根据下拉列表中所有选项是否加载完成判断是否进行下一步;由于网站翻页到一定页数时,需要提交验证码,因此循环中根据“下一页”节点是否可见判断是否继续解析网页。使用beautifulsoup4库解析网页,提取文章信息,保存至MongoDB数据库中。
逐行解读
导入必要的库:
from selenium import webdriver:导入Selenium的webdriver模块,用于控制浏览器。
from selenium.webdriver.common.by import By:导入By模块,用于定位页面元素。
from selenium.webdriver.support.ui import WebDriverWait:导入WebDriverWait模块,用于等待元素出现。
from selenium.webdriver.support import expected_conditions as EC:导入expected_conditions模块,用于设置等待条件。
from selenium.common.exceptions import TimeoutException:导入TimeoutException,用于处理超时异常。
from bs4 import BeautifulSoup:导入BeautifulSoup模块,用于解析HTML。
import pymongo:导入pymongo模块,用于操作MongoDB。
import time:导入time模块,用于控制程序执行的延时。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1487
1487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











