







论文链接:
概述
Eyeriss是MIT Yu-Hsin Chen 团队最早于2016年推出的神经网络加速框架,Eyerissv2是其在2019年推出的改进。相比Eyerissv1,v2的结构、设计等各方面均有大幅领先,广受关注。今天我们阅读的文章就是这篇著名的Eyerissv2。
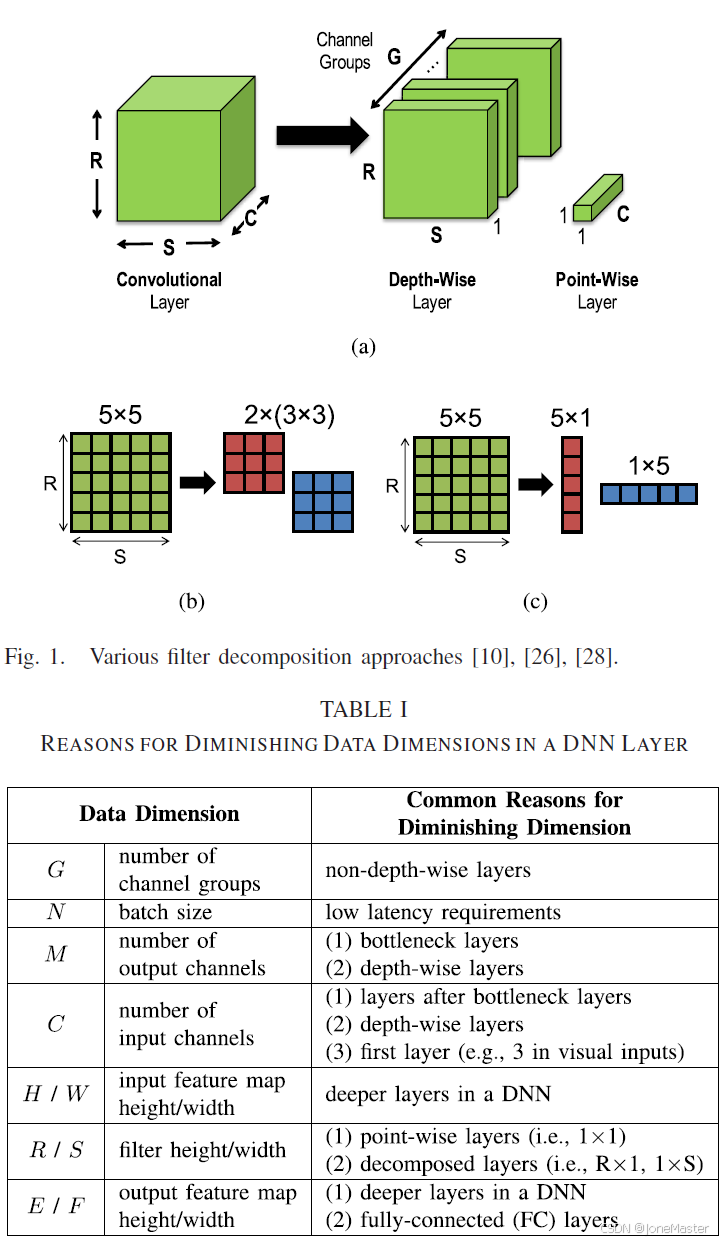
Eyerissv2聚焦于稀疏卷积神经网络加速,那么首先我们先了解一下什么是稀疏卷积神经网络。众所周知,神经网络中主要有两部分数据,一部分是输入图像,我们称之为ifmap(Input feature map),另一部分是权重。简单地来说,我们在很多情况下并不需要一张图全部的特征点,在仅保留部分特征点的情况下,可以获得和以前一样的识别精度和准确率,这是模型的稀疏化。一个输入图可以看作一个二维矩阵,其中0的数量越多,稀疏程度越高。在运算的时候,数值为0的特征值不必要参与运算,因此可以节约一些计算周期。输入权重也是类似的。针对这种稀疏网络,制定什么样的策略来跳过这些“0”周期是值得研究的。
本文中,主要有这些创新与贡献:
- 一种新的NoC,称为分层网格,旨在适应广泛的带宽需求。当数据重用较低时,它可以从内存层次结构提供高带宽(通过单播)以保持pe繁忙;在数据复用度高的情况下,仍然可以利用空间数据复用(通过组播或广播)来实现高能效。对于像MobileNet这样的紧凑型深度神经网络,分层网格将吞吐量提高5.6倍,能源效率提高1.8倍。
- 一种PE,利用权重和激活的稀疏性,在各种DNN层上实现更高的吞吐量和能效。数据以压缩稀疏列(CSC)格式保存,用于片上处理和片外访问,以减少存储和数据移动成本。将权重映射到PE是通过考虑稀疏性来增加PE内的重用来执行的,因此可以减少工作负载不平衡的影响。总的来说,利用稀疏性,MobileNet的吞吐量和能源效率分别提高了1.2倍和1.3倍。
