 PIXIV作者作品爬虫实现
PIXIV作者作品爬虫实现




前言
身为一个资深二次元,看到一个作者画的图片,想要统统保存下来。可时常苦恼于手动太费时,费力。于是想找到一个可以爬虫程序可以爬取到图片。找了半天发现大多时间过去了很久爬虫已经失效。于是便利用最近学习的爬虫知识尝试爬取图片。但是不知道是网络原因还是什么其他的原因对于图片下载的完整度不是很好,如果有大佬可以指点的话,小编万分感谢!
一、分析
1.1 URL的构成
以Pixiv博主"可乐米mi"为例,其网址为“https://www.pixiv.net/users/22334948”。当我们看到此url时,其实可以想到大概率组成部分会和后面的数字有关。所以我们便可以再找一个博主的进行比较。接下来是“はねさわ”博主,其网址为“https://www.pixiv.net/users/119532013”。所以现在可以判定,我们的url是由“https://www.pixiv.net/users/+id”所构成的。
1.2 页面分析
当我们打开源代码时,发现所想要保存的图片不在页面当中,并且将鼠标放在想要预览的插画上时,都会有![]() 如图所示的网址,于是,我们可以判断,我们要找的图片URL其实是与这些数字有关的。接下来,我们这里对其做一个简单的抓包,进行分析。
如图所示的网址,于是,我们可以判断,我们要找的图片URL其实是与这些数字有关的。接下来,我们这里对其做一个简单的抓包,进行分析。
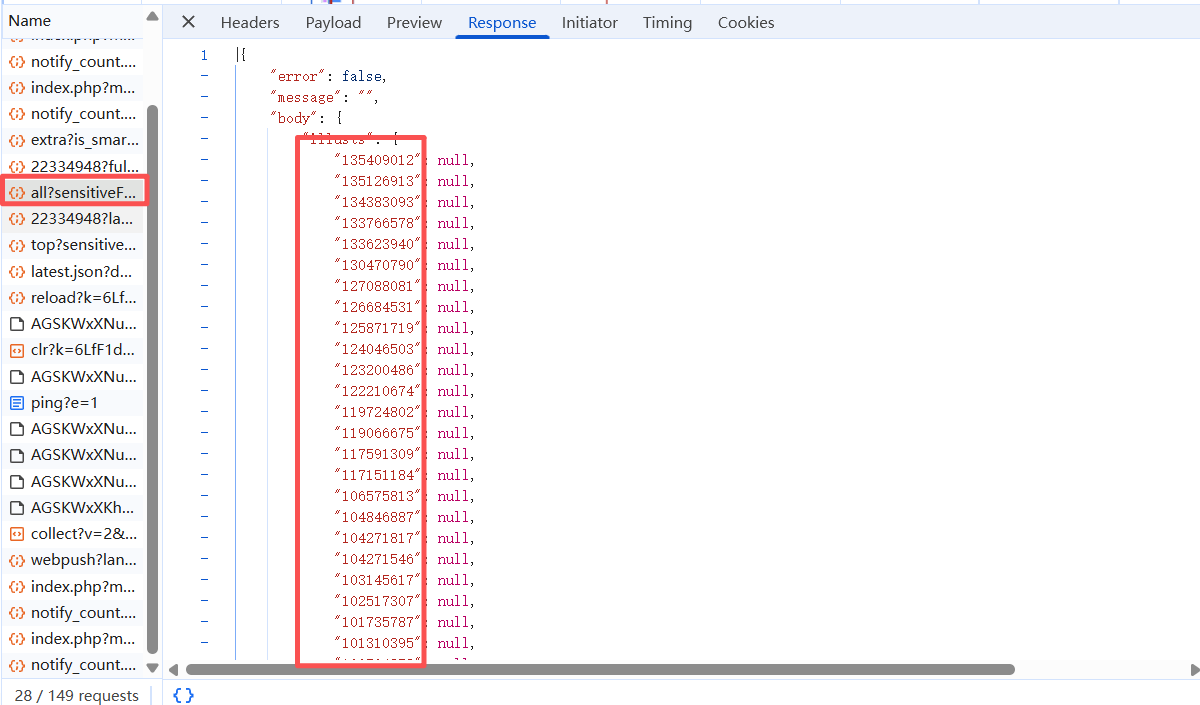
当我们找到此包后,发现所需要的数据都在此中。所以思路就可以是,访问这个包的url来获取json,然后取出这些数字,放在一个列表中,通过遍历列表来取得所有的图片所在地的url。当我们点击一个图片进去后发现面临着同样的问题,预览图片地址也不在url当中。我们打开一个图片在新预览页,发现其URL是“https://i.pximg.net/img-original/img/2025/09/22/18/47/16/135409012_p0.jpg”,所以接下来我们抓包后寻找的应该是神似或者是一样结构的url标题。如图所示
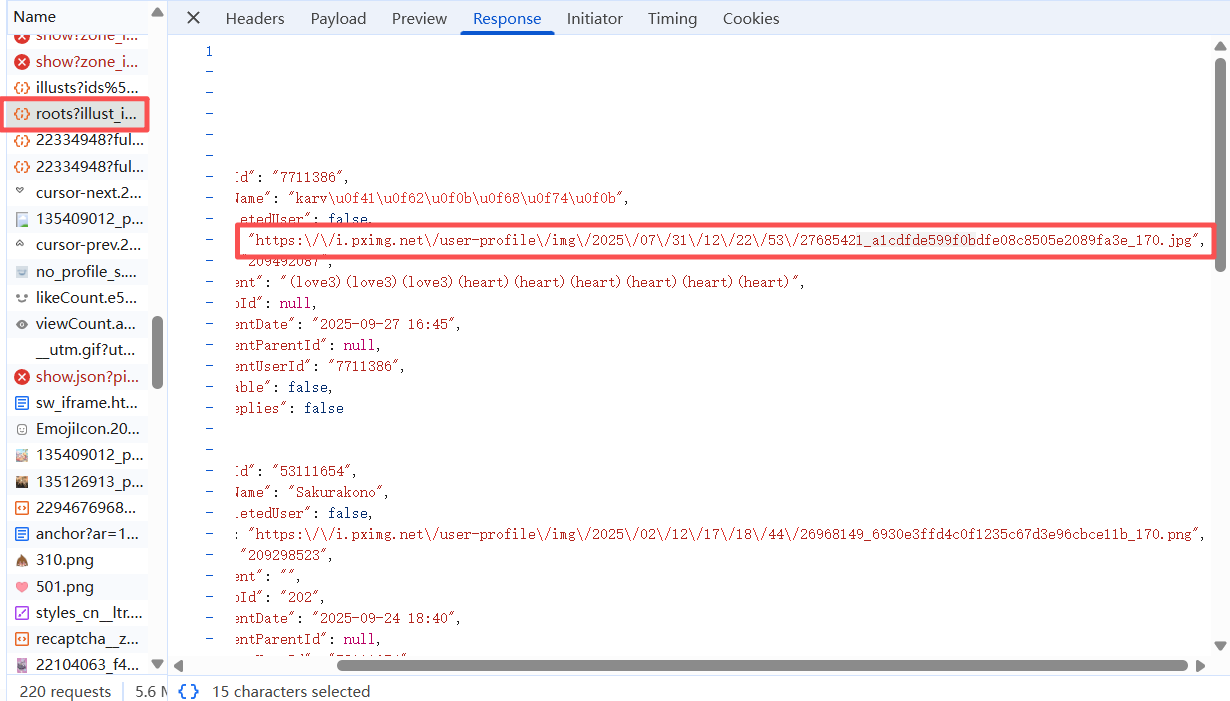
所以我们可以获取所有的json中url的值,然后取第一个,并对他做一些处理,然后得到我们想要的结果。但是这里注意的是,我们需要对它做头的包装,当我们仅仅只是通过网页访问时,并不能获得到其图片,所以当我们对经过PIXIV网站访问的图片预览时,进行抓包发现其有一个防盗链。所以我们要注意这个点。
1.3 思路
- 构造主页面url,使我们进行对其访问获得所有发布图片的帖子;
- 进行抓取其json值,并取出每一个id放到数组中;
- 进行遍历拼接得到我们的子页面url,进行抓取其图片所在的url;
- 保存到本地文件中。
二、源代码
import os.path
from urllib.parse import urlparse
import requests
from bs4 import BeautifulSoup
import json
#判断输入的是否为数字
def judgement_number(id="请输入作者的id:\n"):
while True:
user_input = input(id)
if user_input.isdigit():
return int(user_input)
else:
print("输入无效,请输入id")
def extract_data(number):
try:
json_data = json.loads(number)
except json.JSONDecodeError as e:
print("输入的字符串不是有效的JSON格式")
# 2. 定位到illusts字段(核心目标字段)
# 按JSON结构逐层获取:body → illusts
illusts_dict = json_data.get("body", {}).get("illusts", {})
if not isinstance(illusts_dict, dict):
raise KeyError("JSON中未找到有效的 'body.illusts' 字段,可能数据格式异常")
# 3. 提取illusts字典的所有key(即作品ID字符串),并转为数字
illust_ids = []