- 一个灵活的加速器,Eyeriss v2,结合了上述贡献,有效地支持紧凑和稀疏dnn。运行稀疏MobileNet的Eyeriss v2比原来的Eyeriss(缩放到与Eyeriss v2相同的pe数量和存储容量),即运行MobileNet (492m mac)的Eyeriss v1快12.6倍,节能2.5倍。与运行AlexNet的Eyeriss v1相比,使用稀疏AlexNet的Eyeriss v2的速度也提高了42.5倍,能效提高了11.3倍,(724.4 m mac)。最后,运行稀疏MobileNet的Eyeriss v2比运行AlexNet的Eyeriss v1快225.1倍,节能42.0倍。很明显,支持稀疏和紧凑的深度神经网络对速度和能量消耗有重大影响。
其中,最为重要的是理解NoC的结构和一种特殊的编码方式:CSC压缩编码。接下来我们将详细介绍文章中的这些概念。
背景与挑战
背景:神经网络迅速发展——计算量增大——减少计算复杂度——部署在移动设备上
先前工作:通过各种方法降低权重精度、使用紧凑的网络结构、增加权重filter的稀疏性,提出了与大规模模型相比参数量更小的多种模型;
存在问题:只从理论上减少了,但没有实际的硬件实现将其转化为能效和处理速度的提升,针对大模型的通用加速器在这些更小规模的模型上表现不佳,需要专门的硬件设计;
相关工作:最新的硬件实现支持了降低精度的方法,可以将位宽从16bit降至1bit,还探究了专门用于二进制网络的硬件;
本文主要工作:聚焦于complementary approaches,特别是支持紧凑DNN的各种filter形状,以及支持对于稀疏DNN压缩域处理的支持;