for id_str in illusts_dict.keys():
# 验证key是否为纯数字(排除可能的非数字异常key)
if id_str.isdigit():
illust_ids.append(int(id_str))
# 4. 去重(避免重复ID)+ 降序排序(符合Pixiv最新作品ID更大的逻辑)
unique_ids = list(set(illust_ids))
unique_ids.sort(reverse=True)
return unique_ids
def extract_pixiv_thumb_urls(full_json_str, target_illust_id=None):
"""
从Pixiv作品详情JSON中提取缩略图URL(格式:https://i.pximg.net/c/250x250_80_a2/...)
自动剔除转义字符,返回可直接访问的链接形式
参数:
full_json_str: str - 完整的Pixiv作品详情JSON字符串(如你提供的内容)
target_illust_id: str/int - 可选,指定要提取的作品ID(如135418483),不指定则提取所有有效URL
返回:
list - 提取到的缩略图URL列表(可直接复制访问)
"""
thumb_urls = []
# 1. 解析JSON数据,自动处理转义字符(JSON.loads会自动处理\转义)
try:
json_data = json.loads(full_json_str)
except json.JSONDecodeError as e:
raise ValueError(f"JSON解析失败:{str(e)}") from e
# 2. 定位到存储作品信息的核心字段(userIllusts,包含所有作品的缩略图URL)
user_illusts = json_data.get("body", {}).get("userIllusts", {})
if not isinstance(user_illusts, dict):
raise KeyError("JSON中未找到有效的 'body.userIllusts' 字段,无法提取URL")
# 3. 遍历所有作品,提取符合格式的缩略图URL
for illust_id, illust_info in user_illusts.items():
# 跳过值为null的无效作品
if not isinstance(illust_info, dict):
continue
# 若指定了目标作品ID,只处理该作品
if target_illust_id is not None:
if str(illust_id) != str(target_illust_id):
continue
# 提取缩略图URL(key为"url",格式正是https://i.pximg.net/c/250x250_80_a2/...)
thumb_url = illust_info.get("url")
if not thumb_url or not thumb_url.startswith("https://i.pximg.net/c/250x250_80_a2/"):
continue # 只保留目标格式的URL
# JSON解析后已自动剔除转义字符,直接添加到结果列表
thumb_urls.append(thumb_url)
# 去重(避免重复URL)
unique_thumb_urls = list(set(thumb_urls))
return unique_thumb_urls
def download_img(image_url,save_dir="Pixiv_Downloads"):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print(f"正在创建保存文件夹:{os.path.abspath(save_dir)}")
# 3. 提取文件名(从URL中获取,如135718373_p0.png)
parsed_url = urlparse(image_url)
filename = os.path.basename(parsed_url.path)
save_path = os.path.join(save_dir, filename)