针对紧凑型和稀疏型DNN提供了硬件加速支持。
紧凑型DNN硬件设计挑战:
不同的模型网络层形状不确定,是具有多种变化的,深度神经网络层中任何数据维度都可以减小。大多数DNN加速器依赖于数据重用作为提高效率的手段,数据维度的减少导致从任何特定的维度利用数据重用变得困难
难点一:矩阵利用率低,Eyeriss将独立的信道组映射到PE阵列的不同部分。提高了利用率
难点二:数据重用较低,如果想充分利用PE只能使用较高的数据带宽,如果提供不了足够的带宽就会导致PE利用率下降。
硬件上需要运行的DNN在设计时是未知的,硬件必须足够灵活以支持广泛的神经网络。数据需要根据layer的特定形状和大小进行灵活的空间映射,而不是预先选择一组维度;NoC(片上数据传输网络)必须在数据重用率低的时候提供高带宽,并在有机会时以高并行性利用数据重用。
稀疏型DNN硬件设计挑战:
形成原因:使用ReLU激活函数,把负值变成0;使用自编码器或生成式对抗网络的形式,包含使用零插入对输入特征映射进行上采样的解码器层,导致超过75%的0
两种提高能效和处理速度的方法:MAC计算门控(减少能耗)或跳过(减少能耗和循环次数)、权重(减少能耗)和激活函数压缩(减少能耗和循环次数)
难点一:不规则访问模式 计算门控可以有效地将权重和激活的稀疏性转化为节能,eyeriss实现了稀疏激活的门控,除了节省能源消耗之外,为了提高吞吐量,最好跳过处理零权重或零影响的mac周期,但这需要复杂的读取逻辑,因为必须找到下一个非零的值,可以提出一个压缩数据的方法但仍旧很难实现
难点二:工作负载不平衡和PE利用率 随着稀疏数据的计算跳过,在每个PE上执行的工作量现在取决于稀疏性。由于非零值的数量在同一过滤器或特征映射中的不同层、数据类型甚至区域之间有所不同,因此它在不同PE之间创建了不平衡的工作负载,并且整个DNN加速器的吞吐量将受到具有最多非零mac的PE的限制。这将导致PE利用率的降低。