# 4. 关键:构造访问图片的请求头(必须包含Cookie和Referer)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
"Referer": "https://www.pixiv.net/", # Pixiv图片防盗链,必须带该Referer
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br, zstd"
}
# 尝试下载函数
def attempt_download(url, path):
try:
print(f"开始下载:{url}")
# 使用stream=True分块下载,避免内存占用过大
response = requests.get(url, headers=headers, timeout=30, verify=False, stream=True)
response.raise_for_status() # 若状态码非200(如403/404),直接抛出异常
# 写入图片文件
with open(path, "wb") as f:
for chunk in response.iter_content(chunk_size=1024 * 1024): # 1MB分块
if chunk:
f.write(chunk)
print(f"下载成功!保存路径:{path}")
return True
except Exception as e:
# 不在这里打印错误,让上层处理
return False
# 5. 发送请求下载图片
try:
# 首先尝试原始URL
success = attempt_download(image_url, save_path)
# 如果失败且是PNG格式,尝试替换为JPG
if not success and filename.lower().endswith('.png'):
# 创建JPG版本的URL和保存路径
jpg_filename = filename[:-4] + '.jpg'
jpg_save_path = os.path.join(save_dir, jpg_filename)
# 替换URL中的.png为.jpg
jpg_url = image_url[:-4] + '.jpg'
print(f"PNG下载失败,尝试下载JPG版本:{jpg_url}")
success = attempt_download(jpg_url, jpg_save_path)
if success:
return True
# 如果下载成功,直接返回
if success:
return True
# 所有尝试都失败,打印错误信息
print(f"下载失败(所有格式都尝试过):{image_url}")
print("可能原因:Cookie过期/URL错误/图片被删除")
except requests.exceptions.HTTPError as e:
print(f"下载失败(HTTP错误):{e}")
print("可能原因:Cookie过期/URL错误/图片被删除")
except requests.exceptions.ConnectionError:
print("下载失败:网络连接异常")
except requests.exceptions.Timeout:
print("下载失败:请求超时")
except Exception as e:
print(f"下载失败(其他错误):{str(e)}")
# 下载失败时删除空文件
if os.path.exists(save_path):
os.remove(save_path)
# 也清理可能创建的JPG文件
if 'jpg_save_path' in locals() and os.path.exists(jpg_save_path):
os.remove(jpg_save_path)
return False
def convert_pixiv_thumb_to_original(thumb_url):
"""
将Pixiv缩略图URL转换为原图URL格式
输入示例: https://i.pximg.net/c/250x250_80_a2/img-master/img/2025/09/30/19/55/30/135718373_p0_square1200.jpg
输出示例: https://i.pximg.net/img-original/img/2025/09/30/19/55/30/135718373_p0.png
参数:
thumb_url: str - 原始缩略图URL
返回:
str - 转换后的原图URL;若格式不匹配则返回None
"""
# 验证URL格式
if not thumb_url.startswith("https://i.pximg.net/c/250x250_80_a2/img-master/img/"):
print("URL格式不匹配,需以'https://i.pximg.net/c/250x250_80_a2/img-master/img/'开头")
return None
# 提取路径部分
base_url = "https://i.pximg.net/"
path_start = thumb_url.find("img-master/img/") + len("img-master/img/")
path_part = thumb_url[path_start:]
# 替换文件名部分
if "_square1200.jpg" in path_part:
filename_part = path_part.replace("_square1200.jpg", ".png")
else:
print("URL缺少'_square1200.jpg'后缀,无法转换")
return None
# 拼接最终URL
original_url = f"{base_url}img-original/img/{filename_part}"
return original_url
id = judgement_number()
#https://www.pixiv.net/ajax/user/26408825/profile/all?sensitiveFilterMode=userSetting&lang=zh
#https://www.pixiv.net/ajax/user/22334948/profile/all?sensitiveFilterMode=userSetting&lang=zh
url = f"https://www.pixiv.net/ajax/user/{id}/profile/all?sensitiveFilterMode=userSetting&lang=zh"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
"referer":f"https://www.pixiv.net/users/{id}",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cookie":""
}
data = {
"lang":"zh",
'sensitiveFilterMode':'userSetting',
}
resp = requests.get(url,headers=headers,data=data)
illust_ids = extract_data(resp.text)
for item in illust_ids:
url1 = f"https://www.pixiv.net/artworks/{item}"
url2 = f"https://www.pixiv.net/ajax/illust/{item}?lang=zh"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36",
"referer": url1,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cookie": ""
}
data = {
"lang":"zh",
}
child_resp = requests.get(url2,headers=headers,data=data)
img_url = extract_pixiv_thumb_urls(child_resp.text)[0]
orange_img_url = convert_pixiv_thumb_to_original(img_url)
download_img(orange_img_url)
















 108
108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}