Eyerissv2的整体结构
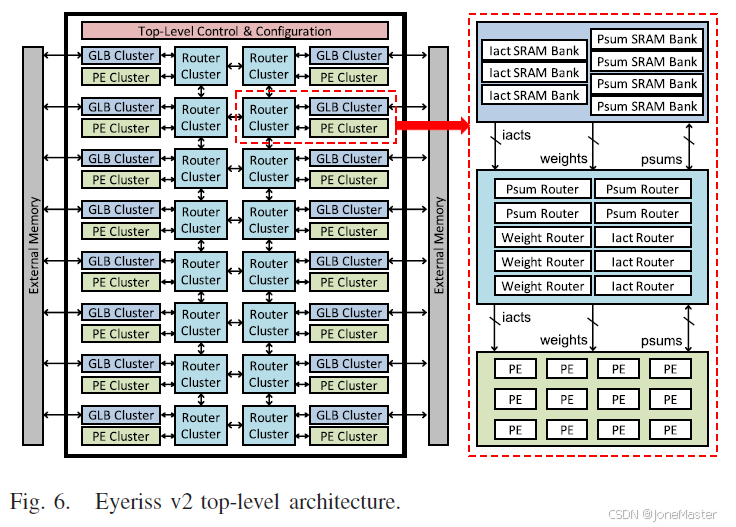
在本文中,设计了如图所示的结构,整体上来说包含3个重要组件,即GLB Cluster、Router Cluster和PE Cluster。这三个小组件为一个小模块,整体上共包含2×8=16个计算阵列。其中,GLB Cluster主要是存储单元(见上图右侧,注意观察颜色,上面蓝色的是GLB内部结构,中间是Router,最下面是PE)其中提供了Iact(输入特征图)和Psum(卷积计算部分和)的存储单元,相应的Weight并没有在GLB中占据额外的存储单元,而是直接从外部存储器中获取。Router中对应于Iact\Weight\Psum都有专门的路由器,这是因为它们提供的复用方式不同,我们在后面详细讲解。在PE Cluster中,包含3×4=12个PE阵列,它们用于卷积的计算。
在这里我们研究一下卷积的运算过程。卷积实质上是不断地乘加的一个过程,相比单纯的矩阵乘法,它多了一步相加求和操作,实际上压缩了矩阵乘法的维度。根据分块矩阵乘法的原理,可以将一个大的矩阵分割成几个小块,分别同时计算,之后再把它们加起来,结果和直接计算大的卷积是一样的。根据这样的原理,Eyeriss的核心思想就是用空间换时间,把计算细化到小块,提高计算的并行度。

本文提到,作者提出了两级内存层次结构,这体现在外部存储和GLB两级。如上所述,Iact从外部存储读入GLB,Psum始终存储在GLB(不与外界存储器交换数据,只在内部交换数据),Weight不存储在GLB:
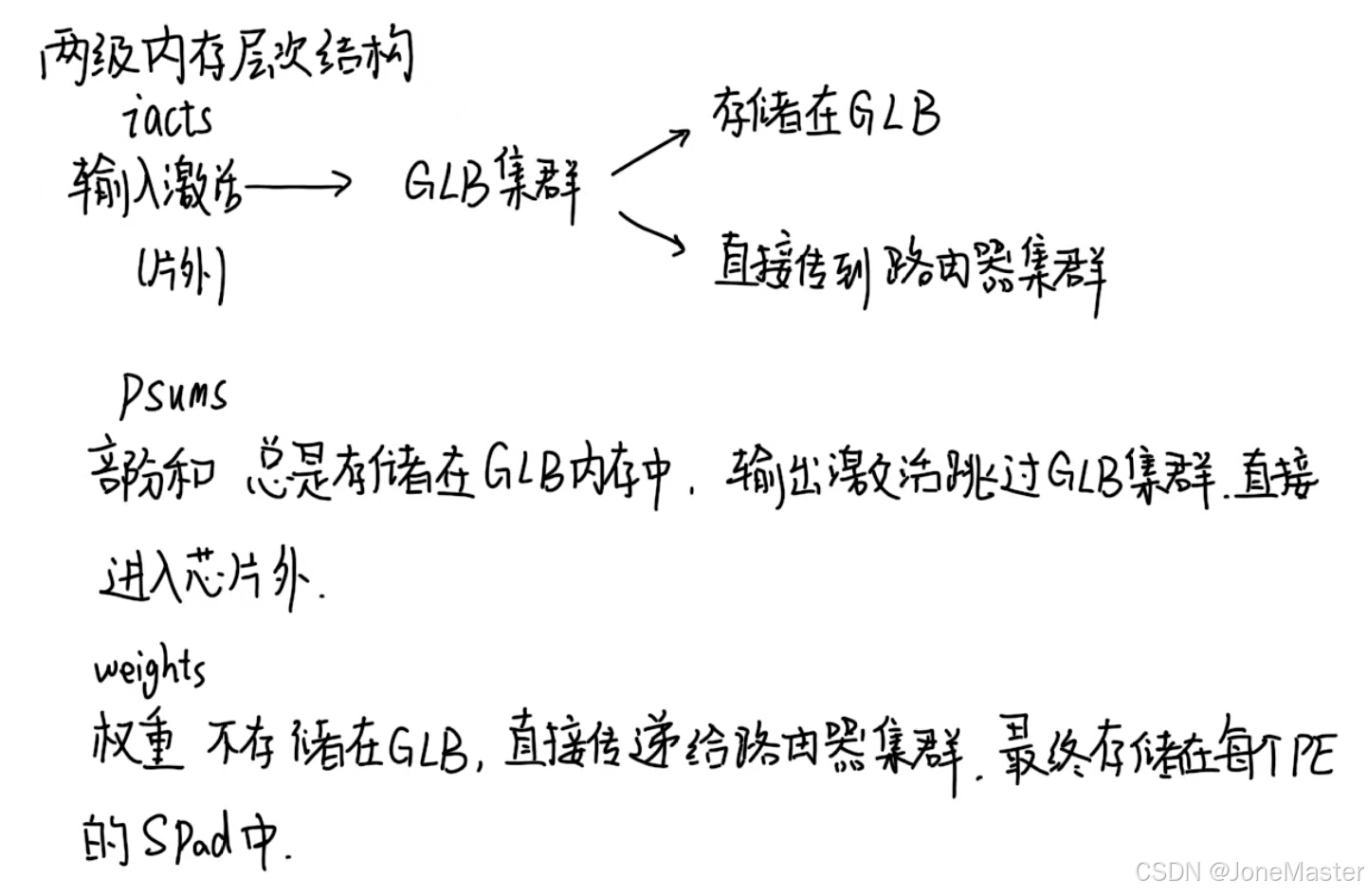
这样的结构设计让Eyerissv2获得了灵活的拓展性,举例来说,当资源不够的时候我们可以减少阵列数量,或者更改每个计算阵列中的单元数目,比如减少PE的数量和SRAM的使用。相反,当资源很充足的时候可以进行拓展以达到更高的并行度。
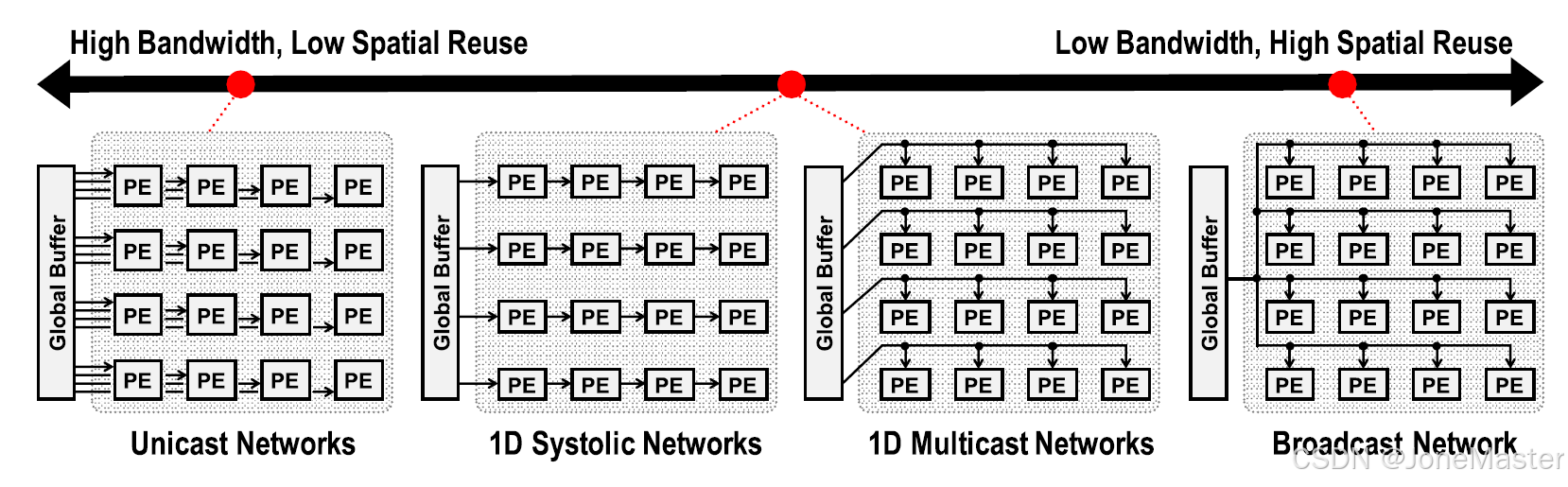
针对数据复用来说,有4种常见的模式,分别是单播(一对一连接)、脉动阵列、组播(一对一列或一行)、广播(一对全部连接)他们的数据复用和带宽的需求是相反规律的变化(单播带宽高,数据复用低;广播带宽低,数据复用高)
注意,Psum的累计精度是20bit,输入输出都是8bit,所以在Psum到最后输出过程的时候中间存在精度转换,但作者表示这样的精度转换并未损失很多准确度。
我们来总结一下,Eyerissv2工作的流程是这样的:
- 首先把Iact和Weight加载到内存中(片外存储器)然后使能加速器,加速器开始工作。
- 在顶层控制模块控制输入数据分别发送到哪个计算单元,相应的计算单元(包含GLB,Router和PE)加速器从内存读取Iact并将其存入GLB。
- 根据数据复用方法,将GLB中的数据经过Router发送到PE进行计算,而结果从PE经Router传回GLB中的Psum SRAM存储,下一次计算时也需要同时读出上一次计算完成的Psum以完成累加的步骤。
本章内容就是这样,我们从整体上了解了Eyerissv2的框架,下一篇文章我们会进一步剖析GLB,Router和PE的具体实现。

















 5647
5647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









